
Pandas騷操作:用 pandas 快速爬數(shù)據(jù)
↑ 關(guān)注 + 星標(biāo) ,每天學(xué)Python新技能
后臺(tái)回復(fù)【大禮包】送你Python自學(xué)大禮包

提起爬蟲,大家可能都知道requests、beautifulsoup、scrapy、selenium等等一些工具庫(kù)。但其實(shí)對(duì)于一些日常的網(wǎng)頁(yè)Table表格數(shù)據(jù)抓取來(lái)講,沒(méi)有必要去F12研究HTML頁(yè)面結(jié)構(gòu)甚至寫正則表達(dá)式解析字段。
本次東哥介紹一個(gè)超級(jí)簡(jiǎn)單的方法,用pandas也可以玩爬蟲。
pandas自帶一個(gè)方法是read_html,利用這個(gè)方法可以直接爬蟲網(wǎng)頁(yè)的Table表格型數(shù)據(jù),無(wú)需敲更多的爬蟲代碼,簡(jiǎn)單!粗暴!
查看HTML結(jié)構(gòu),如果發(fā)現(xiàn)是下面這個(gè)table格式的,那直接可以上手開干。
<table class="..." id="...">
<thead>
<tr>
<th>...</th>
</tr>
</thead>
<tbody>
<tr>
<td>...</td>
</tr>
<tr>...</tr>
<tr>...</tr>
...
<tr>...</tr>
<tr>...</tr>
</tbody>
</table>
下面我們來(lái)看下如何操作。
一、使用方法
舉一個(gè)例子,拿wiki百科上的各國(guó)家收入的頁(yè)面抓取演示一下。
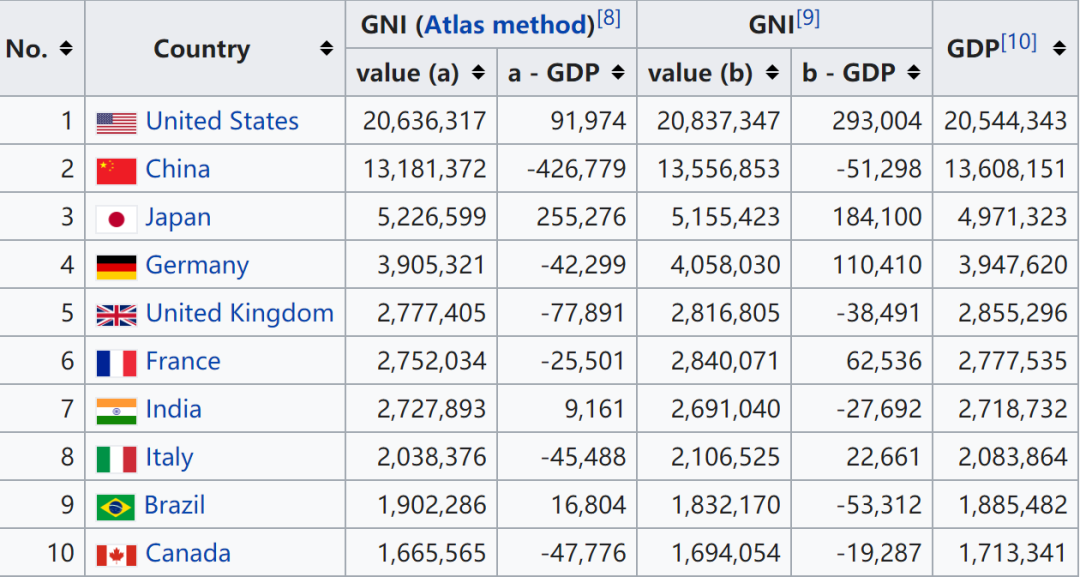
read_html,它可以自動(dòng)將網(wǎng)頁(yè)的所有表格數(shù)據(jù)全部抓取下來(lái)。代碼如下:import pandas as pd
url = 'https://en.wikipedia.org/wiki/Gross_national_income'
