
大廠是怎么干掉OOM的?
不點藍字關(guān)注,我們哪來故事?
一個指導程序員進入大公司/獨角獸的精品社群,致力于分享職場達人的專業(yè)打法,包括「學習路線+簡歷模板+實習避坑+筆試面試+試用轉(zhuǎn)正+升職加薪+跳槽技巧」。
隨著項目不斷壯大,OOM(Out Of Memory)成為崩潰統(tǒng)計平臺上的疑難雜癥之一,大部分業(yè)務(wù)開發(fā)人員對于線上OOM問題一般都是暫不處理,一方面是因為OOM問題沒有足夠的log,無法在短期內(nèi)分析解決,另一方面可能是忙于業(yè)務(wù)迭代、身心疲憊,沒有精力去研究OOM的解決方案。
這篇文章將以線上OOM問題作為切入點,介紹常見的OOM類型、OOM的原理、大廠OOM優(yōu)化黑科技、以及主流的OOM監(jiān)控方案。
文章較長,請備好小板凳~
OOM問題分類
很多人對于OOM的理解就是Java虛擬機內(nèi)存不足,但通過線上OOM問題分析,OOM可以大致歸為以下3類:
線程數(shù)太多 打開太多文件 內(nèi)存不足
接下來將分別圍繞這三類問題進行展開分析~
三、線程數(shù)太多
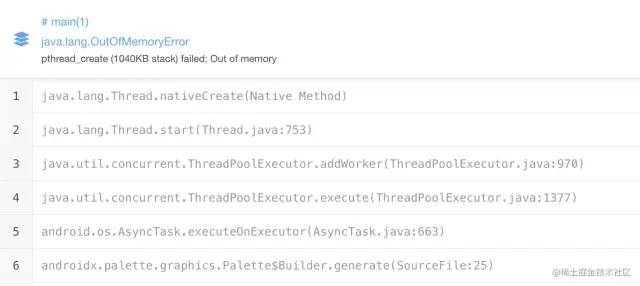
3.1 報錯信息
pthread_create?(1040KB?stack)?failed:?Out?of?memory
這個是典型的創(chuàng)建新線程觸發(fā)的OOM問題
3.2 源碼分析
pthread_create觸發(fā)的OOM異常,源碼(Android 9)位置如下:androidxref.com/9.0.0_r3/xr…
void Thread::CreateNativeThread(JNIEnv* env, jobject java_peer, size_t stack_size, bool is_daemon) {
...
pthread_create_result = pthread_create(...)
//創(chuàng)建線程成功
if (pthread_create_result == 0) {
return;
}
//創(chuàng)建線程失敗
...
{
std::string msg(child_jni_env_ext.get() == nullptr ?
StringPrintf("Could not allocate JNI Env: %s", error_msg.c_str()) :
StringPrintf("pthread_create (%s stack) failed: %s",
PrettySize(stack_size).c_str(), strerror(pthread_create_result)));
ScopedObjectAccess soa(env);
soa.Self()->ThrowOutOfMemoryError(msg.c_str());
}
}
復(fù)制代碼
pthread_create里面會調(diào)用Linux內(nèi)核創(chuàng)建線程,那什么情況下會創(chuàng)建線程失敗呢?
查看系統(tǒng)對每個進程的線程數(shù)限制
cat /proc/sys/kernel/threads-max

不同設(shè)備的threads-max限制是不一樣的,有些廠商的低端機型threads-max比較小,容易出現(xiàn)此類OOM問題。
查看當前進程運行的線程數(shù)
cat proc/{pid}/status
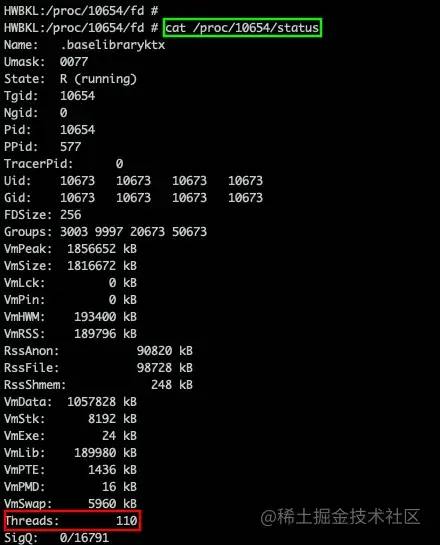
當線程數(shù)超過/proc/sys/kernel/threads-max中規(guī)定的上限時就會觸發(fā)OOM。
既然系統(tǒng)對每個進程的線程數(shù)有限制,那么解決這個問題的關(guān)鍵就是盡可能降低線程數(shù)的峰值。
線程優(yōu)化
回看兩年前我寫過一篇文章《面試官:今日頭條啟動很快,你覺得可能是做了哪些優(yōu)化?》,雖然里面的內(nèi)容有些已經(jīng)過時,不過分析問題的思路還是可以借鑒的,記得當時對于線程優(yōu)化只是一句話描述,今天這篇文章剛好可以做一個補充。
3.3.1 禁用 new Thread
解決線程過多問題,傳統(tǒng)的方案是禁止使用new Thread,統(tǒng)一使用線程池,但是一般很難人為控制, 可以在代碼提交之后觸發(fā)自動檢測,有問題則通過郵件通知對應(yīng)開發(fā)人員。
不過這種方式存在兩個問題:
無法解決老代碼的 new Thread;對于第三方庫無法控制。
3.3.2 無侵入性的new Thread 優(yōu)化
Java層的Thread只是一個普通的對象,只有調(diào)用了start方法,才會調(diào)用native 層去創(chuàng)建線程,
所以理論上我們可以自定義Thread,重寫start方法,不去啟動線程,而是將任務(wù)放到線程池中去執(zhí)行,為了做到無侵入性,需要在編譯期通過字節(jié)碼插樁的方式,將所有new Thread字節(jié)碼都替換成new 自定義Thread。
