
Kafka 中的再均衡
在Kafka 消費(fèi)者的使用和原理中已經(jīng)提到過“再均衡”的概念,我們先回顧下,一個(gè)主題可以有多個(gè)分區(qū),而訂閱該主題的消費(fèi)組中可以有多個(gè)消費(fèi)者。每一個(gè)分區(qū)只能被消費(fèi)組中的一個(gè)消費(fèi)者消費(fèi),可認(rèn)為每個(gè)分區(qū)的消費(fèi)權(quán)只屬于消費(fèi)組中的一個(gè)消費(fèi)者。但是世界是變化的,例如消費(fèi)者會(huì)宕機(jī),還有新的消費(fèi)者會(huì)加入,而為了應(yīng)對(duì)這些變化,讓分區(qū)所屬權(quán)的分配合理,這都需要對(duì)分區(qū)所屬權(quán)進(jìn)行調(diào)整,也就是所謂的“再均衡”。本文將對(duì)再均衡的相關(guān)知識(shí)進(jìn)行詳細(xì)敘述。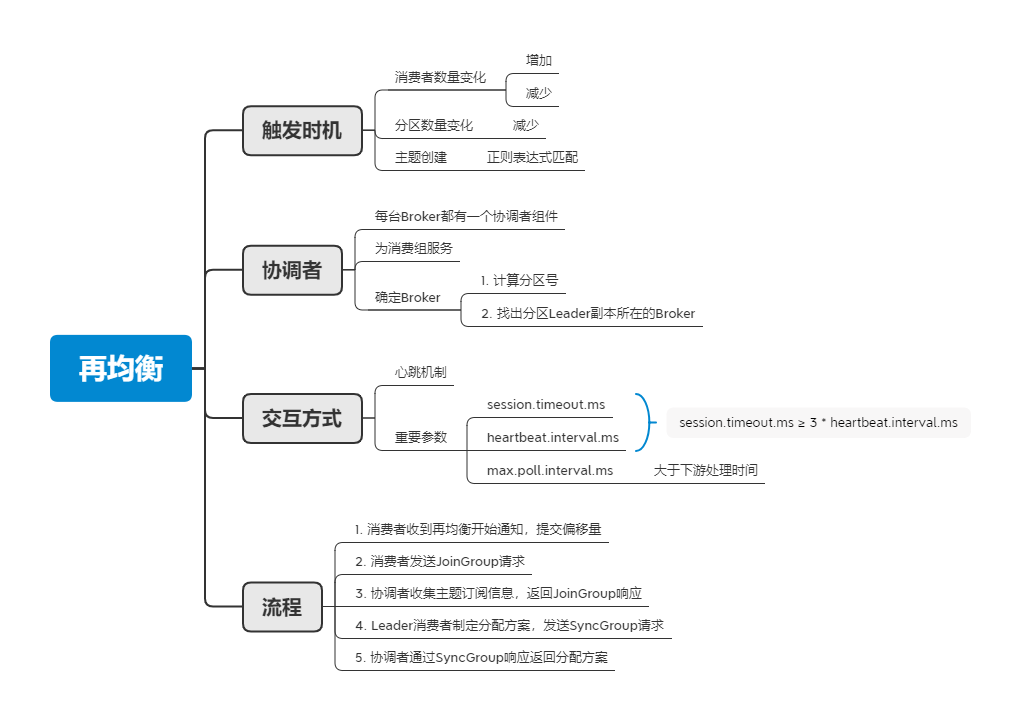
觸發(fā)時(shí)機(jī)
首先,我們需要了解什么情況下會(huì)觸發(fā)再均衡,在前文已經(jīng)提到了消費(fèi)者數(shù)量的變化,是需要再均衡的。在使用Kafka時(shí),除了消費(fèi)者數(shù)量可能會(huì)變化,分區(qū)數(shù)量也同樣可能變化,我們可以人為的對(duì)分區(qū)數(shù)量進(jìn)行修改,但是Kafka只允許增加分區(qū),所以我們只能把分區(qū)數(shù)量調(diào)大,不能調(diào)小,否則會(huì)收到InvalidPartitionException異常。關(guān)于為什么不能減少分區(qū),可參考下面的回答:
按Kafka現(xiàn)有的代碼邏輯,此功能是完全可以實(shí)現(xiàn)的,不過也會(huì)使得代碼的復(fù)雜度急劇增大。實(shí)現(xiàn)此功能需要考慮的因素很多,比如刪除掉的分區(qū)中的消息該作何處理?如果隨著分區(qū)一起消失則消息的可靠性得不到保障;如果需要保留則又需要考慮如何保留。直接存儲(chǔ)到現(xiàn)有分區(qū)的尾部,消息的時(shí)間戳就不會(huì)遞增,如此對(duì)于Spark、Flink這類需要消息時(shí)間戳(事件時(shí)間)的組件將會(huì)受到影響;如果分散插入到現(xiàn)有的分區(qū)中,那么在消息量很大的時(shí)候,內(nèi)部的數(shù)據(jù)復(fù)制會(huì)占用很大的資源,而且在復(fù)制期間,此主題的可用性又如何得到保障?與此同時(shí),順序性問題、事務(wù)性問題、以及分區(qū)和副本的狀態(tài)機(jī)切換問題都是不得不面對(duì)的。反觀這個(gè)功能的收益點(diǎn)卻是很低,如果真的需要實(shí)現(xiàn)此類的功能,完全可以重新創(chuàng)建一個(gè)分區(qū)數(shù)較小的主題,然后將現(xiàn)有主題中的消息按照既定的邏輯復(fù)制過去即可。
