
Flink 版本 | Apache Flink 1.14.0 發(fā)布
Apache 軟件基金會最近發(fā)布了年度報告,Apache Flink 再次躋身最活躍項目前 5 名!這一非凡的活動也體現(xiàn)在新的 1.14.0 版本中。200 多名貢獻者再次致力于解決 1,000 多個問題。我們?yōu)檫@個社區(qū)如何持續(xù)推進項目而感到自豪。
此版本在 SQL API、更多連接器支持、檢查點和 PyFlink 等領(lǐng)域帶來了許多新功能和改進。此版本中的一個主要變化領(lǐng)域是集成的流和批處理體驗。我們相信,在實踐中,無界流處理在實踐中與有界和批處理任務(wù)密切相關(guān),因為許多用例需要處理來自各種來源的歷史數(shù)據(jù)以及流數(shù)據(jù)。示例包括開發(fā)新應(yīng)用程序時的數(shù)據(jù)探索、新應(yīng)用程序的引導(dǎo)狀態(tài)、要在流應(yīng)用程序中應(yīng)用的訓(xùn)練模型、修復(fù)/升級后重新處理數(shù)據(jù)等.
在 Flink 1.14 中,我們終于可以在應(yīng)用程序中混合有界和無界流:Flink 現(xiàn)在支持獲取部分運行和部分完成的應(yīng)用程序的檢查點(一些運算符到達有界輸入的末尾)。此外,有界流現(xiàn)在在到達終點時采用最終檢查點,以確保在接收器中順利提交結(jié)果。
所述批處理執(zhí)行模式現(xiàn)在支持使用DataStream API和SQL /Table API的混合程序(以前僅純表/ SQL或的數(shù)據(jù)流中的程序)。
統(tǒng)一的 Source 和 Sink API 已經(jīng)更新,我們開始圍繞統(tǒng)一 API 整合連接器生態(tài)系統(tǒng)。我們添加了一個新的混合源,可以在多個存儲系統(tǒng)之間架起橋梁。您現(xiàn)在可以執(zhí)行一些操作,例如從 Amazon S3 讀取舊數(shù)據(jù),然后切換到 Apache Kafka。
此外,此版本進一步推動了我們的舉措,使 Flink 更具自調(diào)性和更易于操作,而無需大量特定于流處理器的知識。我們在之前的版本中通過反應(yīng)式擴展啟動了這項計劃, 現(xiàn)在正在添加自動網(wǎng)絡(luò)內(nèi)存調(diào)整(又名緩沖區(qū)去膨脹)。此功能可在高負載下加速檢查點,同時保持高吞吐量且不增加檢查點大小。該機制不斷調(diào)整網(wǎng)絡(luò)緩沖區(qū),以確保最佳吞吐量,同時擁有最少的傳輸中數(shù)據(jù)。有關(guān) 更多詳細信息,請參閱緩沖區(qū)去膨脹部分。
正如我們在下面討論的那樣,在各個組件中還有更多改進和新增功能。我們還不得不告別一些在最近的版本中被更新的功能所取代的功能,最突出的是我們正在刪除舊的 SQL 執(zhí)行引擎,并正在刪除與 Apache Mesos 的主動集成。
我們希望您喜歡這個新版本,我們渴望了解您使用它的體驗,它解決了哪些尚未解決的問題,它為您解鎖了哪些新用例。
統(tǒng)一的批處理和流處理體驗
Flink 的獨特之處之一是它如何集成流處理和批處理,使用統(tǒng)一的 API 和支持多種執(zhí)行范式的運行時。
正如介紹中的動機,我們相信流處理和批處理總是齊頭并進。來自Facebook 流基礎(chǔ)設(shè)施報告的這句話 很好地回應(yīng)了這種情緒。
流式處理與批處理不是一個非此即彼的決定。最初,F(xiàn)acebook 的所有數(shù)據(jù)倉庫處理都是批處理。大約五年前,我們開始開發(fā) Puma 和 Swift。正如我們在第 […] 節(jié)中所展示的,混合使用流處理和批處理可以將長管道加速數(shù)小時。
在同一引擎中同時進行實時計算和歷史計算還可以確保語義之間的一致性并使結(jié)果具有很好的可比性。這是阿里巴巴的一篇 關(guān)于使用 Apache Flink 統(tǒng)一業(yè)務(wù)報告并以這種方式獲得一致報告的文章。
雖然在早期版本中已經(jīng)可以實現(xiàn)統(tǒng)一流和批處理,但此版本帶來了一些解鎖新用例的功能,以及一系列的生活質(zhì)量改進。
檢查點和有界流
Flink 的檢查點機制最初只能在應(yīng)用程序 DAG 中的所有任務(wù)都在運行時創(chuàng)建檢查點。這意味著同時使用有界和無界數(shù)據(jù)源的應(yīng)用程序?qū)嶋H上是不可能的。此外,當(dāng)某些任務(wù)完成時,以流方式(而不是以批處理方式)執(zhí)行的有界輸入上的應(yīng)用程序在處理結(jié)束時停止檢查點。如果沒有檢查點,則不會提交最新的輸出數(shù)據(jù),從而導(dǎo)致恰好一次接收器的數(shù)據(jù)揮之不去。
使用FLIP-147, Flink 現(xiàn)在支持任務(wù)完成后的檢查點,并在有界流的末尾獲取最終檢查點,確保在作業(yè)結(jié)束之前提交所有接收器數(shù)據(jù)(類似于stop-with-savepoint 的行為)。
要激活此功能,請?zhí)砑觘xecution.checkpointing.checkpoints-after-tasks-finish.enabled: true到您的配置中。與大功能和新功能的選擇加入傳統(tǒng)保持一致,這在 Flink 1.14 中默認不激活。我們希望它成為下一個版本的默認模式。
背景:雖然批處理執(zhí)行模式通常是在有界流上運行應(yīng)用程序的首選方式,但在有界流上使用流式執(zhí)行模式有多種原因。例如,正在使用的接收器可能僅支持流執(zhí)行(即 Kafka 接收器),或者您可能希望在應(yīng)用程序中利用流固有的準(zhǔn)按時間排序,例如受Kappa+ 架構(gòu)的啟發(fā)。
混合DataStream和Table/SQL 應(yīng)用程序的批處理執(zhí)行
