
用OpenCV搭建活體檢測器
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺”公眾號(hào)
視覺/圖像重磅干貨,第一時(shí)間送達(dá)
來源 | 小白學(xué)視覺
照片、視頻中的人臉有時(shí)也能騙過一些不成熟的人臉識(shí)別系統(tǒng),讓人們對人臉解鎖的安全性產(chǎn)生很大懷疑。在這篇 4 千多字的教程中,作者介紹了如何用 OpenCV 進(jìn)行活體檢測(liveness detection)。跟隨作者給出的代碼和講解,你可以在人臉識(shí)別系統(tǒng)中創(chuàng)建一個(gè)活體檢測器,用于檢測偽造人臉并執(zhí)行反人臉欺騙。
我在過去的一年里寫了不少人臉識(shí)別的教程,包括:
penCV 人臉識(shí)別
用 dlib、Python 和深度學(xué)習(xí)進(jìn)行人臉識(shí)別
用樹莓派實(shí)現(xiàn)人臉識(shí)別
https://www.pyimagesearch.com/2018/09/24/opencv-face-recognition/
https://www.pyimagesearch.com/2018/06/18/face-recognition-with-opencv-python-and-deep-learning/
https://www.pyimagesearch.com/2018/06/25/raspberry-pi-face-recognition/
但在我的郵件和人臉識(shí)別相關(guān)帖子下面的評(píng)論中經(jīng)常會(huì)出現(xiàn)以下問題:
我該如何識(shí)別真假人臉呢?
想想如果有壞人試圖攻破你的人臉識(shí)別系統(tǒng)會(huì)發(fā)生什么?
這樣的用戶可能會(huì)拿到另一個(gè)人的照片。甚至可能他們的手機(jī)上就有其他人的照片或視頻,他們可以用這樣的照片或視頻來欺騙識(shí)別人臉的相機(jī)(就像本文開頭的圖片那樣)。
在這種情況下,照相機(jī)完全有可能將其識(shí)別為正確的人臉,從而讓未經(jīng)授權(quán)的用戶騙過人臉識(shí)別系統(tǒng)!
如何識(shí)別這些真假人臉呢?如何在人臉識(shí)別應(yīng)用中使用反人臉欺騙算法?
答案是用?OpenCV?實(shí)現(xiàn)活體檢測——這也是我今天要介紹的內(nèi)容。
要了解如何用 OpenCV 將活體檢測結(jié)合到你自己的人臉識(shí)別系統(tǒng)中,請繼續(xù)往下讀。
你可以在文末的下載部分下載源代碼:
https://www.pyimagesearch.com/2019/03/11/liveness-detection-with-opencv/#
本教程第一部分將討論什么是活體檢測以及為什么要借助活體檢測提升我們的人臉識(shí)別系統(tǒng)。
從這里開始要先研究一下用于活體檢測的數(shù)據(jù)集,包括:
如何構(gòu)建活體檢測的數(shù)據(jù)集?
真假面部圖像的樣例。
我們還將回顧用于活體檢測器項(xiàng)目的項(xiàng)目結(jié)構(gòu)。
為了創(chuàng)建活體檢測器,我們要訓(xùn)練一個(gè)能分辨真假人臉的深度神經(jīng)網(wǎng)絡(luò)。
因此,我們還需要:
構(gòu)建圖像數(shù)據(jù)集;
實(shí)現(xiàn)可以執(zhí)行活體檢測的 CNN(我們將這個(gè)網(wǎng)絡(luò)稱為「LivenessNet」);
訓(xùn)練活體檢測器網(wǎng)絡(luò);
創(chuàng)建一個(gè) Python+OpenCV 的腳本,可以通過該腳本使用我們訓(xùn)練好的活體檢測器模型,并將其應(yīng)用于實(shí)時(shí)視頻。
那我們就開始吧!
什么是活體檢測?我們?yōu)槭裁葱枰铙w檢測?
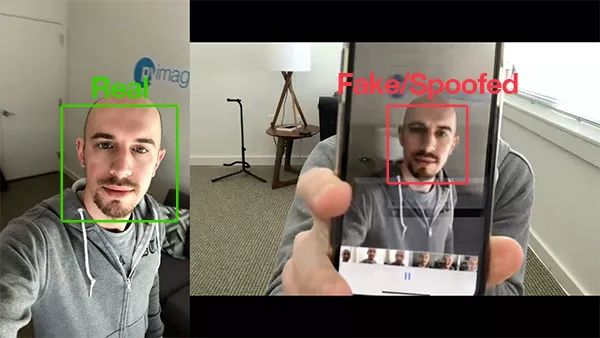
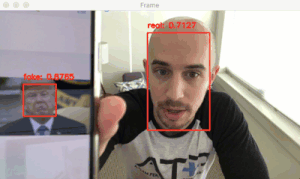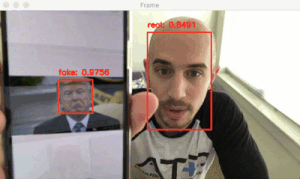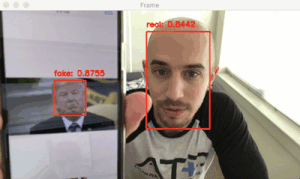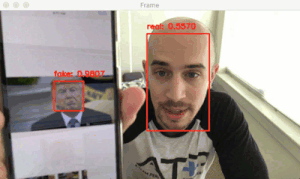
圖 1:用 OpenCV 進(jìn)行活體檢測。左圖是我的實(shí)時(shí)(真實(shí))視頻,而右圖中我拿著自己的 iPhone(欺騙)。
人臉識(shí)別系統(tǒng)與以往任何時(shí)候相比都更加普遍。從 iPhone(智能手機(jī))中的人臉識(shí)別,到中國大規(guī)模監(jiān)控中的人臉識(shí)別,人臉識(shí)別系統(tǒng)的應(yīng)用無處不在。
