
一文串起從NLP到CV 預(yù)訓(xùn)練技術(shù)和范式演進(jìn)
本文首發(fā)于微信公眾號:包包算法筆記。包大人班車原創(chuàng)內(nèi)容分享。
主題是深度學(xué)習(xí)中的預(yù)訓(xùn)練技術(shù)發(fā)展,基本思路是順著CV和NLP雙線的預(yù)訓(xùn)練技術(shù)發(fā)展演進(jìn)。看他們怎么影響和交織。
序言
會大致的看一下,在2013年,在CNN時代的word2vec,在2020年,Bert的時代的MAE,他們各自的預(yù)訓(xùn)練技術(shù)是在8年之間,從CNN發(fā)展到MAE,以及怎么從word2vec發(fā)展到Bert,各自的思路是怎樣形成以及相互影響的。預(yù)訓(xùn)練技術(shù)的歷史背景是什么,演進(jìn)路線是什么,各個創(chuàng)新點是什么。為什么transformer作為集大成者,在CV和NLP上最后形成了交織和影響。
開頭和結(jié)尾放同一張圖,分別奠定本文的主線,所有細(xì)節(jié)將在后面逐漸展開!
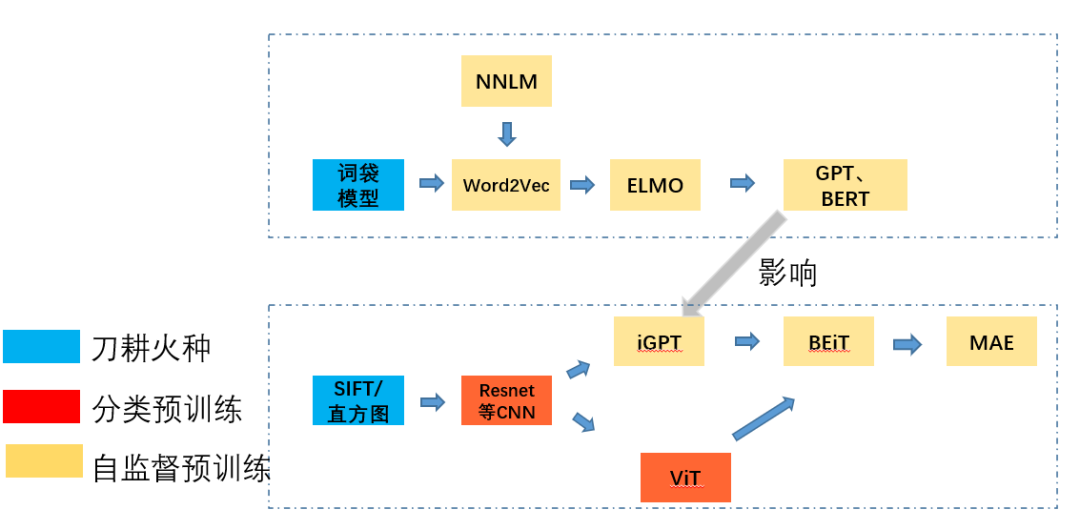
從NLP說起
從預(yù)訓(xùn)練技術(shù)說起,按照時間線,還是講NLP里的word2vec吧,NLP里的有監(jiān)督任務(wù)的范式,可以歸納成如下的樣子。
輸入是字詞序列,中間一步關(guān)鍵的是語義表征,有了語義表征之后,然后交給下游的模型學(xué)習(xí)。預(yù)訓(xùn)練技術(shù)的發(fā)展,都是在圍繞怎么得到一個好的語義表征(representation)的這一層次,逐漸改進(jìn)的。
下面我們圍繞表征(representation)這一塊展開講解。
語義表征演進(jìn)
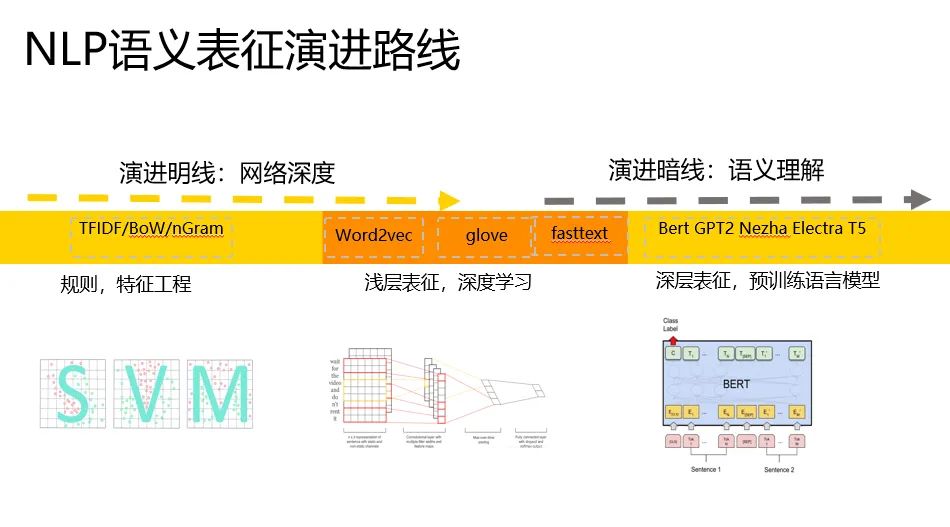
我們可以把語義表征(representation)的計算,大致將演進(jìn)路線歸納成如下的樣子。
有兩條路線,分別從網(wǎng)絡(luò)深度和語義理解兩個角度出發(fā),網(wǎng)絡(luò)越走越深,語義理解越來越深刻,越來越有代表性。
我們粗略的可以把語義表征的計算分為三個階段,分別是:
一、特征工程階段,以詞袋模型為典型代表。
二、淺層表證階段,以word2vec為典型代表。
三、深層表征階段,以基于transformer的Bert為典型代表。
后面我們講仔細(xì)講解,演進(jìn)中解決的關(guān)鍵問題和基本思路。
刀耕火種
首先是詞袋模型,顧名思義,就是一個袋子打包詞,表征計算如下文右邊的籃筐,每個維度統(tǒng)計了文檔中詞的數(shù)量。
這種簡單粗暴的表征有一個問題,就是語義局限與字面相同與否。
人工智能和AI兩個詞,在語義上是有強關(guān)聯(lián)的,但是這個詞袋模型就抓瞎了。
為了解決這個問題,word2vec在2013年被搞出來了。

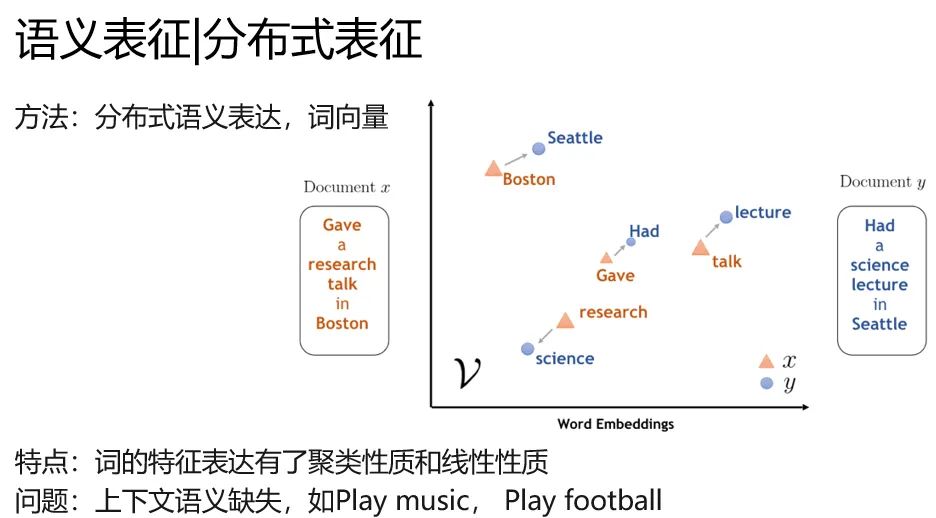
詞向量
word2vec就是典型學(xué)術(shù)的分布式語義表征(distribution representation)的代表,你肯定聽過另外一個名字,詞向量。
嗯詞袋模型的時候,人還真沒把叫做詞向量。頂多算特征工程的一種。在word2vec時候,這種語義表征有了專門的名字。
他的特別是詞的特征表達(dá)具有了聚類性質(zhì)和線性性質(zhì),在一篇文章中,football和baseketball天然聚集。
并且有 國王-女王=男人-女人的奇妙性質(zhì)。(不過這個性質(zhì)后來沒有什么研究了,也沒什么太多的應(yīng)用)
word2vec解決了一個關(guān)鍵的問題,就是語義表征,真的有語義。不局限在字面意思。
但是不要太開心,他還沒有解決一個關(guān)鍵的問題,上下文語義。比如play music和play football,同一個play沒辦法區(qū)分開是打球還是彈琴,他就是玩哎。
語言模型
看了剛才word2vec解決的問題和存在什么問題,你一定想知道,他是怎么做的吧。這里其實說來話長,說word2vec的話,要從語言模型說起。
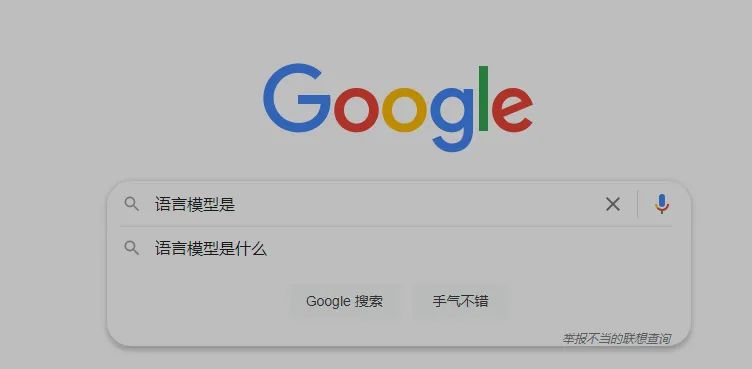
語言模型就是給你一串文本,讓你猜猜后面的詞是什么,以下面的圖為例。不知道是啥的搜索引擎,在我敲出【語言模型是】的時候,給出了【什么】的預(yù)測,這里面就有一定程度語言模型的功勞。
形式化地表達(dá)就是算這個東西 P(wi|w1,w2,...wi?1),其中w是一個詞,根據(jù)輸入的前i-1個詞,預(yù)測第i個詞。
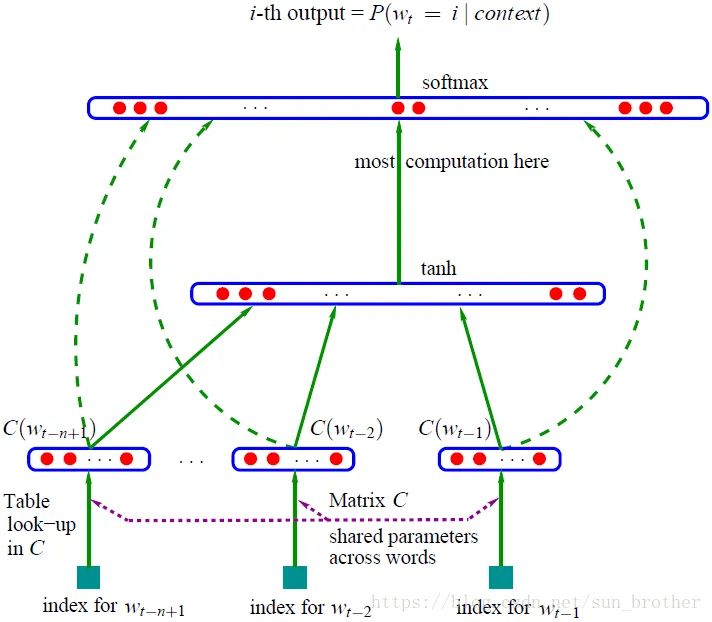
NNLM
語言模型除了類似貝葉斯那種統(tǒng)計的方法,有一個路子在這條線里非常重要,就是神經(jīng)語言模型。
下面那個圖,估計你看得云里霧里。不過你可以發(fā)揮一下聰明才智,要是讓你穿越回20年前,讓你做一個輸入法預(yù)測的工具,你會怎么做?
