
多目標跟蹤:視覺聯(lián)合檢測和跟蹤
國內頭部以自動駕駛全站技術為主線的交流學習社區(qū)(感知、歸控等),包含大量前沿論文解讀、工程實踐(源代碼)、視頻課程,熱招崗位。歡迎加入!
點擊上方“
邁微AI研習社
”,選擇“
星標★
”公眾號
重磅干貨,第一時間送達
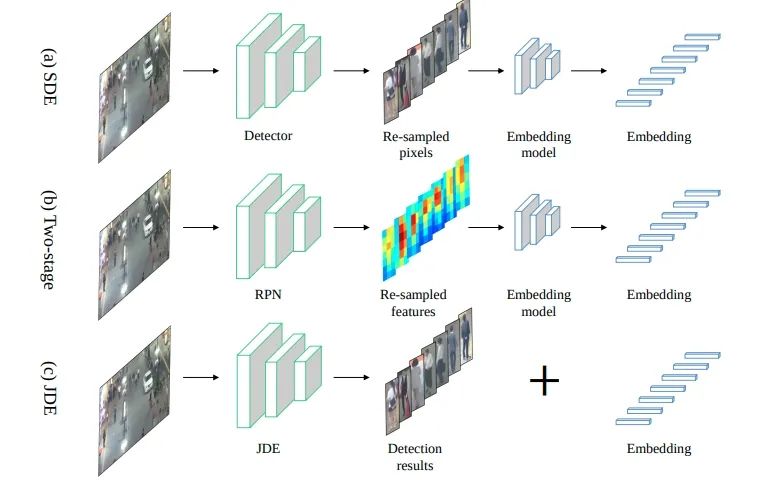
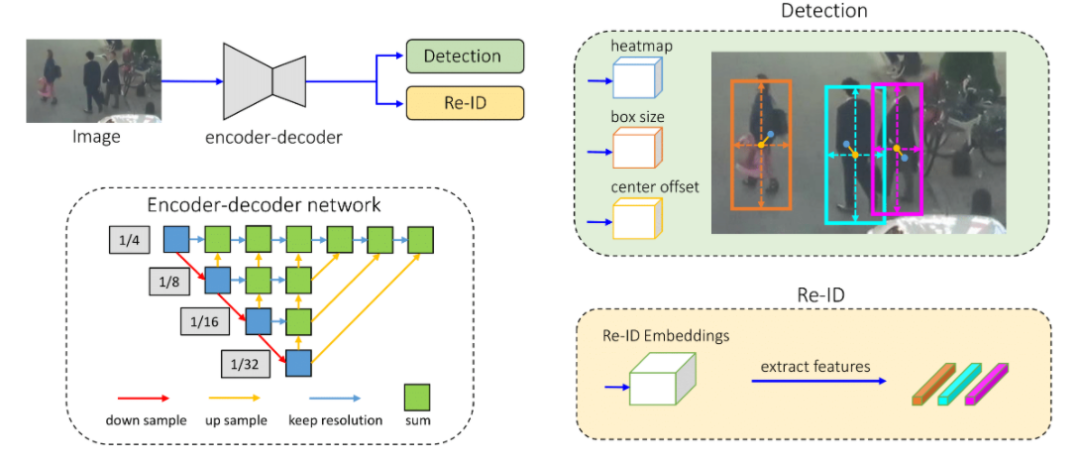
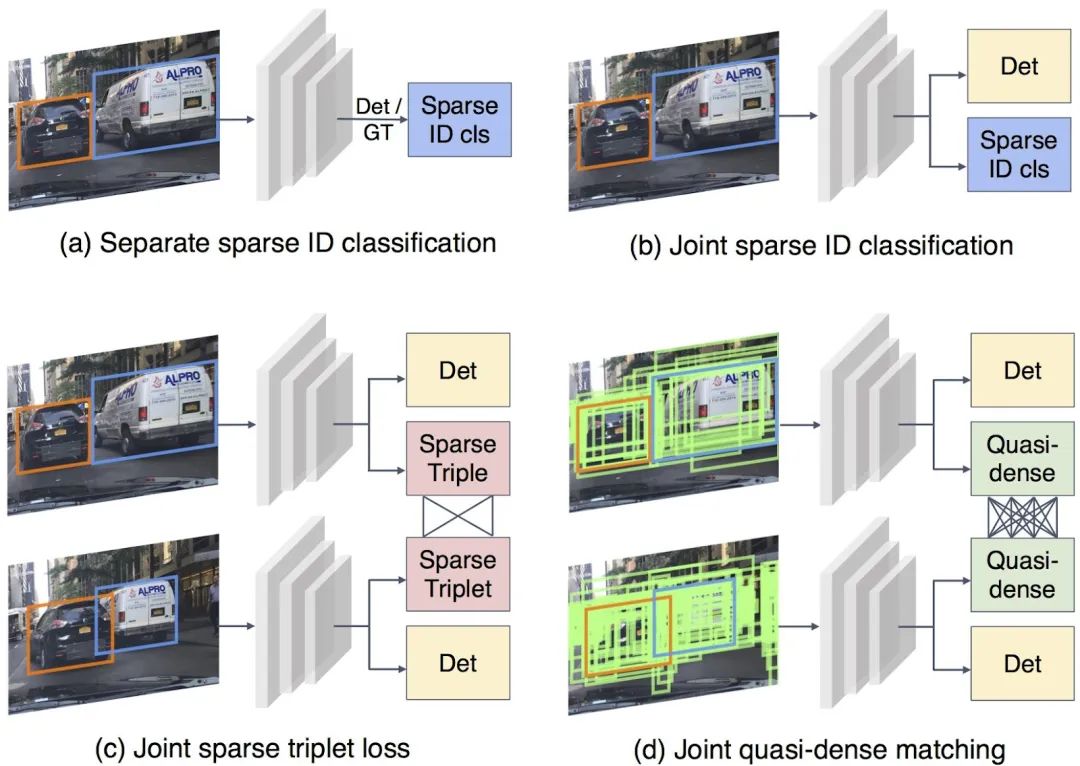
Joint detection and tracking (同時實現(xiàn)檢測和跟蹤)是Multiple Object Tracking(MOT)的一個重要研究方向。Multiple Object Tracking,多目標跟蹤, 主要包括兩個過程(Detection + ReID,Detection 是檢測出圖像或者點云中的目標框從而獲取目標的位置,而ReID是將序列中同一個目標關聯(lián)起來) ,因此一方面這涉及到時間和空間的特征學習和交互,另一方面也涉及到檢測和重識別(特征的embedding)的多任務學習,導致MOT任務。目前MOT可以分成三大類(如圖一所示):
-
SDE(Separate Detection and Embedding), 或者稱為Tracking-by-detection, 該類的想法也非常直接,將多目標跟蹤這個任務進行拆分,先進行單幀的目標檢測得到每幀的目標框,然后再根據幀間同一目標的共性進行關聯(lián)(association),幀間的關聯(lián)的重要線索包括appearance, motion, location等,典型的代表算法包括SORT和Deep SORT。這類算法的優(yōu)點是簡單,將Detection和ReID解耦分開解決。例如上述的SORT和Deep SORT的檢測器可以不受到限制,使用SOTA的檢測方法,在目標關聯(lián)上使用卡爾曼濾波+匈牙利匹配等傳統(tǒng)方法。但是缺點也很明顯,就是解耦開無法促進多任務學習,特別受限目標關聯(lián)階段的方法而且依賴目標檢測算法,也只能處理比較簡單的場景。
-
Two-Stage方法也可稱之為Tracking-by-detection,只不過其中的ReID變成第一階段網絡學習得到的ROI特征然后在第二階段進行embedding特征的學習,相對于第一類進步點在于 appearance特征 可由第一階段獲得,但是兩階段方法的詬病是inference比較慢,而且我覺得detection特征和embedding特征還是沒有構成多任務學習的狀態(tài)。
-