但人臉識(shí)別系統(tǒng)也很容易被「偽造」和「不真實(shí)」的面部所欺騙。
在面部識(shí)別相機(jī)前拿著一個(gè)人的照片(無論是印出來的還是手機(jī)上的)可以輕而易舉地騙過人臉識(shí)別系統(tǒng)。
為了讓人臉識(shí)別系統(tǒng)更加安全,我們需要檢測出這樣偽造的面部——活體檢測(術(shù)語)指的就是這樣的算法。
活體檢測的方法有很多,包括:
紋理分析(Texture analysis),該方法計(jì)算了面部區(qū)域的局部二值模式(Local Binary Patterns,LBP),用 SVM 將面部分為真實(shí)面部和偽造面部;
頻率分析(Frequency analysis),比如檢查面部的傅立葉域;
可變聚焦分析(Variable focusing analysis),例如檢查連續(xù)兩幀間像素值的變化;
啟發(fā)式算法(Heuristic-Based algorithms),包括眼球運(yùn)動(dòng)、嘴唇運(yùn)動(dòng)和眨眼檢測。這些算法試圖追蹤眼球運(yùn)動(dòng)和眨眼行為,來確保用戶不是拿著誰的照片(因?yàn)檎掌粫?huì)眨眼也不會(huì)動(dòng)嘴唇);
光流算法(Optical Flow algorithm),即檢測 3D 對象和 2D 平面產(chǎn)生的光流的屬性和差異;
3D 面部形狀(3D face shape),類似于 iPhone 上的面部識(shí)別系統(tǒng),這種算法可以讓面部識(shí)別系統(tǒng)區(qū)分真實(shí)面部和其他人的照片或打印出來的圖像;
結(jié)合以上算法,這種方法可以讓面部識(shí)別系統(tǒng)工程師挑選適用于自己應(yīng)用的活體檢測模型。
Chakraborty 和 Das 2014 年的論文(《An Overview of Face liveness Detection》)對活體檢測算法做了全面的綜述。
我們在本教程中將活體檢測視為一個(gè)二分類問題。
給定輸入圖像,我們要訓(xùn)練一個(gè)能區(qū)分真實(shí)面部和偽造面部的卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network)。
但在訓(xùn)練活體檢測模型之前,我們要先檢查一下數(shù)據(jù)集。
我們的活體檢測視頻
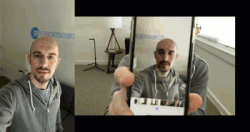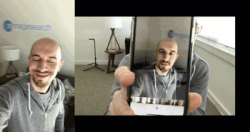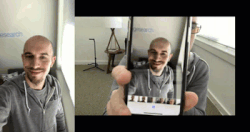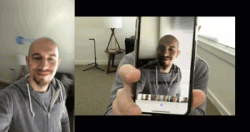
圖 2:真實(shí)面部和偽造面部的樣例。左邊的視頻是我的面部的真實(shí)視頻,右邊是在播放同樣的視頻時(shí)筆記本錄制的視頻。
為了讓例子更直觀,本文建立的活體檢測器側(cè)重于區(qū)分真實(shí)面部和屏幕上的偽造面部。
這一算法可以輕易擴(kuò)展到其他類型的偽造面部上,比如打印輸出的偽造面部和高分辨率輸出的偽造面部等。
為了建立活體檢測數(shù)據(jù)集,我做了下列工作:
拿著我的 iPhone,將它設(shè)置為人像或自拍模式;
錄制約 25 秒我在辦公室里來回走的視頻;
重播這段 25 秒的視頻,這次用我的 iPhone 對著錄制了重播視頻的電腦;
這樣就產(chǎn)生了兩段樣例視頻,一段用于「真實(shí)」面部,一段用于「偽造」面部;
最后,我在這兩段視頻上都用了人臉檢測,為這兩類提取出單獨(dú)的面部 ROI(Reign of Interest)。
我在本文的「下載」部分提供了真實(shí)面部和偽造面部的視頻文件。
你可以將這些視頻作為數(shù)據(jù)集的起點(diǎn),但我建議你多收集一些數(shù)據(jù),這可以讓你的活體檢測器更魯棒也更安全。
通過測試,我確定模型有些偏向我的臉,這是意料之中的結(jié)果,因?yàn)樗械哪P投际腔谖业拿娌坑?xùn)練出來的。此外,由于我是白人(高加索人),所以如果數(shù)據(jù)集中有其他膚色或其他人種的面部時(shí),這個(gè)模型效果會(huì)沒有那么好。
在理想情況下,你應(yīng)該用不同膚色和不同人種的面部來訓(xùn)練模型。請參考本文的「限制和后續(xù)工作」部分,來了解其他改善活體檢測模型的建議。
你將在本教程剩下的部分學(xué)習(xí)如何獲取我錄制的數(shù)據(jù)集以及如何將它實(shí)際應(yīng)用于通過 OpenCV 和深度學(xué)習(xí)建立的活體檢測器。
項(xiàng)目結(jié)構(gòu)
你可以通過本教程的「Downloads」部分下載代碼、數(shù)據(jù)和活體模型,然后解壓縮存檔。
進(jìn)入項(xiàng)目目錄后,你能看到這樣的結(jié)構(gòu):

目錄中有四個(gè)主目錄:
?
