
Pandas 數(shù)據(jù)分析 5 個實用小技巧
三步加星標(biāo)
你好,我是 zhenguo
我攥了很久才匯總出這個小技巧系列手冊,現(xiàn)暫命名為:《Pandas數(shù)據(jù)分析小技巧系列手冊1.0》
我會一篇5個小技巧陸續(xù)推送出來,如果可以歡迎星標(biāo)我的公眾號:Python與算法社區(qū)
小技巧1:如何使用map對某些列做特征工程?
先生成數(shù)據(jù):
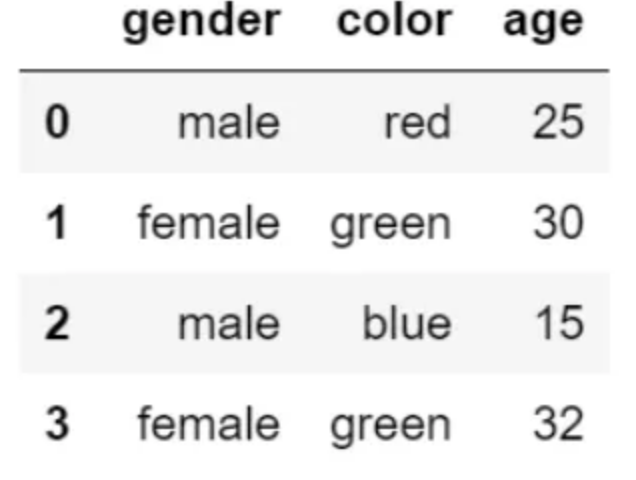
d?=?{
"gender":["male",?"female",?"male","female"],
"color":["red",?"green",?"blue","green"],
"age":[25,?30,?15,?32]
}
df?=?pd.DataFrame(d)
df
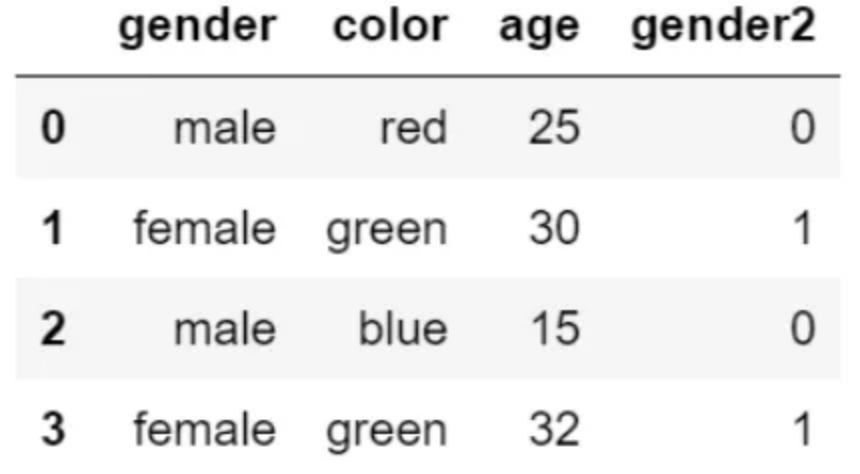
在 gender 列上,使用 map 方法,快速完成如下映射:
d?=?{"male":?0,?"female":?1}
df["gender2"]?=?df["gender"].map(d)
小技巧2:使用 replace 和正則清洗數(shù)據(jù)
Pandas 的強(qiáng)項在于數(shù)據(jù)分析,自然就少不了數(shù)據(jù)清洗。
一個快速清洗數(shù)據(jù)的小技巧,在某列上使用 replace 方法和正則,快速完成值的清洗。
源數(shù)據(jù):
d?=?{"customer":?["A",?"B",?"C",?"D"],
"sales":[1100,?"950.5RMB",?"$400",?"?$1250.75"]}
df?=?pd.DataFrame(d)
df
打印結(jié)果:
customer?sales
0?A?1100
1?B?950.5RMB
2?C?$400
3?D?$1250.75
看到 sales 列的值,有整型,浮點型+RMB后變?yōu)樽址停€有美元+整型,美元+浮點型。
我們的目標(biāo):清洗掉 RMB,$ 符號,轉(zhuǎn)化這一列為浮點型。
一行代碼搞定:(點擊代碼區(qū)域,向右滑動,查看完整代碼)
df["sales"]?=?df["sales"].replace("[$,RMB]",
??????????????????????????????????"",?regex?=?True)?\
.astype("float")
使用正則替換,將要替換的字符放到列表中 [$,RMB],替換為空字符,即 "";
最后使用 astype 轉(zhuǎn)為 float
打印結(jié)果:
customer?sales
0?A?1100.00
1?B?950.50
2?C?400.00
3?D?1250.75
如果不放心,再檢查下值的類型:
df["sales"].apply(type)
打印結(jié)果:
0????<class?'float'>
1????<class?'float'>
2????<class?'float'>
3????<class?'float'>
小技巧3:使用 melt 如何對數(shù)據(jù)透視分析?
構(gòu)造一個 DataFrame:
d?=?{\
"district_code":?[12345,?56789,?101112,?131415],
"apple":?[5.2,?2.4,?4.2,?3.6],
"banana":?[3.5,?1.9,?4.0,?2.3],
"orange":?[8.0,?7.5,?6.4,?3.9]
}
??
df?=?pd.DataFrame(d)
df
打印結(jié)果:
district_code?apple?banana?orange
0123455.23.58.0
1567892.41.97.5
21011124.24.06.4
31314153.62.33.9
5.2 表示 12345 區(qū)域的 apple 價格,并且 apple, banana, orange,這三列都是一種水果,那么如何把這三列合并為一列?
使用 pd.melt
具體參數(shù)取值,根據(jù)此例去推敲:
df?=?df.melt(\
id_vars?=?"district_code",
var_name?=?"fruit_name",
value_name?=?"price")
df
打印結(jié)果:
district_code?fruit_name?price
012345?apple?5.2
156789?apple?2.4
2101112?apple?4.2
3131415?apple?3.6
412345?banana?3.5
556789?banana?1.9
6101112?banana?4.0
7131415?banana?2.3
812345?orange?8.0
956789?orange?7.5
10101112?orange?6.4
11131415?orange?3.9
以上就是長 DataFrame,對應(yīng)的原 DataFrame 是寬 DF.
小技巧4:已知 year 和 dayofyear,怎么轉(zhuǎn) datetime?
原 DataFrame
d?=?{\
"year":?[2019,?2019,?2020],
"day_of_year":?[350,?365,?1]
}
df?=?pd.DataFrame(d)
df
打印結(jié)果:
??year?day_of_year
02019350
12019365
220201
轉(zhuǎn) datetime 的 小技巧
步驟 1: 創(chuàng)建整數(shù)
df["int_number"]?=
df["year"]*1000?+?df["day_of_year"]
打印 df 結(jié)果:
year?day_of_year?int_number
020193502019350
120193652019365
2202012020001
步驟 2: to_datetime
df["date"]=pd.to_datetime(df["int_number"],
format?=?"%Y%j")
注意 "%Y%j" 中轉(zhuǎn)化格式 j
打印結(jié)果:
?year?day_of_year?int_number?date
0201935020193502019-12-16
1201936520193652019-12-31
22020120200012020-01-01
小技巧5:如何將分類中出現(xiàn)次數(shù)較少的值歸為 others?
這也是我們在數(shù)據(jù)清洗、特征構(gòu)造中面臨的一個任務(wù)。
如下一個 DataFrame:
d?=?{"name":['Jone','Alica','Emily','Robert','Tomas',
?????????????'Zhang','Liu','Wang','Jack','Wsx','Guo'],
?????"categories":?["A",?"C",?"A",?"D",?"A",?
????????????????????"B",?"B",?"C",?"A",?"E",?"F"]}
df?=?pd.DataFrame(d)
df
結(jié)果:
?name?categories
0?Jone?A
1?Alica?C
2?Emily?A
3?Robert?D
4?Tomas?A
5?Zhang?B
6?Liu?B
7?Wang?C
8?Jack?A
9?Wsx?E
10?Guo?F
D、E、F 僅在分類中出現(xiàn)一次,A 出現(xiàn)次數(shù)較多。
步驟 1:統(tǒng)計頻次,并歸一
frequencies?=?df["categories"].value_counts(normalize?=?True)
frequencies
結(jié)果:
A????0.363636
B????0.181818
C????0.181818
F????0.090909
E????0.090909
D????0.090909
Name:?categories,?dtype:?float64
步驟 2:設(shè)定閾值,過濾出頻次較少的值
threshold?=?0.1
small_categories?=?frequencies[frequencies?small_categories
結(jié)果:
Index(['F',?'E',?'D'],?dtype='object')
步驟 3:替換值
df["categories"]?=?df["categories"]?\
.replace(small_categories,?"Others")
替換后的 DataFrame:
?name?categories
0?Jone?A
1?Alica?C
2?Emily?A
3?Robert?Others
4?Tomas?A
5?Zhang?B
6?Liu?B
7?Wang?C
8?Jack?A
9?Wsx?Others
10?Guo?Others
福利時間:本次聯(lián)合【機(jī)械工業(yè)出版社華章公司】為大家?guī)怼稒C(jī)器學(xué)習(xí)實戰(zhàn):基于Scikit-Learn、Keras和TensorFlow(原書第2版)》。

《機(jī)器學(xué)習(xí)實戰(zhàn):基于Scikit-Learn、Keras和TensorFlow(原書第2版)》,國外AI“四大名著”之一!AI霸榜書重磅更新!“美亞”AI+神經(jīng)網(wǎng)絡(luò)+CV+NLP四大暢銷榜首圖書,基于TensorFlow 2和新版Scikit-Learn全面升級,內(nèi)容增加近一倍!前谷歌工程師撰寫,Keras之父和TensorFlow移動端負(fù)責(zé)人鼎力推薦,從實踐出發(fā),手把手教你從零開始搭建起一個神經(jīng)網(wǎng)絡(luò)。詳情點擊下面圖片:
送書方法:本次一共送3本,每本149元,含金量很高。首先,關(guān)注我下面這個微信,關(guān)注后再在留言區(qū)聊聊:你和 Python與算法社區(qū) 一起成長的故事,如怎么關(guān)注的,關(guān)注后收獲大不大,學(xué)到什么又有什么建議等,留言最走心的前3名每人一本。