JDE(Joint Detection and Embedding)或者是Joint detection and tracking 這類算法是在一個共享神經網絡中同時學習Detection和Embedding,使用一個多任務學習的思路共享特征學習網絡參數并設置損失函數,從而可以實現(xiàn)Detection和ReID的交互和促進,然后由于屬于一階段模型,因此在速度上是可以達到實時,所以是可以保證應用的。因此是Joint detection and tracking 這類算法我們關注的重點。
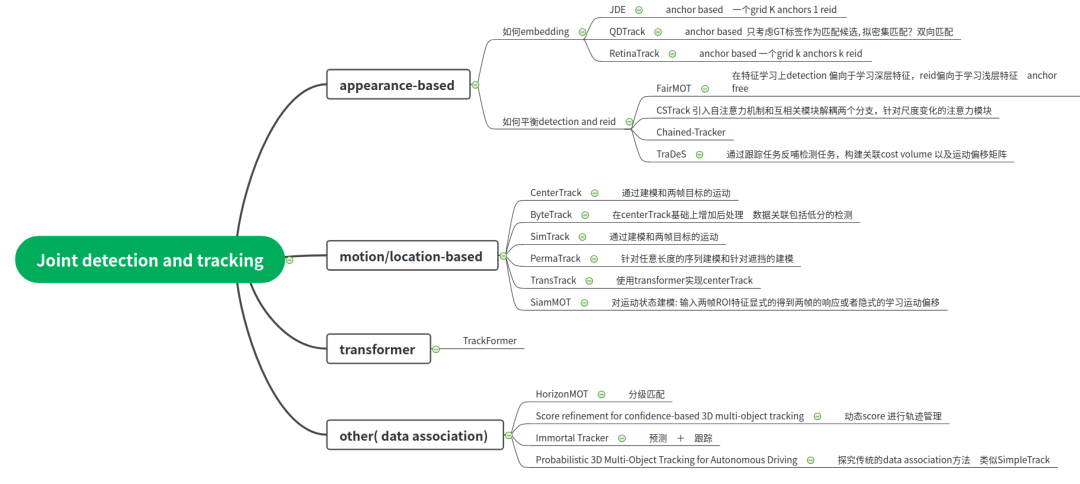
同時為了實現(xiàn)Joint detection and tracking,需要解決如下幾個問題(也包括一些思路):
-
多任務學習 中如何同時輸出檢測和幀間的數據關聯(lián), 特別是數據關聯(lián)如何實現(xiàn)?損失函數如何設計?
-
目前看到的方案中主要分成兩大類,一種是通過motion based 例如一個head實現(xiàn)輸出目標的速度或者是目標的偏移,然后通過位置關聯(lián)實現(xiàn)(CenterTrack系列)。另外一種是appearance based 在新增加的heading中通過對比學習得到各目標在特征上的差異, 但是匹配還是通過計算相似度并且二分匹配,也不是真正意義上的Joint detection and tracking。
-
-
網絡設計上如何實現(xiàn)detection和embedding的聯(lián)合訓練?
-
Detection和ReID模型的學習是存在不公平的過度競爭的,這種競爭制約了兩個任務(檢測任務和 ReID 任務 )的表示學習,導致了學習的混淆。具體而言,檢測任務需要的是同類的不同目標擁有相似的語義信息(類間距離最大),而ReID要求的是同類目標有不同的語義信息(類內距離最大)。
-
需要將對embedding分支和現(xiàn)detection分支分開,以及可以在embedding內部進行注意力機制的建模。(CSTrack里面引入自相關注意力機制和互相關權重圖)
-
淺層特征對于ReID任務更有幫助,深層特征對于Detection任務更有幫助。(FairMOT)
-
Detection和Tracking模型的相互促進,如何做到Detection幫助Tracking, Tracking反哺Detection(TraDeS構建CVA和MFW分別進行匹配和特征搬移,該部分和多幀的特征學習相似,利用學習到的運動信息搬移歷史特征到當前幀,輔助當前幀的目標檢測)
-
在圖像里目標較大的尺度變化也對embedding的學習有很大的影響,之前embedding的學習是固定大小的proposal區(qū)域。(CSTrack里引入尺度感知注意力網絡)
-
-
如何進行多幀的學習,時間和空間的交互?
