
JMH 和 Arthas 定位問題的案例分享 !
點擊關(guān)注公眾號,Java干貨及時送達(dá)??

https://bryantchang.github.io/2019/12/08/java-profile-tools/
最近的工作日并不算太平,各種大大小小的case和解case,發(fā)現(xiàn)已經(jīng)有好久好久沒有靜下心來專心寫點東西了。不過倒還是堅持利用業(yè)余時間學(xué)習(xí)了不少微課上的東西,發(fā)現(xiàn)大佬們總結(jié)的東西還是不一樣,相比于大學(xué)時的那些枯燥的課本,大佬們總結(jié)出來的內(nèi)容更活,更加容易理解。自己后面也會把大佬們的東西好好消化吸收,變成自己的東西用文字性的東西表達(dá)出來。
今天想總結(jié)的東西是最近工作中使用到的測試工具JMH以及Java運行時監(jiān)控工具Arthas。他們在我的實際工作中也算是幫了大忙。所以在這里拋磚引玉一下這些工具的使用方法。同時也加深一下自己對這些工具的熟悉程度。對這兩個工具,我都會首先簡單介紹一下這些工具的大致使用場景,然后會使用一個在工作中真正遇到的性能問題排查為例詳細(xì)講解這兩個工具的實際用法。話不多說,直奔主題。
問題描述
為了能夠讓我后面的實例能夠貫穿這兩個工具的使用,我首先簡單描述下我們在開發(fā)中遇到的實際的性能問題。然后再引出這兩個性能工具的實際使用,看我們?nèi)绾问褂眠@兩個工具成功定位到性能瓶頸的。
問題如下:為了能夠支持丟失率,我們將原先log4j2 的Async+自定義Appender的方式進(jìn)行了修正,把異步的邏輯放到了自己改版后的Appender中。但我們發(fā)現(xiàn)修改后日志性能要比之前Async+自定義Appender的方式下降不少。這里由于隱私原因我并沒有用實際公司中的實例,這里我用了一種其他同樣能夠體現(xiàn)問題的方式。我們暫時先不給出具體的配置文件,先給出性能測試代碼和結(jié)果
代碼
package com.bryantchang.appendertest;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class AppenderTest {
private static final String LOGGER_NAME_DEFAULT = "defaultLogger";
private static final String LOGGER_NAME_INCLUDE = "includeLocationLogger";
private static final Logger LOGGER = LoggerFactory.getLogger(LOGGER_NAME_INCLUDE);
public static final long BATCH = 10000;
public static void main(String[] args) throws InterruptedException {
while(true) {
long start, end;
start = System.currentTimeMillis();
for (int i = 0; i < BATCH; i++) {
LOGGER.info("msg is {}", i);
}
end = System.currentTimeMillis();
System.out.println("duration of " + LOGGER_NAME_INCLUDE + " is " + (end - start) + "ms");
Thread.sleep(1000);
}
}
}
代碼邏輯及其簡單,就是調(diào)用logger.info每次打印10000條日志,然后記錄耗時。兩者的對比如下
果")
對比結(jié)果
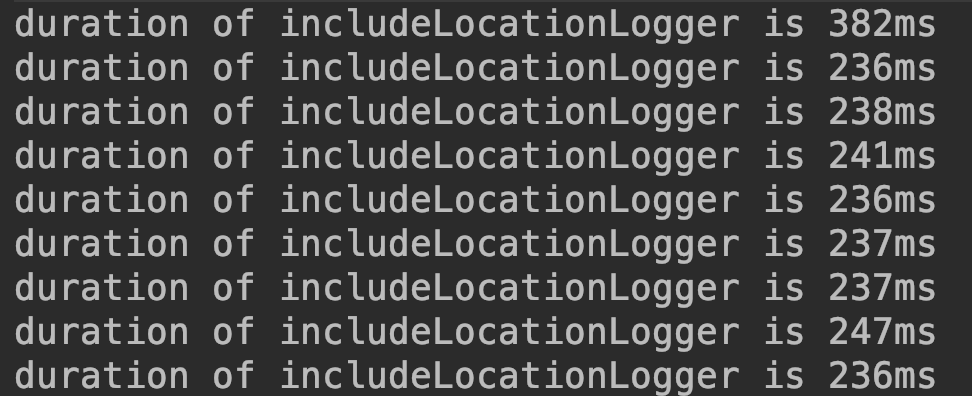
從這兩張圖片中我們能夠看到同樣的邏輯,兩個程序的耗時差距相差了數(shù)十倍,但看圖片,貌似僅僅是logger的名稱不一樣。對上面的實驗結(jié)果進(jìn)行分析,我們可能會有兩個疑問
上面的代碼測試是否標(biāo)準(zhǔn),規(guī)范
如果真的是性能問題,那么這兩個代碼到底在哪個方法上有了這么大的差距導(dǎo)致了最終的性能差異
下面這兩個工具就分別來回答這兩個問題
JMH簡介
第一個問題就是,測試的方法是否標(biāo)準(zhǔn)。我們在編寫代碼時用的是死循環(huán)+前后“掐秒表”的方式。假如我們要再加個多線程的測試,我們還需要搞一個線程池,除了代碼本身的邏輯還要關(guān)心測試的邏輯。我們會想,有沒有一款工具能夠?qū)⑽覀儚臏y試邏輯中徹底解放出來,只需要關(guān)心我們需要測試的代碼邏輯。JMH就是這樣一款Java的測試框架。下面是JMH的官方定義
JMH 是一個面向 Java 語言或者其他 Java 虛擬機(jī)語言的性能基準(zhǔn)測試框架
這里面我們需要注意的是,JMH所測試的方法約簡單越好,依賴越少越好,最適合的場景就是,測試兩個集合put,get性能,例如ArrayList與LinkedList的對比等,這里我們需要測試的是批量打一批日志所需要的時間,也基本符合使用JMH的測試場景。下面是測試代碼,bench框架代碼以及主函數(shù)。
待測試方法
public class LogBenchMarkWorker {
private LogBenchMarkWorker() {}
private static class LogBenchMarkWorkerInstance {
private static final LogBenchMarkWorker instance = new LogBenchMarkWorker();
}
public static LogBenchMarkWorker getInstance() {
return LogBenchMarkWorkerInstance.instance;
}
private static final String LOGGER_DEFAULT_NAME = "defaultLogger";
private static final String LOGGER_INCLUDE_LOCATION = "includeLocationLogger";
private static final Logger LOGGER = LoggerFactory.getLogger(LOGGER_DEFAULT_NAME);
private static long BATCH_SIZE = 10000;
public void logBatch() {
for (int i = 0; i < BATCH_SIZE; i++) {
LOGGER.info("msg is {}", i);
}
}
}
可以看到待測試方法非常簡單,就是單批次一次性打印10000條日志的操作,所以并沒有需要額外說明的部分。下面我們再來看benchmark部分。
public class LogBenchMarkMain {
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@Fork(value = 1)
@Threads(1)
public void testLog1() {
LogBenchMarkWorker.getInstance().logBatch();
