
從Embedding到XLNet:NLP預(yù)訓(xùn)練模型簡(jiǎn)介
深度學(xué)習(xí)
Author:louwill
Machine Learning Lab
遷移學(xué)習(xí)和預(yù)訓(xùn)練模型不僅在計(jì)算機(jī)視覺(jué)應(yīng)用廣泛,在NLP領(lǐng)域也逐漸成為主流方法。近來(lái)不斷在各項(xiàng)NLP任務(wù)上刷新最佳成績(jī)的各種預(yù)訓(xùn)練模型值得我們第一時(shí)間跟進(jìn)。本節(jié)對(duì)NLP領(lǐng)域的各種預(yù)訓(xùn)練模型進(jìn)行一個(gè)簡(jiǎn)要的回顧,對(duì)從初始的Embedding模型到ELMo、GPT、到谷歌的BERT、再到最強(qiáng)NLP預(yù)訓(xùn)練模型XLNet。梳理NLP預(yù)訓(xùn)練模型發(fā)展的基本脈絡(luò),對(duì)當(dāng)前NLP發(fā)展的基本特征進(jìn)行概括。
從Embedding到ELMo
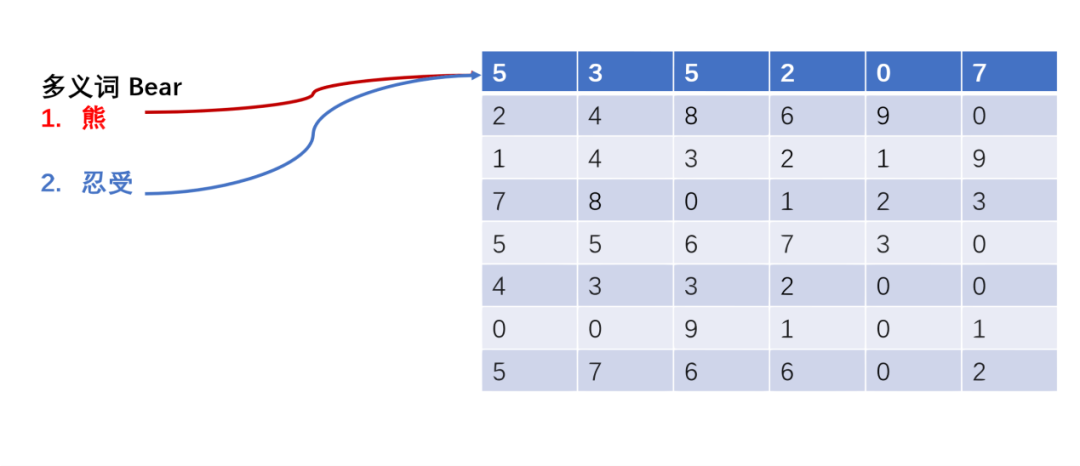
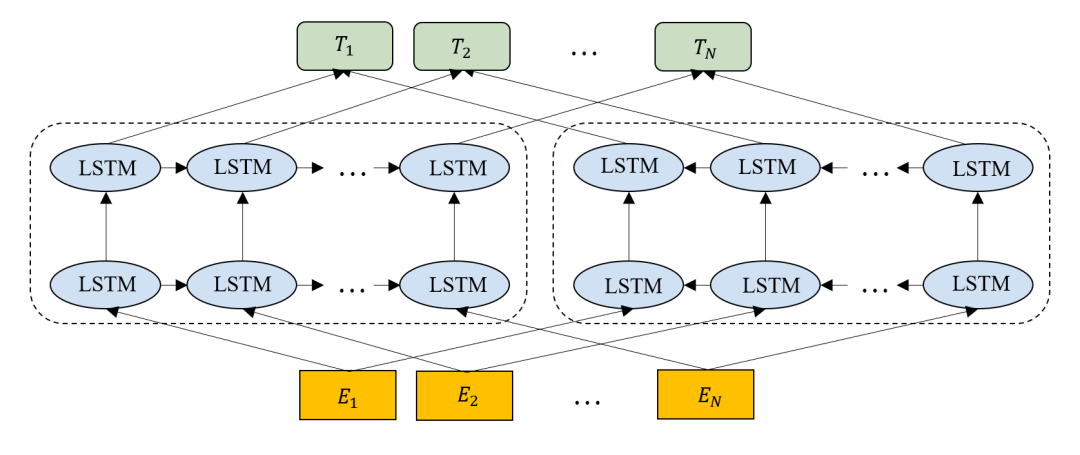
圖2 ELMo結(jié)構(gòu)

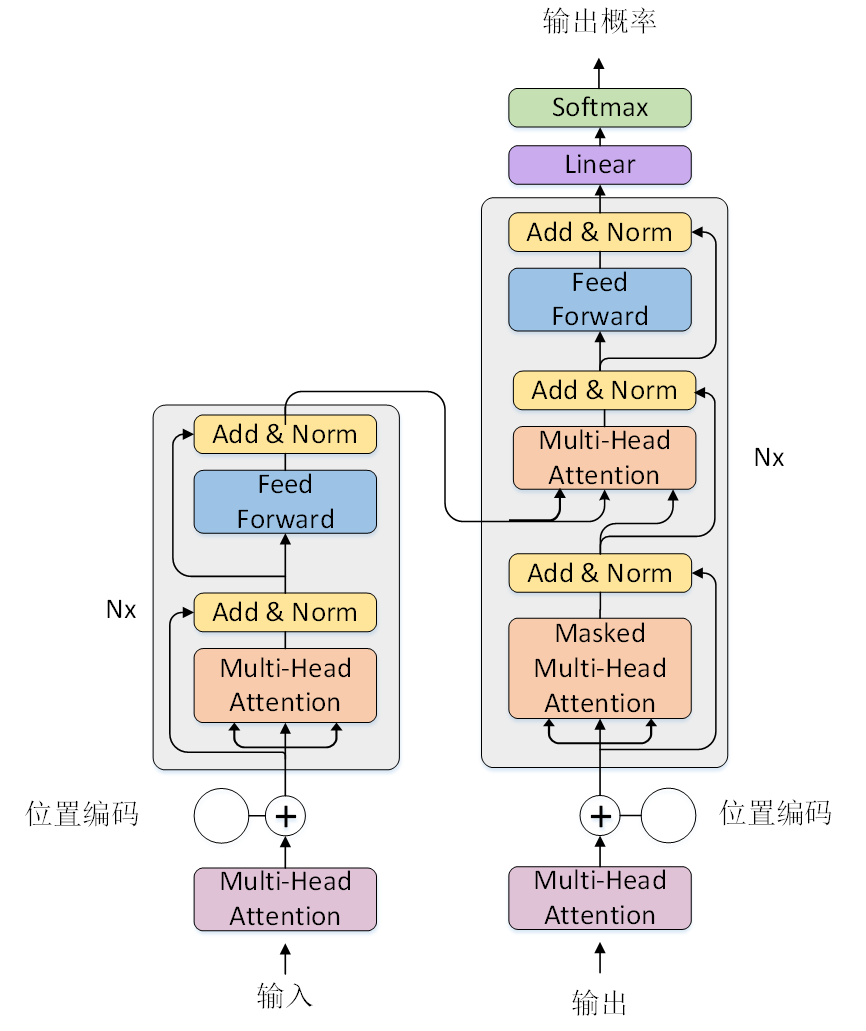
特征提取器:Transformer
低調(diào)王者:GPT
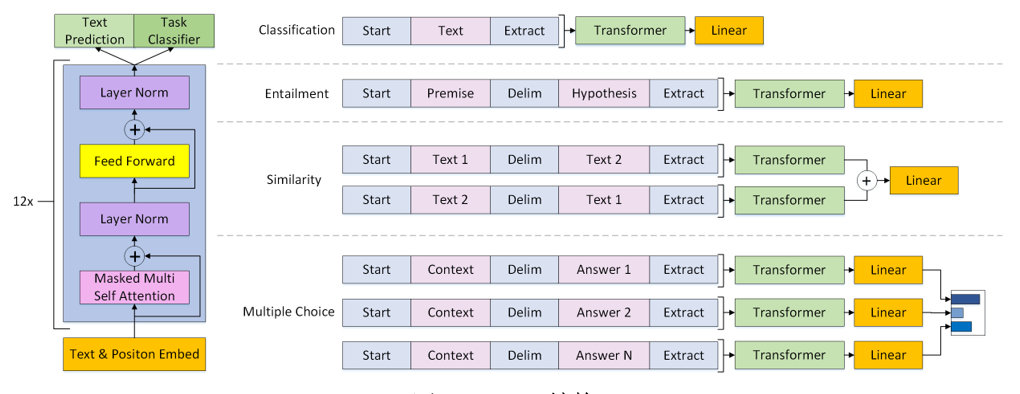