-
目前大部分的網絡輸入的一幀或者兩幀,學習到的數據關聯(lián)都是短時的,如何拓展到任意多幀,例如使用convGRU的方法等(可以參見Perma Track)。
-
如何處理遮擋?遮擋包括局部遮擋以及全部遮擋,尤其是全部遮擋,一方面需要根據多幀來將歷史的狀態(tài)進行推移,另一方面也需要處理appearance特征和motion特征的關系,并且在損失函數設計上如何處理Detection和ReID不一致的地方。
-
需要同時cover 住short-range matching和long-range matching, 也就是分成正常情況下的matching, 短時間的遮擋和長時間的遮擋如何對特征的利用。
-
對運動信息的顯示建模,例如學習特征圖的運動信息(或者場景流之類的)也是多幀融合的一種方案,同時該運動信息也是幀間目標關聯(lián)的依據。
-
-
appearance, motion, location特征如何學習和使用?
-
appearance特征對于long-range matching比較有用,但是沒法處理遮擋,可能會帶來干擾。
-
motion和location特征沒有那么準確,特別進行l(wèi)ong-range matching, 但是在short-range matching可以發(fā)揮作用,而且在被全部遮擋的情況下可以發(fā)揮作用。
-
-
anchor-based vs anchor-free
-
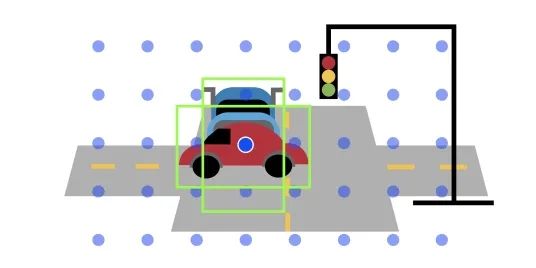
此部分其實也是屬于網絡設計的一部分,目前的Joint detection and tracking都是基于detection的框架,而detection分成anchor-based與anchor-free兩部分,目前而言,使用anchor-based的方法進行建模的包括JDE以及RetinaTrack,例如JDE進行訓練的時候一個grid分成很多個anchor, 但是分成1個track id, 這個造成遮擋的id匹配的模棱兩可,RetinaTrack是每一個anchor分配一個track id
-
anchor free使用點攜帶所有特征進行分類或者位置回歸,如果需要學習embedding只是加上一個分支,模棱兩可更小一點,所以建議使用anchor-free方法。
-
通過歷史heatmap和當前heatmap構成存在置信度(SimTrack)
-
通過雙向匹配(QDTrack)
-
依照傳統(tǒng)的方法(CenterTrack系列)
-
分類(部分方法)
JDE: Towards Real-Time Multi-Object Tracking
-
paper: https://arxiv.org/abs/1909.12605v1
-
code: https://github.com/Zhongdao/Towards-Realtime-MOT
JDE同時輸出了檢測框和embedding信息。后面通過卡爾曼濾波和匈牙利算法進行目標的匹配。總的來說,還是分為檢測和匹配雙階段。
另外屬于anchor based,而且一個grid K anchors 1 reid,這是很大的缺點。
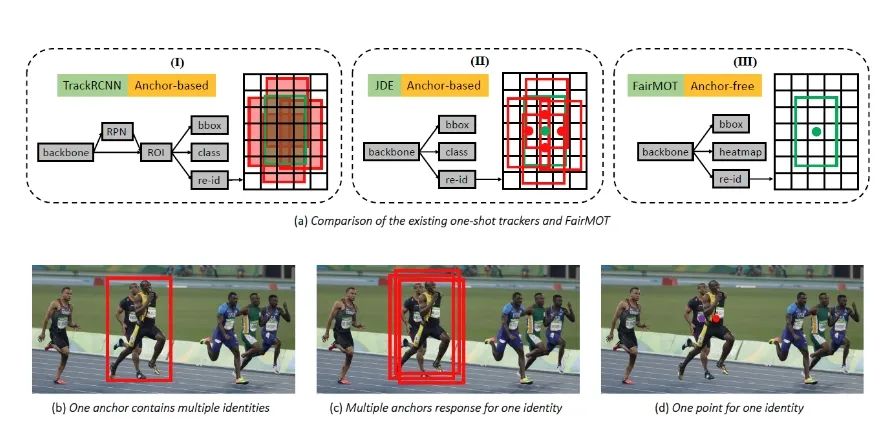
FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking
paper: https://arxiv.org/abs/2004.01888 code: https://github.com/ifzhang/FairMOT- A simple baseline for one-shot multi-object tracking
- 行人性能比較好 tracking = detection + re-id 單類別?