dataset/:我們的數(shù)據(jù)集目錄中包含兩類圖像:
???????????? 1. 在播放我的面部視頻時(shí)通過錄制屏幕得到的偽造圖像;
???????????? 2. 手機(jī)直接拍攝我的面部視頻得到的真實(shí)圖像。
face_detector/:由預(yù)訓(xùn)練的 Caffe 面部檢測器組成,用來定位面部 ROI;
Pyimagesearch/:該模塊包含了 LivenessNet 類;
videos/:這里提供了兩段用于訓(xùn)練 LivenessNet 分類器的輸入視頻。
今天我們會(huì)詳細(xì)地學(xué)習(xí)三個(gè) Python 腳本。在文章結(jié)束后,你可以在自己的數(shù)據(jù)和輸入視頻上運(yùn)行這三個(gè)腳本。按在教程中出現(xiàn)的順序,這三個(gè)腳本分別是:
1. gather_examples.py:這個(gè)腳本從輸入的視頻文件中提取了面部 ROI,幫助我們創(chuàng)建了深度學(xué)習(xí)面部活體數(shù)據(jù)集;
2. train_liveness.py:如文件名所示,這個(gè)腳本用來訓(xùn)練 LivenessNet 分類器。我們將用 Keras 和 TensorFlow 訓(xùn)練模型。在訓(xùn)練過程中會(huì)產(chǎn)生一些文件:
?le.pickle:分類標(biāo)簽編碼器。
?liveness.model:?可以檢測面部活性的序列化 Keras 模型。
?plot.png:訓(xùn)練歷史圖呈現(xiàn)了準(zhǔn)確率和損失曲線,我們可以根據(jù)它來評(píng)估模型(是否過擬合或欠擬合。)
3. liveness_demo.py:演示腳本,它會(huì)啟動(dòng)你的網(wǎng)絡(luò)攝像頭抓取幀,可以進(jìn)行實(shí)時(shí)的面部活體檢測。
從訓(xùn)練(視頻)數(shù)據(jù)集中檢測并提取面部 ROI
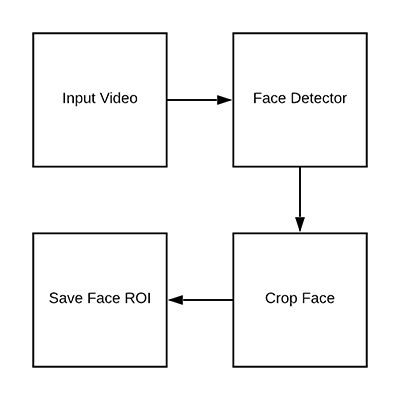
圖 3:為了構(gòu)建活體檢測數(shù)據(jù)集,在視頻中檢測面部 ROI。
現(xiàn)在有機(jī)會(huì)看到初始數(shù)據(jù)集和項(xiàng)目結(jié)構(gòu)了,讓我們看看該如何從輸入視頻中提取出真實(shí)面部圖像和偽造面部圖像吧。
最終目標(biāo)是用這個(gè)腳本填充兩個(gè)目錄:
dataset/fake/:fake.mp4 中的面部 ROI;
dataset/real/:real.mov 中的面部 ROI。
根據(jù)這些幀,我們后續(xù)將在這些圖像上訓(xùn)練基于深度學(xué)習(xí)的活體檢測器。
打開 gataer_examples.py,插入下面的代碼:

2~5 行導(dǎo)入了我們需要的包。除了內(nèi)置的 Python 模塊外,該腳本只需要 OpenCV 和 NumPy。
8~19 行解析了命令行參數(shù):
--input:輸入視頻文件的路徑
--output:輸出目錄的路徑,截取的每一張面部圖像都存儲(chǔ)在這個(gè)目錄中。
--detector:面部檢測器的路徑。我們將使用 OpenCV 的深度學(xué)習(xí)面部檢測器。方便起見,本文的「Downloads」部分也有這個(gè) Caffe 模型。
--confidence:過濾弱面部檢測的最小概率,默認(rèn)值為 50%。
--skip:我們不需要檢測和存儲(chǔ)每一張圖像,因?yàn)橄噜彽膸窍嗨频摹R虼宋覀冊跈z測時(shí)會(huì)跳過 N 個(gè)幀。你可以使用這個(gè)參數(shù)并更改默認(rèn)值(16)。
?