}
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@Fork(value = 1)
@Threads(4)
public void testLog4() {
LogBenchMarkWorker.getInstance().logBatch();
}
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@Fork(value = 1)
@Threads(8)
public void testLog8() {
LogBenchMarkWorker.getInstance().logBatch();
}
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@Fork(value = 1)
@Threads(16)
public void testLog16() {
LogBenchMarkWorker.getInstance().logBatch();
}
在這段代碼中,我們就會發(fā)現(xiàn)有了一些JMH中特有的東西,我下面進(jìn)行簡要介紹。
Benchmark注解:標(biāo)識在某個具體方法上,表示這個方法將是一個被測試的最小方法,在JMH中成為一個OPS
BenmarkMode:測試類型,JMH提供了幾種不同的Mode
Throughput:整體吞吐量
AverageTime:調(diào)用的平均時間,每次OPS執(zhí)行的時間
SampleTime:取樣,給出不同比例的ops時間,例如99%的ops時間,99.99%的ops時間
fork:fork的次數(shù),如果設(shè)置為2,JMH會fork出兩個進(jìn)程來測試
Threads:很容易理解,這個參數(shù)表示這個方法同時被多少個線程執(zhí)行
在上面的代碼中,我定義了4個待測試的方法,方法的Fork,BenchmarkMode均為測試單次OPS的平均時間,但4個方法的線程數(shù)不同。
除了這幾個參數(shù),還有幾個參數(shù),我會在main函數(shù)里面來講,main代碼如下所示
public class Main {
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(LogBenchMarkMain.class.getSimpleName())
.warmupIterations(5)
.measurementIterations(5)
.output("logs/BenchmarkCommon.log")
.build();
new Runner(options).run();
}
}
我們可以看到,在main函數(shù)中,我們就是要設(shè)置JMH的基礎(chǔ)配置,這里面的幾個配置參數(shù)含義如下:
include:benchmark所在類的名字,可以使用正則表達(dá)
warmupIteration:預(yù)熱的迭代次數(shù),這里為什么要預(yù)熱的原因是由于JIT的存在,隨著代碼的運行,會動態(tài)對代碼的運行進(jìn)行優(yōu)化。因此在測試過程中需要先預(yù)熱幾輪,讓代碼運行穩(wěn)定后再實際進(jìn)行測試
measurementIterations:實際測試輪次
output:測試報告輸出位置
我分別用兩種logger運行一下測試,查看性能測試報告對比
使用普通logger
LogBenchMarkMain.testLog1 avgt 5 0.006 ± 0.001 s/op
LogBenchMarkMain.testLog16 avgt 5 0.062 ± 0.026 s/op