跨時代的發(fā)明來了,這個東西是Bengio大神發(fā)明的,真的跨時代,現(xiàn)代NLP,都是這個簡單模型的痕跡。
解釋一下,這是一個基本的MLP網(wǎng)絡(luò),其中,最下面藍(lán)色框是詞的id,然后C是共享的矩陣參數(shù),查表能到一個詞的
嵌入?yún)?shù),你這里可以理解為,輸入為詞的onehot表達(dá)的MLP網(wǎng)絡(luò)。結(jié)果是一樣的。
在中間經(jīng)過concat后,走一層tanh激活的MLP。softmax激活,得到最大可能性詞的輸出概率。
其中輸出的softmax維度。和詞表V的大小是一樣的,就是在詞匯空間挑一個最大的詞。
嗯,就是一個很簡單的MLP。
其中關(guān)鍵的一步是,Table look up in C,這一步奠定了word2vec的基礎(chǔ)。
這個東西,每個詞對應(yīng)的參數(shù),掏出來就是詞向量。
只不過在2013年的時候,最后那個詞表對應(yīng)的MLP網(wǎng)絡(luò)實在是太奢侈了,畢竟一個詞表動輒幾十萬,前文就算10個300維的詞向量拼接,
那也是3k*30萬的參數(shù)規(guī)模,實在是太奢侈了。
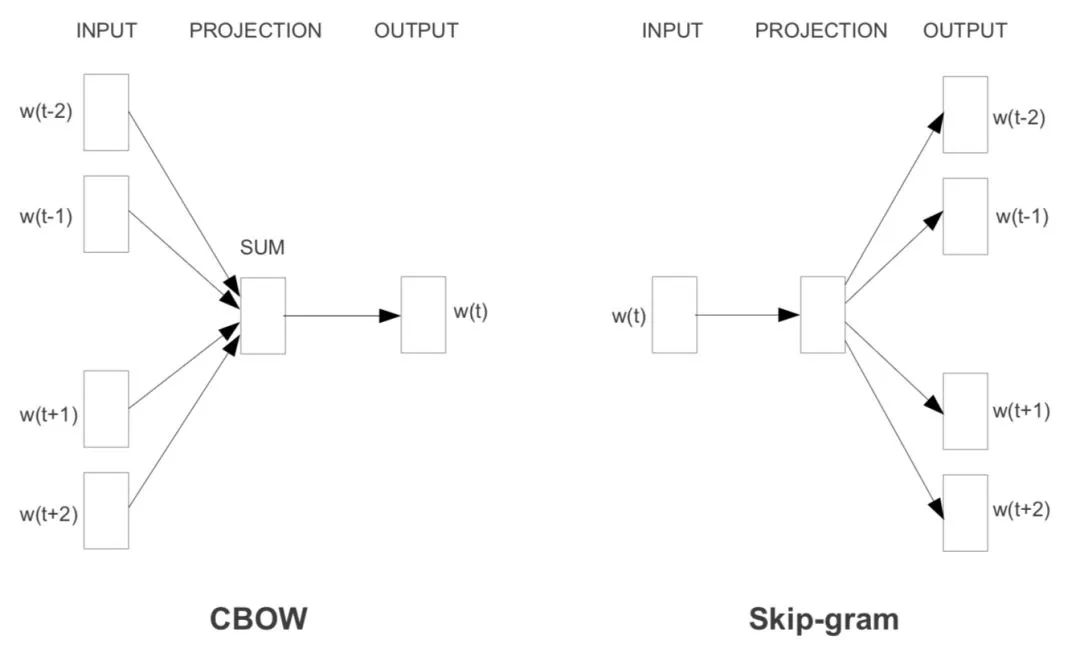
Word2Vec
word2vec解決了這個關(guān)鍵的問題,并且設(shè)計了兩種語言模型的任務(wù)。
直接大放異彩。
word2vec有兩種任務(wù),
分別是CBOW和SkipGram,分別對應(yīng)著上下文預(yù)測中心詞,和中心詞預(yù)測上下文。
如下圖所示。
還有兩種加速技巧,分別是負(fù)采樣和哈夫曼樹,這里篇幅有限,實在是沒辦法展開了。
但是我們要注意這里的重點是,word2vec通過,大規(guī)模無標(biāo)注語料上的自監(jiān)督訓(xùn)練語言神經(jīng)網(wǎng)絡(luò)模型。
把網(wǎng)絡(luò)中的lookup table參數(shù)掏出來,當(dāng)成詞向量的。
這里有兩個不平凡的地方,一個是神經(jīng)語言模型,一個是從網(wǎng)絡(luò)中提出出來的參數(shù)。
NLP的初級預(yù)訓(xùn)練+下游任務(wù)
好了。現(xiàn)在詞向量有了。
等等,似乎還沒有講word2vec怎么用在NLP任務(wù)里。
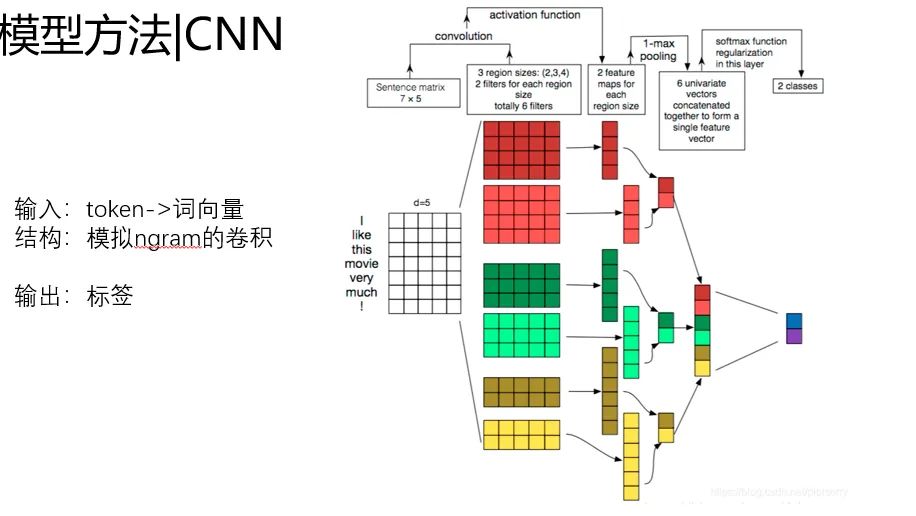
這里以文本分類為例,穿插一點。以CNN做文本分類為例。
輸入是詞的token id,經(jīng)過詞向量層,映射到預(yù)訓(xùn)練好的詞向量,然后下游通過卷積層提取特征。
基本的范式是 詞向量+DNN,詞向量負(fù)責(zé)提升特征表達(dá)能力,DNN負(fù)責(zé)特征提取和預(yù)測。
而在最最初期的時候,基本就是Bow(wordcount vector) + LR這樣的方案。
DNN改進(jìn)了LR,詞向量改進(jìn)了BoW,還沒有從根本上改進(jìn)NLP的范式。
預(yù)訓(xùn)練語言模型
下面是激動人心的時刻,我們先回顧下詞向量的問題。
他還沒有解決一個關(guān)鍵的問題,上下文語義。比如play music和play football,同一個play沒辦法區(qū)分開是打球還是彈琴,他就是玩哎。
于是預(yù)訓(xùn)練語言模型出來了。
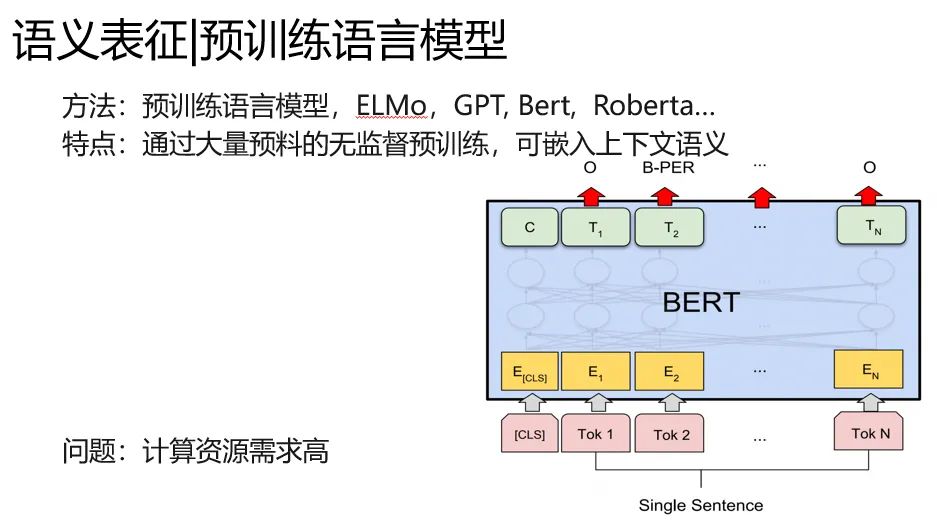
預(yù)訓(xùn)練語言模型,與word2vec不同的是。
1.同樣在語料上進(jìn)行自監(jiān)督訓(xùn)練,我把任務(wù)改造成難度更大的形式,比如完形填空,句子順序?qū)︻A(yù)測等。
2.表征參數(shù)和特征提取組件的一體化。不需要像word2vec那樣掏出一層固定網(wǎng)絡(luò)參數(shù),我預(yù)訓(xùn)練語言模型本身可以實時推斷一個語義表征。
從ELMO說起
預(yù)訓(xùn)練語言模型的開篇之作是ELMO,
源于 Deep contextualized word representation,這是NAACL在2019年的best paper。ELMO的全程是Embedding from Language Models。
ELMO是深層LSTM的堆疊,他最大的改進(jìn)有兩點
1、表征參數(shù)和特征提取組件的一體化,拋棄了靜態(tài)詞向量的方案。
2、提出了兩階段上游預(yù)訓(xùn)練+下游任務(wù)微調(diào)的范式
ELMO不再拆分詞向量和語言模型,用語言模型本身學(xué)好一個單詞的Word Embedding,一步到位。
這樣很巧妙的解決了靜態(tài)詞向量沒有語義的問題。
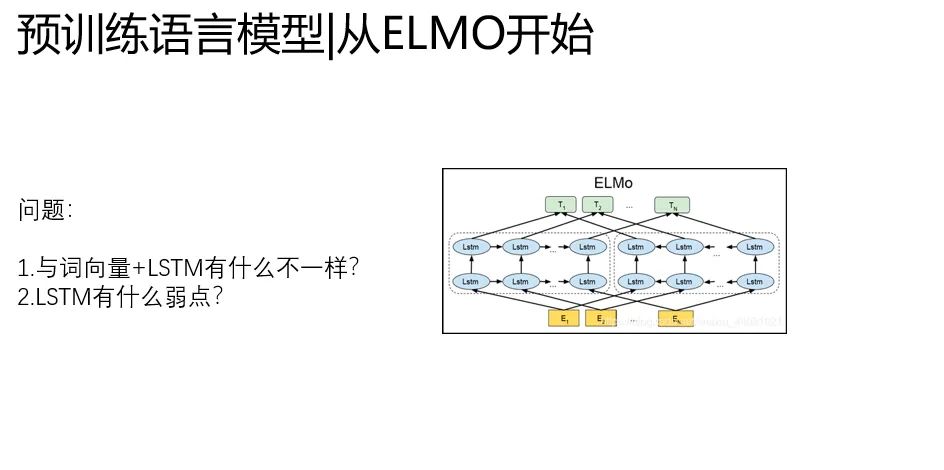
不足之處就是,ELMO還是以LSTM堆疊為基礎(chǔ)的。
而LSTM有一個致命的缺點,無法做到真正的并行,網(wǎng)絡(luò)復(fù)雜度高,在堆疊深的時候,難以快速訓(xùn)練。
這就限制了這個框架的潛力,而Transformer正好解決了這個問題。
Transformer引入
tansformer有個非常好的優(yōu)點,就是可以跑得很快,并且做的很深。
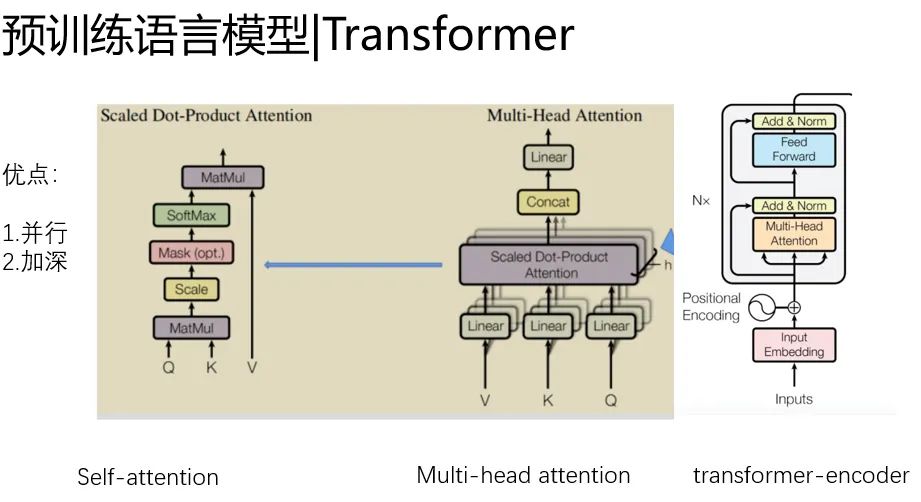
至于是怎么實現(xiàn)的,還要從self-attention說起。self-attention改進(jìn)了CNN那種粗暴的建模局部關(guān)鍵信息的思路,側(cè)重建模元素之間的關(guān)系,
能夠自動捕捉信息的關(guān)鍵和信息的交互,所以被稱為注意力機制。
并且他有個非常好的好處,
1.就是實現(xiàn)以無時序的矩陣乘法為核心,矩陣乘法是GPU最擅長地方,那么我就可以做的很快。
2.可以做的比較深,我沒有LSTM那種超級的復(fù)雜的非線性。我就是簡單的MHA+殘差。
我可以通過每一層,微弱的非線性表達(dá)做深,來提升網(wǎng)絡(luò)容量,又不至于過擬合和難以訓(xùn)練。
這兩個天賦決定了,transformer的潛力無窮,只要你善于挖掘他。而Bert就是充分挖掘了transformer的潛力。