繼續(xù)加載面部檢測器并初始化視頻流:
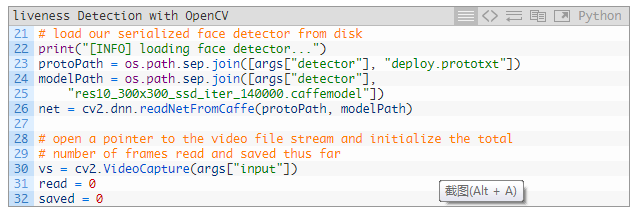
23~26 行加載了 OpenCV 的深度學(xué)習(xí)面部檢測器:
https://www.pyimagesearch.com/2018/02/26/face-detection-with-opencv-and-deep-learning/
從 30?行開始打開視頻流。
我們還初始化了兩個(gè)參數(shù)——讀取的幀的數(shù)量和執(zhí)行循環(huán)時(shí)保存的幀的數(shù)量(31 和 32 行)。
接著要?jiǎng)?chuàng)建處理幀的循環(huán):
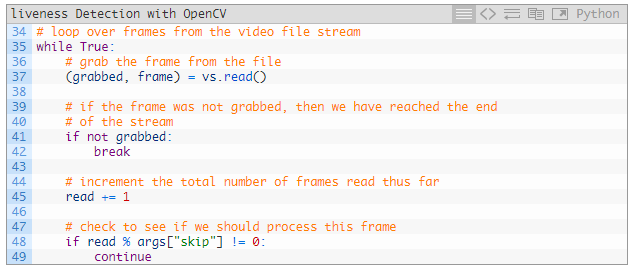
while 循環(huán)是從 35 行開始的。
從這里開始我們抓取一幀并進(jìn)行驗(yàn)證(37~42 行)。
此時(shí),因?yàn)橐呀?jīng)讀取了一個(gè)幀,我們將增加讀取計(jì)數(shù)器(48 行)。如果我們跳過特定的幀,也會(huì)跳過后面的處理,再繼續(xù)下一個(gè)循環(huán)(48 和 49 行)。
接著檢測面部:
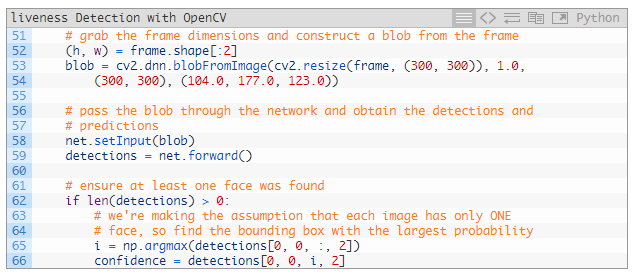
為了進(jìn)行面部檢測,我們要在 53 和 54 行根據(jù)圖像創(chuàng)建一個(gè) blob。為了適應(yīng) Caffe 面部識(shí)別器,這個(gè) blob 是 300*300?的。之后還要縮放邊界框,因此 52 行抓取了幀的維度。
58 和 59 行通過深度學(xué)習(xí)面部識(shí)別器執(zhí)行了 blob 的前向傳輸。
我們的腳本假設(shè)視頻的每一幀中只有一張面部(62~65 行)。這有助于減少假陽性。如果你要處理的視頻中不止有一張面部,我建議你根據(jù)需要調(diào)整邏輯。
因此,第 65 行抓取了概率最高的面部檢測索引。66 行用這個(gè)索引計(jì)算了檢測的置信度。
接下來要過濾弱檢測并將面部 ROI 寫進(jìn)磁盤:
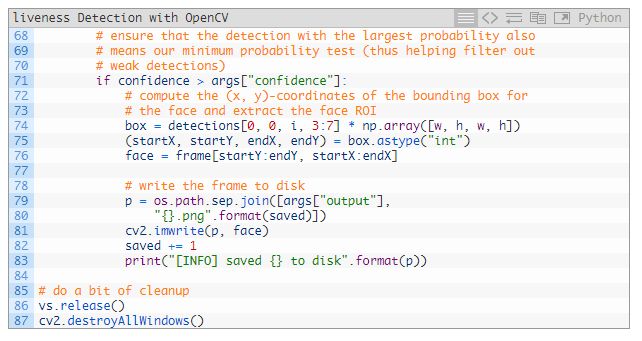
71 行確保我們的面部檢測 ROI 滿足最小閾值,從而減少假陽性。
在 74~76 行提取了面部 ROI 和相應(yīng)的邊界框。
在 79~81 行為面部 ROI 生成了路徑和文件名,并將它寫在磁盤上。此時(shí),我們就可以增加保存的面部圖像數(shù)量了。
處理完成后,我們將在 86 和 87 行執(zhí)行清理工作。
建立活體檢測圖像數(shù)據(jù)集

圖 4:OpenCV 面部活體檢測數(shù)據(jù)集。我們要用 Keras 和 OpenCV 來訓(xùn)練并演示活體模型。
現(xiàn)在我們已經(jīng)實(shí)現(xiàn)了 gather_example.py 腳本,接下來要讓它開始工作。
確保你已經(jīng)用這篇教程的「Downloads」部分獲取了源代碼和輸入視頻樣例。
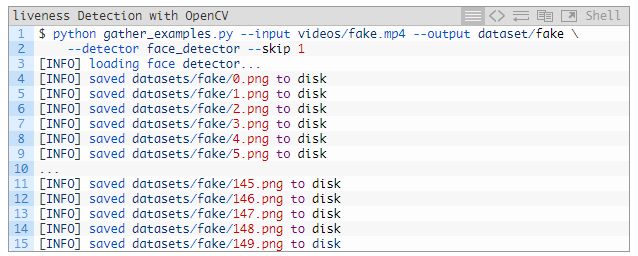
打開終端并執(zhí)行下面的命令來提取「偽造」類的面部:
也可以對「真實(shí)」類別的面部執(zhí)行同樣的操作:
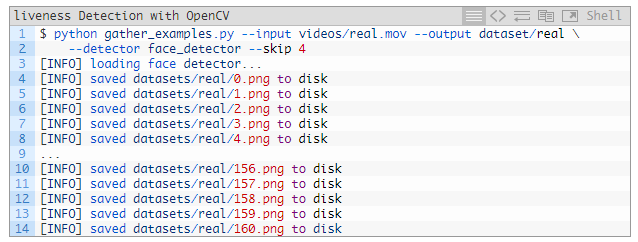
因?yàn)椤刚妗挂曨l比「假」視頻長,因此我們得把跳過幀的值設(shè)置得更長,來平衡每一類輸出的面部 ROI 數(shù)量。
在執(zhí)行這個(gè)腳本之后,你的圖像數(shù)量應(yīng)該如下:
偽造面部:150?張圖片;
真實(shí)面部:161 張圖片;
總數(shù):311 張圖片。
實(shí)現(xiàn)「LivenessNet」——我們的深度學(xué)習(xí)活體檢測器

圖 5:LivenessNet(一個(gè)用來檢測圖片和視頻中面部活性的 CNN)的深度學(xué)習(xí)架構(gòu)。