對于字節(jié)碼操作,在上一篇文章《ASM hook隱私方法調(diào)用,防止App被下架》已經(jīng)詳細介紹,本文不再過多解釋。
步驟如下:
1、創(chuàng)建一個Thread的子類叫ShadowThread吧,重寫start方法,調(diào)用自定義的線程池CustomThreadPool來執(zhí)行任務(wù);
public?class?ShadowThread?extends?Thread?{
????@Override
????public?synchronized?void?start()?{
????????Log.i("ShadowThread",?"start,name="+?getName());
????????CustomThreadPool.THREAD_POOL_EXECUTOR.execute(new?MyRunnable(getName()));
????}
????class?MyRunnable?implements?Runnable?{
????????String?name;
????????public?MyRunnable(String?name){
????????????this.name?=?name;
????????}
????????@Override
????????public?void?run()?{
????????????try?{
????????????????ShadowThread.this.run();
????????????????Log.d("ShadowThread","run?name="+name);
????????????}?catch?(Exception?e)?{
????????????????Log.w("ShadowThread","name="+name+",exception:"+?e.getMessage());
????????????????RuntimeException?exception?=?new?RuntimeException("threadName="+name+",exception:"+?e.getMessage());
????????????????exception.setStackTrace(e.getStackTrace());
????????????????throw?exception;
????????????}
????????}
????}
}
復(fù)制代碼
2、在編譯期,hook 所有new Thread字節(jié)碼,全部替換成我們自定義的ShadowThread,這個難度應(yīng)該不大,按部就班,
我們先確認new Thread和new ShadowThread對應(yīng)字節(jié)碼差異,可以安裝一個ASM Bytecode Viewer插件,如下所示
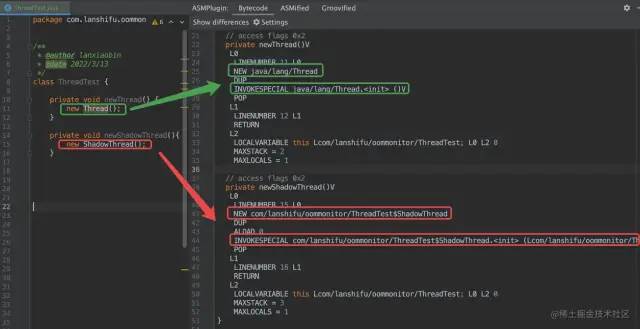
通過字節(jié)碼修改,你可以簡單理解為做如下替換:
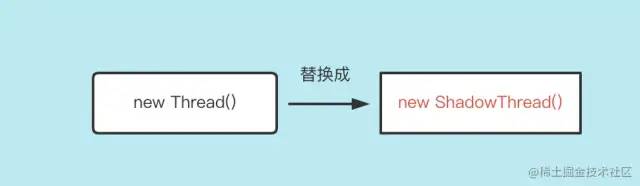
3、由于將任務(wù)放到線程池去執(zhí)行,假如線程奔潰了,我們不知道是哪個線程出問題,所以自定義ShadowThread中的內(nèi)部類MyRunnable 的作用是:在線程出現(xiàn)異常的時候,將異常捕獲,還原它的名字,重新拋出一個信息更全的異常。
測試代碼
????private?fun?testThreadCrash()?{
????????Thread?{
????????????val?i?=?9?/?0
????????}.apply?{
????????????name?=?"testThreadCrash"
????????}.start()
????}
復(fù)制代碼
開啟一個線程,然后觸發(fā)奔潰,堆棧信息如下:

可以看到原本的new Thread已經(jīng)被優(yōu)化成了CustomThreadPool線程池調(diào)用,并且奔潰的時候不用擔心找不到線程是哪里創(chuàng)建的,會還原線程名。
當然這種方式有一個小問題,應(yīng)用正常運行的情況下,如果你想要收集所有線程信息,那么線程名可能不太準確,因為通過new Thread 去創(chuàng)建線程,已經(jīng)被替換成線程池調(diào)用了,獲取到的線程名是線程池中的線程的名字
數(shù)據(jù)對比
同個場景簡單測試了一下new Thread優(yōu)化前后線程數(shù)峰值對比:
| 線程數(shù)峰值(優(yōu)化前) | 線程數(shù)峰值(優(yōu)化后) | 降低最大線程數(shù) |
|---|---|---|
| 337 | 314 | 23 |
對于不同App,優(yōu)化效果會有一些不同,不過可以看到這個優(yōu)化確實是有效的。
3.3.3 無侵入的線程池優(yōu)化
隨著項目引入的SDK越來越多,絕大部分SDK內(nèi)部都會使用自己的線程池做異步操作,
線程池的參數(shù)如果設(shè)置不對,核心線程空閑的時候沒有釋放,會使整體的線程數(shù)量處于較高位置。
線程池幾個參數(shù):