LogBenchMarkMain.testLog4 avgt 5 0.006 ± 0.002 s/op
LogBenchMarkMain.testLog8 avgt 5 0.040 ± 0.004 s/op
使用了INCLUDE_LOCATION的logger
LogBenchMarkMain.testLog1 avgt 5 0.379 ± 0.007 s/op
LogBenchMarkMain.testLog16 avgt 5 1.784 ± 0.670 s/op
LogBenchMarkMain.testLog4 avgt 5 0.378 ± 0.003 s/op
LogBenchMarkMain.testLog8 avgt 5 0.776 ± 0.070 s/op
這里我們看到,性能差距立現(xiàn)。使用INCLUDE_LOCATION的性能要明顯低于使用普通logger的性能。這是我們一定很好奇,并且問一句“到底慢在哪”!!
Arthas 我的代碼在運行時到底做了什么
Arthas是阿里開源的一款java調(diào)試神器,與greys類似,不過有著比greys更加強(qiáng)大的功能,例如,可以直接繪制java方法調(diào)用的火焰圖等。這兩個工具的原理都是使用了Java強(qiáng)大的字節(jié)碼技術(shù)。畢竟我也不是JVM大佬,所以具體的實現(xiàn)細(xì)節(jié)沒法展開,我們要做的就是站在巨人的肩膀上,接受并用熟練的使用好這些好用的性能監(jiān)控工具。
實際操作
talk is cheap, show me your code,既然是工具,我們直接進(jìn)行實際操作。我們在本機(jī)運行我們一開始的程序,然后講解arthas的使用方法。
我們首先通過jps找到程序的進(jìn)程號,然后直接通過arthas給到的as.sh對我們運行的程序進(jìn)行字節(jié)碼增強(qiáng),然后啟動arthas,命令如下
./as.sh pid這個就是arthas的啟動界面了,我們使用help命令查看工具所支持的功能
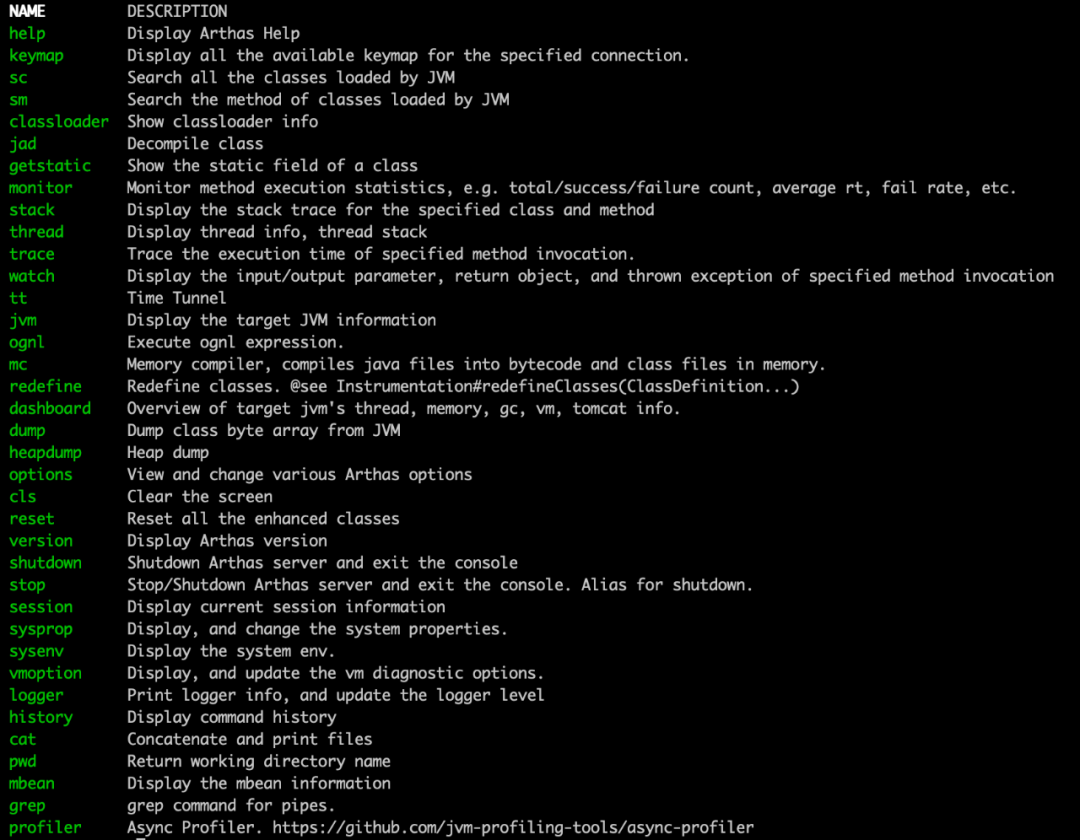
可以看到,arthas支持查看當(dāng)前jvm的狀態(tài),查看當(dāng)前的線程狀態(tài),監(jiān)控某些方法的調(diào)用時間,trace,profile生成火焰圖等,功能一應(yīng)俱全
我們這里也只將幾個比較常用的命令,其他的命令如果大家感興趣可以詳見官網(wǎng)arthas官網(wǎng)。這篇文章主要介紹下面幾個功能
反編譯代碼
監(jiān)控某個方法的調(diào)用
查看某個方法的調(diào)用和返回值
trace某個方法
監(jiān)控方法調(diào)用
這個主要的命令為monitor,根據(jù)官網(wǎng)的介紹,常用的使用方法為
monitor -c duration className methodName
其中duration代表每隔幾秒展示一次統(tǒng)計結(jié)果,即單次的統(tǒng)計周期,className就是類的全限定名,methodname就是方法的名字,這里面我們查看的方法是Logger類的info方法,我們分別對使用兩種不同logger的info方法。這里面的類是org.slf4j.Logger,方法時info,我們的監(jiān)控語句為
monitor -c 5 org.slf4j.Logger info
監(jiān)控結(jié)果如下
使用普通appender
使用include appender