下一步就要實(shí)現(xiàn)基于深度學(xué)習(xí)的活體檢測器「LivenessNet」了。
從核心上講,LivenessNet 實(shí)際上就是一個(gè)簡單的卷積神經(jīng)網(wǎng)絡(luò)。
我們要讓這個(gè)網(wǎng)絡(luò)盡可能淺,并用盡可能少的參數(shù),原因如下:
避免因數(shù)據(jù)集小而導(dǎo)致的過擬合;
確保活性檢測器足夠快,能夠?qū)崟r(shí)運(yùn)行(即便是在像樹莓派這樣資源受限的設(shè)備上)。
現(xiàn)在來實(shí)現(xiàn) LivenessNet 吧。打開 livenessnet.py 并插入下面的代碼:
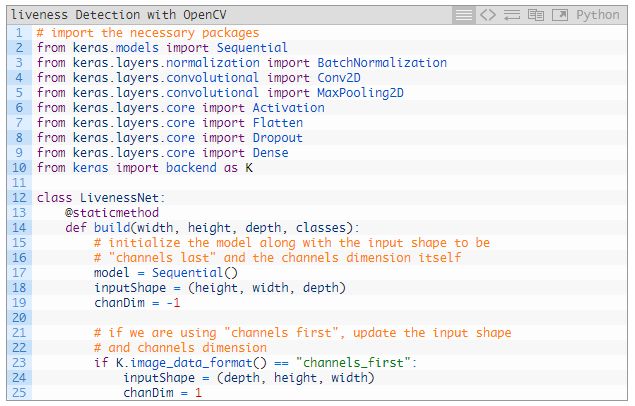
所有導(dǎo)入(import)的包都來自 Keras(2~10?行)。要深入了解這些層和函數(shù),請參考《Deep Learning for Computer Vision with Python》。
第 12 行定義了 LivenessNet 的類。這里用了一種靜態(tài)方法——build(14 行)。build 方法接受 4 個(gè)參數(shù):
width:圖片/體積的寬度;
height:圖片的高度;
depth:圖像的通道數(shù)量(本例中是 3,因?yàn)槲覀兲幚淼氖?RGB 圖像);
classes:類的數(shù)量。我們總共有兩類:「真」和「假」。
在 17 行初始化模型。
在 18 行定義了 inputShape,在 23~25 行確定了通道順序。
接著給 CNN 添加層:

我們的 CNN 展現(xiàn)了 VGGNet 特有的品質(zhì)——只學(xué)習(xí)了少量的過濾器。在理想情況下,我們不需要能區(qū)分真實(shí)面部和偽造面部的深度網(wǎng)絡(luò)。
28~36 行是第一個(gè)層的集合——CONV => RELU => CONV => RELU => POOL,這里還添加了批歸一化和 dropout。
39~46 行添加了另一個(gè)層集合——CONV => RELU => CONV => RELU => POOL。
最后,我們還要添加 FC => RELU 層:

49~57 行添加了全連接層和帶有 softmax 分類器 head 的 ReLU 激活層。
模型在 60?行返回到訓(xùn)練腳本。
創(chuàng)建訓(xùn)練活體檢測器的腳本
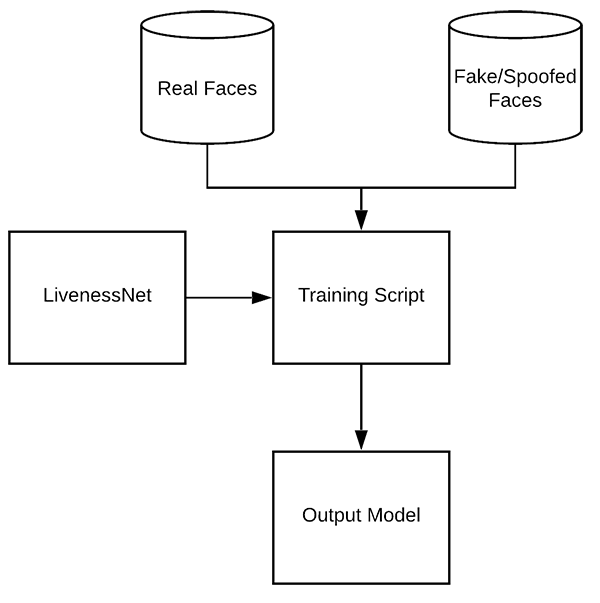
圖 6:LivenessNet 的訓(xùn)練過程。同時(shí)用「真實(shí)」圖像和「偽造」圖像作為數(shù)據(jù)集,可以用 OpenCV、Keras 和深度學(xué)習(xí)訓(xùn)練活體檢測模型。
鑒于我們已經(jīng)有了真實(shí)/偽造圖像,且已經(jīng)實(shí)現(xiàn)了 LivenessNet,我們現(xiàn)在準(zhǔn)備訓(xùn)練網(wǎng)絡(luò)了。
打開 train_liveness.py 文件,插入下列代碼:
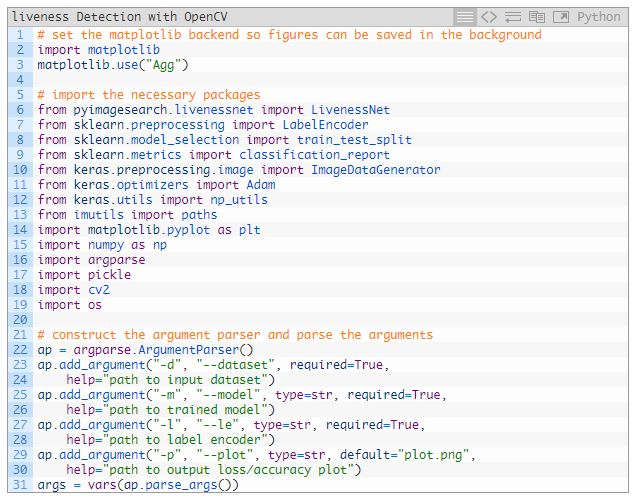
訓(xùn)練面部活體檢測器的腳本要導(dǎo)入大量的包(2~19 行)。大概了解一下:
matplotlib:用于生成訓(xùn)練圖。在第 3 行將后端參數(shù)設(shè)為「Agg」,這樣就可以將生成的圖保存在磁盤上了。
LivenessNet:我們之前定義好的用于活體檢測的 CNN;
train_test_split:scikit-learn 中的函數(shù),用于將數(shù)據(jù)分割成訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù);
classification_report:scikit-learn 中的函數(shù),這個(gè)工具可以根據(jù)模型性能生成簡要的統(tǒng)計(jì)報(bào)告;