????public?ThreadPoolExecutor(int?corePoolSize,
??????????????????????????????int?maximumPoolSize,
??????????????????????????????long?keepAliveTime,
??????????????????????????????TimeUnit?unit,
??????????????????????????????BlockingQueue?workQueue,
??????????????????????????????ThreadFactory?threadFactory)?{
????????this(corePoolSize,?maximumPoolSize,?keepAliveTime,?unit,?workQueue,
?????????????threadFactory,?defaultHandler);
????}
復(fù)制代碼
corePoolSize:核心線程數(shù)量。核心線程默認情況下即使空閑也不會釋放,除非設(shè)置 allowCoreThreadTimeOut為true。maximumPoolSize:最大線程數(shù)量。任務(wù)數(shù)量超過核心線程數(shù),就會將任務(wù)放到隊列中,隊列滿了,就會啟動非核心線程執(zhí)行任務(wù),線程數(shù)超過這個限制就會走拒絕策略; keepAliveTime:空閑線程存活時間 unit:時間單位 workQueue:隊列。任務(wù)數(shù)量超過核心線程數(shù),就會將任務(wù)放到這個隊列中,直到隊列滿,就開啟新線程,執(zhí)行隊列第一個任務(wù)。 threadFactory:線程工廠。實現(xiàn)new Thread方法創(chuàng)建線程
通過線程池參數(shù),我們可以找到優(yōu)化點如下:
限制空閑線程存活時間, keepAliveTime設(shè)置小一點,例如1-3s;允許核心線程在空閑時自動銷毀
executor.allowCoreThreadTimeOut(true)
復(fù)制代碼
如何做呢?為了做到無侵入性,依然采用ASM操作字節(jié)碼,跟new Thread的替換基本同理
在編譯期,通過ASM,做如下幾個操作:
將調(diào)用 Executors類的靜態(tài)方法替換為自定義ShadowExecutors的靜態(tài)方法,設(shè)置executor.allowCoreThreadTimeOut(true);將調(diào)用 ThreadPoolExecutor類的構(gòu)造方法替換為自定義ShadowThreadPoolExecutor的靜態(tài)方法,設(shè)置executor.allowCoreThreadTimeOut(true);可以在 Application 類的 () 中調(diào)用我們自定義的靜態(tài)方法 ShadowAsyncTask.optimizeAsyncTaskExecutor()來修改 AsyncTask 的線程池參數(shù),調(diào)用executor.allowCoreThreadTimeOut(true);
你可以簡單理解為做如下替換:
詳細代碼可以參考 booster。
3.4 線程監(jiān)控
假如線程優(yōu)化后還存在創(chuàng)建線程OOM問題,那我們就需要監(jiān)控是否存在線程泄漏的情況。
3.4.1 線程泄漏監(jiān)控
主要監(jiān)控native線程的幾個生命周期方法:pthread_create、pthread_detach、pthread_join、pthread_exit。
hook 以上幾個方法,用于記錄線程的生命周期和堆棧,名稱等信息; 當發(fā)現(xiàn)一個joinable的線程在沒有detach或者join的情況下,執(zhí)行了pthread_exit,則記錄下泄露線程信息; 在合適的時機,上報線程泄露信息。
linux線程中,pthread有兩種狀態(tài)joinable狀態(tài)和unjoinable狀態(tài)。joinable狀態(tài)下,當線程函數(shù)自己返回退出時或pthread_exit時都不會釋放線程所占用堆棧和線程描述符。只有當你調(diào)用了pthread_join之后這些資源才會被釋放,需要main函數(shù)或者其他線程去調(diào)用pthread_join函數(shù)。
具體代碼可以參考:KOOM-thread_holder
3.4.2 線程上報
當監(jiān)控到線程有異常的時候,我們可以收集線程信息,上報到后臺進行分析。
收集線程信息代碼如下:
????private?fun?dumpThreadIfNeed()?{
????????val?threadNames?=?runCatching?{?File("/proc/self/task").listFiles()?}
????????????.getOrElse?{
????????????????return@getOrElse?emptyArray()
????????????}
?????????????.map?{
