風頭正勁的對比學習和項目實踐
知乎專欄:數(shù)據(jù)拾光者 公眾號:數(shù)據(jù)拾光者
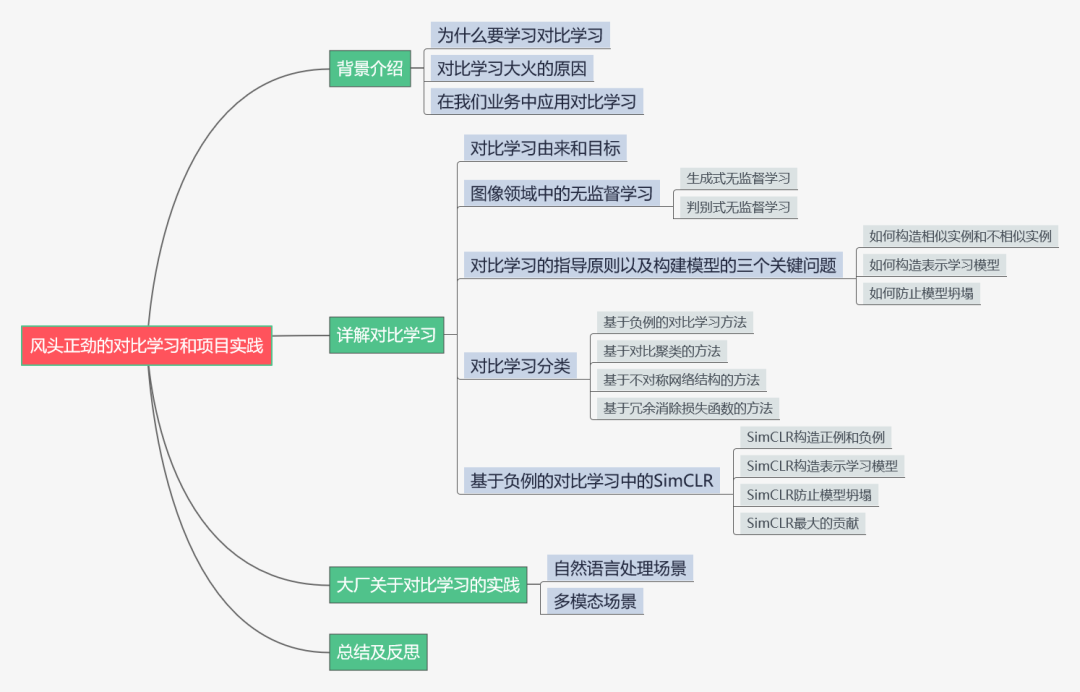
01
02
基于負例的對比學習方法 基于對比聚類的對比學習方法 基于不對稱網(wǎng)絡結(jié)構(gòu)的對比學習方法 基于冗余消除損失函數(shù)的對比學習方法

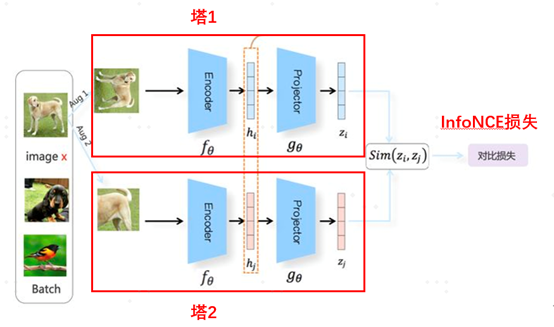
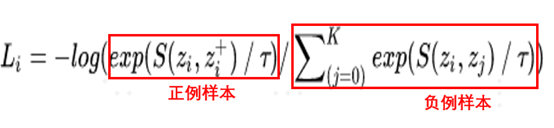
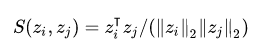
03
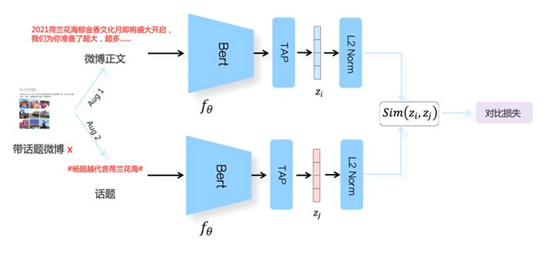
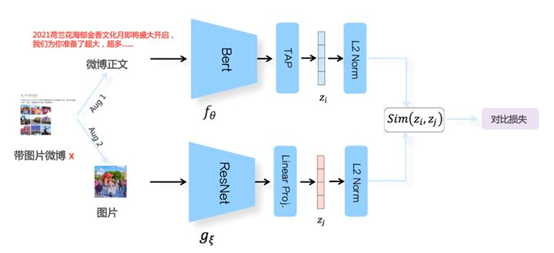
04
05
評論
圖片
表情
<b id="afajh"><abbr id="afajh"></abbr></b>
 下載APP
下載APP知乎專欄:數(shù)據(jù)拾光者 公眾號:數(shù)據(jù)拾光者
01
02
03
04
05
<b id="afajh"><abbr id="afajh"></abbr></b>