ImageDataGenerator:用于數(shù)據(jù)增強(qiáng),它生成了一批隨機(jī)變換后的圖像;
Adam:適用于該模型的優(yōu)化器(也可以用 SGD、RMSprop 等替換);
paths:來自 imutils 包,這個(gè)模塊可以幫助我們收集磁盤上所有圖像文件的路徑;
pyplot:用來生成漂亮的訓(xùn)練圖;
numpy:Python 的數(shù)字處理庫。對 OpenCV 來說這個(gè)庫也是必需的;
argparse:用來處理命令行參數(shù);
pickle:將標(biāo)簽編碼器序列化到磁盤;
cv2:綁定了 OpenCV;
os:這個(gè)模塊可以做很多事,但我們只用它來作操作系統(tǒng)路徑分隔符。
現(xiàn)在你知道導(dǎo)入的都是些什么了,可以更直接地查看腳本剩余的部分。
這個(gè)腳本接受四個(gè)命令行參數(shù):
--dataset:輸入數(shù)據(jù)集的路徑。我們在本教程前面的部分用 gather_examples.py 腳本創(chuàng)建了數(shù)據(jù)集。
--model:我們的腳本會(huì)生成一個(gè)輸出模型文件,在這個(gè)參數(shù)中提供路徑。
--le:這里要提供輸出序列化標(biāo)簽編碼器文件的路徑。
--plot:訓(xùn)練腳本會(huì)生成一張圖。如果要覆蓋默認(rèn)值「plog.png」,那你就要在命令行中指定值。
下面的代碼塊要進(jìn)行大量的初始化工作,還要構(gòu)建數(shù)據(jù):

在 35~37 行要設(shè)置訓(xùn)練參數(shù),包含初始化學(xué)習(xí)率、批大小和 epoch 的數(shù)量。
在 42~44 行要抓取 imagePaths。我們還要初始化兩個(gè)列表來存放數(shù)據(jù)和類別標(biāo)簽。
46~55 行的循環(huán)用于建立數(shù)據(jù)和標(biāo)簽列表。數(shù)據(jù)是由加載并將尺寸調(diào)整為 32*32 像素的圖像組成的,標(biāo)簽列表中存儲(chǔ)了每張圖相對應(yīng)的標(biāo)簽。
在 59 行將所有像素縮放到?[0,1]?之間,并將列表轉(zhuǎn)換為 NumPy 數(shù)組。
現(xiàn)在來編碼標(biāo)簽并劃分?jǐn)?shù)據(jù):
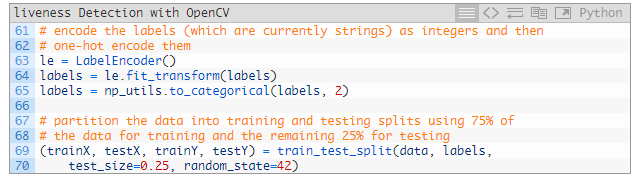
63~65 行對標(biāo)簽進(jìn)行 one-hot 編碼處理。
在 69 和 70?行用 scikit-learn 劃分?jǐn)?shù)據(jù)————將數(shù)據(jù)的 75%?用來訓(xùn)練,剩下的 25%?用來測試。
接下來要初始化數(shù)據(jù)增強(qiáng)對象、編譯和訓(xùn)練面部活性模型:

73~75 行構(gòu)造了數(shù)據(jù)增強(qiáng)對象,這個(gè)過程通過隨機(jī)的旋轉(zhuǎn)變換、縮放變換、平移變換、投影變換以及翻轉(zhuǎn)變換來生成圖像。
在 79~83 行中建立并編譯了我們的 LivenessNet 模型。
在 87~89 行著手訓(xùn)練。考慮到模型較淺且數(shù)據(jù)集較小,因此這個(gè)過程相對而言會(huì)快一些。
模型訓(xùn)練好后,就可以評(píng)估結(jié)果并生成訓(xùn)練圖了:
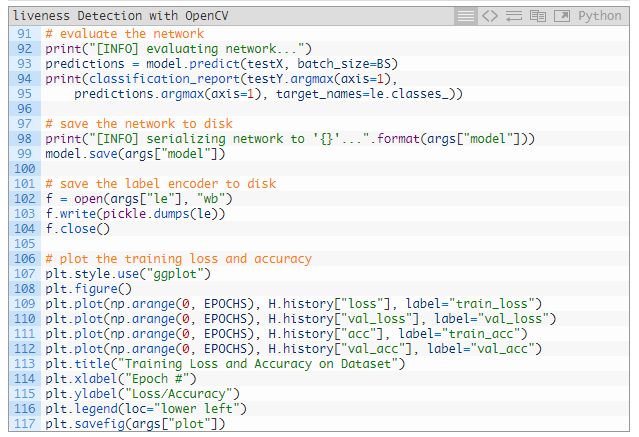
在測試集上作出預(yù)測(93 行)。94 和 95 行生成了 classification_report,并將結(jié)果輸出在終端上。
99~104 行將 LivenessNet 模型和標(biāo)簽編碼器一起序列化到磁盤上。
剩下的 107~117 行則為后續(xù)的檢查生成了訓(xùn)練歷史圖。
訓(xùn)練活體檢測器
我們現(xiàn)在準(zhǔn)備訓(xùn)練活體檢測器了。
確保你已經(jīng)通過本教程的「Downloads」部分下載了源代碼和數(shù)據(jù)集,執(zhí)行以下命令:
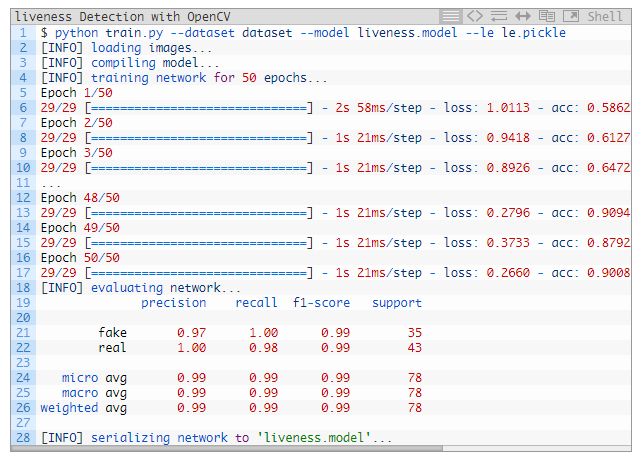

圖 6:用 OpenCV、Keras 和深度學(xué)習(xí)訓(xùn)練面部活體模型的圖。
結(jié)果表明,我們的活體檢測器在驗(yàn)證集上的準(zhǔn)確率高達(dá) 99%!
將各個(gè)部分組合在一起:用 OpenCV 做活體檢測
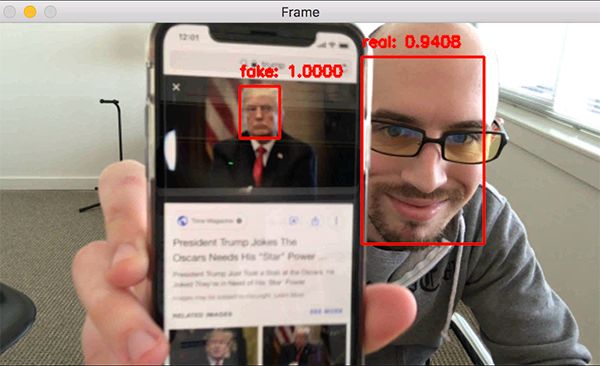
圖 7:用 OpenCV 和深度學(xué)習(xí)做面部活性檢測。
最后一步是將各個(gè)部分組合在一起:
訪問網(wǎng)絡(luò)攝像頭/視頻流
將面部檢測應(yīng)用到每一幀
對面部檢測的結(jié)果應(yīng)用活體檢測器模型
打開 liveness_demo.py 并插入以下代碼:
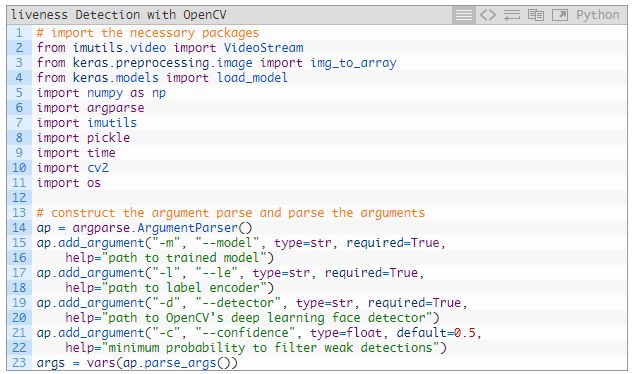
2~11 行導(dǎo)入了需要的包。值得注意的是:
會(huì)使用 VideoStream 來訪問相機(jī)饋送
使用 img_to_array 來使幀采用兼容的數(shù)組形式
用 load_model 來加載序列化的 Keras 模型
為了方便起見還要使用 imutils
用 cv2 綁定 OpenCV
解析 14~23 行命令行的參數(shù):
--model:用于活性檢測的預(yù)訓(xùn)練 Keras 模型的路徑;
--le:標(biāo)簽編碼器的路徑;
--detector:用來尋找面部 ROI 的 OpenCV 的深度學(xué)習(xí)面部檢測器路徑;
--confidence:濾出弱檢測的最小概率閾值。
現(xiàn)在要繼續(xù)初始化面部檢測器、LivenessNet 模型和標(biāo)簽編碼器,以及視頻流:
27~30?行加載 OpenCV 人臉檢測器。
34 和 35 行加載序列化的預(yù)訓(xùn)練模型(LivenessNet)和標(biāo)簽編碼器。
39 和 40?行實(shí)例化 VideoStream 對象,允許相機(jī)預(yù)熱兩秒。
此時(shí)開始遍歷幀來檢測真實(shí)和虛假人臉:

43 行開啟了無限的 while 循環(huán)塊,從這里開始捕獲并調(diào)整各個(gè)幀的大小(46 和 47 行)。
調(diào)整幀的大小后,抓取幀的維度,以便稍后進(jìn)行縮放(50?行)。
用 OpenCV 的 blobFromImage 函數(shù)可以生成 blob(51 和 52 行),然后將其傳到面部檢測器網(wǎng)絡(luò),再繼續(xù)推理(56 和 57 行)。
現(xiàn)在可以進(jìn)行有意思的部分了——用 OpenCV 和深度學(xué)習(xí)做活性檢測:

在 60?行開始循環(huán)遍歷面部檢測。在這個(gè)過程中,我們:
濾出弱檢測(63~66 行);
提取對應(yīng)的面部邊界框,確保它們沒有超出幀(69~77 行);
提取面部 ROI,用處理訓(xùn)練數(shù)據(jù)的方式對面部 ROI 進(jìn)行預(yù)處理(81~85 行);
部署活性檢測器模型,確定面部圖片是「真實(shí)的」還是「偽造的」(89~91 行);
當(dāng)檢測出是真實(shí)面部時(shí),直接在 91 行后面插入面部識(shí)別的代碼。偽代碼類似于:if label ==?"real": run_face_reconition();
最后(在本例中)繪制出標(biāo)簽文本并框出面部(94~98 行)。
展示結(jié)果并清理:
當(dāng)捕獲按鍵時(shí),在循環(huán)的每一次迭代中顯示輸出幀。無論用戶在什么時(shí)候按下「q」(「退出」),都會(huì)跳出循環(huán)、釋放指針并關(guān)閉窗口(105~110?行)。
在實(shí)時(shí)視頻中部署活體檢測器
要繼續(xù)本教程,請確保你已經(jīng)通過本教程的「Downloads」部分下載了源代碼和預(yù)訓(xùn)練的活體檢測模型。
打開終端并執(zhí)行下列命令:

在這里可以看到我們的活性檢測器成功地分辨出真實(shí)面部和偽造面部。
下面的視頻中有更長的演示:
限制、改進(jìn)和進(jìn)一步工作
本教程中的活體檢測器的主要限制在于數(shù)據(jù)集的限制——數(shù)據(jù)集中只有 311 張圖片(161 個(gè)「真實(shí)」類和 150?個(gè)「偽造」類)。
這項(xiàng)工作第一個(gè)要擴(kuò)展的地方就是要收集更多的訓(xùn)練數(shù)據(jù),更具體地說,不只是要有我或你自己的圖像(幀)。
記住,這里用的示例數(shù)據(jù)集只包括一個(gè)人(我)的面部。我是個(gè)白人(高加索人),而你收集的訓(xùn)練數(shù)據(jù)中還應(yīng)該有其他人種或其他膚色的面部。
我們的活體檢測器只是針對屏幕上顯示的偽造面部訓(xùn)練的——并沒有打印出來圖像或照片。因此,我的第三個(gè)建議是除了屏幕錄制得到的偽造面部外,還應(yīng)該有通過其他方式偽造的面部資源。
我最后要說的是,這里的活體檢測并未涉及任何新技術(shù)。最好的活體檢測器會(huì)包含多種活性檢測的方法(請參考前文中提到的《What is liveness detection and why do we need it?》)。
花些時(shí)間思考并評(píng)估你自己的項(xiàng)目、指南和需求——在某些情況下,你可能只需要基本的眨眼檢測啟發(fā)式。
而在另一些情況中,你可能需要將基于深度學(xué)習(xí)的活體檢測和其他啟發(fā)式結(jié)合在一起。
不要急于進(jìn)行人臉識(shí)別和活體檢測——花點(diǎn)時(shí)間思考你的項(xiàng)目獨(dú)一無二的需求。這么做可以確保你獲得更好、更準(zhǔn)確的結(jié)果。
你將在本教程中學(xué)習(xí)如何用 OpenCV 進(jìn)行活體檢測。你現(xiàn)在就可以在自己的面部識(shí)別系統(tǒng)中應(yīng)用這個(gè)活體檢測器,來發(fā)現(xiàn)偽造的面部并進(jìn)行反面部欺騙。
我們用 OpenCV、深度學(xué)習(xí)和 Python 創(chuàng)建了自己的活體檢測器。
第一步是要收集真實(shí)面部和虛假面部的數(shù)據(jù)集。為了完成這項(xiàng)任務(wù),我們:
首先用智能手機(jī)錄制了一段自己的視頻(即「真實(shí)」面部);
將手機(jī)放在筆記本電腦或桌面上,重播同樣的視頻,用網(wǎng)絡(luò)攝像頭錄制重播的視頻(即「偽造」面部);
在這兩段視頻上使用面部檢測器,來生成最終的活體檢測數(shù)據(jù)集。
在構(gòu)建數(shù)據(jù)集之后,我們實(shí)現(xiàn)了「LivenessNet」,它集成了 Keras 和深度學(xué)習(xí) CNN。
我們有意讓這個(gè)網(wǎng)絡(luò)盡可能淺,以確保:
減少模型因數(shù)據(jù)集太小而導(dǎo)致的過擬合情況;
模型可以實(shí)時(shí)運(yùn)行(包括樹莓派)
總體來說,我們的活體檢測器在驗(yàn)證集上的準(zhǔn)確率高達(dá) 99%。
為了演示完整的活體檢測流程,我們創(chuàng)建了一個(gè) Python+OpenCV 的腳本,它可以加載我們的活體檢測器,并且可以將它應(yīng)用在實(shí)時(shí)的視頻流上。
正如演示所示,我們的活體檢測器可以區(qū)分真實(shí)面部和偽造面部。
—版權(quán)聲明—
僅用于學(xué)術(shù)分享,版權(quán)屬于原作者。
若有侵權(quán),請聯(lián)系微信號(hào):yiyang-sy 刪除或修改!