
推薦兩本 Spark 好書
點(diǎn)擊藍(lán)色“有關(guān)SQL”關(guān)注我喲
加個(gè)“星標(biāo)”,天天與10000人一起快樂成長

這兩本書,分別是:
《Spark 快速大數(shù)據(jù)分析》 (英文書名《Learning Spark: Lightning-fast Data Analysis》) 《Spark高級數(shù)據(jù)分析》影印版(英文書名《Advanced Analytics with Spark》)
我第一時(shí)間在朋友圈分享這兩本時(shí),很多朋友都跑來“指點(diǎn)”我,你怎么可以看這兩本書呢,你應(yīng)該看 xxx, xxx.
讀書是件很私密的事情,別人告訴你怎么怎么滴,沒有卵用。
你的理解力,你的背景知識結(jié)構(gòu),沒有人比你更清楚。什么階段看什么樣的書,什么樣的書,適合自己讀,需要自己去體驗(yàn)。
別人給你的書單,往往比較“他化”,帶著“他”或“她”的讀書品味。如果書單系統(tǒng)化還行,我最怕的是,在別人的口里做人,做事。萬一錯(cuò)過自己應(yīng)該學(xué)到的,能找上門去算賬么?或許有些人會,但我肯定羞于這么干。
首先來看第一本《Spark快速大數(shù)據(jù)分析》。這本書的4位原作者,清一色技術(shù)出身,全是 Databricks 創(chuàng)始人。而 Databricks 正是孵化 Apache Spark 的公司。
全書210頁,非常薄。我知道大家都深惡痛絕大磚頭,包括學(xué)霸都是。
記得余晟老師(滬江網(wǎng)CTO)曾經(jīng)在一次訪談中談及翻譯正則表達(dá)式那本經(jīng)典書。也是大部頭,他怎么做的呢?趁心血來潮,把書的前半部分翻譯個(gè)上百頁,實(shí)在無聊了,再從中間挑個(gè)上百頁來翻。來回翻騰幾次,書也就翻完了。
所以用這本200頁的書來做入門,非常適宜。
如果你是位新手,對分布式計(jì)算很陌生,只是偶爾從我們微信公眾號《有關(guān)SQL》聽到過這么一個(gè)概念,但你有些編程經(jīng)驗(yàn),對多線程,多進(jìn)程也稍稍耳熟。那么本書的第一部分,5個(gè)章節(jié),不到90頁書,絕對可以讓你快速熟絡(luò) Spark.
Spark 總體框架,可以理解是多線程,多進(jìn)程的衍生。將任務(wù)切割,分發(fā)到很多計(jì)算機(jī)上處理。我大學(xué)同學(xué),老胡,跟我分享過一個(gè)很有意思的例子。你聽聽看。
有天植物生理課,我們在花房修剪殘枝,老讀者都知道,我是學(xué)農(nóng)學(xué)的嘛。他指著根木柴問我,如何讓這根木柴燒得更快?
聽到這樣的開放題,我就很開心,當(dāng)然是澆上汽油。
他似乎沒有被我的笑話冷到,自問自答,把木柴盡可能對半砍,兩頭點(diǎn)上火。砍的次數(shù)越多,燒得越快。
雖然在植物課上提出這樣的題,有些奇怪,但更奇怪的是,后來每次用多線程編程,我總想到這個(gè)例子。
Spark 原理也一樣。一臺計(jì)算機(jī)的計(jì)算資源(CPU個(gè)數(shù))總是恒定的,當(dāng)多線程沾滿資源時(shí),加快計(jì)算的唯一方案,就是利用多臺機(jī)器。
多線程會有一個(gè)主程控制整個(gè)過程,Spark 也有這樣一個(gè)主程,控制每臺計(jì)算機(jī)上跑的進(jìn)程,這個(gè)主程,就是 Driver 程序。切割到每臺機(jī)器上的計(jì)算任務(wù),就由 RDD 包裝起來。
短短這90頁,可以充分學(xué)到 Spark 的核心編程知識。極力推薦各位好好看。多讀幾遍,除非你腦回路驚奇,不然書讀百遍,才是yyds.
縱觀全書,我認(rèn)為可以分成 3 部分。
上面我冒死推薦的,是第一部分。接下來兩部分,是進(jìn)階篇和實(shí)用篇。想要做點(diǎn)實(shí)事,必須要會。
第六章到第八章,是編程進(jìn)階。如果說前五章,讓初學(xué)者可以快速操作數(shù)據(jù),那么這三章,就可以拿來實(shí)戰(zhàn)。比如維度表的 Join, Spark 應(yīng)用的提交以及并行化處理的優(yōu)化,等等。
第九章開始到11章結(jié)束,講的是 Spark 技術(shù)棧的應(yīng)用。比如 Spark SQL, Spark Streaming 和 Spark 機(jī)器學(xué)習(xí)。這三章都偏場景應(yīng)用,可以快速瀏覽。想要深入,請搭配其他書一起看。比如對于 Spark 機(jī)器學(xué)習(xí),下面提到的第二本書,就是絕佳伴侶。
機(jī)器學(xué)習(xí)本身是非常廣的一個(gè)領(lǐng)域,Spark 對它來說,不過是工具。在第一本書中,寥寥幾頁紙,真是不夠的。所以我挑了第二本書來看。這本絕對彪高你的求知荷爾蒙!
來看下書的目錄:

都是和機(jī)器學(xué)習(xí)相關(guān)的場景應(yīng)用。這種學(xué)起來才帶勁。
大數(shù)據(jù)就一工具,如果一開始就蒙頭鉆研其內(nèi)部,被她魅惑了很長時(shí)間,這樣不僅沒有發(fā)揮她最大的功效,而且還會打擊你的積極性。
就像車,造出來是為了讓你開的。只有在開的過程中,你才有可能發(fā)現(xiàn),燃油轉(zhuǎn)換率不高,剎車靈敏度不夠,車身最高平穩(wěn)駕駛速度,等等問題。恰巧你是改裝車迷,那么神仙也擋不住你動(dòng)手了。
如果你是新手,小白,拿到一臺車,不去駕駛,反而在研究各個(gè)零部件是怎么造的,請問,什么時(shí)候你才能帶上妹子去兜風(fēng)?
看這樣的書,挑戰(zhàn)不亞于每月跑10次10公里。剛開始極容易放棄,因?yàn)樘鞖猓驗(yàn)榧影唷V挥袌?jiān)持過最難的那段堅(jiān)持,才會被多巴胺給徹底征服。身心經(jīng)歷過汗水的洗禮,才會升華。
要做出真實(shí)的例子,看一本書完全不夠。比如推薦算法 Alternating Least Squares Recommender :

為了看懂這里面的原理,設(shè)計(jì)和檢測標(biāo)準(zhǔn)。我接連又去看了其他幾本書,還有幾篇論文。本書純碎當(dāng)做是按圖索驥的地圖,經(jīng)過微信讀書,甚至是 wikipedia 的檢索閱讀,最終才對推薦算法的的實(shí)驗(yàn)設(shè)計(jì),步驟和評測標(biāo)準(zhǔn)有了些掌握。
本書在講解 Alternating Least Squares Recommander 算法時(shí),采用了 Latent-factor 模型。如果照著書中所講述的學(xué)下去,可能知道的僅僅是推薦算法中的九牛一毛。真正業(yè)界研究火熱的,是基于鄰域的算法(neighborhood-based).
看到這里,我對推薦算法的實(shí)驗(yàn)設(shè)計(jì)產(chǎn)生了興趣。一個(gè)標(biāo)準(zhǔn)的推薦引擎開發(fā),到底要經(jīng)歷哪些步驟?有沒有什么套路?
于是又找來一本囤積了好久的《推薦系統(tǒng)實(shí)踐》(就是項(xiàng)亮那本,國內(nèi)最早講推薦系統(tǒng))來看。
不得不說,這本書,才是推薦系統(tǒng)的入門經(jīng)典。閱讀了其中30頁關(guān)于推薦系統(tǒng)的設(shè)計(jì),漸漸對 《Advanced Analytics with Spark》有了更全面的認(rèn)識。
比如,推薦系統(tǒng)乃至機(jī)器學(xué)習(xí)整個(gè)流程大致是這樣的:
挑選數(shù)據(jù)模型 設(shè)計(jì)算法 挑選數(shù)據(jù)集 評測算法優(yōu)劣
項(xiàng)亮這本書,系統(tǒng)化講解了推薦算法的實(shí)踐路線。羅列了很多數(shù)據(jù)模型,以及匹配的算法,還有這些算法之間的對比,性能如何。
經(jīng)過一番檢索,我才能知道,原來 Latent-factor 僅僅是一種算法,比他優(yōu)秀的算法還有很多,各自用在哪些領(lǐng)域。在我頭腦中,慢慢建立起一個(gè)完整的推薦算法地圖。
當(dāng)然,項(xiàng)亮的《推薦》也有門檻, 并不是所有對推薦一無所知的人,都可以快速掌握。比如像我這樣,數(shù)學(xué)稀爛的人,對其中的很多術(shù)語,都需要喝上一杯星巴克,才能領(lǐng)悟的了。
在講解精度(Precision)和召回率(Recall)時(shí),項(xiàng)亮用了這兩個(gè)公式和描述:

召回率描述有多少比例的用戶—物品評分記錄包含在最終的推薦列表中,而準(zhǔn)確率描述最終的推薦列表中有多少比例是發(fā)生過的用戶—物品評分記錄
基于他的文字描述,我無法理解兩者的概念。準(zhǔn)備來說,是無法知道兩者的真正不同。(看圖中的公式和表述,一般讀者估計(jì)也難懂)
于是,我又找了深度學(xué)習(xí)的花書。通過微信讀書,看到花書中對精度和召回率的描述。依舊難解。
花書中,對Precision和Recall是這樣描述的:

看完,我更暈了。怎么辦,外事不決,問Google. 我默默打開了 wikipedia.
找到了這段解釋:
Suppose a computer program for recognizing dogs (the relevant element) in photographs identifies eight dogs in a picture containing ten cats and twelve dogs, and of the eight it identifies as dogs, five actually are dogs (true positives), while the other three are cats (false positives). Seven dogs were missed (false negatives), and seven cats were correctly excluded (true negatives). The program's precision is then 5/8 (true positives / all positives) while its recall is 5/12 (true positives / relevant elements).
加上他的配圖:
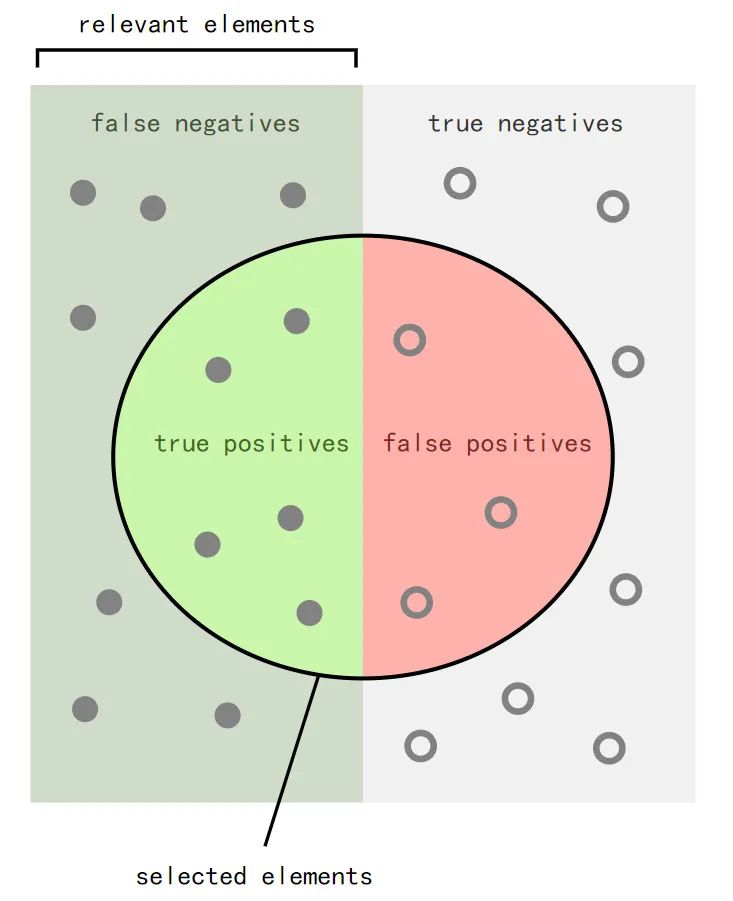

恍然大悟,這不就是我要的答案嘛!
在編程領(lǐng)域,“放棄實(shí)戰(zhàn),則開卷無益”,永遠(yuǎn)正確。通過實(shí)戰(zhàn)領(lǐng)悟的技術(shù)才有意義,從而激發(fā)你更多的靈感。想想看,要是從統(tǒng)計(jì)學(xué),具體數(shù)學(xué)和機(jī)器學(xué)習(xí)一路看上來,得花多少時(shí)間,去學(xué)一堆暫時(shí)用不了的知識,這完全違背實(shí)戰(zhàn)主義的規(guī)律。
所以,在工作之后,我學(xué)會的一個(gè)技能,凡事先從“把大象裝冰箱,需要幾個(gè)步驟”開始構(gòu)思。每一步再拆分可執(zhí)行的小步驟,一步步攻克。
當(dāng)然,如果你還在上大學(xué),有大把時(shí)間,還是非常建議,努力提高自己的數(shù)學(xué)修養(yǎng)。你看,數(shù)學(xué)稀爛的我,只能被 CRUD 的巨浪淹沒。
我的想法是5月份能把這本書看完,但事實(shí)上我真高估自己的水平了,這樣的知識密度,一個(gè)月真不夠讀懂全書。
很多朋友會說,第一本書是2015年出版的,太老了,不適合看。那推薦買第二版的,全進(jìn)口,600多RMB,我料他一定會說浪費(fèi)錢。
當(dāng)然我必須承認(rèn),第一本書以 Spark1.0 為基礎(chǔ)講的,與當(dāng)前的版本說,是陳舊了不少。但基礎(chǔ)知識還是沒變,仍舊具有可讀性。而且概念性寫得比其他國內(nèi)作者好太多。畢竟 Spark 火過那么一段時(shí)間,大量靠翻譯文檔出的書,國內(nèi)有很多,但大多缺乏靈魂。
有些朋友,蘋果設(shè)備,潮牌服裝買得飛起,要他買本100塊的書,恨不得馬上能賺回10倍,才甘心。要不然一句費(fèi)錢就完事。能花個(gè)幾小時(shí)找盜版電子書,堅(jiān)決不買正版書。不要這樣。
對于我,買書是種樂趣;朋友圈打卡讀書,也是;寫書評,更是樂事一件。
往期精彩: