
【干貨大禮包】NLP大模型開發(fā)18個(gè)干貨資料合集(高頻面試問題答案)

這是求職產(chǎn)品經(jīng)理系列的第189篇文章
哈嘍大家好,最近很多小伙伴求職NLP大模型算法工程師,找我要的一個(gè)干貨資料:《NLP大模型開發(fā)18個(gè)干貨資料合集》耗時(shí)25天終于整理完成了!
干貨合集一:NLP大模型面試最全題庫整理篇
一、大模型基本概念相關(guān)問題(9個(gè))
二、基礎(chǔ)知識(shí)相關(guān)問題(32個(gè))
三、大模型算法相關(guān)問題(12個(gè))
四、訓(xùn)練框架相關(guān)問題(3個(gè))
五、評(píng)測(cè)相關(guān)問題(4個(gè))
六、數(shù)據(jù)相關(guān)問題(3個(gè))
( 不含答案,大家可以當(dāng)做題庫使用,但是這63道問題的答案基本已包含在其他干貨合集中)
干貨合集二:網(wǎng)易NLP大模型實(shí)習(xí)面試題及解析(含答案)
1、文本生成的幾大預(yù)訓(xùn)練任務(wù)?
2、多模態(tài)中常見的SOTA模型有哪些?
3、介紹一下stable diffusion的原理。
4、instructGPT的原理,講講rlhf和reward。
5、講講T5和Bart的區(qū)別,講講bart的DAE任務(wù)。
6、講講Bart和Bert的區(qū)別。
7、對(duì)比學(xué)習(xí)負(fù)樣本是否重要?負(fù)樣本構(gòu)造成本過高應(yīng)該怎么解決?
8、介紹一下lora的原理和ptuning的原理。
干貨合集三:科大訊飛-NLP大模型算法面試題及解析(含答案)
1、jieba分詞的原理
2、word2vec的原理,怎么訓(xùn)練的?
3、ChatGPT是怎么訓(xùn)練出來的
4、BERT模型簡(jiǎn)述
5、PyTorch中的train和eval模塊:
6、Python中字典的結(jié)構(gòu)及實(shí)現(xiàn)方式
7、有一組無序數(shù)組,如何取前10個(gè)最大的數(shù)
干貨合集四:榮耀NLP算法工程師面試題及解析(含答案)
1、講一下transformer
2、transformer怎么調(diào)優(yōu)
3、講講word2vec和word embedding區(qū)別
4、有做過NER嗎,講講prompt learning
5、講講生成模型和判別模型的區(qū)別
6、講講LDA算法
干貨合集五:華為NLP算法工程師面試題及解析(含答案)
1、NLP中常見的分詞方法有哪些?
2、講一下BERT的結(jié)構(gòu)?
3、自然語言處理有哪些任務(wù)?
4、L1,L2正則化的區(qū)別,嶺回歸是L1正則化還是L2正則化?
5、怎么處理類別不平衡?
6、模型提速的方法有哪些?
7、了解數(shù)據(jù)挖掘的方法嘛?
8、了解對(duì)比學(xué)習(xí)嘛?
9、說一下廣度優(yōu)先遍歷和深度優(yōu)先遍歷?
干貨合集六:大廠常考Transformer模型面試題及解析(含答案)
1、Transformer在哪里做了權(quán)重共享,為什么可以做權(quán)重共享?
2、不考慮多頭的原因,self-attention中詞向量不乘QKV參數(shù)矩陣,會(huì)有什么問題?
3、什么BERT選擇mask掉15%這個(gè)比例的詞,可以是其他的比例嗎?
4、為什么BERT在第一句前會(huì)加一個(gè)[CLS]標(biāo)志?
5、Self-Attention公式為什么要除以d_k的開方?
干貨合集七:百度NLP實(shí)習(xí)面試及解析(含答案)
1、說一下transformer。
2、Layer Normalization 和 Batch Normalization。
3、項(xiàng)目里面具體怎么實(shí)現(xiàn)PGN的。
4、你知道什么生成任務(wù)的模型嗎。
干貨合集八:NLP大模型-Transformer面試題總結(jié)100道題