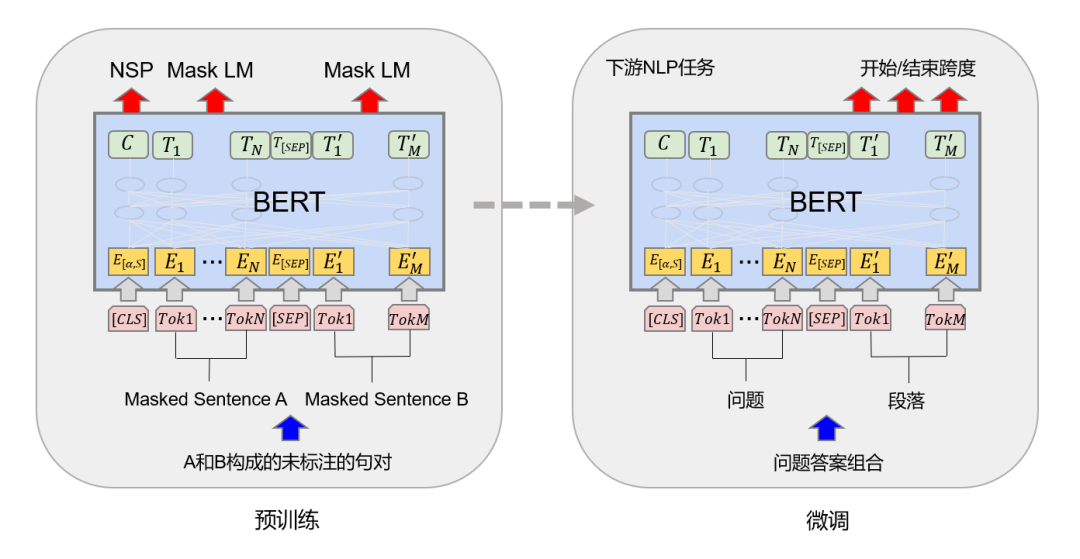
封神之作:BERT
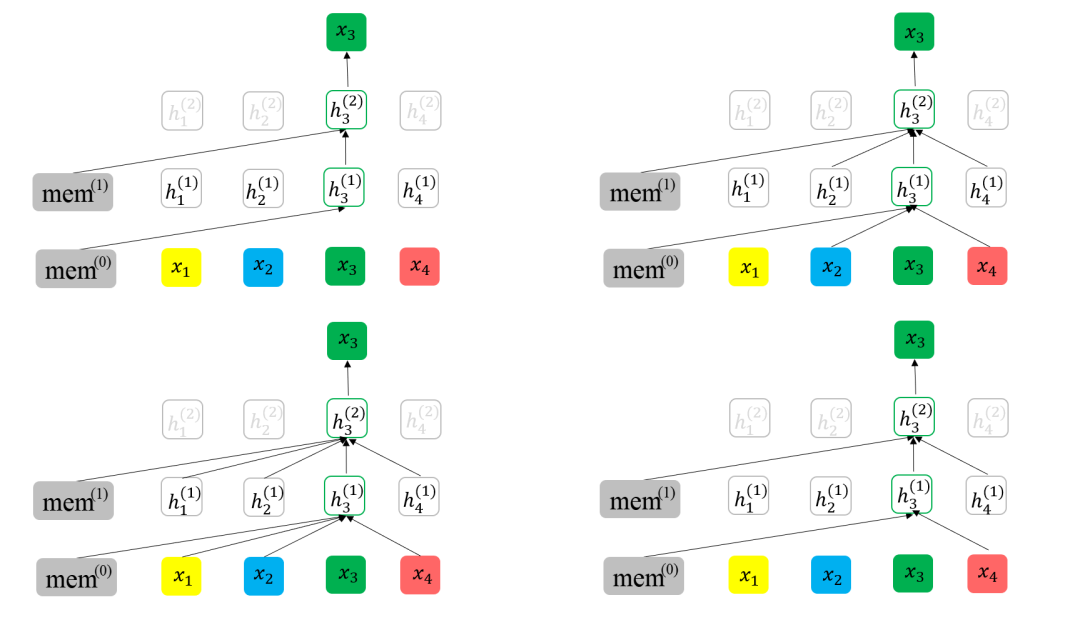
持續(xù)創(chuàng)新:XLNet
往期精彩:
【原創(chuàng)首發(fā)】機(jī)器學(xué)習(xí)公式推導(dǎo)與代碼實(shí)現(xiàn)30講.pdf
【原創(chuàng)首發(fā)】深度學(xué)習(xí)語(yǔ)義分割理論與實(shí)戰(zhàn)指南.pdf
算法工程師的日常,一定不能脫離產(chǎn)業(yè)實(shí)踐
技術(shù)人要學(xué)會(huì)自我營(yíng)銷(xiāo)
求個(gè)在看
評(píng)論
圖片
表情