簡(jiǎn)單來說,就是做這個(gè)功能需要考慮很多因素,這樣會(huì)把代碼弄的很復(fù)雜,而收益卻很低,而且存在替代方案來實(shí)現(xiàn)該效果,創(chuàng)建一個(gè)分區(qū)數(shù)小的主題,再把當(dāng)前主題遷移過去。
除了消費(fèi)者、分區(qū)數(shù)量的變化,還有一種情況,也需要進(jìn)行再均衡。當(dāng)消費(fèi)者訂閱主題時(shí)使用的是正則表達(dá)式,例如“test.*”,表示訂閱所有以test開頭的主題,當(dāng)有新的以test開頭的主題被創(chuàng)建時(shí),則需要通過再均衡將該主題的分區(qū)分配給消費(fèi)者。
再均衡的三種觸發(fā)時(shí)機(jī),我們已經(jīng)清楚了,下面我們看下再均衡是如何實(shí)現(xiàn)的。
協(xié)調(diào)者
再均衡,將分區(qū)所屬權(quán)分配給消費(fèi)者。因此需要和所有消費(fèi)者通信,這就需要引進(jìn)一個(gè)協(xié)調(diào)者的概念,由協(xié)調(diào)者為消費(fèi)組服務(wù),為消費(fèi)者們做好協(xié)調(diào)工作。在Kafka中,每一臺(tái)Broker上都有一個(gè)協(xié)調(diào)者組件,負(fù)責(zé)組成員管理、再均衡和提交位移管理等工作。如果有N臺(tái)Broker,那就有N個(gè)協(xié)調(diào)者組件,而一個(gè)消費(fèi)組只需一個(gè)協(xié)調(diào)者進(jìn)行服務(wù),那該**由哪個(gè)Broker為其服務(wù)?**確定Broker需要兩步:
計(jì)算分區(qū)號(hào)
partition = Math.abs(groupID.hashCode() % offsetsTopicPartitionCount)根據(jù)
groupID的哈希值,取余offsetsTopicPartitionCount(內(nèi)部主題__consumer_offsets的分區(qū)數(shù),默認(rèn)50)的絕對(duì)值,其意思就是把消費(fèi)組哈希散列到內(nèi)部主題__consumer_offsets的一個(gè)分區(qū)上。確定協(xié)調(diào)者為什么要和內(nèi)部主題扯上關(guān)系。這就跟協(xié)調(diào)者的作用有關(guān)了。協(xié)調(diào)者不僅是負(fù)責(zé)組成員管理和再均衡,在協(xié)調(diào)者中還需要負(fù)責(zé)處理消費(fèi)者的偏移量提交,而偏移量提交則正是提交到__consumer_offsets的一個(gè)分區(qū)上。所以這里需要取余offsetsTopicPartitionCount來確定偏移量提交的分區(qū)。找出分區(qū)Leader副本所在的Broker
確定了分區(qū)就簡(jiǎn)單了,分區(qū)Leader副本所在的Broker上的協(xié)調(diào)者,就是我們要找的。
這個(gè)算法通常用于幫助定位問題。當(dāng)一個(gè)消費(fèi)組出現(xiàn)問題時(shí),我們可以先確定協(xié)調(diào)者的Broker,然后查看Broker端的日志來定位問題。
交互方式
協(xié)調(diào)者,我們確定了。那協(xié)調(diào)者和消費(fèi)者之間是如何交互的?協(xié)調(diào)者如何掌握消費(fèi)者的狀態(tài),又如何通知再均衡。這里使用了心跳機(jī)制。在消費(fèi)者端有一個(gè)專門的心跳線程負(fù)責(zé)以heartbeat.interval.ms的間隔頻率發(fā)送心跳給協(xié)調(diào)者,告訴協(xié)調(diào)者自己還活著。同時(shí)協(xié)調(diào)者會(huì)返回一個(gè)響應(yīng)。而當(dāng)需要開始再均衡時(shí),協(xié)調(diào)者則會(huì)在響應(yīng)中加入REBALANCE_IN_PROGRESS,當(dāng)消費(fèi)者收到響應(yīng)時(shí),便能知道再均衡要開始了。
由于再平衡的開始依賴于心跳的響應(yīng),所以heartbeat.interval.ms除了決定心跳的頻率,也決定了再均衡的通知頻率。
現(xiàn)在我們?cè)僦匦驴聪拢|發(fā)再均衡的時(shí)機(jī),前面說到有三種情況觸發(fā)再均衡,分別是消費(fèi)者數(shù)量的增加或減少、分區(qū)數(shù)的增加和新創(chuàng)建主題,其中消費(fèi)者數(shù)量增加、分區(qū)數(shù)增加和新創(chuàng)建主題,這都是必須是人為操作,算是計(jì)劃內(nèi)的再均衡。而消費(fèi)者數(shù)量減少則除了是人為操作,也可能因?yàn)槠渌驅(qū)е拢瑢儆?strong style="line-height: 1.75em;">計(jì)劃之外的再均衡,這是我們需要關(guān)心的,畢竟再均衡的開銷還是很大的,所有消費(fèi)者都會(huì)停止工作,所以我們應(yīng)盡量避免不必要的再均衡。下面我們看下影響消費(fèi)者數(shù)量減少的參數(shù)有哪些:
session.timeout.ms:Broker端參數(shù),消費(fèi)者的存活時(shí)間,默認(rèn)10秒,如果在這段時(shí)間內(nèi),協(xié)調(diào)者沒收到任何心跳,則認(rèn)為該消費(fèi)者已崩潰離組;heartbeat.interval.ms:消費(fèi)者端參數(shù),發(fā)送心跳的頻率,默認(rèn)3秒;max.poll.interval.ms:消費(fèi)者端參數(shù),兩次調(diào)用poll的最大時(shí)間間隔,默認(rèn)5分鐘,如果5分鐘內(nèi)無法消費(fèi)完,則會(huì)主動(dòng)離組。
可以看出session.timeout.ms和heartbeat.interval.ms是相關(guān)的,這里給出一個(gè)建議參考的公式:
session.timeout.ms ≥ 3 * heartbeat.interval.ms
為盡量避免因?yàn)榕及l(fā)的網(wǎng)絡(luò)原因,心跳無法到達(dá)協(xié)調(diào)者,在超時(shí)之前,應(yīng)至少能發(fā)送3輪心跳。再給出一個(gè)經(jīng)驗(yàn)值的設(shè)置:session.timeout.ms=6s,heartbeat.interval.ms=2s。
max.poll.interval.ms的設(shè)置,則主要和下游處理時(shí)間有關(guān),例如下游處理時(shí)間需要6分鐘,那按默認(rèn)值是不合理的,消費(fèi)者會(huì)頻繁主動(dòng)離組。所以需要把值設(shè)置的比下游處理時(shí)間大一點(diǎn),避免不必要的再均衡。
這一小節(jié)主要講了協(xié)調(diào)者如何通知消費(fèi)者開始再均衡,以及如何設(shè)置參數(shù)避免不必要的再均衡,下面我們看下再均衡的流程是怎么樣的。
流程
當(dāng)消費(fèi)者收到協(xié)調(diào)者的再均衡開始通知時(shí),需要立即提交偏移量; 消費(fèi)者在收到提交偏移量成功的響應(yīng)后,再發(fā)送JoinGroup請(qǐng)求,重新申請(qǐng)加入組,請(qǐng)求中會(huì)含有訂閱的主題信息; 當(dāng)協(xié)調(diào)者收到第一個(gè)JoinGroup請(qǐng)求時(shí),會(huì)把發(fā)出請(qǐng)求的消費(fèi)者指定為Leader消費(fèi)者,同時(shí)等待 rebalance.timeout.ms,在收集其他消費(fèi)者的JoinGroup請(qǐng)求中的訂閱信息后,將訂閱信息放在JoinGroup響應(yīng)中發(fā)送給Leader消費(fèi)者,并告知他成為了Leader,同時(shí)也會(huì)發(fā)送成功入組的JoinGroup響應(yīng)給其他消費(fèi)者;Leader消費(fèi)者收到JoinGroup響應(yīng)后,根據(jù)消費(fèi)者的訂閱信息制定分配方案,把方案放在SyncGroup請(qǐng)求中,發(fā)送給協(xié)調(diào)者。普通消費(fèi)者在收到響應(yīng)后,則直接發(fā)送SyncGroup請(qǐng)求,等待Leader的分配方案; 協(xié)調(diào)者收到分配方案后,再通過SyncGroup響應(yīng)把分配方案發(fā)給所有消費(fèi)組。 當(dāng)所有消費(fèi)者收到分配方案后,就意味著再均衡的結(jié)束,可以正常開始消費(fèi)工作了。 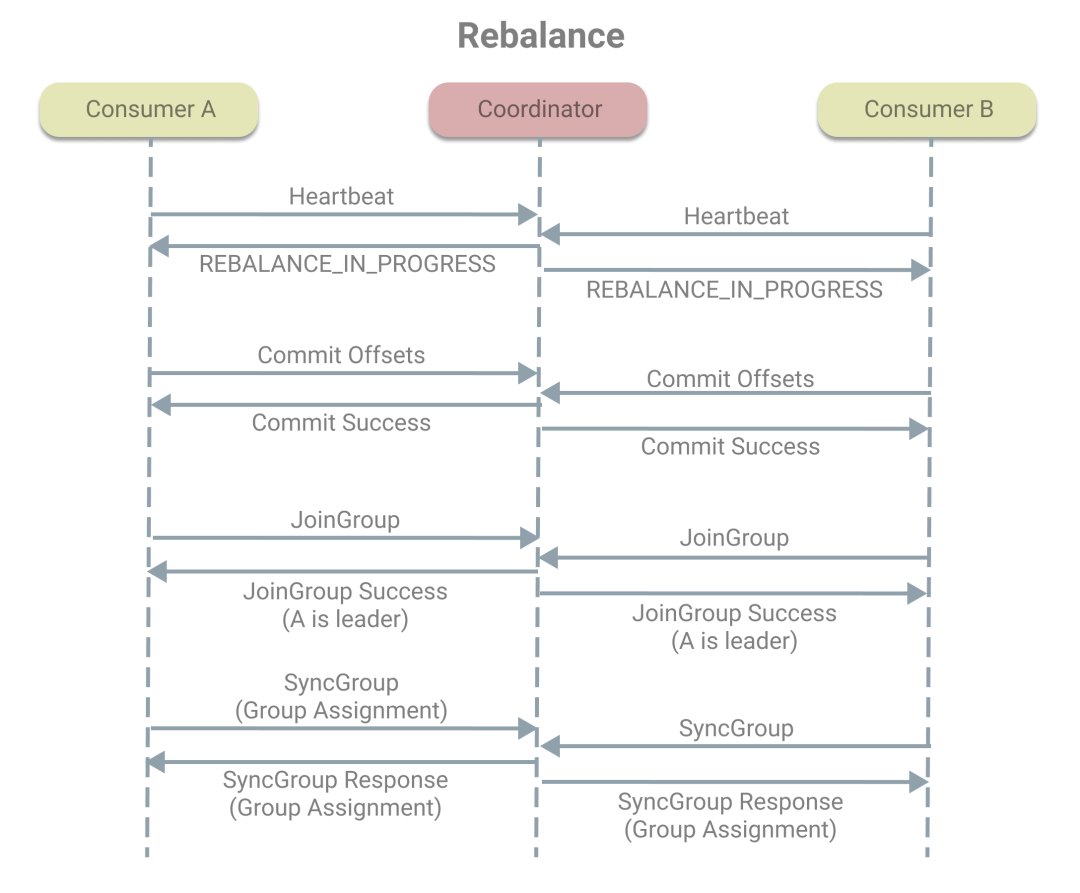
參考
《深入理解Kafka》 《Kafka核心技術(shù)與實(shí)戰(zhàn)》 Kafka之Group狀態(tài)變化分析及Rebalance過程:?https://matt33.com/2017/01/16/kafka-group/#Consumer-初始化時(shí)-group-狀態(tài)變化
完
? ? ? ?
 ???
???覺得不錯(cuò),點(diǎn)個(gè)在看~