( 不含答案,但是這100道問題的答案基本已包含在其他干貨合集中)
干貨合集九:LLM大模型面試準(zhǔn)備題庫及答案(上)(含答案)
1. 如何定義“大模型”在現(xiàn)代AI領(lǐng)域的概念?
2. GPT的全稱是什么,其中每個(gè)詞匯的具體含義是什么?描述ChatGPT、GPT和大模型之間的關(guān)系和區(qū)別。
3.如何定義AGI這一概念?AIGC代表的是什么概念或技術(shù)?
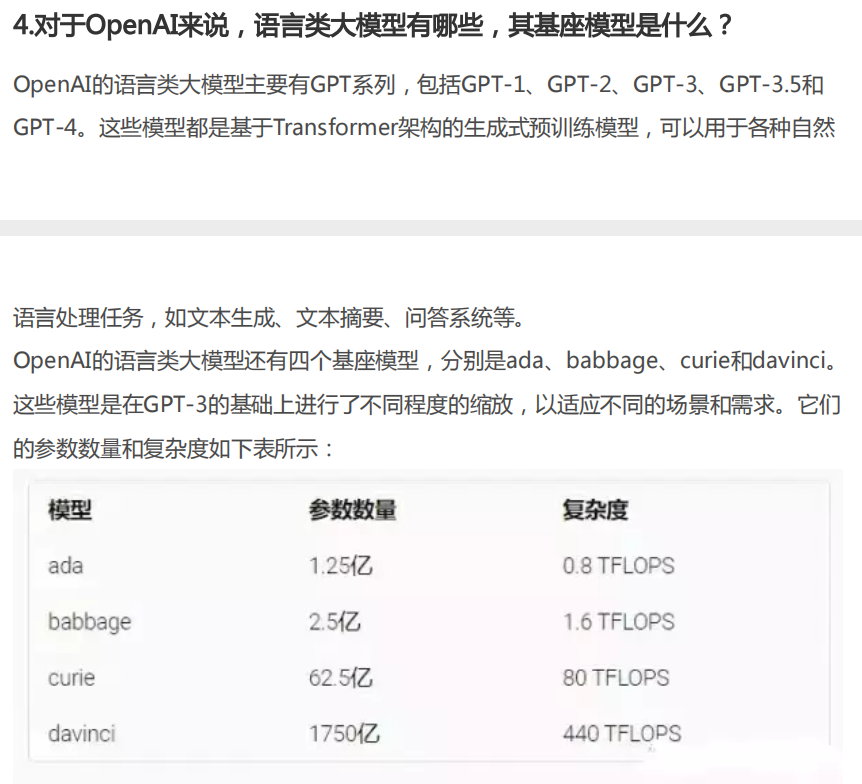
4.對(duì)于OpenAI來說,語言類大模型有哪些,其基座模型是什么?
5.OpenAI的文本向量化模型是用來做什么的?
6.請(qǐng)描述LLM的涌現(xiàn)能力及其主要包含的方面,以及其激活方法
7.定義提示工程是什么?
8.在提示工程中,主要采用哪些方式添加提示?
9.微調(diào)的定義是什么?
10.當(dāng)微調(diào)與提示工程進(jìn)行比較時(shí),優(yōu)勢(shì)和劣勢(shì)是什么?
11.微調(diào)和提示工程在應(yīng)用場(chǎng)景中的關(guān)系和聯(lián)系是什么?
12.請(qǐng)描述代碼提示工程的核心概念
13.什么是Zero-shot提示方法
14.什么是Few-shot提示方法
15.闡述One-shot和Few-shot提示策略及其應(yīng)用場(chǎng)景
16.什么是思維鏈?思維鏈的本質(zhì)是什么
17.什么是逐步Zero-shot
18.定義Zero-shot-CoT提示策略并描述其應(yīng)用方法
19.解釋Few-shot-CoT提示策略及其實(shí)際使用方式
20.什么是模型的推理能力?
21.LtM提示策略是如何分階段進(jìn)行的
22.Few-shot-LtM策略包含哪些主要階段及其職責(zé)
干貨合集十:LLM大模型面試準(zhǔn)備題庫及答案(下)(含答案)
1.相比較于llama而言,llama2有哪些改進(jìn),對(duì)于llama2是應(yīng)該如何finetune?
2、什么是多模態(tài),多模態(tài)中常見的SOTA模型有哪些?
3、什么是stable diffusion,請(qǐng)你介紹一下diffusion模型的原理?
4、instructGPT的原理,講講RLHF、SFT、和reward。
5、講講T5和Bart的區(qū)別,講講Bart的DAE任務(wù)。
6、講講Bart和Bert的區(qū)別。
7、對(duì)比學(xué)習(xí)負(fù)樣本是否重要?負(fù)樣本構(gòu)造成本過高應(yīng)該怎么解決?
8、介紹一下lora的原理和ptuning的原理。
9.aigc方向國(guó)內(nèi)的典型研究機(jī)構(gòu)以及代表性工作有哪些?
10.什么是langchain,原理是什么,有什么應(yīng)用?
干貨合集十一:NLP常見面試題及答案匯總(含答案)
一 、基礎(chǔ)問題
1. NLP有哪些常見任務(wù)
2. 請(qǐng)介紹下你知道的文本表征的方法(詞向量)。
3. 如何生成句向量?
4. 如何計(jì)算文本似度
5. 樣本不平衡的解決方法?
6. 過擬合有哪些表現(xiàn),怎么解決?
7. 用過 jiaba 分詞嗎,了解原理嗎
8. 了解命名實(shí)體識(shí)別嗎?通常用什么方法,各自有什么特點(diǎn)
9. 了解HMM和CRF嗎?
10. 了解RNN嗎,LSTM呢,LSTM相對(duì)RNN有什么特點(diǎn)
11. 會(huì)用正則表達(dá)式嗎?re.match() 和 re.search() 有什么區(qū)別?
二 進(jìn)階問題
1. elmo、GPT、bert三者之間有什么區(qū)別?
2. 了解BERT?講一下原理?有用過嗎?
3. word2vec和fastText對(duì)比有什么區(qū)別
4. LSTM時(shí)間復(fù)雜度,Transformer 時(shí)間復(fù)雜度