Bert千呼萬喚
重頭戲Bert來了,其實在他之前有個GPT,這個東西,實在是尷尬,理論上GPT才是把transformer和預(yù)訓(xùn)練語言模型結(jié)合起來的最早的方法。
但是Bert通過改進(jìn)預(yù)訓(xùn)練和模型細(xì)節(jié),實在是效果太好了搶了風(fēng)頭,這兩者區(qū)別不太大,不單獨寫GPT了。特別沒有面子。
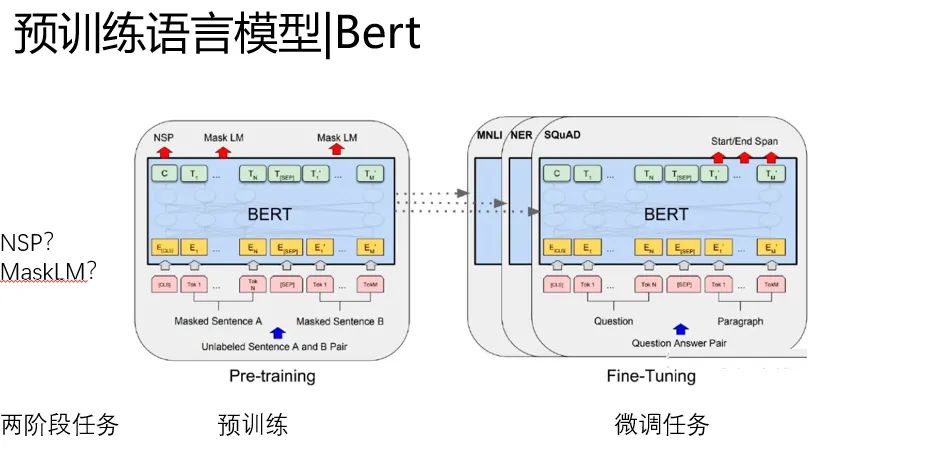
Bert比GPT的改進(jìn)有兩點:
第一、預(yù)訓(xùn)練任務(wù)的改進(jìn),MaskLM(完形填空)的成功應(yīng)用,要比普通的根據(jù)前文預(yù)測下文效果好很多,構(gòu)成了語義上的雙向性。
第二、NSP任務(wù)的引進(jìn)(后來很多模型把他干掉了)
還是沿用了EMLo那種兩階段的微調(diào)范式。
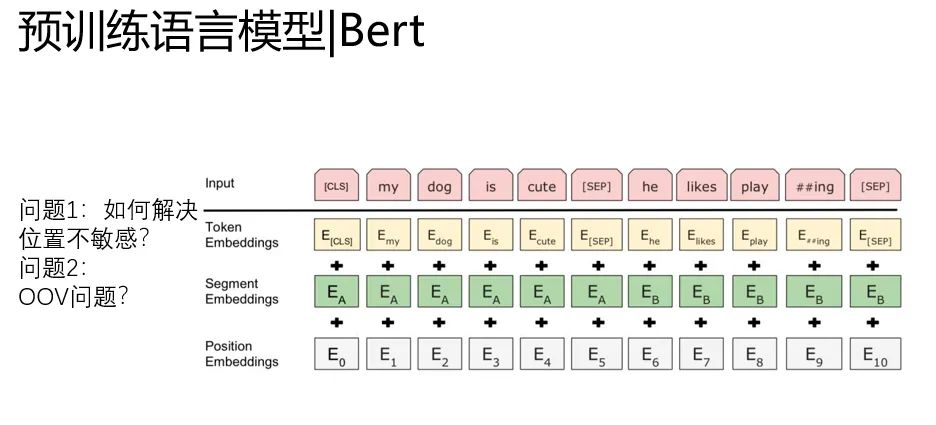
除了預(yù)訓(xùn)練任務(wù)的改進(jìn),Bert里面有兩個關(guān)鍵的地方
1. position embedding引入解決了上下文不敏感的問題
2.word level降級到BPE level(單詞拆分)一定程度解決了OOV的問題。
(2這個思路,在bert沒有出現(xiàn)的時候,我們在Kaggle上2017年 jigsaw第一屆的比賽用過,把word拆成bpe來訓(xùn)練,提分很多)
從NLP到CV的預(yù)訓(xùn)練
好了說了這么多,我們總結(jié)下NLP預(yù)訓(xùn)練技術(shù)的演進(jìn)特點吧。
一、模型從淺變深,從簡單NNLM變化到深層的transformer。
二、預(yù)訓(xùn)練任務(wù)逐漸復(fù)雜,從上下文預(yù)測演進(jìn)成完形填空。
三、任務(wù)從拆分靜態(tài)詞向量向 深度語義向量一體化演進(jìn)。
四、語義從表面向深層,語義從孤立到上下文情景敏感。
好了NLP到這里,我們繼續(xù)翻到CV上。
CV從imagenet說起吧,imagenet是深度學(xué)習(xí)興起的見證者,見證了alexnet,vgg,resenet,densenet一直到現(xiàn)在的基于automl的efficient。
我們對比一下,CV和NLP在初期的預(yù)訓(xùn)練上有什么特點。
CV上,預(yù)訓(xùn)練來的還是比較簡單粗暴的,大家發(fā)現(xiàn),在大的分類數(shù)據(jù)集上訓(xùn)練好的參數(shù),當(dāng)其他的初始化,效果特別好。
這么簡單的思想一直在各種backbone上沿用。
但是這里面有個問題:
1.NLP里的預(yù)訓(xùn)練都是自監(jiān)督的,憑啥你CV可以找人標(biāo)注數(shù)據(jù)。
2.NLP里的預(yù)訓(xùn)練都是側(cè)重輸入本身的表征學(xué)習(xí)的,憑啥你CV拿個分類backbone到處忽悠人?