SQL 和 Table API 正在成為新項目的默認起點。內(nèi)置類型和操作的聲明性和豐富性使得快速開發(fā)應(yīng)用程序變得容易。然而,對于某些類型的事件驅(qū)動的業(yè)務(wù)邏輯,開發(fā)人員最終會達到 SQL 表達能力的極限(或者當(dāng)用 SQL 表達該邏輯變得怪誕時,這種情況并不少見)。
那時,自然的步驟是在再次切換回 SQL 之前融入一段有狀態(tài)的 DataStream API 邏輯。
在 Flink 1.14 中,有界批處理執(zhí)行的 SQL/Table 程序可以將它們的中間 Table 轉(zhuǎn)換為 DataStream,應(yīng)用一些 DataSteam API 操作,并將其轉(zhuǎn)換回 Table。在幕后,F(xiàn)link 構(gòu)建了一個數(shù)據(jù)流 DAG,將聲明式優(yōu)化的 SQL 執(zhí)行與批處理執(zhí)行的 DataStream 邏輯混合在一起。查看文檔了解詳細信息。
混合Source
新的混合源 產(chǎn)生來自多個源的組合流,通過一個接一個地讀取這些源,從一個源無縫切換到另一個源。
混合源的激勵用例是從分層存儲設(shè)置中讀取流,就好像有一個跨所有層的流。例如,新數(shù)據(jù)可能會登陸 Kafa 并最終遷移到 S3(通常采用壓縮柱狀格式,以提高成本效率和性能)。混合源可以將其作為一個連續(xù)的邏輯流讀取,從 S3 上的歷史數(shù)據(jù)開始,過渡到 Kafka 中更新的數(shù)據(jù)。
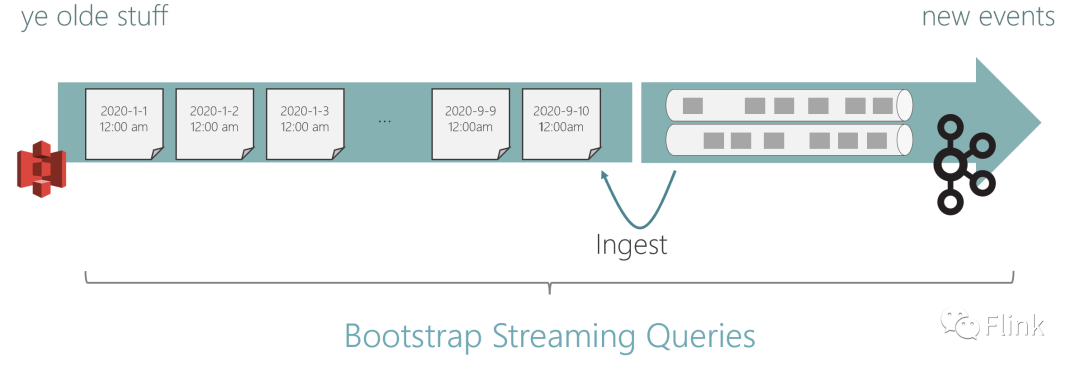
我們相信這是實現(xiàn)日志和Kappa 架構(gòu)的全部承諾的令人興奮的一步。即使事件日志的舊部分被物理遷移到不同的存儲(出于成本、更好的壓縮、更快的讀取等原因),您仍然可以將其視為一個連續(xù)的日志并將其處理。
Flink 1.14 增加了 Hybrid Source 的核心功能。在下一個版本中,我們希望為典型的切換策略添加更多實用程序和模式。
整合Source和Sink
隨著新的統(tǒng)一(流/批處理)源和接收器 API 現(xiàn)在穩(wěn)定,我們開始大力整合這些 API 周圍的所有連接器。同時,我們更好地對齊 DataStream 和 SQL/Table API 之間的連接器。首先是用于 DataStream API的Kafka和文件源和接收器。
這項努力的結(jié)果(我們預(yù)計至少會發(fā)布 1-2 個后續(xù)版本)將為 Flink 用戶在連接到外部系統(tǒng)時提供更流暢、更一致的體驗。
緩沖消脹
Buffer Debloating是 Flink 中的一項新技術(shù),可以最大限度地減少檢查點延遲和成本。它通過自動調(diào)整網(wǎng)絡(luò)內(nèi)存的使用來確保高吞吐量,同時最大限度地減少傳輸中的數(shù)據(jù)量。
Apache Flink 在其網(wǎng)絡(luò)堆棧中緩沖一定數(shù)量的數(shù)據(jù),以便能夠利用快速網(wǎng)絡(luò)的帶寬。以高吞吐量運行的 Flink 應(yīng)用程序使用部分(或全部)內(nèi)存。對齊的檢查點與數(shù)據(jù)一起以毫秒為單位通過網(wǎng)絡(luò)緩沖區(qū)。
當(dāng) Flink 應(yīng)用程序變得(暫時)背壓時(例如,當(dāng)受到外部系統(tǒng)的背壓時,或者當(dāng)命中偏斜的記錄時),這通常會導(dǎo)致網(wǎng)絡(luò)緩沖區(qū)中的數(shù)據(jù)比使用應(yīng)用程序當(dāng)前所需的足夠網(wǎng)絡(luò)帶寬所必需的多得多。吞吐量(由于背壓而降低)。甚至還有一個不利的影響:更多的緩沖數(shù)據(jù)意味著檢查點需要做更多的工作。對齊的檢查點屏障需要等待更多的數(shù)據(jù)被處理,未對齊的檢查點需要持久化更多的動態(tài)數(shù)據(jù)。
這就是Buffer Debloating發(fā)揮作用的地方:它將網(wǎng)絡(luò)堆棧從保持最多 X 字節(jié)的數(shù)據(jù)更改為保持值得 X 毫秒的接收器計算時間的數(shù)據(jù)。默認設(shè)置為 1000 毫秒,這意味著網(wǎng)絡(luò)堆棧將緩沖接收任務(wù)在 1000 毫秒內(nèi)可以處理的數(shù)據(jù)。這些值會不斷測量和調(diào)整,因此系統(tǒng)即使在變化的條件下也能保持這種特性。因此,F(xiàn)link 現(xiàn)在可以為背壓下的對齊檢查點提供穩(wěn)定且可預(yù)測的對齊時間,并且可以大大減少背壓下未對齊檢查點中存儲的動態(tài)數(shù)據(jù)量。
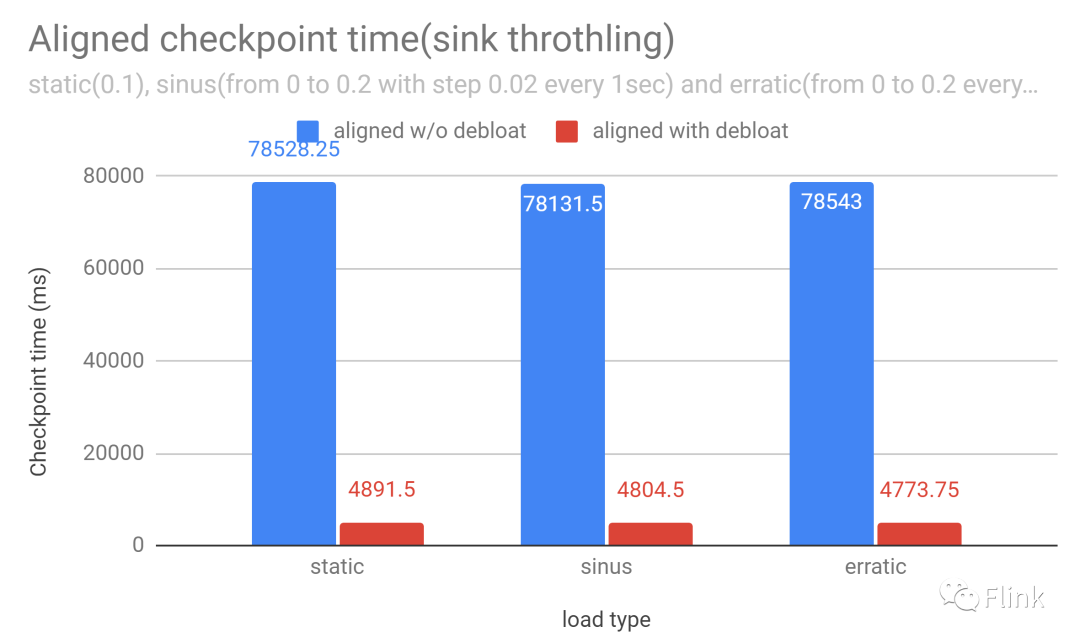
Buffer Deloating 是未對齊檢查點的補充功能,甚至是替代功能。查看文檔 以了解如何激活此功能。
細粒度資源管理
細粒度資源管理是一項高級新功能,可提高大型共享集群的資源利用率。
Flink 集群執(zhí)行各種數(shù)據(jù)處理工作負載。不同的數(shù)據(jù)處理步驟通常需要不同的資源,例如計算資源和內(nèi)存。例如,大多數(shù)map()函數(shù)都相當(dāng)輕量級,但是保留時間長的大窗口可以從大量內(nèi)存中受益。默認情況下,F(xiàn)link 以稱為slot的粗粒度單元管理資源,這些單元是 TaskManager 資源的切片。流式管道用每個操作符的一個并行子任務(wù)填充一個槽,因此每個槽都持有一個子任務(wù)管道。通過“插槽共享組”,用戶可以影響子任務(wù)如何分配給插槽。
通過細粒度的資源管理,TaskManager 插槽現(xiàn)在可以動態(tài)調(diào)整大小。轉(zhuǎn)換和操作符指定他們想要的資源配置文件(CPU 大小、內(nèi)存池、磁盤空間),并且 Flink 的資源管理器和任務(wù)管理器將任務(wù)管理器總資源的特定部分切掉。您可以將其視為 Flink 中最小的輕量級資源編排層。下圖說明了共享固定大小插槽的當(dāng)前默認模式與新的細粒度資源管理功能之間的區(qū)別。
