
基于相關(guān)學(xué)習(xí)的多目標(biāo)跟蹤


摘要
最近的研究表明,卷積網(wǎng)絡(luò)通過同時學(xué)習(xí)檢測和外觀特征,大大提高了多目標(biāo)跟蹤的性能。然而,由于對卷積網(wǎng)絡(luò)結(jié)構(gòu)本身的局部感知,無法有效地獲得空間和時間上的長期依賴關(guān)系。為了結(jié)合空間布局,我們提出利用局部關(guān)聯(lián)模塊來建模目標(biāo)與其周圍環(huán)境之間的拓?fù)潢P(guān)系,從而提高模型在擁擠場景中的識別能力。具體地說,我們建立了每個空間位置及其上下文的密集對應(yīng)關(guān)系,并通過自我監(jiān)督學(xué)習(xí)明確地約束相關(guān)量。為了利用時間上下文,現(xiàn)有的方法通常利用兩個或兩個以上的相鄰幀來構(gòu)建增強(qiáng)的特征表示,但動態(tài)運(yùn)動場景本質(zhì)上難以通過cnn描述。相反,本文提出了一種可學(xué)習(xí)的相關(guān)算子來在不同層的卷積特征映射上建立幀對幀的匹配,以對齊和傳播時間上下文。通過在MOT數(shù)據(jù)集上的大量實(shí)驗(yàn)結(jié)果,我們的方法證明了相關(guān)性學(xué)習(xí)的有效性和優(yōu)越的性能,并在MOT17上獲得了最先進(jìn)的MOTA為76:5%和IDF1為73:6%。

我們做出了以下貢獻(xiàn):
我們提出了一種統(tǒng)一的相關(guān)跟蹤器CorrTracker來集中地建模對象之間的關(guān)聯(lián),并通過關(guān)聯(lián)傳遞信息。
提出了一種局部結(jié)構(gòu)感知網(wǎng)絡(luò),通過自監(jiān)督學(xué)習(xí)提高了相似對象的可辨別性。
我們將局部相關(guān)網(wǎng)絡(luò)擴(kuò)展到有效地建模時間信息。
CorrTracker在四個MOT基準(zhǔn)測試中顯示了比現(xiàn)有的最先進(jìn)結(jié)果顯著的改進(jìn)。特別是在MOTA 17上,我們實(shí)現(xiàn)了76:5%的MOTA和73:6%的IDF1。

框架結(jié)構(gòu)
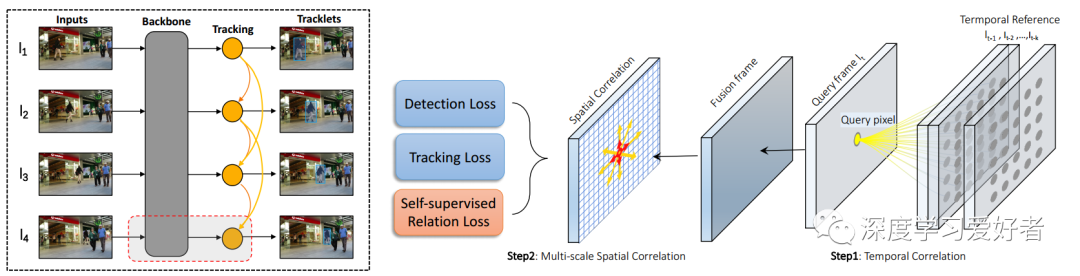
概述
通過相關(guān)層對外觀特征進(jìn)行增強(qiáng),將對象的成對關(guān)系及其時空鄰域密集編碼。局部相關(guān)量以自監(jiān)督方式進(jìn)行優(yōu)化。

在參考圖像中的指示目標(biāo)(白叉)和查詢圖像的所有位置之間計(jì)算的匹配置信度(a)-(b)的可視化。基于外觀特征的跟蹤器[58](a)由于存在相似的干擾物而產(chǎn)生不顯著和不準(zhǔn)確的置信度。相反,我們的相關(guān)跟蹤器(b)通過相關(guān)學(xué)習(xí)(c)在正確的位置預(yù)測出一個明顯的高置信值。

多金字塔層次的相關(guān)性

實(shí)驗(yàn)結(jié)果

幀從MOT17- 03采樣
我們的CorrTracker可以通過挖掘目標(biāo)周圍的上下文模式來識別對象。

每個邊界框的顏色表示目標(biāo)標(biāo)識。每個邊界框下面的虛線表示每個目標(biāo)的最近軌跡。該跟蹤器預(yù)測軌跡具有很大的魯棒性和時間一致性。
 結(jié)論
結(jié)論
我們的相關(guān)模塊密集地匹配所有目標(biāo)與他們的局部上下文,并從相關(guān)體學(xué)習(xí)有區(qū)別的嵌入。此外,我們展示了如何擴(kuò)展相關(guān)模塊從空間布局到鄰近的幀,以加強(qiáng)時間建模能力。我們探索了自我監(jiān)督學(xué)習(xí)對關(guān)聯(lián)量施加區(qū)別性約束,它顯式地預(yù)測實(shí)例流。對四個MOT挑戰(zhàn)的廣泛實(shí)驗(yàn)表明,我們的CorrTracker達(dá)到了最先進(jìn)的性能,在推理方面是有效的。
論文鏈接:https://arxiv.org/pdf/2101.02877.pdf
雙一流高校研究生團(tuán)隊(duì)創(chuàng)建 ↓
專注于計(jì)算機(jī)視覺原創(chuàng)并分享相關(guān)知識 ?
整理不易,點(diǎn)贊三連!