
SRCNN:基于深度學(xué)習(xí)的超分辨率開山之作回顧

來(lái)源:DeepHub IMBA 本文約1800字,建議閱讀5分鐘
本文將介紹CNN 如何用于單圖像超分辨率(SISR)。
本文提供了與SRCNN論文的總結(jié)和回顧,如果你對(duì)于圖像的超分辨率感興趣,一定要先閱讀這篇論文,他可以說(shuō)是所有基于深度學(xué)習(xí)的超分辨率模型的鼻祖。
卷積神經(jīng)網(wǎng)絡(luò)通常用于分類,目標(biāo)檢測(cè),圖像分割等與某些與圖像有關(guān)的問題中。
在本文中,將介紹CNN 如何用于單圖像超分辨率(SISR)。這有助于解決與計(jì)算機(jī)視覺相關(guān)的各種其他問題。在CNN出現(xiàn)之前,傳統(tǒng)的方法是使用最近鄰插值、雙線性或雙三次插值等上采樣方法,也可以取得不錯(cuò)的效果。
Nearest Neighbors Interpolation — 最近鄰插值是一種簡(jiǎn)單明了的方法。它為每個(gè)插值點(diǎn)選擇最近像素的值,而不考慮任何其他像素的值。
Bilinear Interpolation (BLI) — 雙線性插值 這是一種在圖像的一個(gè)軸上進(jìn)行線性插值,然后再移動(dòng)到另一個(gè)軸的技術(shù)。因?yàn)樗a(chǎn)生了一個(gè)接受域大小為 2x2 的二次插值,所以它在保持合理速度的同時(shí)優(yōu)于最近鄰插值。
Bicubic Interpolation(BCI) — 雙三次插值與雙線性插值一樣,雙三次插值 (BCI) 在兩個(gè)軸上進(jìn)行。與 BLI 相比,BCI 考慮 4x4 像素,從而產(chǎn)生更平滑的輸出,具有更少的偽影,但速度要慢得多。

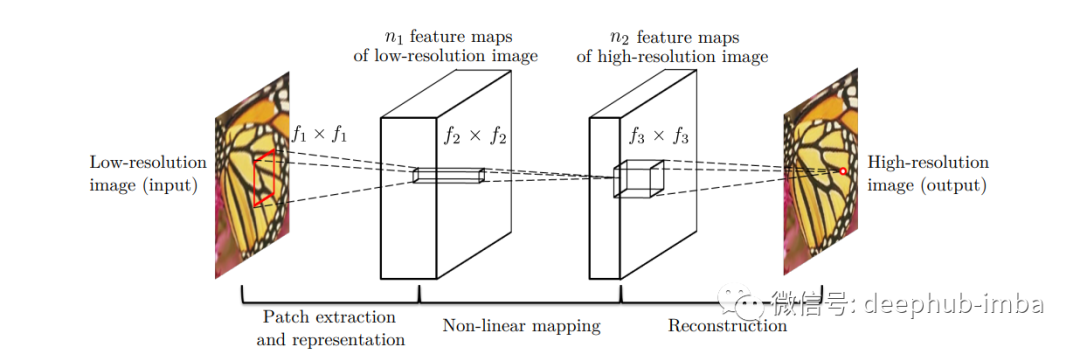
本文介紹的SRCNN 模型基本由三個(gè)使用步驟組成:
區(qū)塊補(bǔ)丁提取和表示
非線性映射
重建
相關(guān)工作
一般情況下 SISR (Single Image Super Resolution,)可以總結(jié)為以下4種方法——預(yù)測(cè)模型、基于邊緣的方法、圖像統(tǒng)計(jì)方法和基于補(bǔ)丁(或基于樣本)的方法。SRCNN 使用基于補(bǔ)丁的方法。利用輸入圖像內(nèi)部樣本的自相似性屬性來(lái)生成補(bǔ)丁。SRCNN 使用稀疏編碼公式來(lái)映射低分辨率和高分辨率的補(bǔ)丁,并且圖像考慮了 YCbCr 顏色通道。
用于圖像恢復(fù)的深度學(xué)習(xí)
大多數(shù)圖像恢復(fù)深度學(xué)習(xí)方法都是去噪驅(qū)動(dòng)的。雖然自編碼器不能提供從低分辨率到高分辨率圖像的端到端映射,但是在去噪圖像領(lǐng)域表現(xiàn)得非常好,而SRCNN 專注于解決這個(gè)問題。
CNN 超分辨率
對(duì)于一個(gè)單一的低分辨率圖像:首先使用雙三次插值將其放大到適當(dāng)?shù)拇笮。@是唯一要做的預(yù)處理。使用術(shù)語(yǔ)“Y”來(lái)描述我們正在談?wù)摰膬?nèi)容。Y 是插值圖像。我們的目標(biāo)是讓圖像 F(Y) 回到與高分辨率真實(shí)圖像 (X) 盡可能接近的 Y 上。我們?nèi)匀粚?Y 稱為“低分辨率”,因?yàn)樗子诔尸F(xiàn),盡管它與 (X) 大小相同。而模型的目的是學(xué)習(xí) F(Y) 映射,它由三部分操作組成:
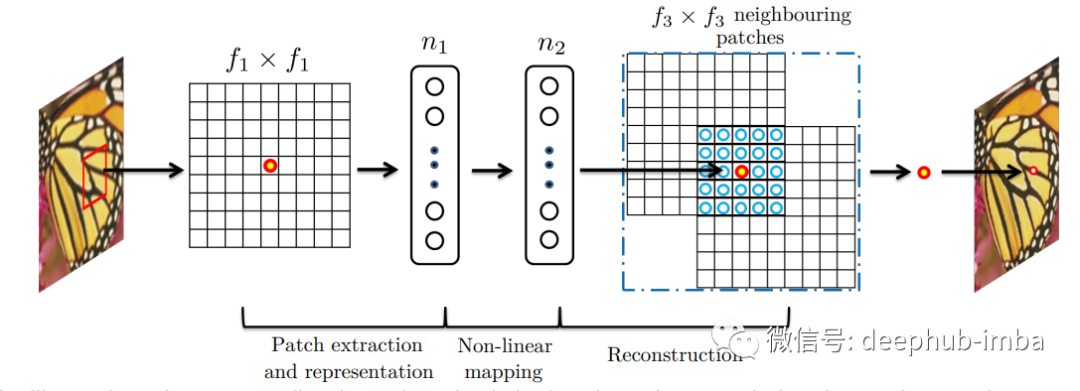
1. 補(bǔ)丁提取和表示:該操作從低分辨率圖像 Y 中提取(重疊)補(bǔ)丁,然后將每個(gè)補(bǔ)丁表示為一個(gè)高維向量。這些向量由一組特征圖組成,其數(shù)量等于向量的維度。
2. 非線性映射:每個(gè)高維向量在這個(gè)過(guò)程中非線性映射到另一個(gè)高維向量上。高分辨率補(bǔ)丁在概念上由每個(gè)映射向量表示。另一個(gè)特征圖集合由這些向量組成。
3. 重建:這個(gè)過(guò)程結(jié)合了前面提到的高分辨率補(bǔ)丁表示來(lái)產(chǎn)生最終的高分辨率圖像。此圖像應(yīng)類似于 X 真實(shí)圖像。
補(bǔ)丁提取和表示
采用提取小塊的方法,通過(guò)一組預(yù)訓(xùn)練的基礎(chǔ)(例如 PCA、DCT離散余弦變換等)來(lái)表示它,這種技術(shù)非常的常見。這與通過(guò)一系列卷積核(過(guò)濾器)的運(yùn)行圖像相同。操作表示為:這里 W1,B1 是過(guò)濾器和偏差,* 表示執(zhí)行卷積。W1 是支持 c x f1 x f1 的 n1 個(gè)過(guò)濾器,其中 c 代表通道,f1 是過(guò)濾器的大小。B1 的大小為 n1。
非線性映射
執(zhí)行非線性映射以減少維度,并嘗試保持?jǐn)?shù)據(jù)點(diǎn)之間的距離。
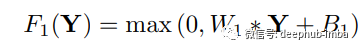
這里 W2 是 n1 x f2 x f2 x n2 并且 f2 = 1 ,n1>n2。
重建
最后,卷積層再次用于生成最終的高分辨率圖像。
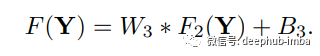
W3 的大小為 n2 x f3 x f3,B3 是 c 維向量。
與基于稀疏編碼的方法的關(guān)系
在稀疏編碼(Sparse Coding / SC)的情況下,輸入圖片通過(guò) f1 進(jìn)行卷積并投影到 n1 維字典上。在大多數(shù)情況下 n1=n2 。然后,在沒有減少維度的情況下,n1 到 n2 被映射為相同的維度。它類似于將低分辨率矢量映射到高分辨率矢量。之后f3 重建每個(gè)補(bǔ)丁并卷積對(duì)重疊的補(bǔ)丁進(jìn)行平均,而不是將它們與不同的權(quán)重放在一起。
訓(xùn)練過(guò)程
訓(xùn)練圖像時(shí)的損失函數(shù)是 MSE 均方誤差。
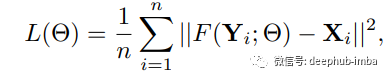
模型使用 T91和 ImageNet 進(jìn)行訓(xùn)練。為了評(píng)估 SRCNN,考慮了圖像恢復(fù)中流行的評(píng)估指標(biāo) PSNR(峰值信噪比)。T91個(gè)圖像數(shù)據(jù)集的 SRCNN 為 31.42,ImageNet 數(shù)據(jù)集為 35.2 dB(分貝),與之前的超分辨率技術(shù)相比,兩者的性能都非常出色。
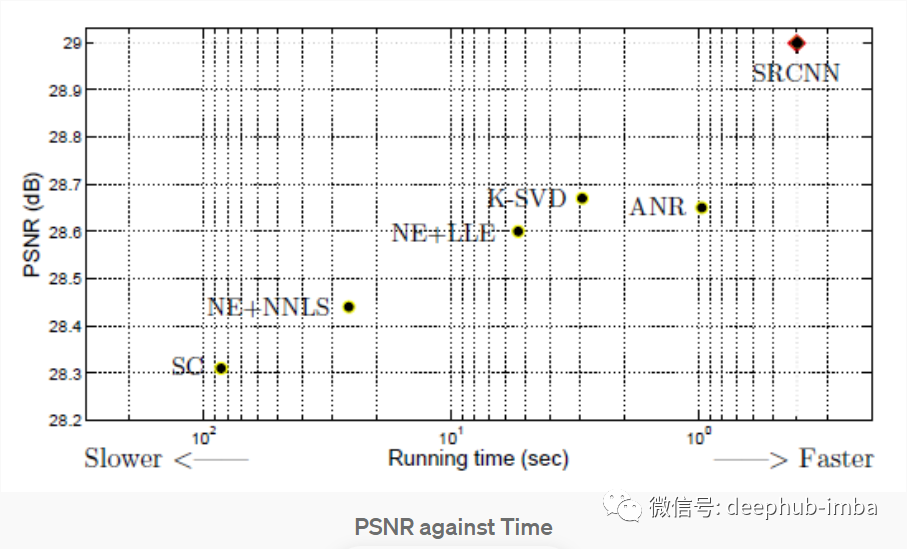
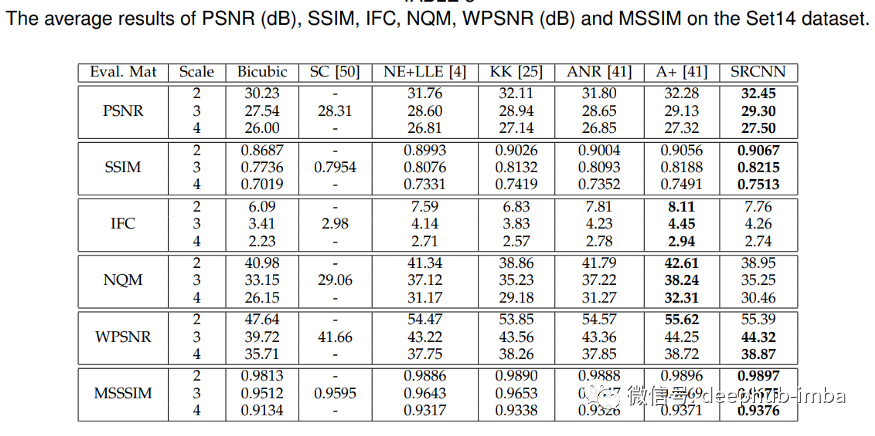
上圖中可以看到 SRCNN 表現(xiàn)更好,在圖像超分辨率 SRCNN 的其他評(píng)估指標(biāo)中也表現(xiàn)良好。Set14 數(shù)據(jù)集是來(lái)自 T91 圖像數(shù)據(jù)集的子圖像,其中 24.800 個(gè)子圖像使用步幅 14 和高斯模糊。
總結(jié)
經(jīng)過(guò)這么多年的發(fā)展,相比于SRGAN 等圖像超分辨率的最先進(jìn)模型,SRCNN肯定已經(jīng)被超越了。但是SRCNN 是一個(gè)簡(jiǎn)單模型,使用僅僅3層就解決了解決圖像恢復(fù)問題并且產(chǎn)生了非常好的效果,目前超分方向的論文基本上都是以他的研究為基礎(chǔ)的,所以如果你對(duì)圖像超分感興趣,或者想深入學(xué)習(xí)的話,這篇論文一定要看。
論文地址:
Image Super-Resolution Using Deep Convolutional Networks https://arxiv.org/abs/1501.00092
最后這里有個(gè)完整代碼,可以直接線上運(yùn)行:
https://colab.research.google.com/drive/1qGit7oTmIBPcFdu9CR5jH7sMe0X_4Qeg?usp=sharing
作者:Jitesh Rawat
編輯:黃繼彥