
人人都能讀懂的編譯器原理
作者注:
?簡(jiǎn)單介紹?
編譯器是什么?
編譯器是做什么的?
從你給定的源代碼中讀取單個(gè)詞。 把這些詞按照單詞、數(shù)字、符號(hào)、運(yùn)算符進(jìn)行分類。 通過模式匹配從分好類的單詞中找出運(yùn)算符,明確這些運(yùn)算符想進(jìn)行的運(yùn)算,然后產(chǎn)生一個(gè)運(yùn)算符的樹(表達(dá)式樹)。 最后一步遍歷表達(dá)式樹中的所有運(yùn)算符,產(chǎn)生相應(yīng)的二進(jìn)制數(shù)據(jù)。
解釋器是什么?
1. 詞法分析
2+2?– 其實(shí)這個(gè)表達(dá)式只有三種?標(biāo)記:一個(gè)數(shù)字:2,一個(gè)加號(hào),另外一個(gè)數(shù)字:2。12+3?這樣的字符串:它會(huì)讀入字符?1,2,+,和?3。我們已經(jīng)把這些字符拆分開了,但是現(xiàn)在我們必須把他們組合起來;這是分詞器的主要任務(wù)之一。舉個(gè)例子,我們得到了兩個(gè)單獨(dú)的字符?1?和?2,但是我們需要把它們放到一起,然后把它們解析成為一個(gè)整數(shù)。至于?+也需要被識(shí)別為加號(hào),而不是它的字符值 – 字符值是43 。C 語言的樣例代碼已經(jīng)進(jìn)行過詞法分析,并且輸出了它的標(biāo)記
2. 解析
int a = 3?和?a: int = 3?的區(qū)別在于解析器的處理上面。解析器決定了語法的外在形式是怎樣的。它確保括號(hào)和花括號(hào)的左右括號(hào)是數(shù)量平衡的,每個(gè)語句結(jié)尾都有一個(gè)分號(hào),每個(gè)函數(shù)都有一個(gè)名稱。當(dāng)標(biāo)記不符合預(yù)期的模式時(shí),解析器就會(huì)知道標(biāo)記的順序不正確。12+3?:expr?解析器,因?yàn)樗苯优c所有內(nèi)容都相關(guān)的頂層。唯一有效的輸入必須是任意數(shù)字,加號(hào)或減號(hào),任意數(shù)字。expr?需要一個(gè)?additive_expr,這主要出現(xiàn)在加法和減法表達(dá)式中。additive_expr?首先需要一個(gè)?term?(一個(gè)數(shù)字),然后是加號(hào)或者減號(hào),最后是另一個(gè)?term?。// BEGIN PARSER //?和?// END PARSER //?的注釋標(biāo)記出了新的解析器代碼的開頭和結(jié)尾。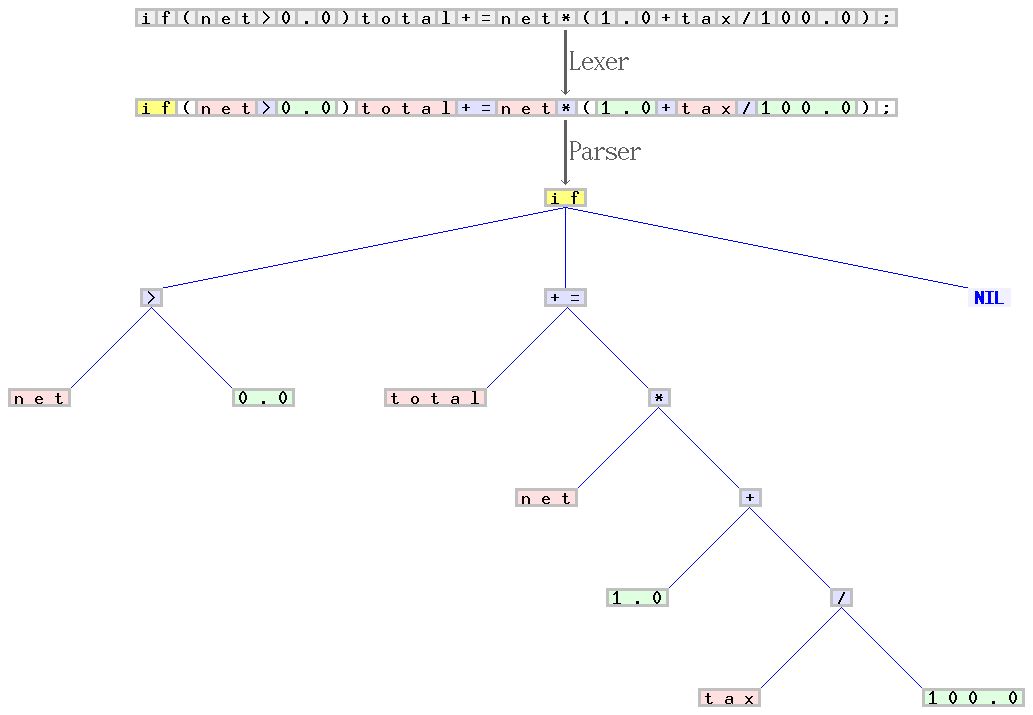
針對(duì) C 語言語法編寫的解析器(又叫做詞法分析器)和解析器樣例。從字符序列的開始 “if(net>0.0)total+=net(1.0+tax/100.0);”,掃描器組成了一系列標(biāo)記,并且對(duì)它們進(jìn)行分類,例如,標(biāo)識(shí)符,保留字,數(shù)字,或者運(yùn)算符。后者的序列由解析器轉(zhuǎn)換成語法樹,然后由其他的編譯器分階段進(jìn)行處理。掃描器和解析器分別處理 C 語法中的規(guī)則和與上下文無關(guān)的部分。引自:Jochen Burghardt.來源.
3. 生成代碼
-O?).s?或?.asm)。然后該文件會(huì)被傳遞給匯編器,匯編器是匯編語言的編譯器,它會(huì)生成相應(yīng)的二進(jìn)制代碼。之后這些二進(jìn)制代碼會(huì)被寫入到一個(gè)新的目標(biāo)文件中 (.o) 。?總結(jié)?
評(píng)論
圖片
表情