????????????????runCatching?{?File(it,?"comm").readText()?}.getOrElse?{?"failed?to?read?$it/comm"?}
????????????}
?????????????.map?{
????????????????if?(it.endsWith("\n"))?it.substring(0,?it.length?-?1)?else?it
????????????}
?????????????:?emptyList()
????????Log.d("TAG",?"dumpThread?=?"?+?threadNames.joinToString(separator?=?","))
????}
復(fù)制代碼
接下來介紹打開太多文件導致的OOM問題
四、打開太多文件
4.1 錯誤信息
E/art:?ashmem_create_region?failed?for?'indirect?ref?table':?Too?many?open?files
Java.lang.OutOfMemoryError:?Could?not?allocate?JNI?Env
復(fù)制代碼
這個問題跟系統(tǒng)、廠商關(guān)系比較大
4.2 系統(tǒng)限制
Android是基于Linux內(nèi)核,/proc/pid/limits 描述著linux系統(tǒng)對每個進程的一些資源限制,
如下圖是一臺Android 6.0的設(shè)備,Max open files的限制是1024
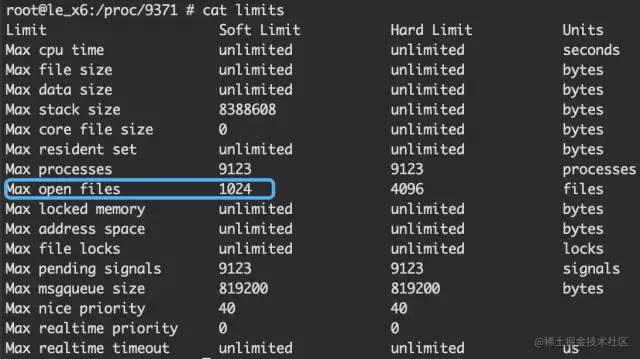
如果沒有root權(quán)限,可以通過ulimit -n命令查看Max open files,結(jié)果是一樣的
ulimit -n

Linux 系統(tǒng)一切皆文件,進程每打開一個文件就會產(chǎn)生一個文件描述符fd(記錄在/proc/pid/fd下面)
cd /proc/10654/fd
ls
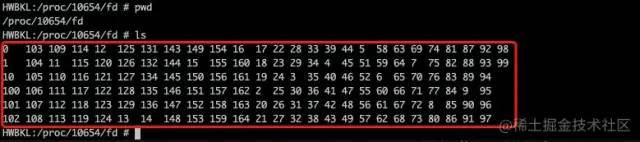
這些fd文件都是鏈接文件,通過 ls -l可以查看其對應(yīng)的真實文件路徑
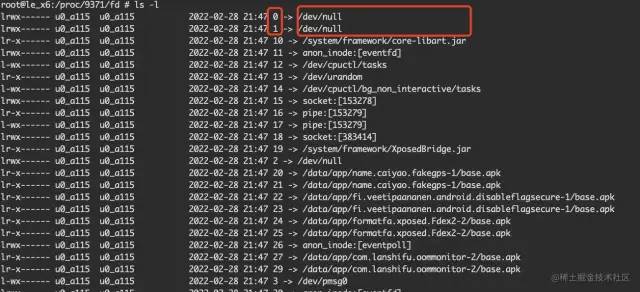
當fd的數(shù)目達到Max open files規(guī)定的數(shù)目,就會觸發(fā)Too many open files的奔潰,這種奔潰在低端機上比較容易復(fù)現(xiàn)。
知道了文件描述符這玩意后,看看怎么優(yōu)化~
4.2 文件描述符優(yōu)化
對于打開文件數(shù)太多的問題,盲目優(yōu)化其實無從下手,總體的方案是監(jiān)控為主。
通過如下代碼可以查看當前進程的fd信息
????private?fun?dumpFd()?{
????????val?fdNames?=?runCatching?{?File("/proc/self/fd").listFiles()?}
????????????.getOrElse?{
????????????????return@getOrElse?emptyArray()
????????????}
?????????????.map?{?file?->
????????????????runCatching?{?Os.readlink(file.path)?}.getOrElse?{?"failed?to?read?link?${file.path}"?}
????????????}
?????????????:?emptyList()
????????Log.d("TAG",?"dumpFd:?size=${fdNames.size},fdNames=$fdNames")
????}
復(fù)制代碼
4.3 文件描述符監(jiān)控
監(jiān)控策略:當fd數(shù)大于1000個,或者fd連續(xù)遞增超過50個,就觸發(fā)fd收集,將fd對應(yīng)的文件路徑上報到后臺。
這里模擬一個bug,打開一個文件多次不關(guān)閉,通過dumpFd,可以看到很多重復(fù)的文件名,進而大致定位到問題。
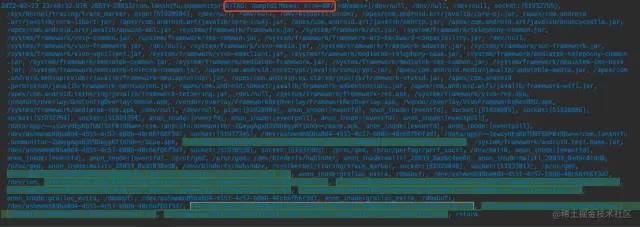
當懷疑某個文件有問題之后,我們還需要知道這個文件在哪創(chuàng)建,是誰創(chuàng)建的,這個就涉及到IO監(jiān)控~
4.4 IO監(jiān)控
4.4.1 監(jiān)控內(nèi)容
監(jiān)控完整的IO操作,包括open、read、write、close
open:獲取文件名、fd、文件大小、堆棧、線程
read/write:獲取文件類型、讀寫次數(shù)、總大小,使用buffer大小、讀寫總耗時
close:打開文件總耗時、最大連續(xù)讀寫時間
4.4.2 Java監(jiān)控方案:
以Android 6.0 源碼為例,FileInputStream 的調(diào)用鏈如下
java?:?FileInputStream?->?IoBridge.open?->?Libcore.os.open?->??