tables = pd.read_html(url)
這里返回的tables是一個(gè)DataFrames的列表,每個(gè)DataFrame就是網(wǎng)頁(yè)中從上到下順序的數(shù)據(jù)表格。因此,可以用列表的切片tables[x]來(lái)提取網(wǎng)頁(yè)指定的表格數(shù)據(jù)。
比如,我們對(duì)第4個(gè)表格感興趣,那么直接:
talbes[3]
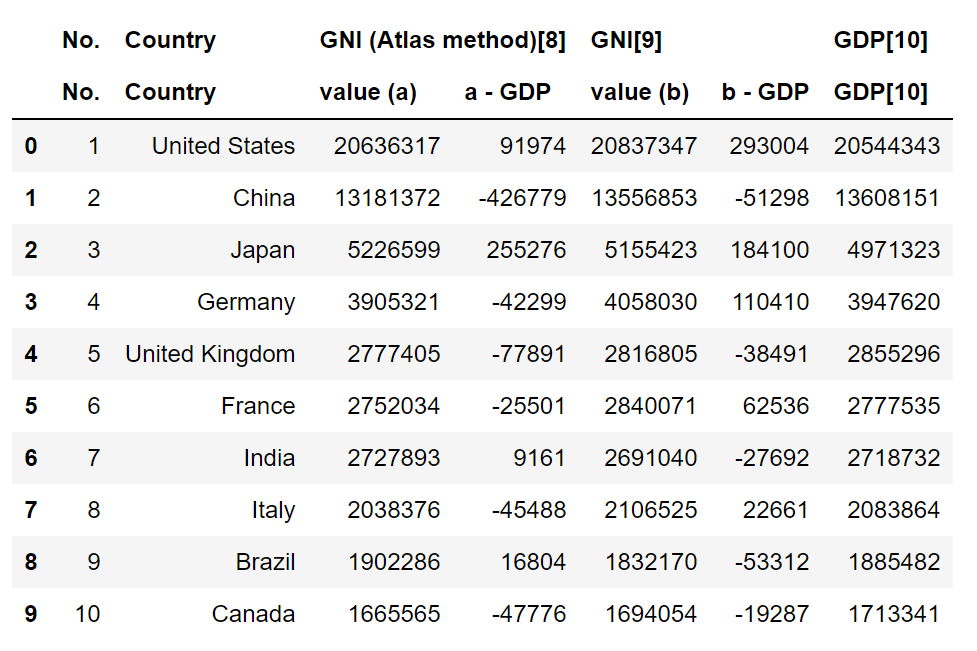
當(dāng)然,上面表格看起來(lái)有點(diǎn)別扭,我們可以簡(jiǎn)單幾個(gè)操作調(diào)整一下表結(jié)構(gòu)。
df = tables[3].droplevel(0, axis=1)\
.rename(columns={'No.':'No', 'GDP[10]':'GDP'})\
.set_index('No')
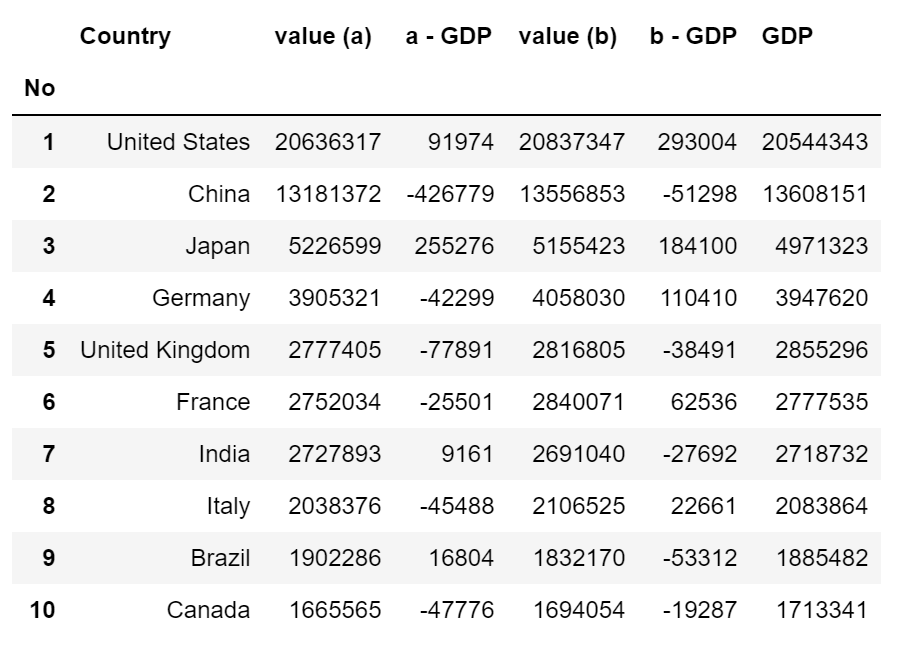
這樣看起來(lái)就好多了。
最后,read_html中也配有很多參數(shù)可供調(diào)整,比如匹配方式、標(biāo)題所在行、網(wǎng)頁(yè)屬性識(shí)別表格等等,具體說(shuō)明可以參看pandas的官方文檔學(xué)習(xí)。
官網(wǎng)鏈接:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_html.html
以上所有代碼已上傳至我的GitHub:
項(xiàng)目鏈接:https://github.com/xiaoyusmd/PythonDataScience
原創(chuàng)不易,GitHub給個(gè)Star求續(xù)命
- END -
推薦閱讀
推薦一個(gè)公眾號(hào),幫助程序員自學(xué)與成長(zhǎng)
覺(jué)得還不錯(cuò)就給我一個(gè)小小的鼓勵(lì)吧!
