
SQL查詢是從Select開始的嗎?

好吧,顯然很多SQL查詢都是從SELECT開始的(實(shí)際上本文只是關(guān)注SELECT查詢,而不是INSERT或其它別的什么)。
但是!昨天我正在做窗口函數(shù)的解釋說明,并且我發(fā)現(xiàn)自己在谷歌上搜索“你能根據(jù)窗口函數(shù)的結(jié)果進(jìn)行過濾嗎”。比如 — 你能在WHERE、HAVING或者其它地方過濾窗口函數(shù)的結(jié)果嗎?
最后我得出的結(jié)論是:“窗口函數(shù)必須在WHERE和GROUP BY之后運(yùn)行,所以你做不到”。但這讓我想到了一個(gè)更大的問題 — SQL查詢的實(shí)際運(yùn)行順序是什么?
這是我憑直覺就知道的事情(“我肯定知道!我已經(jīng)編寫了至少10000個(gè)SQL查詢,其中一些非常復(fù)雜!),但我很難真正地準(zhǔn)確說出順序是什么。
SQL查詢按此順序進(jìn)行
這就是我查找到的順序!(SELECT并不是在第一步執(zhí)行,而是到第五步才執(zhí)行)
(這里是一篇推特: https://twitter.com/b0rk/status/1179449535938076673)
(我真的很想找到一種比“sql查詢按此順序發(fā)生/運(yùn)行”更準(zhǔn)確的表達(dá)方式,但我還沒想出來。)
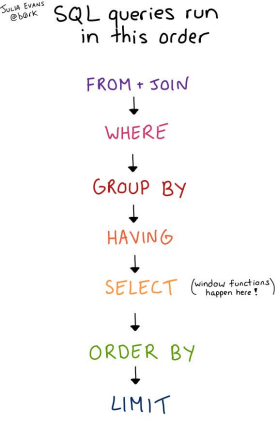
在非圖形格式中,其順序?yàn)椋?/span>
l FROM/JOIN 和所有的 ON 條件l WHEREl GROUP BYl HAVINGl SELECT(包括窗口函數(shù))l ORDER BYl LIMIT
圖解此圖有助于你做出回答
此圖是關(guān)于SQL查詢的語義的 — 你可以通過它,對給定查詢將返回什么結(jié)果進(jìn)行推理,并回答如下問題:
我能在一個(gè)GROUP BY的結(jié)果上執(zhí)行WHERE么?(不行!WHERE發(fā)生在GROUP BY之前!)
我可以根據(jù)窗口函數(shù)的結(jié)果進(jìn)行過濾嗎(不行!窗口函數(shù)發(fā)生在SELECT中,它發(fā)生在WHERE和GROUP BY之后)
我可以基于GROUP BY中所做的來進(jìn)行ORDER BY么?(可以!ORDER BY是最后執(zhí)行的基本步驟,你可以根據(jù)任何東西做ORDER BY!)
LIMIT何時(shí)執(zhí)行?(在最后!)
數(shù)據(jù)庫引擎實(shí)際并不是按這個(gè)順序運(yùn)行查詢
因?yàn)樗鼘?shí)現(xiàn)了一系列優(yōu)化以使查詢運(yùn)行得更快 — 我們稍后將在本文中討論這一點(diǎn)。
所以:
當(dāng)你只想了解哪些查詢是有效的,以及如何推理給定查詢的結(jié)果時(shí),可以使用此圖。
你不應(yīng)該使用此圖來解釋查詢性能或任何有關(guān)索引的事情,那是一個(gè)復(fù)雜得多的問題,涉及更多變量。
混淆因素:列別名
有人在Twitter上指出,許多SQL實(shí)現(xiàn)允許你使用以下語法:
SELECT CONCAT(first_name, ' ', last_name) AS full_name, count(*)FROM tableGROUP BY full_name
此查詢使其看起來像是在SELECT之后才發(fā)生GROUP BY,即使GROUP BY先執(zhí)行,因?yàn)镚ROUP BY引用了SELECT中的別名。但是要使GROUP BY發(fā)揮作用,其實(shí)并不需要在SELECT之后才運(yùn)行 — 數(shù)據(jù)庫引擎只要將查詢重寫為:
SELECT CONCAT(first_name, ' ', last_name) AS full_name, count(*)FROM tableGROUP BY CONCAT(first_name, ' ', last_name)
并且首先運(yùn)行GROUP BY。
你的數(shù)據(jù)庫引擎肯定還會在開始運(yùn)行查詢之前執(zhí)行一系列檢查,確保你在SELECT和GROUP BY中放置的內(nèi)容合在一起是有意義的,因此在開始制定執(zhí)行計(jì)劃之前,它必須將查詢作為一個(gè)整體來查看。
查詢實(shí)際上不是按此順序運(yùn)行的(優(yōu)化!)
實(shí)際上,數(shù)據(jù)庫引擎并不是真的通過連接、然后過濾、然后再分組來運(yùn)行查詢,因?yàn)樗鼈儗?shí)現(xiàn)了一系列優(yōu)化,只要重新排列執(zhí)行順序不改變查詢結(jié)果,就可以重排以使查詢運(yùn)行得更快。
一個(gè)簡單的例子說明了為什么需要以不同的順序運(yùn)行查詢以使其快速運(yùn)行,在這個(gè)查詢中:
SELECT * FROMowners LEFT JOIN cats ON owners.id = cats.ownerWHERE cats.name = 'mr darcy'
如果你只需要查找3個(gè)名為“mr darcy”的貓,那么執(zhí)行整個(gè)左連接并匹配這兩個(gè)表中的所有行是非常愚蠢的 —— 首先對名為“mr darcy”的貓進(jìn)行一些篩選要快得多。在這種情況下,先進(jìn)行過濾不會改變查詢結(jié)果!
實(shí)際上,數(shù)據(jù)庫引擎還實(shí)現(xiàn)了許多其它優(yōu)化,這些優(yōu)化可能會使它們以不同的順序運(yùn)行查詢,但不能再說了,老實(shí)講,這方面我不是專家。
LINQ以FROM開始查詢
LINQ(一種C#和VB.NET中的查詢語法)使用的順序?yàn)镕ROM ... WHERE ... SELECT。下面是一個(gè)LINQ查詢的示例:
var teenAgerStudent = from s in studentListwhere s.Age > 12 && s.Age < 20select s;
pandas(我所喜歡的數(shù)據(jù)治理工具:https://github.com/jvns/pandas-cookbook)也基本上是這樣工作的,盡管你不需要使用這種精確的順序 — 我經(jīng)常會這樣編寫pandas代碼:
df = thing1.join(thing2) # like a JOINdf = df[df.created_at > 1000] # like a WHEREdf = df.groupby('something', num_yes = ('yes', 'sum')) # like a GROUP BYdf = df[df.num_yes > 2] # like a HAVING, filtering on the result of a GROUP BYdf = df[['num_yes', 'something1', 'something']] # pick the columns I want to display, like a SELECTdf.sort_values('sometthing', ascending=True)[:30] # ORDER BY and LIMITdf[:30]
這并不是因?yàn)閜andas對如何編寫代碼強(qiáng)加了任何特定規(guī)則。只是按照J(rèn)OIN / WHERE / GROUP BY / HAVING的順序編寫代碼通常好理解。(不過,我經(jīng)常會先放一個(gè)WHERE來提高性能,而且我認(rèn)為大多數(shù)數(shù)據(jù)庫引擎實(shí)際也會先執(zhí)行WHERE)
在R的dplyr中,你還能使用不同的語法來查詢諸如Postgres、MySQL或SQLite等SQL數(shù)據(jù)庫,它們的順序也更符合邏輯。
不知道這一點(diǎn)令我自己著實(shí)驚訝
我寫了這樣一篇博文,因?yàn)楫?dāng)我發(fā)現(xiàn)這個(gè)順序的時(shí)候非常驚訝,我以前從來沒有看到過它被這樣寫下來 — 它基本上解釋了我憑直覺所知道的,關(guān)于為什么一些查詢被允許而另一些不被允許的一切。所以我想把它寫下來,希望它能幫助其他人理解如何編寫SQL查詢。
原文:https://jvns.ca/blog/2019/10/03/sql-queries-don-t-start-with-select/

往 期 推 薦 1、Intellij IDEA這樣 配置注釋模板,讓你瞬間高出一個(gè)逼格!
2、Spring+SpringMVC+Mybatis實(shí)現(xiàn)校園二手交易平臺【實(shí)戰(zhàn)項(xiàng)目】
3、基于SpringBoot的迷你商城系統(tǒng),附源碼!
4、把Redis當(dāng)作隊(duì)列來用,真的合適嗎?
5、驚呆了,Spring Boot居然這么耗內(nèi)存!你知道嗎?
6、全網(wǎng)最全 Java 日志框架適配方案!還有誰不會?
7、Spring中毒太深,離開Spring我居然連最基本的接口都不會寫了 點(diǎn)分享
點(diǎn)收藏
點(diǎn)點(diǎn)贊
點(diǎn)在看