我們可以看到,使用include appeder的打印日志方法要比普通的appender高出了3倍,這就不禁讓我們有了疑問,究竟這兩個方法各個步驟耗時如何呢。下面我們就介紹第二條命令,trace方法。
trace命令 & jad命令
這兩個程序的log4j2配置文件如下
<configuration status="warn" monitorInterval="30">
<appenders>
<Console name="console" target="SYSTEM_OUT">
<ThresholdFilter level="warn" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="[%d{HH:mm:ss.SSS}] [%-5p] %l - %m%n"/>
Console>
<Async name="AsyncDefault" blocking="false" includeLocation="false">
<AppenderRef ref="fileAppender"/>
Async>
<Async name="AsyncIncludeLocation" blocking="false" includeLocation="true">
<AppenderRef ref="fileAppender"/>
Async>
<File name="fileAppender" fileName="log/test.log" append="false">
<PatternLayout pattern="[%d{HH:mm:ss.SSS}] [%-5p] %l - %m%n"/>
File>
<File name="ERROR" fileName="logs/error.log">
<ThresholdFilter level="error" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="[%d{yyyy.MM.dd 'at' HH:mm:ss z}] [%-5p] %l - %m%n"/>
File>
<RollingFile name="rollingFile" fileName="logs/app.log"
filePattern="logs/$${date:yyyy-MM}/web-%d{yyyy-MM-dd}.log.gz">
<PatternLayout pattern="[%d{yyyy-MM-dd HH:mm:ss}] [%-5p] %l - %m%n"/>
<Policies>
<TimeBasedTriggeringPolicy modulate="true" interval="1"/>
Policies>
<DefaultRolloverStrategy>
<Delete basePath="logs" maxDepth="2">
<IfFileName glob="*/*.log.gz" />
<IfLastModified age="7d" />
Delete>
DefaultRolloverStrategy>
RollingFile>
appenders>
<loggers>
<logger name="defaultLogger" additivity="false">
<appender-ref ref="AsyncDefault">appender-ref>
logger>
<logger name="includeLocationLogger" additivity="false">
<appender-ref ref="AsyncIncludeLocation">appender-ref>
logger>
<root level="INFO">
root>
loggers>