這兩點,成為了最近CV預(yù)訓(xùn)練任務(wù)改進(jìn)的重大范式。
CNN初步演進(jìn)主要還是集中在網(wǎng)絡(luò)結(jié)構(gòu)上,對于預(yù)訓(xùn)練任務(wù),大家約定俗成的似乎不太重視。
自監(jiān)督的水花:對比學(xué)習(xí)
當(dāng)然,在這里面也有一些水花,比如對比學(xué)習(xí)。他是圖像領(lǐng)域為了解決
“在沒有更大標(biāo)注數(shù)據(jù)集的情況下,如何采用自監(jiān)督預(yù)訓(xùn)練模式,來從中吸取圖像本身的先驗知識分布,得到一個預(yù)訓(xùn)練的模型”。
這一點很關(guān)鍵,在NLP里很自然的。大家使用無標(biāo)注的語料,學(xué)習(xí)詞向量的表達(dá),但是在CV里,就很怪。
有沒有辦法不依賴標(biāo)注數(shù)據(jù),要從無標(biāo)注圖像中自己學(xué)習(xí)知識。
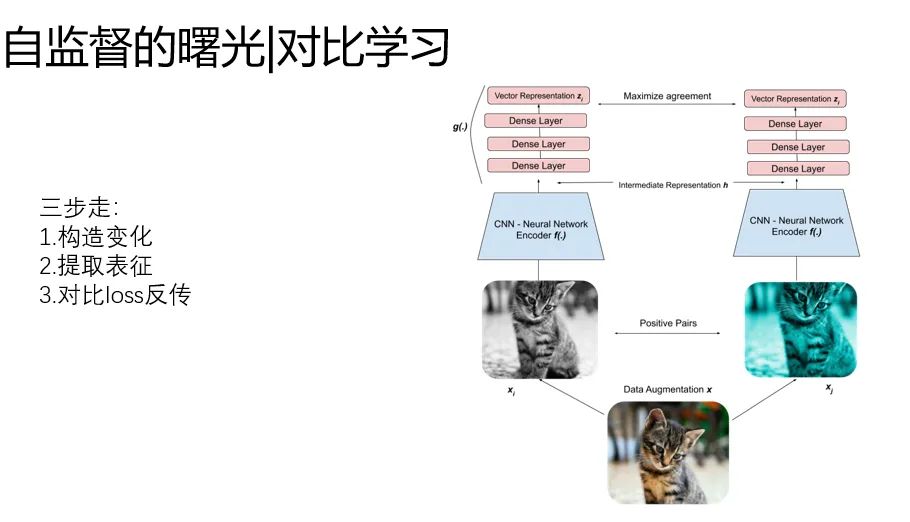
基本套路歸結(jié)成三步走:
1.構(gòu)造輸入的變化:對同一個樣本進(jìn)行增強變換
2.使用backbone提取表征
3.loss:同一個樣本(原始和增強),表征距離相似,不同的樣本,表征的距離拉遠(yuǎn)。
具體的細(xì)節(jié)暫且不展開。
嗯這樣的操作終于解決了不要標(biāo)注的問題,你是一個成熟的CNN了,可以自己學(xué)起來了。不過讓人比較喪氣的是,這種方案的上限不太高,在imagenet能刷到70%就不錯了。
但是,這是一個偉大而美好的嘗試,我們先放一放,看看transformer在CV里折騰出什么花樣來了。
Transformer初見威力:iGPT
與NLP不一樣的地方,圖像作為一種高維、噪聲大、冗余度高的形態(tài),被認(rèn)為是生成建模的難點,這也是為什么過了好幾年,transformer才應(yīng)用到視覺領(lǐng)域。
其實我們想一下 就很離譜。
1. 圖像是連續(xù)的,NLP是離散的,如何解決圖像token輸入的問題?文本是個1D序列,圖像是個2D矩陣,transformer輸入的形式是類序列,因此,如何轉(zhuǎn)化圖片為transformer的輸入很關(guān)鍵。
2.怎么搞定圖像的預(yù)訓(xùn)練呢?還是簡單的在分類上train嗎?似乎沒有夢想。我想像NLP一樣,自監(jiān)督,學(xué)習(xí)上下文,效果還特別好。
3.transfomer的self-attention的復(fù)雜度是O(n^2 d)的。CIFA圖像展開之后的序列長度是 3072,再長的大分辨率圖完全搞不定了。
關(guān)鍵一:為了解決問題1,本文把像素從上到下,從左到右拉平,作為離散的token來輸入transfomer,這里會帶來問題3。后面會講
關(guān)鍵二:為了解決問題2,這個論文借鑒了GPT2的結(jié)構(gòu),預(yù)訓(xùn)練任務(wù)設(shè)計為
1.自回歸任務(wù),根據(jù)前邊的像素,逐個預(yù)測后面的像素