- 在方法上基于anchor的方法會使ReID的方法帶來壞處 ,涉及到遮擋目標id分配問題
- 淺層特征對于使ReID會有益處,而且需要將detection和re-id分支分開
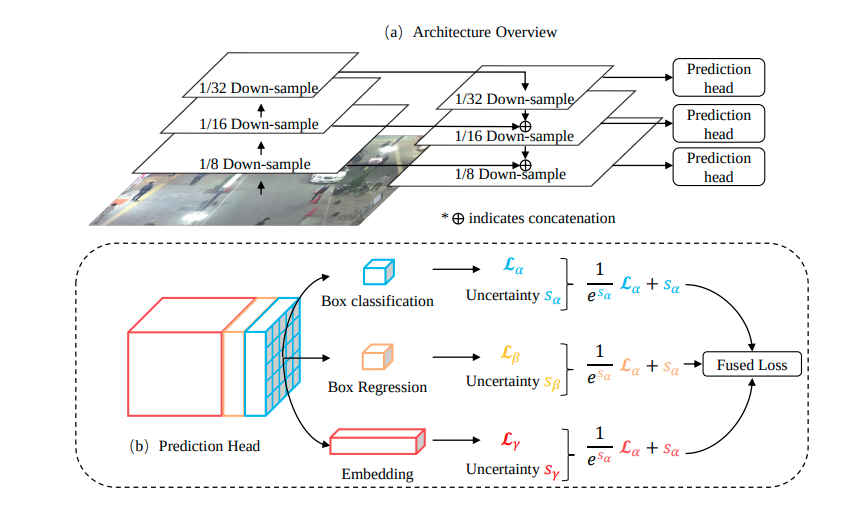
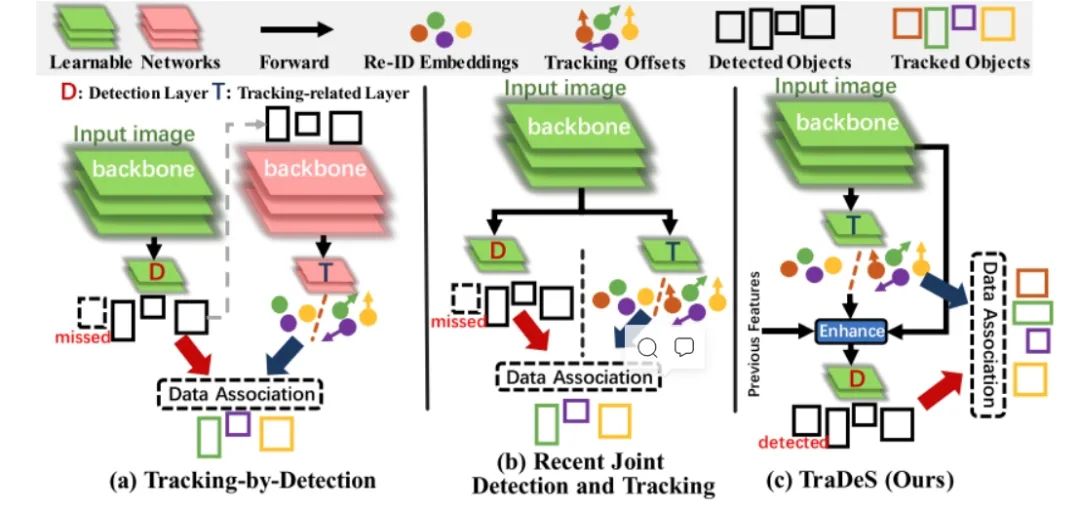
特別說明的是針對3d目前主要是motion/location-based 方法,這些對于3d joint detection and tracking首先采用anchor-free框架容易嵌套到我們的框架里,另外簡單高效。特別是CenterTrack/SimTrack系列(包括CenterTrack, ByteTrack, SimTrack以及PermaTrack)。其中CenterTrack在原有anchor-free detection方法基礎上增加一個位置偏移分支用于匹配,ByteTrack在此基礎上為了增加匹配的成功率,進行級聯(lián)匹配方式,PermaTrack對遮擋問題進行建模以提高long-range tracking能力(包括輸入任意長度的幀)。從上述可以看到該框架仍然有一些改進點:1.對motion/location特征用的比較多,對于appearance特征發(fā)揮的作用滅有那么大。2.從實驗也可以看到tracker management做的不是特別好, tracker id 容易切換,應該也是因為匹配的時候多用于motion/location特征的原因,有可能是對多幀建模較弱的原因(CenterTrack輸入只有兩幀,而且inference用的歷史信息不足造成的,而且training和inference如何做到統(tǒng)一) 3. 遮擋情況下如何可以處理的更好,特征利用上一方面需要將歷史特征搬到當前幀(如何搬,顯式預測速度還是ConvGRU隱式的方式),損失函數如何設計,畢竟detection看不到reid需要。
下文對一些方法進行簡單/詳細的說明(詳細說CenterTrack系列方法)。其中SimTrack可參見
Exploring Simple 3D Multi-Object Tracking for Autonomous Driving論文閱讀
CenterTrack: Tracking Objects as Points
paper: https://arxiv.org/abs/2004.01177 code: https://github.com/xingyizhou/CenterTrack 輸入是當前幀圖片和前一幀圖片以及前一幀的heatmap(在訓練的時候是由真值產生, 當然為了模擬測試的情況也加入一些噪聲, 在測試的時候由檢測框渲染生成)。預測當前幀的檢測結果,然后使用當前幀的檢測結果以及當前幀到上一幀的偏移。在預測的時候通過該偏移將目標中心點引入到上一幀和上一幀進行關聯(lián)(使用貪婪匹配算法)

-
跟蹤條件檢測(Tracking-conditioned detection)利用多輸入上一幀以及輸入上一幀渲染出的heatmap來作為歷史信息的輸入
-
時間關聯(lián)( Association through offsets)通過多輸出偏移來進行目標ID的匹配
數據增強方法:真值生成heatmap增加噪聲(數量不定的missing tracklets、錯誤定位的目標以及還可能有誤檢的目標存在),在輸入的兩幀上時間間隔不一定是連續(xù)的,從而規(guī)避掉模型對視頻幀率的敏感性。(比較重要)
缺點:都是兩幀的匹配,如果出現(xiàn)遮擋或者離開檢測區(qū)域則可能會引起ID的切換和跳變,沒有考慮如何在時間上有較大間隔的對象重新建立聯(lián)系。此問題也是需要面對的問題。
ByteTrack: Multi-Object Tracking by Associating Every Detection Box
- paper: https://arxiv.org/abs/2110.06864
- code: https://github.com/ifzhang/ByteTrack

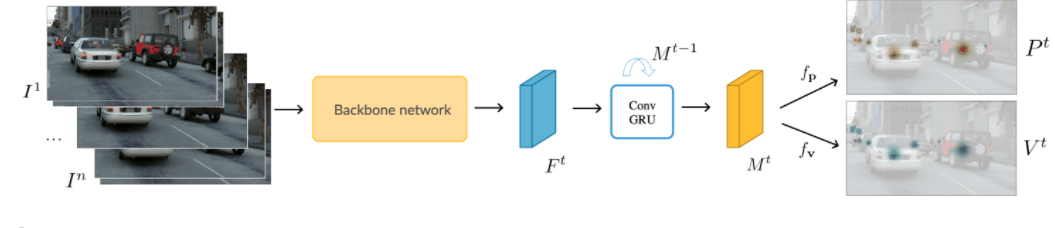
Perma Track: Learning to Track with Object Permanence
- paper: https://arxiv.org/abs/2103.14258
- code: https://github.com/TRI-ML/permatrack
- 端到端和joint object detection and tracking that operates on videos of arbitrary length。
- 怎么對不可見的目標的軌跡通過在線的方式進行學習。
-
怎么彌補合成數據和真實數據之間的gap
- 合成數據與真實數據的差異性?
- 通過同時訓練合成數據(Parallel Domain(PD) simulation platform產生)和真實數據,然后將不可見數據只在合成數據上訓練發(fā)現(xiàn)可以提高模型的性能。
其他一些經典的Track方法
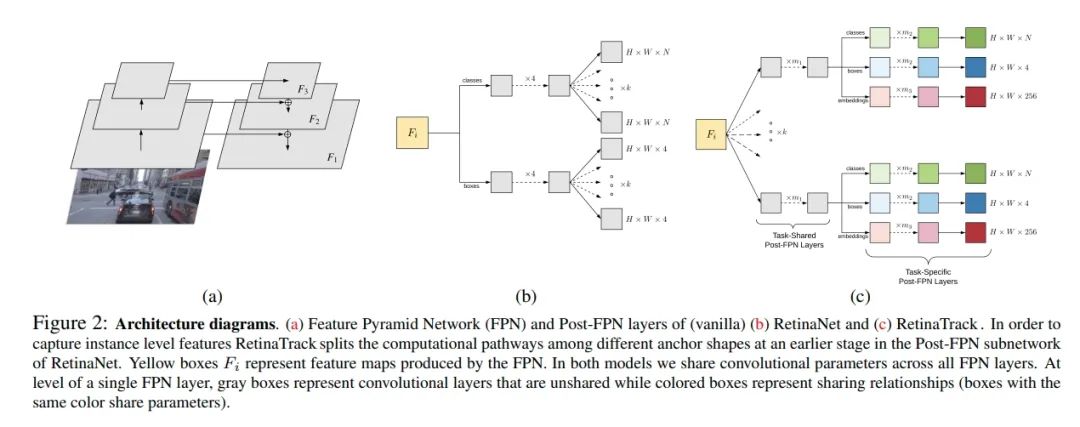
RetinaTrack: Online Single Stage Joint Detection and Tracking
paper: https://arxiv.org/abs/2003.13870 code: 和上述方式, 在RetinaTrack的基礎上,將embedding分支和detection分支分開并且采用anchor-based的方式,每一個anchor都有對應的embedding特征(方便處理遮擋)。 embedding使用采樣三組對比樣本的批處理策略的三元組損失, 只監(jiān)督和gt匹配的上的?
QDTrack:Quasi-Dense Similarity Learning for Multiple Object Tracking
-
paper: https://arxiv.org/abs/2006.06664
-
code: https://github.com/SysCV/qdtrack
-
現(xiàn)有的多目標跟蹤方法僅將稀疏地面真值匹配作為訓練目標, 而忽略了圖像上的大部分信息區(qū)域 。在本文中提出了準稠密相似性學習,它對一對圖像上的數百個區(qū)域建議進行稠密采樣以進行對比學習。作者提出的QDTrack密集匹配一對圖片上的上百個感興趣區(qū)域,通過對比損失進行學習參數,密集采樣會覆蓋圖片上大多數的信息區(qū)域。通過對比學習,一個樣本會被訓練同時區(qū)分所有的Proposal,相較于只使用真值標簽來訓練監(jiān)督,更加的強大且增強了實例的相似度學習。對于消失軌跡的處理,會將背景作為一類,從而進行雙向softmax增強一致性。
-
當前幀和上一幀的雙向匹配可以實現(xiàn)軌跡的管理。
-
擬密集匹配其他算法不是這樣做的?
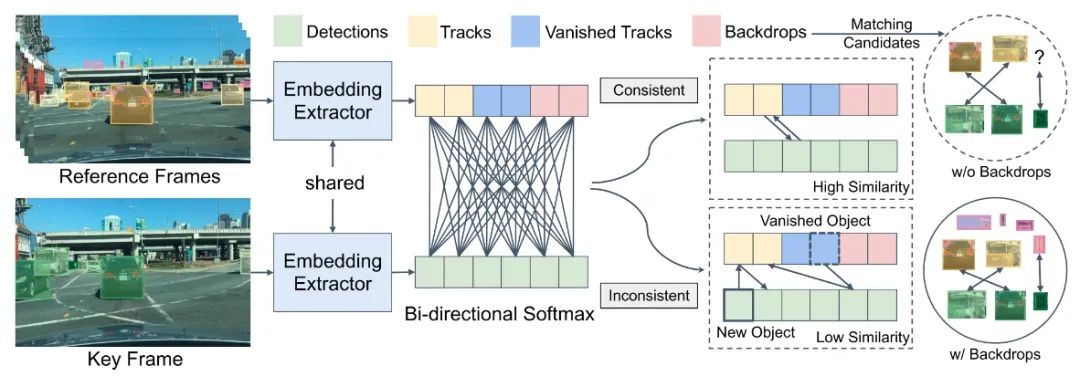

其中保留低置信度的目標?
TraDeS:Track to Detect and Segment: An Online Multi-Object Tracker
-
paper: https://arxiv.org/abs/2103.08808
-
code: https://github.com/JialianW/TraDeS
-
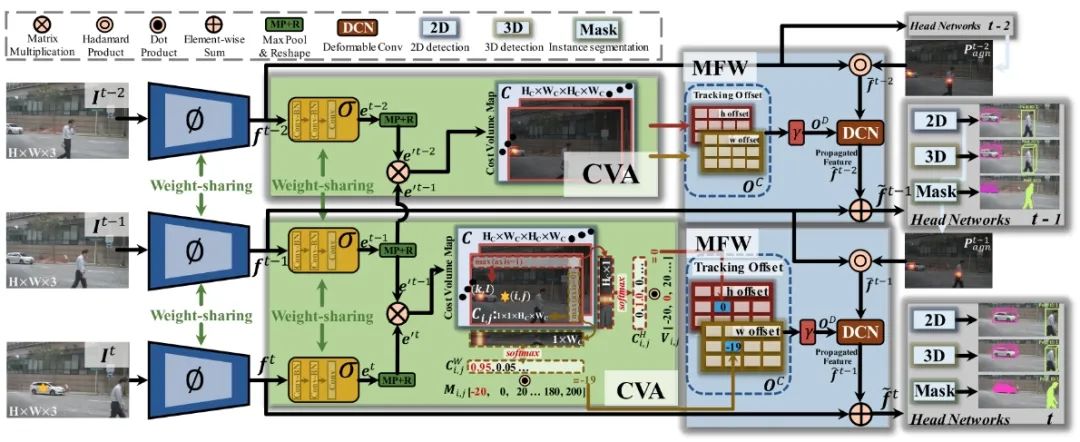
TraDeS通過cost volume來推斷目標跟蹤偏移量,該cost volume用于傳播前幀的目標特征,以改善當前目標的檢測和分割,其實可以理解為一個關聯(lián)代價矩陣,主要由關聯(lián)模塊(CVA)和一個運動指導的特征變換模塊(MFW)構成。CVA模塊通過backbone提取逐點的ReID embedding特征來構建一個cost volume,這個cost volume存儲兩幀之間的embedding對之間的匹配相似度。繼而,模型可以根據cost volume推斷跟蹤偏移(tracking offset),即所有點的時空位移,也就得到了兩幀間潛在的目標中心。跟蹤偏移和embedding一起被用來構建一個簡單的兩輪長程數據關聯(lián)。之后,MFW模塊以跟蹤偏移作為運動線索來將目標的特征從前幀傳到當前幀。最后,對前幀傳來的特征和當前幀的特征進行聚合進行當前幀的檢測和分割任務。
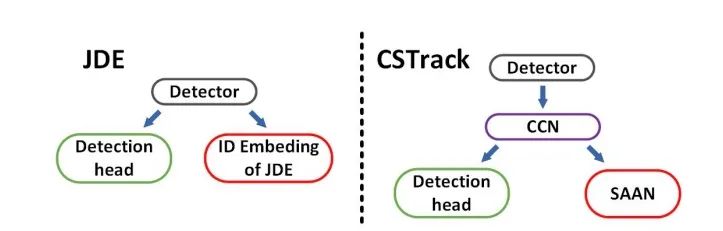
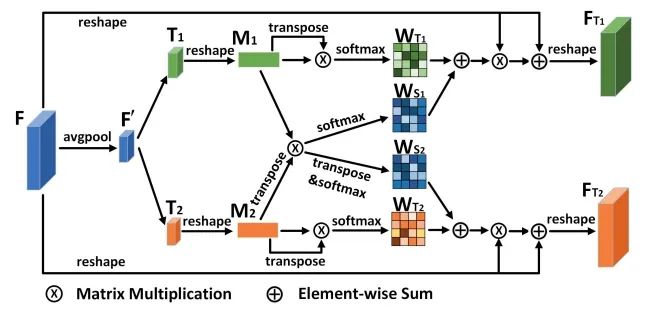
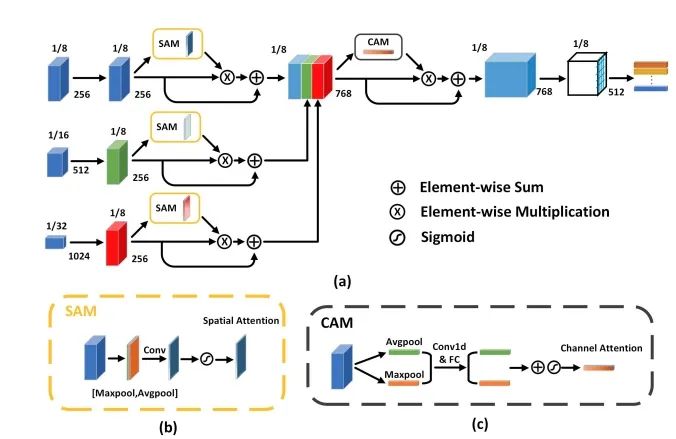
CSTrack:Rethinking the competition between detection and ReID in Multi-Object Tracking
paper: https://arxiv.org/abs/2010.12138 code: https://github.com/JudasDie/SOTS 論文提出了一種新的互相關網絡(CCN)來改進單階段跟蹤框架下 detection 和 ReID 任務之間的協(xié)作學習。作者首先將 detection 和 ReID 解耦為兩個分支,分別學習。然后兩個任務的特征通過自注意力方式獲得自注意力權重圖和互相關性權重圖。自注意力圖是促進各自任務的學習,互相關圖是為了提高兩個任務的協(xié)同學習。而且,為了解決上述的尺度問題,設計了尺度感知注意力網絡(SAAN)用于 ReID 特征的進一步優(yōu)化,SAAN 使用了空間和通道注意力,該網絡能夠獲得目標 不同尺度的外觀信息,最后 不同尺度外觀特征融合輸出即可。
Immortal Tracker
paper: https://arxiv.org/abs/2111.13672 code: https://github.com/ImmortalTracker/ImmortalTracker 目前過早的軌跡終止是目標ID切換的主要原因,因此本方法使用簡單的軌跡預測希望保留長時間的軌跡,軌跡預測方法就是簡單的卡爾曼濾波 實現(xiàn)predict-to-track范式, 在匹配(3D IOU or 3D GIOU)的時候如果當前檢測結果和預測可以匹配的上則更新軌跡,如果沒有匹配的上則更新預測值。 思考:正常的跟蹤不都是這個流程嗎?

HorizonMOT:1st Place Solutions for Waymo Open Dataset Challenges -- 2D and 3D Tracking
- paper: https://arxiv.org/abs/2006.15506
- 運動模型
- 表觀模型
- 數據關聯(lián)(級聯(lián)匹配)
Probabilistic 3D Multi-Object Tracking for Autonomous Driving
paper: https://arxiv.org/abs/2012.13755 code: https://github.com/eddyhkchiu/mahalanobis_3d_multi_object_tracking 使用馬氏距離而不是3D IOU可以防止小目標(行人等)無法匹配 卡爾曼濾波參數使用訓練集的統(tǒng)計值 使用貪心算法進行匹配而不是匈牙利算法Score refinement for confidence-based 3D multi-object tracking
paper: https://arxiv.org/abs/2107.04327 code: https://github.com/cogsys-tuebingen/CBMOT 處理軌跡得分更新的問題,如果軌跡和當前檢測結果匹配上了則該軌跡認為是比之前的軌跡得分和檢測結果得分都大,如果沒有匹配上則認為軌跡得分需要處于衰減狀態(tài)。然后基于此設計一系列的函數來更新軌跡得分,創(chuàng)新點比較一般。但是在很多榜單上排名很高,是個有用的trick。
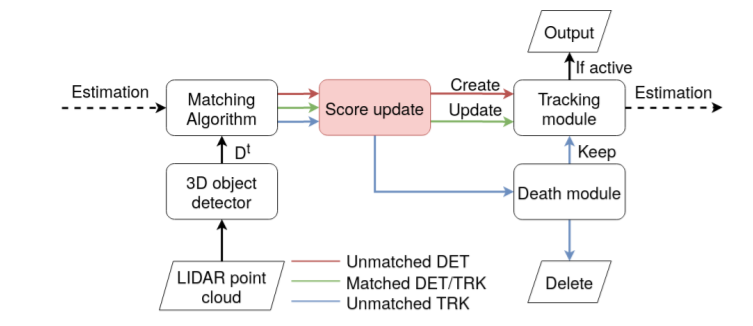
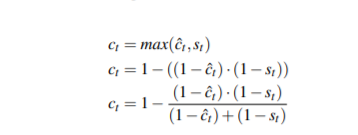
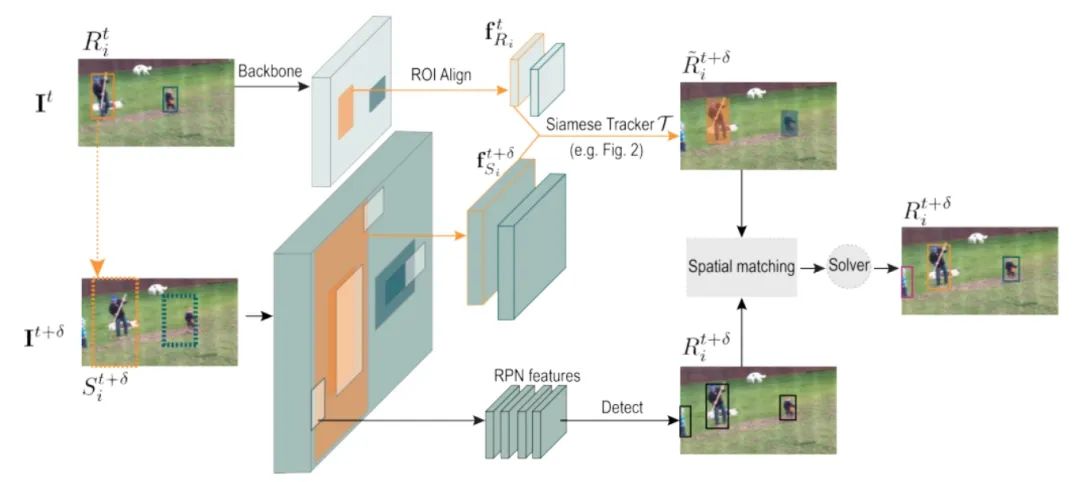
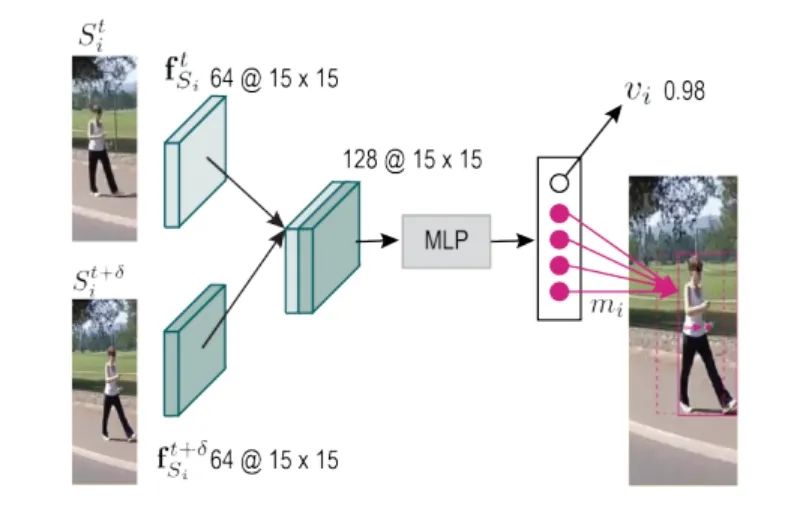
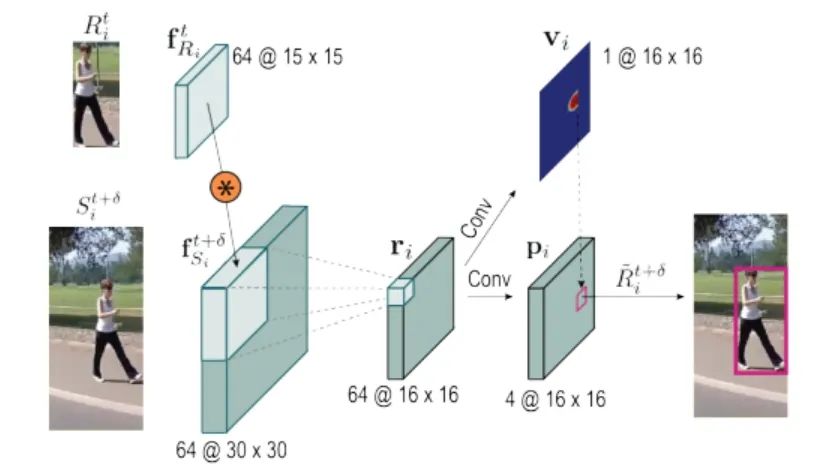
SiamMOT:Siamese Multi-Object Tracking
paper: https://arxiv.org/abs/2105.11595 code: https://github.com/amazon-research/siam-mot 孿生跟蹤器根據其在一個局部窗口范圍內搜索對應的實例, 然后獲得當前幀和歷史幀的特征
TransTrack: Multiple Object Tracking with Transformer
paper: https://arxiv.org/abs/2003.13870 code: https://github.com/PeizeSun/TransTrack 利用transfomer實現(xiàn)跟蹤,類似于centerTrack,利用兩個key-query學習檢測和到上一幀的偏移
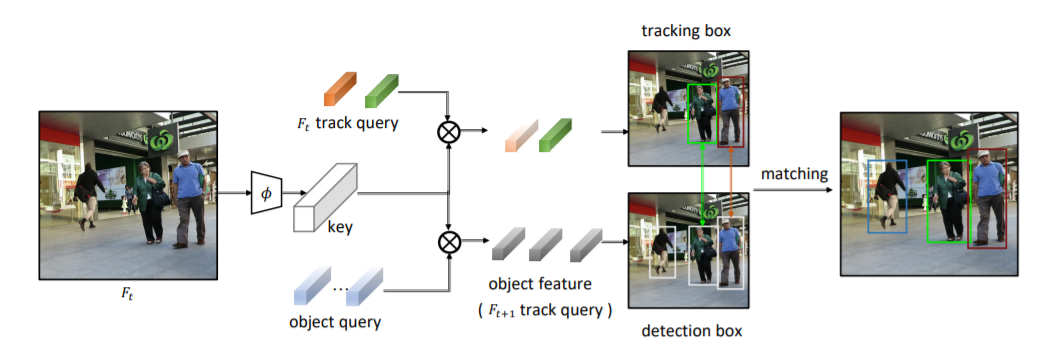
Reference:
-
https://github.com/luanshiyinyang/awesome-multiple-object-tracking
-
https://github.com/JudasDie/SOTS
-
CenterTrack https://github.com/xingyizhou/CenterTrack
-
ByteTrack https://github.com/ifzhang/ByteTrack
-
Perma Track https://github.com/TRI-ML/permatrack
-
https://github.com/DanceTrack/DanceTrack 提出一個數據集
-
