
細(xì)說目標(biāo)檢測中的Anchors
點擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達(dá)
本文轉(zhuǎn)載自52cv。
作者:Raghul Asokan
編譯:ronghuaiyang
給大家再次解釋一下Anchors在物體檢測中的作用。
今天,我將討論在物體檢測器中引入的一個優(yōu)雅的概念 ——?Anchors,它是如何幫助檢測圖像中的物體,以及它們與傳統(tǒng)的兩階段檢測器中的Anchor有何不同。
像往常一樣,讓我們看看在哪些問題中,anchors被引入作為解決方案。
在開始使用anchors之前,讓我們看看兩階段物體檢測器是如何工作的,以及它們實際上是如何促進(jìn)單階段檢測器的發(fā)展的。
兩階段物體檢測器:傳統(tǒng)的兩階段物體檢測器檢測圖像中的物體分兩階段進(jìn)行:
第一階段:第一階段遍歷輸入圖像和物體可能出現(xiàn)的輸出區(qū)域(稱為建議區(qū)域或感興趣的區(qū)域)。這個過程可以通過外部算法(例如:selective search)或者神經(jīng)網(wǎng)絡(luò)來完成。 第二階段:第二階段是一個神經(jīng)網(wǎng)絡(luò),它接受這些感興趣的區(qū)域,并將其分類到一個目標(biāo)物體類中。
為了簡單起見,我會介紹一個著名的兩級探測器 ——?Faster-RCNN。兩個階段都包含了一個神經(jīng)網(wǎng)絡(luò)。
第一個神經(jīng)網(wǎng)絡(luò)預(yù)測一個物體可能出現(xiàn)的位置(也稱為objectness得分)。它基本上就是一個對前景(物體)和背景的分類。這個網(wǎng)絡(luò)被稱為區(qū)域建議網(wǎng)絡(luò),又名RPN。 提取區(qū)域建議后,對輸入圖像中對應(yīng)的位置進(jìn)行裁剪,送入下一個神經(jīng)網(wǎng)絡(luò)進(jìn)行分類,假設(shè)有N個目標(biāo)類。這個網(wǎng)絡(luò)預(yù)測在那個位置上存在什么物體。
步驟2看起來非常簡單,因為它可以歸結(jié)為圖像分類,即將目標(biāo)物體分成N個類別中的一個。
讓我們深入研究第1步。
(a) 這個神經(jīng)網(wǎng)絡(luò)如何預(yù)測這些目標(biāo)的位置?
(b) 如果可以訓(xùn)練神經(jīng)網(wǎng)絡(luò)進(jìn)行前景和背景的分類,那么為什么不訓(xùn)練它一次預(yù)測所有N個類呢?
(a) 的解決方案就是anchors,(b)的答案是肯定的,我們可以用一個單一的網(wǎng)絡(luò)來執(zhí)行N-way目標(biāo)檢測,這樣的網(wǎng)絡(luò)就是眾所周知的單階段目標(biāo)檢測器。單階段檢測器與Faster-RCNN中第一個階段的網(wǎng)絡(luò)幾乎相同。
我說SSD和RPN幾乎是一樣的,因為它們在概念上是相同的,但是在體系結(jié)構(gòu)上有不同。
問題:神經(jīng)網(wǎng)絡(luò)如何檢測圖像中的物體?
解決方案(1) —— 單目標(biāo)檢測:讓我們使用最簡單的情況,在一個圖像中找到一個單一的物體。給定一個圖像,神經(jīng)網(wǎng)絡(luò)必須輸出物體的類以及它的邊界框在圖像中的坐標(biāo)。所以網(wǎng)絡(luò)必須輸出4+C個數(shù)字,其中C是類別的數(shù)量。
可以直接將輸入圖像通過一組卷積層然后將最后的卷積輸出轉(zhuǎn)換為一個4+C維的向量,其中,前4個數(shù)字表示物體的位置(比如minx, miny, maxx, maxy),后面的C個數(shù)字表示類別概率的得分。
解決方案(2) —— 多目標(biāo)檢測:這可以通過將上述方法擴展為N個物體來實現(xiàn)。因此,網(wǎng)絡(luò)現(xiàn)在輸出的不是4+C的數(shù)字,而是*N*(4+C)*數(shù)字。
取一個大小為H x W x 3的輸入圖像讓它通過一組卷積層得到一個大小為H x W x d的卷積體,d是通道的深度或數(shù)量。

考慮上面的輸出卷積 volume。假設(shè)volume大小為7×7×512。使用N個大小為3 x 3 x 512的濾波器,stride=2, padding=1,產(chǎn)生大小為4 x 4 x N的輸出volume。
我們?nèi)∵@個大小為4 x 4 x N的輸出試著推斷它的含義。
在輸出的特征圖中有16個cells,我們可以說,每個cell都有一個接收域(或感受野),對應(yīng)到原始圖像中的某個點。每個這樣的cell都有N個與之相關(guān)的數(shù)字。正如我前面指出的,N是類別的數(shù)量,我們可以說,每個cell都有關(guān)于在feature map中對應(yīng)位置上出現(xiàn)的物體的信息。以同樣的方式,還有另一個并行的conv頭,其中有4個大小為3 x 3 x 512的濾波器,應(yīng)用在同一個conv volume上,以獲得另一個大小為4 x 4 x 4的輸出 —— 這對應(yīng)邊界框的偏移量。
現(xiàn)在我們知道如何用一個神經(jīng)網(wǎng)絡(luò)來預(yù)測多個目標(biāo)。但是等一下,我們?nèi)绾斡嬎氵@個輸出為4x4xn的cell的損失呢?
現(xiàn)在讓我們深入到輸出層使用的N個濾波器中。從N個濾波器中取出一個,看看它是如何通過對feature map進(jìn)行卷積得到輸出的。
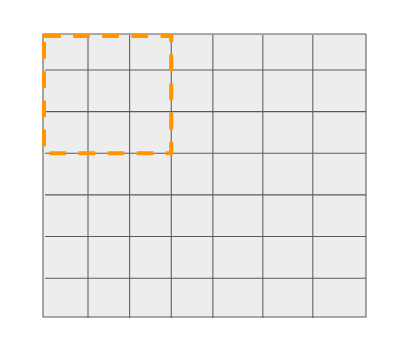
這個3x3的濾波器可以在7x7的網(wǎng)格上移動16個不一樣的位置,并做出預(yù)測(如前所述),這是非常明顯的。
我們知道,網(wǎng)格中的16個cell對應(yīng)于它之前的層中的一個特定位置。請看下面的圖表。輸出網(wǎng)格中的第一個cell有一個大小為3x3的參考框。
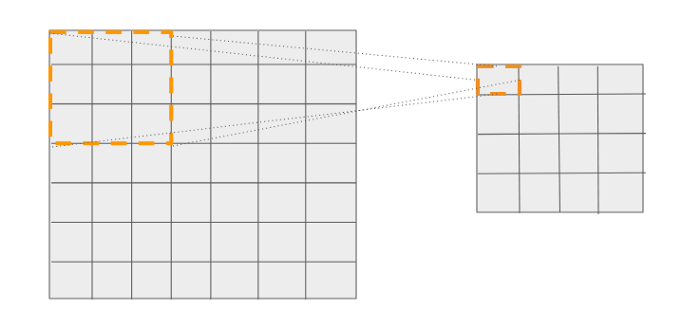
第一個cell可以與輸入圖像中的特定位置相關(guān)聯(lián),從該位置進(jìn)行預(yù)測。
類似地,輸出中的每個cell都可以與輸入圖像中的特定位置相關(guān)聯(lián),從該位置進(jìn)行預(yù)測。
因此有16個這樣的參考位置(大小為3x3) —— 每個位置都有自己相對于輸入圖像的坐標(biāo)。現(xiàn)在通過這些參考位置,我們可以實現(xiàn)兩個目標(biāo):
分類損失:如果N個物體中有一個落在這16個參考位置,即與ground truth的包圍框的IOU≥某個閾值,那么我們就知道要匹配哪個ground truth了。 回歸損失:為什么我們需要這個?假設(shè)一個物體落在其中一個參考框中,我們可以簡單地輸出這些參考位置相對于輸入圖像的實際坐標(biāo)。原因是物體不必是方形的。因此,我們不是天真地輸出一組固定的框坐標(biāo),而是通過輸出4個偏移值來調(diào)整這些參考位置的默認(rèn)坐標(biāo)。現(xiàn)在我們已經(jīng)知道了ground truth box坐標(biāo)和相應(yīng)的參考位置坐標(biāo),我們可以簡單地使用L1/L2距離來計算回歸損失。
與圖像分類的任務(wù)中只有輸出向量要匹配不同,這里我們有16個參考位置要匹配。這意味著該網(wǎng)絡(luò)可以一次性預(yù)測16個物體。要預(yù)測的物體數(shù)量可以通過對多特征圖層次進(jìn)行預(yù)測或通過增加特征圖上所謂的參考位置來增加。
這些參考位置就是anchor boxes或者default boxes。
在上面的例子中,只有一個anchor框,也就是每個濾波器位置只做了一個預(yù)測。
通常,在feature map中,每個filter位置都可以進(jìn)行多次預(yù)測 —— 這意味著需要有多少預(yù)測就有多少個參考。
假設(shè)每個filter位置有3個參考。
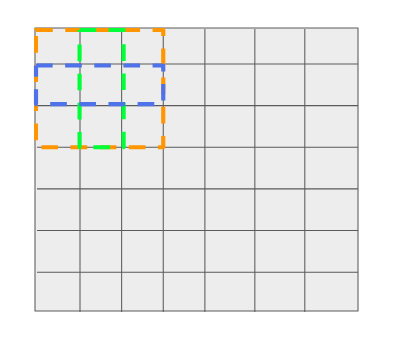
正如我們前面看到的,輸出是anchor框的函數(shù),因此如果參考/anchor的數(shù)量改變,輸出的大小也會改變。因此,網(wǎng)絡(luò)輸出的不是1個anchor點的4x4xN(和4x4x4),而是由于anchor數(shù)=3,所以輸出的是4x4x(N*3)。
一般來說,單階段探測器的輸出形狀可以寫成:
分類頭的形狀:HxWxNA
回歸頭的形狀:HxWx4A
式中,A為使用anchrs的數(shù)量。
一個問題!
每個filter位置有多個anchors/參考框的意義是什么?
這使得網(wǎng)絡(luò)能夠在圖像的給每個位置上預(yù)測多個不同大小的目標(biāo)。
這種在末端使用卷積層來獲得輸出的單階段檢測器的變體稱為SSD,而在末端使用全連接層來獲得輸出的變體稱為YOLO。
我希望我已經(jīng)把anchor的概念變得為大家容易理解。anchor總是一個難以把握的概念,在這個博客中仍然有一些關(guān)于anchor的未解問題。我想在接下來的文章中回答這些問題。到時候見:)
英文原文:
https://towardsdatascience.com/neural-networks-intuitions-5-anchors-and-object-detection-fc9b12120830