configuration>
我們都是用了一個AsyncAppender套用了一個FileAppender。查看fileAppender,發(fā)現(xiàn)二者相同完全沒區(qū)別,只有asyncAppender中的一個選項有區(qū)別,這就是includeLocation,一個是false,另一個是true。至于這個參數(shù)的含義,我們暫時不討論,我們現(xiàn)在知道問題可能出在AsyncAppender里面,但是我們該如何驗證呢。trace命令就有了大用場。
trace命令的基本用法與monitor類似,其中主要的一個參數(shù)是-n則是代表trace多少次的意思
trace -n trace_times className methodName
我在之前Log4j2的相關(guān)博客里面講到過,任何一個appender,最核心的方法就是他的append方法。所以我們分別trace兩個程序的append方法。
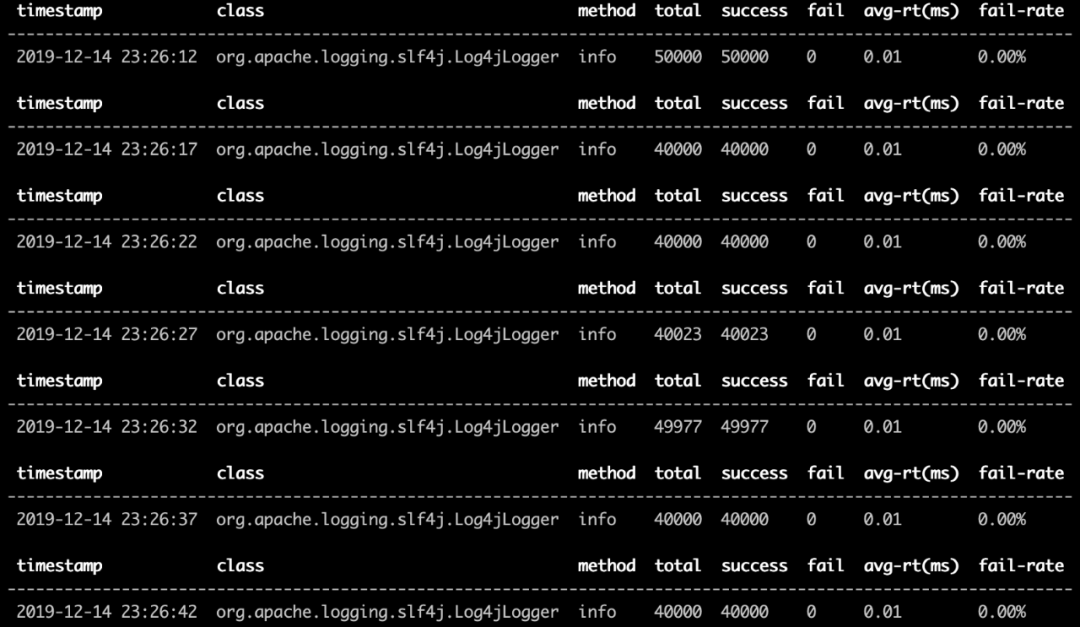
trace -n 5 org.apache.logging.log4j.core.appender.AsyncAppender append
trace結(jié)果如下
使用普通appender
使用include appender
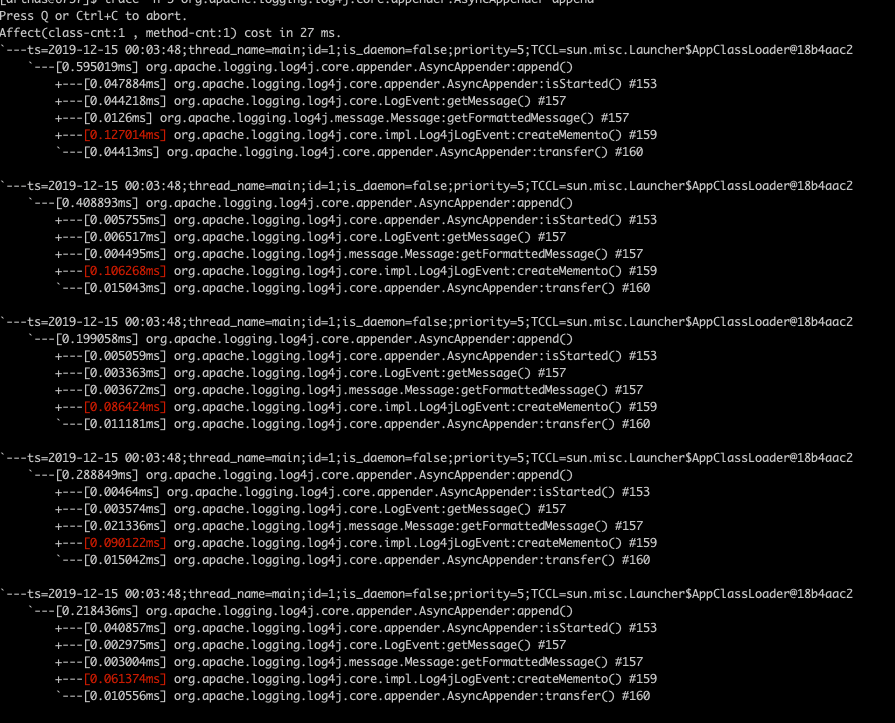
我們立刻可以發(fā)現(xiàn),兩個trace的熱點方法不一樣,在使用include的appender中,耗時最長的方法時org.apache.logging.log4j.core.impl.Log4jLogEvent類中的createMemento方法,那么怎么才能知道這個方法到底做了啥呢,那就請出我們下一個常用命令jad,這個命令能夠反編譯出對應(yīng)方法的代碼。這里我們jad一下上面說的那個createMemento方法,命令很簡單
jad org.apache.logging.log4j.core.impl.Log4jLogEvent createMemento
結(jié)果如下

我們發(fā)現(xiàn),這個方法中有個includeLocation參數(shù),這個和我們的看到的兩個appender的唯一不同的配置相吻合,我們此時應(yīng)該有這個猜想,會不會就是這個參數(shù)導(dǎo)致的呢?為了驗證這個猜想,我們引出下一個命令,watch
watch命令
watch命令能夠觀察到某個特定方法的入?yún)ⅲ祷刂档刃畔ⅲ覀兪褂眠@個命令查看一下這個createMemento方法的入?yún)ⅲ绻麅蓚€程序的入?yún)⒉煌腔究梢詳喽ㄊ沁@個原因引起命令如下
watch org.apache.logging.log4j.core.impl.Log4jLogEvent createMemento "params" -x 2 -n 5 -b -f
這里面的參數(shù)含義如下
-x 參數(shù)展開層次
-n 執(zhí)行次數(shù)
-b 查看方法調(diào)用前狀態(tài)
-f 方法調(diào)用后
其中的param代表查看方法的調(diào)用參數(shù)列表,還有其他的監(jiān)控項詳見官網(wǎng)官網(wǎng)
最終watch結(jié)果如下
使用普通logger
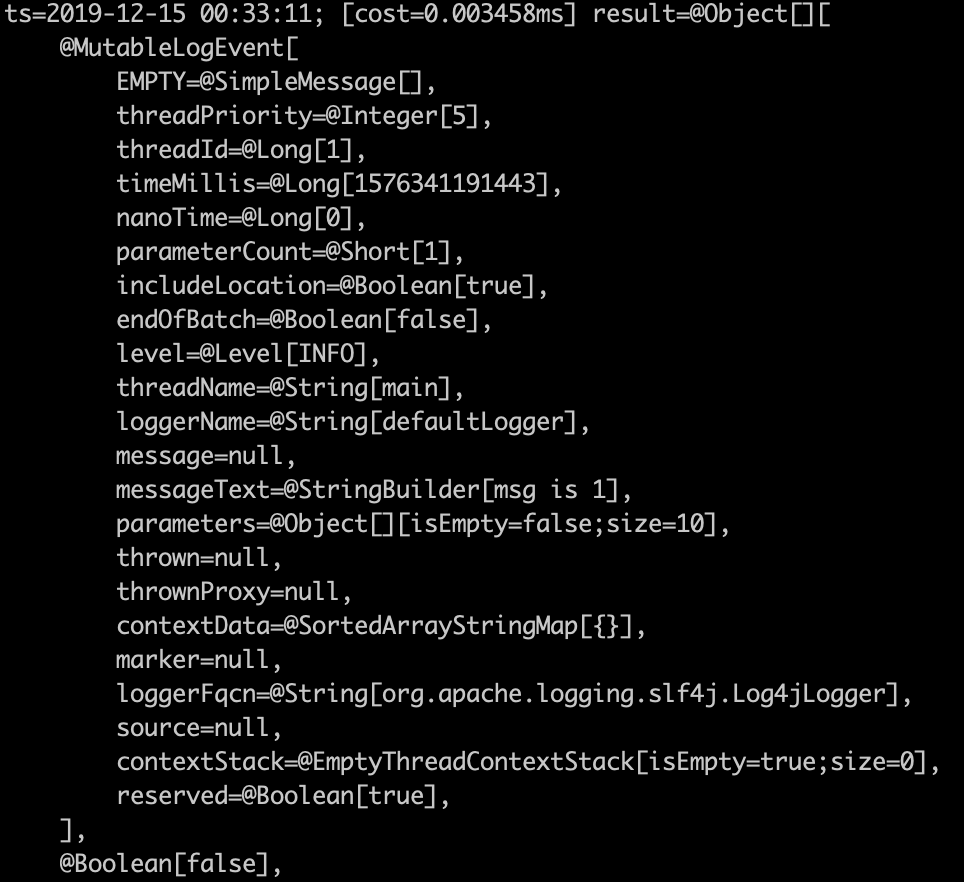
使用include
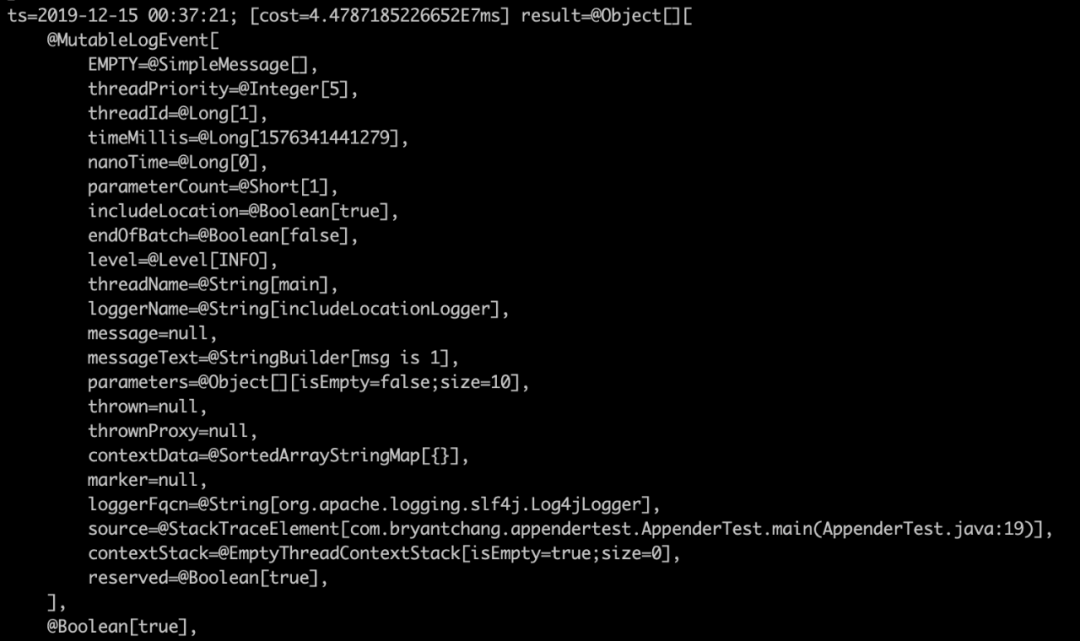
果不其然,這兩個參數(shù)果然是一個true一個false,我們簡單看下這個參數(shù)是如何傳進(jìn)來的,我們jad一下AsyncAppender的append方法