5. 如何減少訓(xùn)練好的神經(jīng)網(wǎng)絡(luò)的推理時(shí)間?
干貨合集十二:NLP/Transformer/BERT/Attention面試問題與答案(含答案)
一、BERT相關(guān)問題(15個(gè))
二、Transformer相關(guān)問題(8個(gè))
三、后BERT相關(guān)問題(6個(gè))
四、Self Attention相關(guān)問題(6個(gè))
五、Norm相關(guān)問題(8個(gè))
干貨合集十三:小紅書/抖音/螞蟻/寒武紀(jì)/Boss直聘NLP大模型社招面經(jīng)匯總
(每一場(chǎng)面試都包含詳細(xì)的面試問題以及參考答案)
一、整體面試總結(jié)
二、面經(jīng)-小紅書
小紅書一面:
小紅書二面:三、面經(jīng)-抖音
抖音一面
抖音二面
抖音三面四、面經(jīng)-螞蟻
螞蟻一面:
螞蟻二面:
螞蟻三面:五、面經(jīng)-寒武紀(jì)
寒武紀(jì)一面:
寒武紀(jì)二面:六、面經(jīng)-某金融公司
金融公司一面:
金融公司二面:七、面經(jīng)-boss直聘
BOSS一面:
BOSS二面:
面試合集十四:貨拉拉NLP工程師面試題及答案(含答案)
1.詞向量平均法做分類的優(yōu)劣勢(shì)是什么
2.詞向量的基礎(chǔ)上如何做優(yōu)化
3.Bert模型和Transformer模型之間的關(guān)系
4.Bert模型中有哪些預(yù)訓(xùn)練的任務(wù)
5.Bert模型的做句向量的缺陷
6.如何解決Bert句向量的缺陷
干貨合集十五:騰訊/阿里/攜程實(shí)習(xí)詳細(xì)NLP面試題面經(jīng)
(每一場(chǎng)面試都包含詳細(xì)的面試問題以及參考答案)
一、阿里(已offer)
一面:電話面試(30min)
二面:電話面試(30min)
反問:
二、攜程(已offer)
一面:線下面試(1h)
二面:線下面試(40min)
三、騰訊(HR面結(jié)束)
一面:騰訊會(huì)議面試(30min)
二面:騰訊平臺(tái)面試(1h20min)
HR面:騰訊會(huì)議面試(18min)
反問:
干貨合集十六:騰訊NLP算法面試題整(抽象歸納多篇騰訊面經(jīng))
編程&數(shù)學(xué)基礎(chǔ)(25個(gè))
項(xiàng)目深度(14個(gè))
基礎(chǔ)知識(shí)(48個(gè))
開放題(17個(gè))
干貨合集十七:阿里巴巴NLP算法面試題整(抽象歸納多篇阿里巴巴面經(jīng))
編程&數(shù)學(xué)基礎(chǔ)(21個(gè))
項(xiàng)目深度(11個(gè))
基礎(chǔ)知識(shí)(37個(gè))
開放題(18個(gè))
干貨合集十八:百度NLP算法面試題整(抽象歸納多篇百度面經(jīng))
編程題(11個(gè))
項(xiàng)目深度(2個(gè))
基礎(chǔ)知識(shí)(32個(gè))
開放題(6個(gè))
都是移動(dòng)互聯(lián)網(wǎng)產(chǎn)品經(jīng)看,隨便截幾張預(yù)覽圖片:
隨便截圖的示例一:

隨便截圖的示例二:
隨便截圖的示例三:

隨便截圖的示例四:

隨便截圖的示例五:面經(jīng)

整理不易,耗時(shí)25天,所以咱們這個(gè)干貨資料不是免費(fèi)的,因?yàn)楹竺娲蛩愠掷m(xù)更新,所以價(jià)格梯度如下
1-100名:¥49
101-200名:¥79
需要的小伙伴掃碼下面的二維碼或者直接添加微信:xuelaoban678
微信轉(zhuǎn)賬即可。當(dāng)然后續(xù)其他很多干貨資料我會(huì)直接分享到咱們AI求職交流群(針對(duì)想要做AIGC大模型產(chǎn)品經(jīng)理的小伙伴)和大模型NLP研發(fā)交流群針對(duì)想要做AIGC大模型算法的小伙伴)中,所以沒有在群里的可以私信我,拉你入群。