https://github.com/ImmortalTracker/ImmortalTracker 用處不是特別大 感覺有點水
-
https://github.com/eddyhkchiu/mahalanobis_3d_multi_object_tracking
-
https://github.com/TuSimple/SimpleTrack 信息量不大
-
Score refinement for confidence-based 3D multi-object tracking https://github.com/cogsys-tuebingen/CBMOT
-
CenterTrack3D: Improved CenterTrack More Suitable for Three-Dimensional Objects
-
FairMOT https://github.com/ifzhang/FairMOT
-
HorizonMOT 地平線參加比賽的方案 https://arxiv.org/abs/2006.15506
-
PTTR: Relational 3D Point Cloud Object Tracking with Transformer https://github.com/Jasonkks/PTTR 單一目標跟蹤器
-
3D Siamese Voxel-to-BEV Tracker for Sparse Point Clouds https://github.com/fpthink/V2B 單一目標跟蹤器
-
3D Object Tracking with Transformer https://github.com/3bobo/lttr 單一目標跟蹤器
-
3D-FCT: Simultaneous 3D Object Detection and Tracking Using Feature Correlation 針對PVRCNN的改進
-
Probabilistic 3D Multi-Modal, Multi-Object Tracking for Autonomous Driving 多傳感器融合
-
https://github.com/wangxiyang2022/DeepFusionMOT 多傳感器融合
-
Learnable Online Graph Representations for 3D Multi-Object Tracking graph-based
-
Neural Enhanced Belief Propagation on Factor Graphs graph-based
-
TransTrack: Multiple Object Tracking with Transformer https://github.com/PeizeSun/TransTrack
-
TrackFormer https://github.com/timmeinhardt/trackformer
-
https://jialianwu.com/projects/TraDeS.html with分割
-
http://www.cvlibs.net/datasets/kitti/eval_tracking.php
更多細節(jié)可參考論文原文, 更多精彩內容請關注邁微AI研習社,每天晚上七點不見不散!

專欄訂閱:https://blog.csdn.net/charmve/category_10595130.html
推薦閱讀
(更多“自動駕駛感知”最新成果)
微信號: MaiweiE_com
GitHub:?@Charmve
CSDN、知乎: @Charmve
主頁: github.com/Charmve
國內頭部以自動駕駛全站技術為主線的交流學習社區(qū)(感知、歸控等),包含大量前沿論文解讀、工程實踐(源代碼)、視頻課程,熱招崗位。歡迎加入
!
如果覺得有用,就請點贊、轉發(fā)吧!