我們發(fā)現(xiàn)這個includeLocation正是appender的一個屬性,也就是我們xml中配置的那個屬性。查看官網(wǎng)的相關(guān)分析,我們看到這個參數(shù)會使log的性能下降5–10倍

不過為了一探究竟,我還是靜態(tài)跟了一下這段代碼
這個includeLocation會在event的createMemento中被用到,在序列化生成對象時會創(chuàng)建一個LogEventProxy,代碼如下
public LogEventProxy(final LogEvent event, final boolean includeLocation) {
this.loggerFQCN = event.getLoggerFqcn();
this.marker = event.getMarker();
this.level = event.getLevel();
this.loggerName = event.getLoggerName();
final Message msg = event.getMessage();
this.message = msg instanceof ReusableMessage
? memento((ReusableMessage) msg)
: msg;
this.timeMillis = event.getTimeMillis();
this.thrown = event.getThrown();
this.thrownProxy = event.getThrownProxy();
this.contextData = memento(event.getContextData());
this.contextStack = event.getContextStack();
this.source = includeLocation ? event.getSource() : null;
this.threadId = event.getThreadId();
this.threadName = event.getThreadName();
this.threadPriority = event.getThreadPriority();
this.isLocationRequired = includeLocation;
this.isEndOfBatch = event.isEndOfBatch();
this.nanoTime = event.getNanoTime();
}
如果includeLocation為true,那么就會調(diào)用getSource函數(shù),跟進(jìn)去查看,代碼如下
public StackTraceElement getSource() {
if (source != null) {
return source;
}
if (loggerFqcn == null || !includeLocation) {
return null;
}
source = Log4jLogEvent.calcLocation(loggerFqcn);
return source;
}
public static StackTraceElement calcLocation(final String fqcnOfLogger) {
if (fqcnOfLogger == null) {
return null;
}
// LOG4J2-1029 new Throwable().getStackTrace is faster than Thread.currentThread().getStackTrace().
final StackTraceElement[] stackTrace = new Throwable().getStackTrace();
StackTraceElement last = null;
for (int i = stackTrace.length - 1; i > 0; i--) {
final String className = stackTrace[i].getClassName();
if (fqcnOfLogger.equals(className)) {
return last;
}
last = stackTrace[i];
}
return null;
}
我們看到他會從整個的調(diào)用棧中去尋找調(diào)用這個方法的代碼行,其性能可想而知。我們用arthas監(jiān)控一下,驗證一下。
首先我們trace crateMemento方法
trace -n 5 org.apache.logging.log4j.core.impl.Log4jLogEvent createMemento

發(fā)現(xiàn)熱點方法時org.apache.logging.log4j.core.impl.Log4jLogEvent的serialize(),繼續(xù)trace下去
trace -n 5 org.apache.logging.log4j.core.impl.Log4jLogEvent serialize

看到熱點是org.apache.logging.log4j.core.impl.Log4jLogEvent:LogEventProxy的構(gòu)造方法,繼續(xù)trace
trace -n 5 org.apache.logging.log4j.core.impl.Log4jLogEvent$LogEventProxy
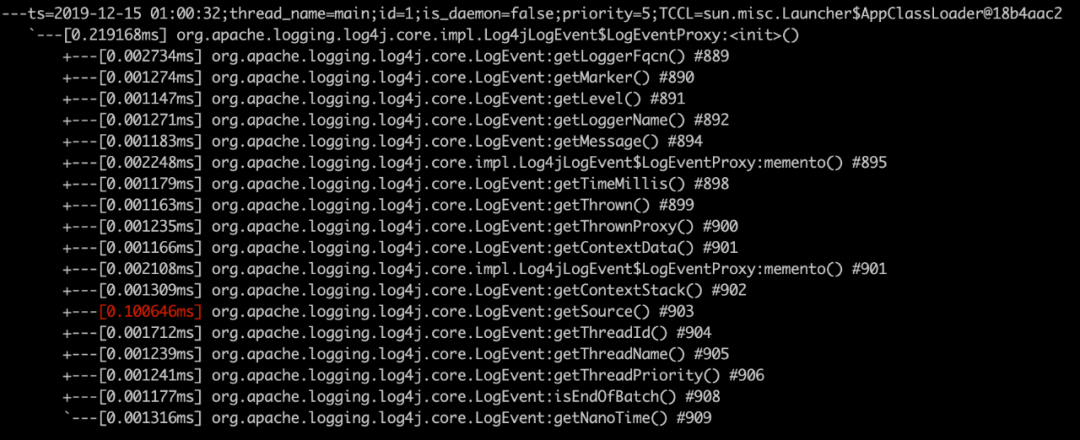
發(fā)現(xiàn)是getSource方法,繼續(xù)
trace -n 5 trace -n 5 org.apache.logging.log4j.core.LogEvent getSource
果")
熱點終于定位到了,是org.apache.logging.log4j.core.impl.Log4jLogEvent的calcLocation函數(shù),和我們靜態(tài)跟蹤的代碼一樣。
至此我們通過結(jié)合JMH和arthas共同定位出了一個線上的性能問題。不過我介紹的只是冰山一角,更多常用的命令還希望大家通過官網(wǎng)自己了解和實踐,有了幾次親身實踐之后,這個工具也就玩熟了。
2.?private修飾的方法可以通過反射訪問,那么private的意義是什么?
最近面試BAT,整理一份面試資料《Java面試BATJ通關(guān)手冊》,覆蓋了Java核心技術(shù)、JVM、Java并發(fā)、SSM、微服務(wù)、數(shù)據(jù)庫、數(shù)據(jù)結(jié)構(gòu)等等。
獲取方式:點“在看”,關(guān)注公眾號并回復(fù)?Java?領(lǐng)取,更多內(nèi)容陸續(xù)奉上。
PS:因公眾號平臺更改了推送規(guī)則,如果不想錯過內(nèi)容,記得讀完點一下“在看”,加個“星標(biāo)”,這樣每次新文章推送才會第一時間出現(xiàn)在你的訂閱列表里。
點“在看”支持小哈呀,謝謝啦??