2.掩碼語言模型MLM,類似Bert中的完形填空,只不過是像素級別的
關(guān)鍵三:為了解決問題3,這個論文對圖像進(jìn)行了壓縮操作。分為兩步,第一步是尺度的降采樣,第二步是用Kmeans對顏色降采樣為9bit。這樣就非常小了。
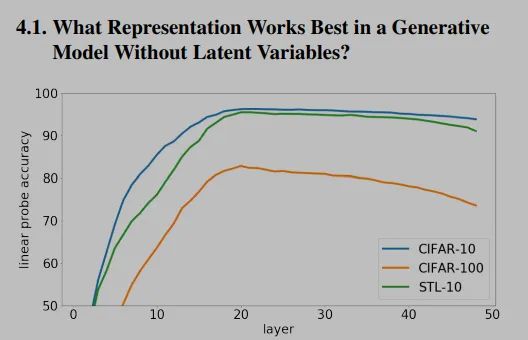
文章中有個小trick就是,第三步。作者發(fā)現(xiàn)最后一層的表征不一定是最好的,結(jié)果最好的可能是中間幾層,所以做了這樣的操作。
這個效果挺好的,在各個數(shù)據(jù)集上刷到了SOTA,但是,他也有幾個問題。
1.iGPT要想達(dá)到同樣的效果,需要的參數(shù)是CNN的2倍多,速度也特別慢,iGPTL在V100上要跑2500天。。。
2.iGPT對于圖片降采樣,損失信息很多,CNN對這個問題不是很敏感
后續(xù)有繼續(xù)的改進(jìn)工作。下面再說。

這張圖展示了TRM不同層向量對于結(jié)果的影響,可以看出來,先上升后下降的,所以中間層效果更好。
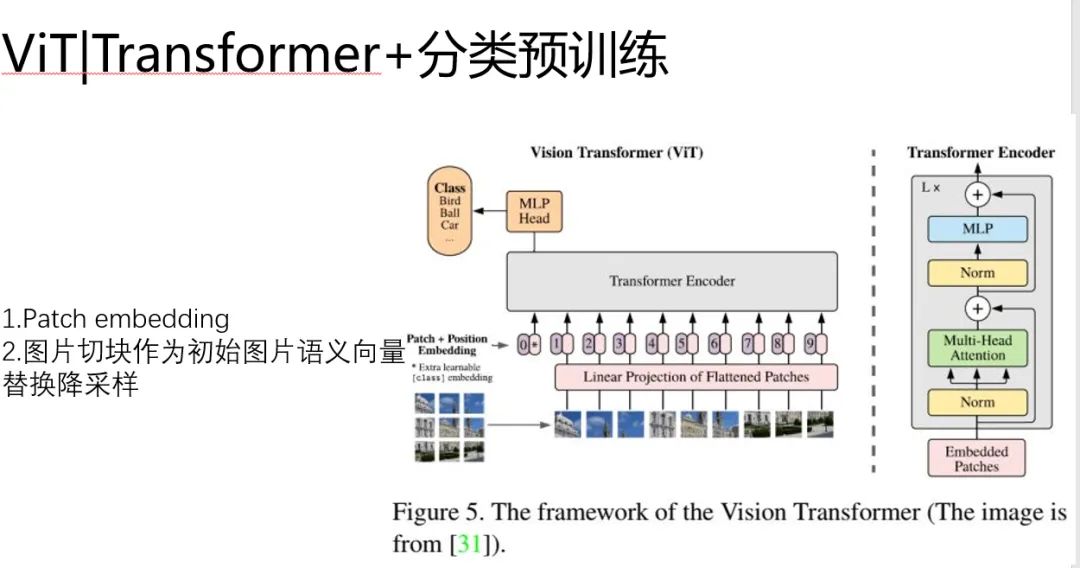
ViT:高效的Transformer分類預(yù)訓(xùn)練
我覺得上面那個iGPT的思路是不錯的,不過看起來就不是很完美的文章,為了預(yù)訓(xùn)練的目標(biāo),降采樣這種操作都出來了。
嗯后來大家改進(jìn)了這個問題。我們看一下ViT吧。
ViT很重要的一點是提出了Path+embedding的思想 替換了降采樣的方式。
另外,Bert里是通過在輸入開頭加【CLS】來實現(xiàn)文本的語義表達(dá)的。如果文本能做到這件事,似乎說明了在我們離圖片語義越來越近了。
ViT具體的做法是:
1.模仿Bert中的position embeding ,標(biāo)記圖片的位置,稱為patch embeddings
2.每一個patch是一個圖形小塊,類比Bert中的 word embedding
ViT通過這樣的方式把圖片塞進(jìn)了transformer,并且沒有壓縮。維持了【CLS】作為語義向量用來分類的特色。
但是,唯一美中不足的是,他是分類任務(wù)進(jìn)行預(yù)訓(xùn)練的(開倒車)。
別忘了我們最初美好的愿景,我們希望像NLP一樣,能從語料庫里面用自監(jiān)督的方式,學(xué)習(xí)到語義信息。
BEiT:Transformer+自監(jiān)督
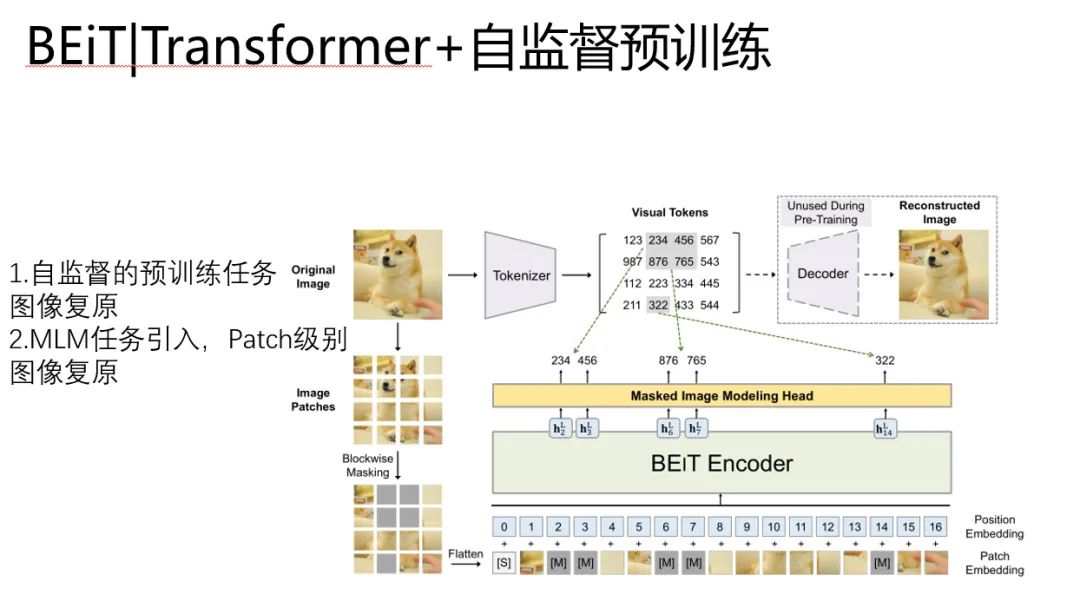
于是更接近Bert的圖像Transformer出現(xiàn)了,他是BEIT。BEiT: BERT Pre-Training of Image Transformers
BEiT繼承了ViT中Patch的做法,改進(jìn)了預(yù)訓(xùn)練任務(wù)。
1、預(yù)訓(xùn)練任務(wù)變成了圖像復(fù)原。
2、Patch級別的MLM引入到預(yù)訓(xùn)練任務(wù)中
搞CV的同學(xué)可能對這個數(shù)字很有疑惑。這個東西是個啥玩意?