?BlockGuardOs.open?->?Posix.open
復(fù)制代碼
Libcore.java是一個不錯的hook點
package?libcore.io;
public?final?class?Libcore?{
????private?Libcore()?{?}
????public?static?Os?os?=?new?BlockGuardOs(new?Posix());
}
復(fù)制代碼
我們可以通過反射獲取到這個Os變量,它是一個接口類型,里面定義了open、read、write、close方法,具體實現(xiàn)在BlockGuardOs里面。
//?反射獲得靜態(tài)變量
Class?clibcore?=?Class.forName("libcore.io.Libcore");
Field?fos?=?clibcore.getDeclaredField("os");
復(fù)制代碼
通過動態(tài)代理的方式,在它所有IO方法前后加入插樁代碼來統(tǒng)計IO信息
//?動態(tài)代理對象
Proxy.newProxyInstance(cPosix.getClassLoader(),?getAllInterfaces(cPosix),?this);
beforeInvoke(method,?args,?throwable);
result?=?method.invoke(mPosixOs,?args);
afterInvoke(method,?args,?result);
復(fù)制代碼
此方案缺點如下:
性能差,IO調(diào)用頻繁,使用動態(tài)代理和Java的字符串操作,導致性能較差,無法達到線上使用標準 無法監(jiān)控Native代碼,這個也是比較重要的 兼容性差:需要根據(jù)Android 版本做適配,特別是Android P的非公開API限制
4.4.3 Native監(jiān)控方案
Native Hook方案的核心從 libc.so 中的這幾個函數(shù)中選定 Hook 的目標函數(shù)
int?open(const?char?*pathname,?int?flags,?mode_t?mode);
ssize_t?read(int?fd,?void?*buf,?size_t?size);
ssize_t?write(int?fd,?const?void?*buf,?size_t?size);?write_cuk
int?close(int?fd);
復(fù)制代碼
我們需要選擇一些有調(diào)用上面幾個方法的 library,例如選擇libjavacore.so、libopenjdkjvm.so、libopenjdkjvm.so,可以覆蓋到所有的 Java 層的 I/O 調(diào)用。
不同版本的 Android 系統(tǒng)實現(xiàn)有所不同,在 Android 7.0 之后,我們還需要替換下面這三個方法。
open64
__read_chk
__write_chk
復(fù)制代碼
native hook 框架目前使用比較廣泛的是愛奇藝的xhook ,以及它的改進版,字節(jié)跳動的bhook。
具體的native IO監(jiān)控代碼,可以參考 Matrix-IOCanary,內(nèi)部使用的是xhook框架。
關(guān)于IO涉及到的知識非常多,后面有時間可以單獨整理一篇文章。
接下來看看最后一種OOM類型~
五、內(nèi)存不足
5.1 堆棧信息

這種是最常見的OOM,Java堆內(nèi)存不足,512M都不夠玩~
發(fā)生此問題的大部分設(shè)備都是Android 7.0,高版本也有,不過相對較少。
5.2 重溫JVM內(nèi)存結(jié)構(gòu)
JVM在運行時,將內(nèi)存劃分為以下5個部分
方法區(qū):存放靜態(tài)變量、常量、即時編譯代碼; 程序計數(shù)器:線程私有,記錄當前執(zhí)行的代碼行數(shù),方便在cpu切換到其它線程再回來的時候能夠不迷路; Java虛擬機棧:線程私有,一個Java方法開始和結(jié)束,對應(yīng)一個棧幀的入棧和出棧,棧幀里面有局部變量表、操作數(shù)棧、返回地址、符號引用等信息; 本地方法棧:線程私有,跟Java虛擬機棧的區(qū)別在于 這個是針對native方法; 堆:絕大部分對象創(chuàng)建都在堆分配內(nèi)存
內(nèi)存不足導致的OOM,一般都是由于Java堆內(nèi)存不足,絕大部分對象都是在堆中分配內(nèi)存,除此之外,大數(shù)組、以及Android3.0-7.0的Bitmap像素數(shù)據(jù),都是存放在堆中。
Java堆內(nèi)存不足導致的OOM問題,線上難以復(fù)現(xiàn),往往比較難定位到問題,絕大部分設(shè)備都是8.0以下的,主要也是由于Android ?3.0-7.0 Bitmap像素內(nèi)存是存放在堆中導致的。(可以參考之前一篇文章分析過其源碼《面試官:簡歷上最好不要寫Glide,不是問源碼那么簡單》)
基于這個結(jié)論,關(guān)于Java堆內(nèi)存不足導致的OOM問題,優(yōu)化方案主要是圖片加載優(yōu)化、內(nèi)存泄漏監(jiān)控。
5.3 圖片加載優(yōu)化
5.3.1 常規(guī)的圖片優(yōu)化方式
常規(guī)的圖片加載優(yōu)化,依然可以參考兩年前的一篇文章《面試官:簡歷上最好不要寫Glide,不是問源碼那么簡單》, 文章核心內(nèi)容大概如下:
分析了主流圖片庫Glide和Fresco的優(yōu)缺點,以及使用場景; 分析了設(shè)計一個圖片加載框架需要考慮的問題; 防止圖片占用內(nèi)存過多導致OOM的三個方式:軟引用、onLowMemory、Bitmap 像素存儲位置
這篇文章現(xiàn)在來看還是有點意義的,其中的原理部分還沒過時,不過技術(shù)更新迭代,常規(guī)的優(yōu)化方式已經(jīng)不太夠了,長遠考慮,可以做圖片自動壓縮、大圖自動檢測和告警。
5.3.2 無侵入性自動壓縮圖片
針對圖片資源,設(shè)計師往往會追求高清效果,忽略圖片大小,一般的做法是拿到圖后手動壓縮一下,這種手動的操作完全看個人修養(yǎng)。
無侵入性自動壓縮圖片,主流的方案是利用Gradle 的Task原理,在編譯過程中,mergeResourcesTask 這個任務(wù)是將所以aar、module的資源進行合并,我們可以在mergeResourcesTask 之后可以拿到所有資源文件,具體做法:
在 mergeResourcesTask這個任務(wù)后面,增加一個圖片處理的Task,拿到所有資源文件;拿到所有資源文件后,判斷如果是圖片文件,則通過壓縮工具進行壓縮,壓縮后如果圖片有變小,就將壓縮過的圖片替換掉原圖。
可以簡單理解如下:
具體代碼可以參考 McImage 這個庫。
5.4 ?大圖監(jiān)控
5.3.2 自動壓縮圖片只是針對本地資源,而對于網(wǎng)絡(luò)圖片,如果加載的時候沒有壓縮,那么內(nèi)存占用會比較大,這種情況就需要監(jiān)控了。
5.4.1 ?從圖片框架側(cè)監(jiān)控
很多App內(nèi)部可能使用了多個圖片庫,例如Glide、Picasso、Fresco、ImageLoader、Coil,如果想監(jiān)控某個圖片框架, 那么我們需要熟讀源碼,找到hook點。
對于Glide,可以通過hook SingleRequest,它里面有個requestListeners,我們可以注冊一個自己的監(jiān)聽,圖片加載完做一個大圖檢測。
其它圖片框架,同理也是先找到hook點,然后進行類似的hook操作就可以,代碼可以參考:dokit-BigImgClassTransformer
5.4.2 從ImageView側(cè)監(jiān)控
5.4.1 是從圖片加載框架側(cè)監(jiān)控大圖,假如項目中使用到的圖片加載框架太多,有些第三方SDK內(nèi)部可能自己搞了圖片加載,
這種情況下我們可以從ImageView控件側(cè)做監(jiān)控,監(jiān)聽setImageDrawable等方法,計算圖片大小如果大于控件本身大小,debug包可以彈窗提示需要修改。
方案如下:
自定義ImageView,重寫 setImageDrawable、setImageBitmap、setImageResource、setBackground、setBackgroundResource這幾個方法,在這些方法里面,檢測Drawable大小;編譯期,修改字節(jié)碼,將所有 ImageView的創(chuàng)建都替換成自定義的ImageView;為了不影響主線程,可以使用 IdleHandler,在主線程空閑的時候再檢測;
最終是希望當檢測到大圖的時候,debug環(huán)境能夠彈窗提示開發(fā)進行修改,release環(huán)境可以上報后臺。
debug如下效果:
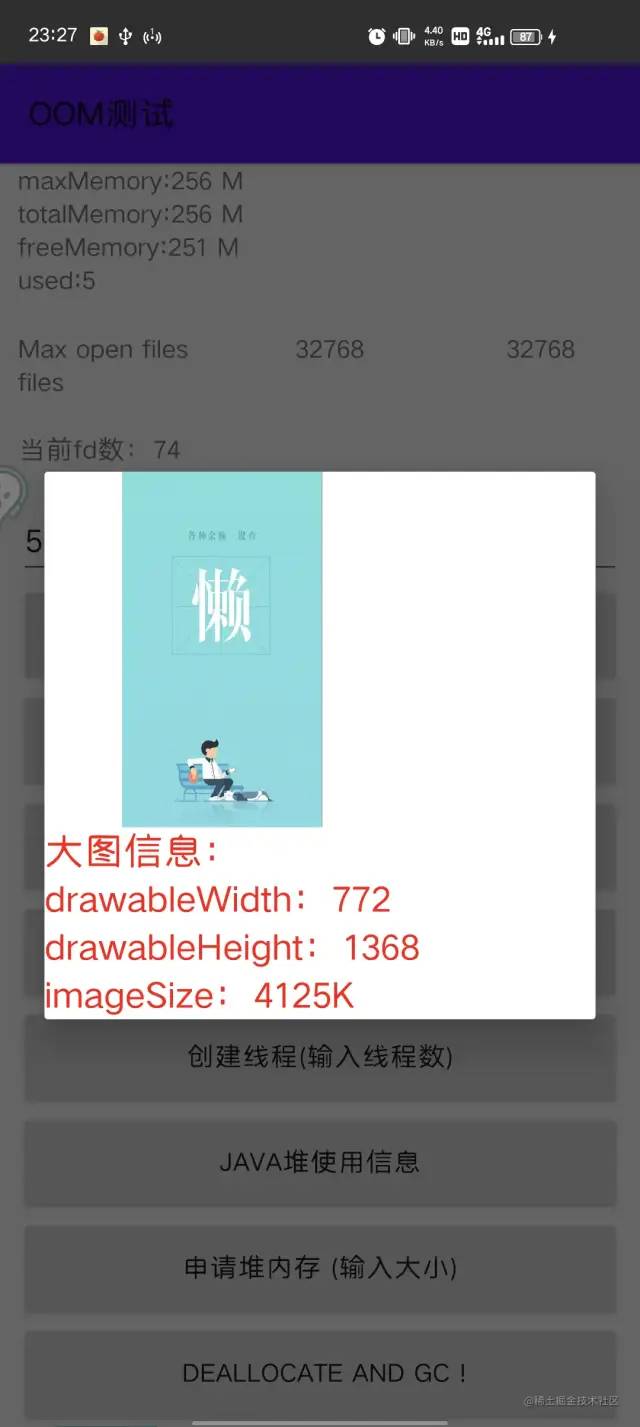
當然這種方案有個缺點:不能獲取到圖片url。
圖片優(yōu)化告一段落,接下來看看內(nèi)存泄漏~
5.5 內(nèi)存泄漏監(jiān)控演進
LeakCanary
關(guān)于內(nèi)存泄漏,大家可能都知道LeakCanary,只要添加一個依賴
debugImplementation 'com.squareup.leakcanary:leakcanary-android:2.8.1',
就能實現(xiàn)自動檢測和分析內(nèi)存泄漏,并發(fā)出一個通知顯示內(nèi)存泄漏詳情信息。
LeakCanary只能在debug環(huán)境使用,因為它是在當前進程dump內(nèi)存快照,Debug.dumpHprofData(path);會凍結(jié)當前進程一段時間,整個 APP 會卡死約5~15s,低端機上可能要幾十秒的時間。
ResourceCanary
微信對LeakCanary做了一些改造,將檢測和分析分離,客戶端只負責檢測和dump內(nèi)存鏡像文件,文件裁剪后上報到服務(wù)端進行分析。
具體可以看這篇文章Matrix ResourceCanary -- Activity 泄漏及Bitmap冗余檢測
KOOM
不管是LeakCanary 還是 ResourceCanary,他們都只能在線下使用,而線上內(nèi)存泄漏監(jiān)控方案,目前KOOM的方案比較完善,下面我將基于KOOM分析線上內(nèi)存泄漏監(jiān)控方案的核心流程。
5.6 線上內(nèi)存泄漏監(jiān)控方案
基于KOOM源碼分析
5.6.1 檢測時機
間隔5s檢測一次 觸發(fā)內(nèi)存鏡像采集的條件:
當內(nèi)存使用率達到80%以上
??????//->OOMMonitorConfig
??????
??????private?val?DEFAULT_HEAP_THRESHOLD?by?lazy?{
????????val?maxMem?=?SizeUnit.BYTE.toMB(Runtime.getRuntime().maxMemory())
????????when?{
??????????maxMem?>=?512?-?10?->?0.8f
??????????maxMem?>=?256?-?10?->?0.85f
??????????else?->?0.9f
????????}
??????}
復(fù)制代碼
兩次檢測時間內(nèi)(例如5s內(nèi)),內(nèi)存使用率增加5%
5.6.2 內(nèi)存鏡像采集
我們知道LeakCanary檢測內(nèi)存泄漏,不能用于線上,是因為它dump內(nèi)存鏡像是在當前進程進行操作,會凍結(jié)App一段時間。
所以,作為線上OOM監(jiān)控,dump內(nèi)存鏡像需要單獨開一個進程。
整體的策略是:
虛擬機supend->fork虛擬機進程->虛擬機resume->dump內(nèi)存鏡像的策略。
dump內(nèi)存鏡像的源碼如下:
??//->ForkJvmHeapDumper
??
??public?boolean?dump(String?path)?{
????...
????boolean?dumpRes?=?false;
????try?{
??????//1、通過fork函數(shù)創(chuàng)建子進程,會返回兩次,通過pid判斷是父進程還是子進程
??????int?pid?=?suspendAndFork();
??????
??????MonitorLog.i(TAG,?"suspendAndFork,pid="+pid);
??????if?(pid?==?0)?{
????????//2、子進程返回,dump內(nèi)存操作,dump內(nèi)存完成,退出子進程
????????Debug.dumpHprofData(path);
????????exitProcess();
??????}?else?if?(pid?>?0)?{
????????//?3、父進程返回,恢復(fù)虛擬機,將子進程的pid傳過去,阻塞等待子進程結(jié)束
????????dumpRes?=?resumeAndWait(pid);
????????MonitorLog.i(TAG,?"notify?from?pid?"?+?pid);
??????}
????}
????return?dumpRes;
??}
復(fù)制代碼
注釋1:父進程調(diào)用native方法掛起虛擬機,并且創(chuàng)建子進程;注釋2:子進程創(chuàng)建成功,執(zhí)行Debug.dumpHprofData,執(zhí)行完后退出子進程;注釋3:得知子進程創(chuàng)建成功后,父進程恢復(fù)虛擬機,解除凍結(jié),并且當前線程等待子進程結(jié)束。
注釋1源碼如下:
//?->native_bridge.cpp
pid_t?HprofDump::SuspendAndFork()?{
??//1、暫停VM,不同Android版本兼容
??if?(android_api_?????suspend_vm_fnc_();
??}
??...
??//2,fork子進程,通過返回值可以判斷是主進程還是子進程
??pid_t?pid?=?fork();
??if?(pid?==?0)?{
????//?Set?timeout?for?child?process
????alarm(60);
????prctl(PR_SET_NAME,?"forked-dump-process");
??}
??return?pid;
}
復(fù)制代碼
注釋3源碼如下:
//->hprof_dump.cpp
bool?HprofDump::ResumeAndWait(pid_t?pid)?{
??//1、恢復(fù)虛擬機,兼容不同Android版本
??if?(android_api_?????resume_vm_fnc_();
??}
??...
??int?status;
??for?(;;)?{
????//2、waitpid,等待子進程結(jié)束
????if?(waitpid(pid,?&status,?0)?!=?-1?||?errno?!=?EINTR)?{
??????//進程異常退出
??????if?(!WIFEXITED(status))?{
????????ALOGE("Child?process?%d?exited?with?status?%d,?terminated?by?signal?%d",
??????????????pid,?WEXITSTATUS(status),?WTERMSIG(status));
????????return?false;
??????}
??????return?true;
????}
????return?false;
??}
}
復(fù)制代碼
這里主要是利用Linux的waitpid函數(shù),主進程可以等待子進程dump結(jié)束,然后再返回執(zhí)行內(nèi)存鏡像文件分析操作。
5.6.3 內(nèi)存鏡像分析
前面一步已經(jīng)通過Debug.dumpHprofData(path)拿到內(nèi)存鏡像文件,接下來就開啟一個后臺服務(wù)來處理
?//->HeapAnalysisService
?
??override?fun?onHandleIntent(intent:?Intent?)?{
????...
????kotlin.runCatching?{
??????//1、通過shark將hprof文件轉(zhuǎn)換成HeapGraph對象
??????buildIndex(hprofFile)
????}
????...
????//2、將設(shè)備信息封裝成json
????buildJson(intent)
????kotlin.runCatching?{
??????//3、過濾泄漏對象,有幾個規(guī)制
??????filterLeakingObjects()
????}
????...
????kotlin.runCatching?{
??????//?4、gcRoot是否可達,判斷內(nèi)存泄漏
??????findPathsToGcRoot()
????}
????...
????//5、泄漏信息填充到j(luò)son中,然后結(jié)束了
????fillJsonFile(jsonFile)
????//通知主進程內(nèi)存泄漏分析成功
????resultReceiver?.send(AnalysisReceiver.RESULT_CODE_OK,?null)
????//這個服務(wù)是在單獨進程,分析完就退出
????System.exit(0);
??}
復(fù)制代碼
內(nèi)存鏡像分析的流程如下:
通過 shark這個開源庫將hprof文件轉(zhuǎn)換成HeapGraph對象收集設(shè)備信息,封裝成json,現(xiàn)場信息很重要 filterLeakingObjects:過濾出泄漏的對象,有一些規(guī)制,例如已經(jīng)destroyed和finished的activity、fragment manager為空的fragment、已經(jīng)destroyed的window等。findPathsToGcRoot:內(nèi)存泄漏的對象,查找其到GcRoot的路徑,通過這一步就可以揪出內(nèi)存泄漏的原因fillJsonFile:格式化輸出內(nèi)存泄漏信息
小結(jié)
線上Java內(nèi)存泄漏監(jiān)控方案分析,這里小結(jié)一下:
掛起當前進程,然后通過 fork創(chuàng)建子進程;fork會返回兩次,一次是子進程,一次是父進程,通過返回的pid可以判斷是子進程還是父進程;如果是父進程返回,則通過 resumeAndWait恢復(fù)進程,然后當前線程阻塞等待子進程結(jié)束;如果子進程返回,通過 Debug.dumpHprofData(path)讀取內(nèi)存鏡像信息,這個會比較耗時,執(zhí)行結(jié)束就退出子進程;子進程退出,父進程的 resumeAndWait就會返回,這時候就可以開啟一個服務(wù),后臺分析內(nèi)存泄漏情況,這塊跟LeakCanary的分析內(nèi)存泄漏原理基本差不多。
不畫圖了,結(jié)合源碼看應(yīng)該可以理解。
5.7 native內(nèi)存泄漏監(jiān)控
對于Java內(nèi)存泄漏監(jiān)控,線下我們可以使用LeakCanary、線上可以使用KOOM,而對于native內(nèi)存泄漏應(yīng)該如何監(jiān)控呢?
方案如下:
首先要了解native層
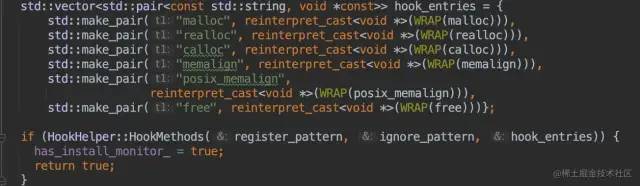
申請內(nèi)存的函數(shù):malloc、realloc、calloc、memalign、posix_memalign釋放內(nèi)存的函數(shù):free
hook申請內(nèi)存和釋放內(nèi)存的函數(shù)
分配內(nèi)存的時候,收集堆棧、內(nèi)存大小、地址、線程等信息,存放到map中,在釋放內(nèi)存的時候從map中移除。
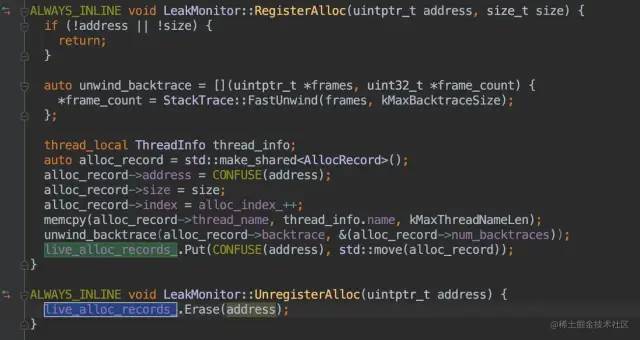
那怎么判斷native內(nèi)存泄漏呢?
周期性的使用 mark-and-sweep分析整個進程 Native Heap,獲取不可達的內(nèi)存塊信息「地址、大小」獲取到不可達的內(nèi)存塊的地址后,可以從我們的Map中獲取其堆棧、內(nèi)存大小、地址、線程等信息。
具體實現(xiàn)可以參考:koom-native-leak
總結(jié)
本文從線上OOM問題入手,介紹了OOM原理, 以及OOM優(yōu)化方案和監(jiān)控方案,基本上都是大廠開源出來的比較成熟的方案:
對于 pthread_createOOM問題,介紹了無侵入性的new Thread優(yōu)化、無侵入性的線程池優(yōu)化、以及線程泄漏監(jiān)控;對于文件描述符過多問題,介紹了原理以及文件描述符監(jiān)控方案、IO監(jiān)控方案; 對于Java內(nèi)存不足導致的OOM、介紹了無侵入性圖片自動壓縮方案、兩種無侵入性的大圖監(jiān)控方案、Java內(nèi)存泄漏監(jiān)控的線下方案和線上方案、以及native內(nèi)存泄漏監(jiān)控方案。
大廠對外開源的技術(shù)非常多,但不一定最優(yōu),我們在學習過程中可以多加思考, 例如線程優(yōu)化,booster 對于new Thread的優(yōu)化只是設(shè)置了線程名,有助于分析問題,而經(jīng)過我的猜想和驗證,通過字節(jié)碼插樁,將new Thread無侵入性替換成線程池調(diào)用,才是真正意義上的線程優(yōu)化。

推薦