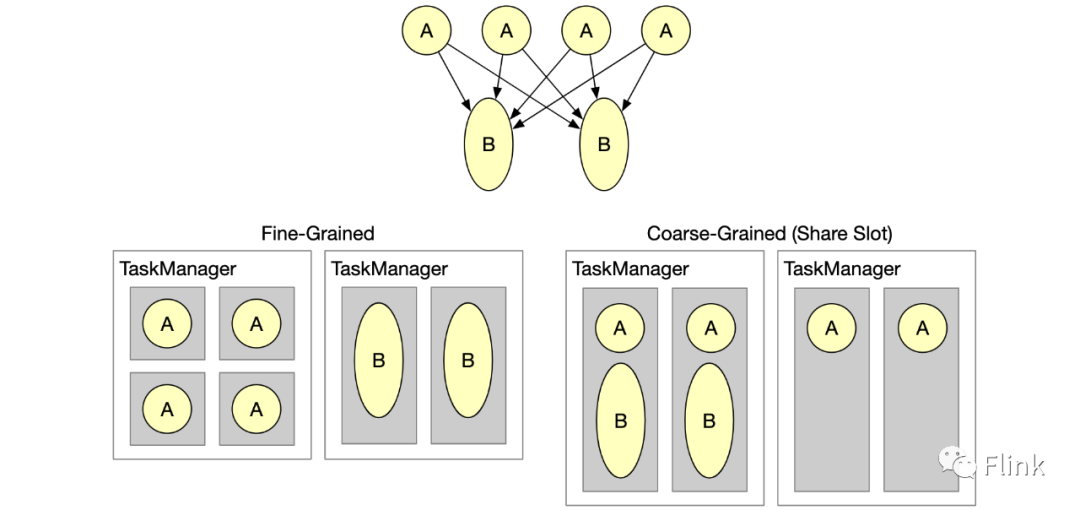
您可能想知道為什么我們在 Flink 中實現(xiàn)這樣的功能,同時我們還與 Kubernetes 或 YARN 等成熟的資源編排框架集成。Flink 內(nèi)部額外的資源管理層顯著提高資源利用率的情況有以下幾種:
對于很多小槽來說,專用TaskManagers的開銷非常高(JVM開銷,F(xiàn)link控制數(shù)據(jù)結(jié)構(gòu))。時隙共享通過在所有運算符類型之間共享時隙來隱式地解決這個問題,這意味著在輕量級運算符(需要小時隙)和重量級運算符(需要大時隙)之間共享資源。然而,這僅在所有操作符共享相同的并行性時才有效,這并非最佳。此外,某些算子在單獨運行時效果更好(例如需要專用 GPU 資源的 ML 訓(xùn)練算子)。
Kubernetes 和 YARN 通常需要相當(dāng)長的時間來滿足請求,尤其是在負載集群上。對于許多批處理作業(yè),在等待請求完成時效率會下降。
那么什么時候應(yīng)該使用這個功能呢?對于大多數(shù)流和批處理作業(yè),默認資源管理機制非常適合。如果您有長時間運行的流作業(yè)或快速批處理作業(yè),其中不同階段具有不同的資源需求,并且您可能已經(jīng)將不同算子的并行度調(diào)整為不同的值,那么細粒度的資源管理可以幫助您提高資源效率。阿里巴巴內(nèi)部基于Flink的平臺已經(jīng)使用這種機制有一段時間了,集群的資源利用率顯著提高。有關(guān)如何使用此功能的詳細信息,請參閱細粒度資源管理文檔。
連接器
連接器指標(biāo)
此版本中已對連接器的度量標(biāo)準(zhǔn)進行了標(biāo)準(zhǔn)化(請參閱FLIP-33)。社區(qū)將逐漸通過所有連接器提取指標(biāo),因為我們會在下一個版本中將它們重新設(shè)計到新的統(tǒng)一 API 上。在 Flink 1.14 中,我們介紹了 Kafka 連接器和(部分)文件系統(tǒng)連接器。
連接器是 Flink 作業(yè)中數(shù)據(jù)的入口和出口點。如果作業(yè)未按預(yù)期運行,則連接器遙測是首先要檢查的部分之一。我們相信在生產(chǎn)中運行 Flink 應(yīng)用程序時,這將成為一個很好的改進。
Pulsar連接器
在這個版本中,F(xiàn)link 添加了Apache Pulsar連接器。Pulsar 連接器從 Pulsar 主題讀取數(shù)據(jù),并支持流和批處理兩種執(zhí)行模式。在事務(wù)功能的支持下(在 Pulsar 2.8.0 中引入),Pulsar 連接器提供了一次性傳遞語義,以確保消息只傳遞給消費者一次,即使生產(chǎn)者重試發(fā)送消息。
為了支持不同用例的不同消息排序和擴展需求,Pulsar 源連接器公開了四種訂閱類型:-獨占 -共享 -故障轉(zhuǎn)移 -密鑰共享
連接器當(dāng)前支持 DataStream API。表 API/SQL 綁定預(yù)計將在未來版本中提供。有關(guān)如何使用 Pulsar 連接器的詳細信息,請參閱 Apache Pulsar 連接器。
PyFlink
通過Chaining提高性能
類似于 Java API 如何在任務(wù)中鏈接轉(zhuǎn)換函數(shù)/操作符以避免序列化開銷,PyFlink 現(xiàn)在鏈接 Python 函數(shù)。在 PyFlink 的情況下,鏈接不僅消除了序列化開銷,還減少了 Java 和 Python 進程之間的 RPC 往返。這極大地提高了 PyFlink 的整體性能。
Python 函數(shù)鏈已經(jīng)可用于 Table API 和 SQL 中使用的 Python UDF。在 Flink 1.14 中,Python DataStream API 中的 cPython 函數(shù)也使用了鏈接。
用于調(diào)試的環(huán)回模式
Python 函數(shù)通常在 Flink 的 JVM 旁邊的一個單獨的 Python 進程中執(zhí)行。這種架構(gòu)使得調(diào)試 Python 代碼變得困難。
PyFlink 1.14 引入了環(huán)回模式,默認情況下為本地部署激活。在這種模式下,用戶自定義的Python函數(shù)將在客戶端的Python進程中執(zhí)行,該進程是啟動PyFlink程序的入口點進程,包含構(gòu)建數(shù)據(jù)流DAG的DataStream API和Table API代碼。用戶現(xiàn)在可以通過在本地啟動 PyFlink 作業(yè)時在其 IDE 中設(shè)置斷點來輕松調(diào)試其 Python 函數(shù)。
其他改進
PyFlink 還有許多其他改進,例如支持在 YARN 應(yīng)用程序模式下執(zhí)行作業(yè)以及支持將壓縮的 tgz 文件作為 Python 存檔。查看Python API 文檔 以獲取更多詳細信息。
告別舊版 SQL 引擎和 Mesos 支持
維護一個開源項目有時也意味著要告別一些心愛的功能。
當(dāng)我們在兩年多前將 Blink SQL Engine 添加到 Flink 時,很明顯它最終會取代之前的 SQL 引擎。Blink 速度更快,功能更完整。一年來,Blink 一直是默認的 SQL 引擎。在 Flink 1.14 中,我們最終從之前的 SQL 引擎中刪除了所有代碼。這使我們能夠刪除許多過時的接口,并減少用戶在實現(xiàn)自定義連接器或功能時使用哪些接口的困惑。它也將幫助我們在未來對 SQL 引擎進行更快的更改。
與 Apache Mesos 的主動集成也被刪除了,因為我們發(fā)現(xiàn)用戶對此功能興趣不大,而且我們無法聚集足夠的貢獻者來幫助維護系統(tǒng)的這一部分。如果沒有 Marathon 等項目的幫助,F(xiàn)link 1.14 無法再在 Mesos 上運行,并且 Flink 資源管理器無法再從 Mesos 請求和釋放資源,以應(yīng)對不斷變化的資源需求的工作負載。