他是為了引入圖像復(fù)原的Visual Tokens,對應(yīng)的東西是一個編號,編號里的玩意,是這個位置對應(yīng)的語義向量,
預(yù)訓(xùn)練任務(wù)就是學(xué)習(xí)預(yù)測的 visual tokens ,復(fù)原網(wǎng)絡(luò),這里是通過encoder-decoder的方式來實現(xiàn)的。
嗯這個工作真是承上啟下已經(jīng)接近完美了。
但是還有一個問題,
這個模型訓(xùn)練的時候是分兩步的。
stage1:首先優(yōu)化 dVAE(圖重構(gòu)組件),這個我們叫重構(gòu)損失,通過優(yōu)化 編碼和解碼 ,好讓dVAE 能夠?qū)W習(xí)到更好的隱變量又能更好還原原圖,:
stage2:然后再優(yōu)化 Encoder 和 Masked Image Modeling Head(語義編碼組件),為了能更好的預(yù)測出對應(yīng)的 visual tokens
有沒有什么辦法能像NLP那樣自然呢?完形填空,大道至簡。
有的,kaiming大神MAE呼之欲出。

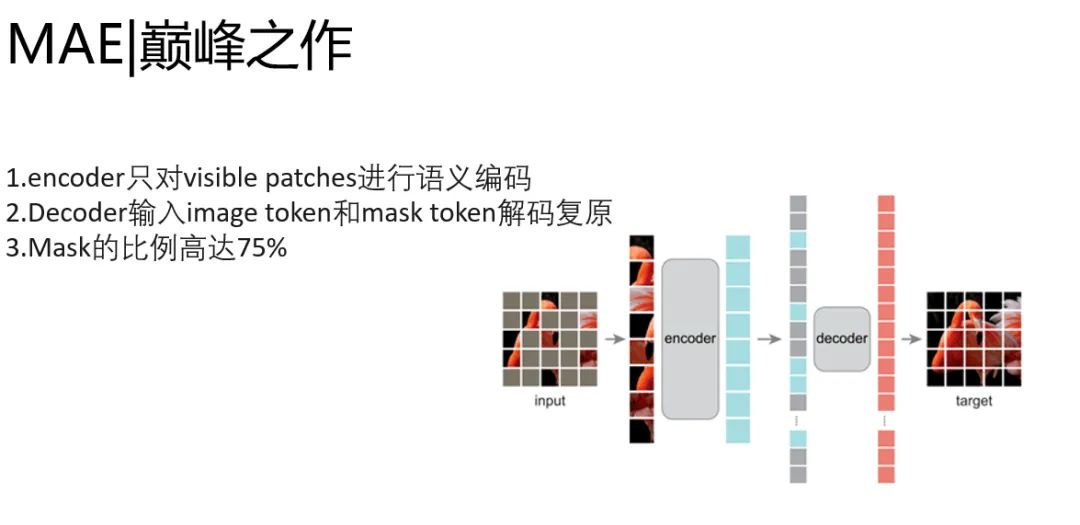
MAE:Transformer+大規(guī)模自監(jiān)督的巔峰之作
大道至簡,MAE秉承了自監(jiān)督預(yù)訓(xùn)練的基因,通過encoder-decoder預(yù)訓(xùn)練框架,encoder輸入只有image的token,decoder同時送入image token和mask token,對patch序列進(jìn)行重建,完成圖片復(fù)原任務(wù)。他改進(jìn)了BEiT兩階段的任務(wù)。去掉了預(yù)訓(xùn)練編解碼器的過程,并且做到了image token和mask token和分離。添加positional embedding來保持patch的位置信息。
encoder只做語義編碼的事情,decoder只做圖像恢復(fù)的事情。簡化的模型,讓速度提升顯著。
在預(yù)訓(xùn)練任務(wù)里面,提速可以讓同樣的時間,過更多的數(shù)據(jù)。而自監(jiān)督,意味著無窮無盡的無標(biāo)注數(shù)據(jù)唾手可得。
我可以把Transformer的潛力壓榨到死。
看一下圖片恢復(fù)的效果,簡直震驚了,這哪里是圖片復(fù)原,這是腦洞打開的自動畫面!

CV中的演進(jìn)總結(jié)
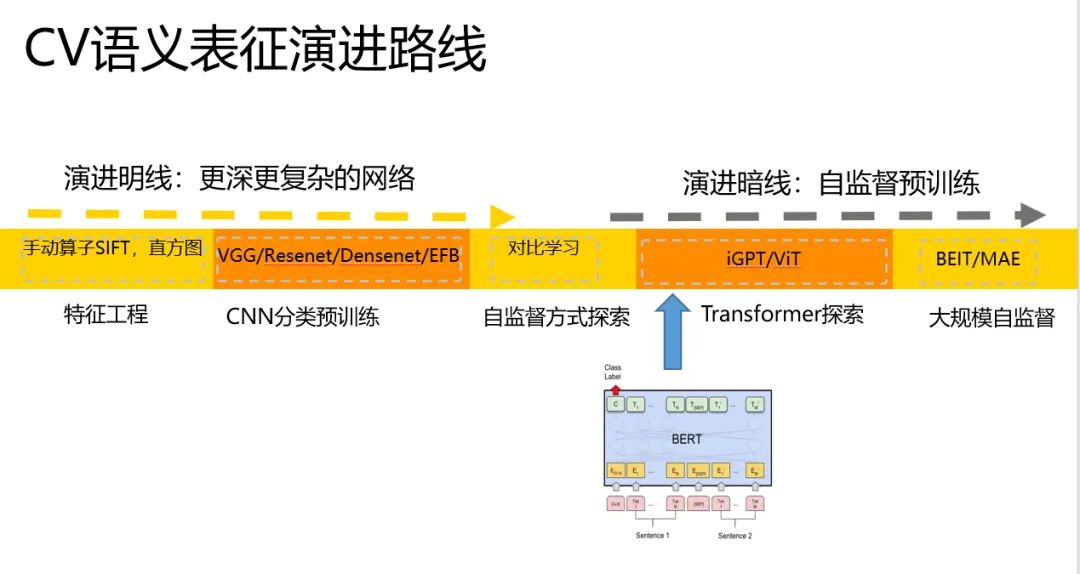
類比下NLP中語義編碼路線的發(fā)展。
我們把他從CV中扒拉出來。
一條線是從CNN到transformer的探索
另一條線是從分類預(yù)訓(xùn)練發(fā)展到大規(guī)模的自監(jiān)督預(yù)訓(xùn)練。
嗯,清晰了。
CV和NLP演進(jìn)的交匯
我們最后一起來看一下吧。
下圖通過三種顏色標(biāo)識了幾個關(guān)鍵的階段,然后箭頭指引了優(yōu)化借鑒和發(fā)展的方向。
要是非要說一條路線的話,那就是為了更好的理解知識表征這一件事。圍繞著這件事,我們在更自動化,設(shè)計學(xué)習(xí)任務(wù),加速模型,提升模型潛力天花板,上做了大量的優(yōu)化工作。
你都看到了這了,一定要分享給你的同學(xué)同事,一起來學(xué)習(xí)下吧~
往期精彩回顧 本站qq群955171419,加入微信群請掃碼: