
可下載:60分鐘入門PyTorch(中文翻譯全集)
前言
原文翻譯自:Deep Learning with PyTorch: A 60 Minute Blitz
翻譯:林不清(https://www.zhihu.com/people/lu-guo-92-42-88)
林不清(林燕燕)是我的學生,這個是她入門PyTorch時候我讓她學習的,她把這個教程翻譯成了中文,分享給大家,希望對大家有幫助。
代碼下載地址:
https://github.com/fengdu78/machine_learning_beginner/tree/master/PyTorch_beginner
目錄
60分鐘入門PyTorch(一)——Tensors
60分鐘入門PyTorch(二)——Autograd自動求導
60分鐘入門Pytorch(三)——神經(jīng)網(wǎng)絡
60分鐘入門PyTorch(四)——訓練一個分類器
(一)Tensors
Tensors張量是一種特殊的數(shù)據(jù)結構,它和數(shù)組還有矩陣十分相似。在Pytorch中,我們使用tensors來給模型的輸入輸出以及參數(shù)進行編碼。Tensors除了張量可以在gpu或其他專用硬件上運行來加速計算之外,其他用法類似于Numpy中的ndarrays。如果你熟悉ndarrays,您就會熟悉tensor的API。如果沒有,請按照這個教程,快速了解一遍API。
%matplotlib?inline
import?torch
import?numpy?as?np
初始化Tensor
創(chuàng)建Tensor有多種方法,如:
直接從數(shù)據(jù)創(chuàng)建
可以直接利用數(shù)據(jù)創(chuàng)建tensor,數(shù)據(jù)類型會被自動推斷出
data?=?[[1,?2],[3,?4]]
x_data?=?torch.tensor(data)
從Numpy創(chuàng)建
Tensor 可以直接從numpy的array創(chuàng)建(反之亦然-參見bridge-to-np-label)
np_array?=?np.array(data)
x_np?=?torch.from_numpy(np_array)
從其他tensor創(chuàng)建
新的tensor保留了參數(shù)tensor的一些屬性(形狀,數(shù)據(jù)類型),除非顯式覆蓋
x_ones?=?torch.ones_like(x_data)?#?retains?the?properties?of?x_data
print(f"Ones?Tensor:?\n?{x_ones}?\n")
x_rand?=?torch.rand_like(x_data,?dtype=torch.float)?#?overrides?the?datatype?of?x_data
print(f"Random?Tensor:?\n?{x_rand}?\n")
Ones Tensor:
tensor([[1, 1],
[1, 1]])
Random Tensor:
tensor([[0.6075, 0.4581],
[0.5631, 0.1357]])
從常數(shù)或者隨機數(shù)創(chuàng)建
shape是關于tensor維度的一個元組,在下面的函數(shù)中,它決定了輸出tensor的維數(shù)。
shape?=?(2,3,)
rand_tensor?=?torch.rand(shape)
ones_tensor?=?torch.ones(shape)
zeros_tensor?=?torch.zeros(shape)
print(f"Random?Tensor:?\n?{rand_tensor}?\n")
print(f"Ones?Tensor:?\n?{ones_tensor}?\n")
print(f"Zeros?Tensor:?\n?{zeros_tensor}")
Random Tensor:
tensor([[0.7488, 0.0891, 0.8417],
[0.0783, 0.5984, 0.5709]])
Ones Tensor:
tensor([[1., 1., 1.],
[1., 1., 1.]])
Zeros Tensor:
tensor([[0., 0., 0.],
[0., 0., 0.]])
Tensor的屬性
Tensor的屬性包括形狀,數(shù)據(jù)類型以及存儲的設備
tensor?=?torch.rand(3,4)
print(f"Shape?of?tensor:?{tensor.shape}")
print(f"Datatype?of?tensor:?{tensor.dtype}")
print(f"Device?tensor?is?stored?on:?{tensor.device}")
Shape of tensor: torch.Size([3, 4])
Datatype of tensor: torch.float32
Device tensor is stored on: cpu
Tensor的操作
Tensor有超過100個操作,包括 transposing, indexing, slicing, mathematical operations, linear algebra, random sampling,更多詳細的介紹請點擊這里
它們都可以在GPU上運行(速度通常比CPU快),如果你使用的是Colab,通過編輯>筆記本設置來分配一個GPU。
#?We?move?our?tensor?to?the?GPU?if?available
if?torch.cuda.is_available():
??tensor?=?tensor.to('cuda')
嘗試列表中的一些操作。如果你熟悉NumPy API,你會發(fā)現(xiàn)tensor的API很容易使用。
標準的numpy類索引和切片:
tensor?=?torch.ones(4,?4)
tensor[:,1]?=?0
print(tensor)
tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])
合并tensors
可以使用torch.cat來沿著特定維數(shù)連接一系列張量。torch.stack另一個加入op的張量與torch.cat有細微的不同
t1?=?torch.cat([tensor,?tensor,?tensor],?dim=1)
print(t1)
tensor([[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],
[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],
[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],
[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.]])
增加tensors
#?This?computes?the?element-wise?product
print(f"tensor.mul(tensor)?\n?{tensor.mul(tensor)}?\n")
#?Alternative?syntax:
print(f"tensor?*?tensor?\n?{tensor?*?tensor}")
tensor.mul(tensor)
tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])
tensor * tensor
tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])
它計算兩個tensor之間的矩陣乘法
print(f"tensor.matmul(tensor.T)?\n?{tensor.matmul(tensor.T)}?\n")
#?Alternative?syntax:
print(f"tensor?@?tensor.T?\n?{tensor?@?tensor.T}")
tensor.matmul(tensor.T)
tensor([[3., 3., 3., 3.],
[3., 3., 3., 3.],
[3., 3., 3., 3.],
[3., 3., 3., 3.]])
tensor @ tensor.T
tensor([[3., 3., 3., 3.],
[3., 3., 3., 3.],
[3., 3., 3., 3.],
[3., 3., 3., 3.]])
原地操作
帶有后綴_的操作表示的是原地操作,例如:x.copy_(y),?x.t_()將改變?x.
print(tensor,?"\n")
tensor.add_(5)
print(tensor)
tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])
tensor([[6., 5., 6., 6.],
[6., 5., 6., 6.],
[6., 5., 6., 6.],
[6., 5., 6., 6.]])
注意
原地操作雖然會節(jié)省許多空間,但是由于會立刻清除歷史記錄所以在計算導數(shù)時可能會有問題,因此不建議使用
Tensor轉(zhuǎn)換為Numpt 數(shù)組
t?=?torch.ones(5)
print(f"t:?{t}")
n?=?t.numpy()
print(f"n:?{n}")
t: tensor([1., 1., 1., 1., 1.])
n: [1. 1. 1. 1. 1.]
tensor的變化反映在NumPy數(shù)組中。
t.add_(1)
print(f"t:?{t}")
print(f"n:?{n}")
t: tensor([2., 2., 2., 2., 2.])
n: [2. 2. 2. 2. 2.]
Numpy數(shù)組轉(zhuǎn)換為Tensor
n?=?np.ones(5)
t?=?torch.from_numpy(n)
NumPy數(shù)組的變化反映在tensor中
np.add(n,?1,?out=n)
print(f"t:?{t}")
print(f"n:?{n}")
t: tensor([2., 2., 2., 2., 2.], dtype=torch.float64)
n: [2. 2. 2. 2. 2.](二)Autograd:自動求導
torch.autograd是pytorch自動求導的工具,也是所有神經(jīng)網(wǎng)絡的核心。我們首先先簡單了解一下這個包如何訓練神經(jīng)網(wǎng)絡。
背景介紹
神經(jīng)網(wǎng)絡(NNs)是作用在輸入數(shù)據(jù)上的一系列嵌套函數(shù)的集合,這些函數(shù)由權重和誤差來定義,被存儲在PyTorch中的tensors中。
神經(jīng)網(wǎng)絡訓練的兩個步驟:
前向傳播:在前向傳播中,神經(jīng)網(wǎng)絡通過將接收到的數(shù)據(jù)與每一層對應的權重和誤差進行運算來對正確的輸出做出最好的預測。
反向傳播:在反向傳播中,神經(jīng)網(wǎng)絡調(diào)整其參數(shù)使得其與輸出誤差成比例。反向傳播基于梯度下降策略,是鏈式求導法則的一個應用,以目標的負梯度方向?qū)?shù)進行調(diào)整。
更加詳細的介紹可以參照下述地址:
[3Blue1Brown]:
https://www.youtube.com/watch?v=tIeHLnjs5U8
Pytorch應用
來看一個簡單的示例,我們從torchvision加載一個預先訓練好的resnet18模型,接著創(chuàng)建一個隨機數(shù)據(jù)tensor來表示一有3個通道、高度和寬度為64的圖像,其對應的標簽初始化為一些隨機值。
%matplotlib?inlineimport?torch,?torchvision
model?=?torchvision.models.resnet18(pretrained=True)
data?=?torch.rand(1,?3,?64,?64)
labels?=?torch.rand(1,?1000)接下來,我們將輸入數(shù)據(jù)向輸出方向傳播到模型的每一層中來預測輸出,這就是前向傳播。
prediction?=?model(data)?#?前向傳播我們利用模型的預測輸出和對應的權重來計算誤差,然后反向傳播誤差。完成計算后,您可以調(diào)用.backward()并自動計算所有梯度。此張量的梯度將累積到.grad屬性中。
loss?=?(prediction?-?labels).sum()
loss.backward()?#?反向傳播接著,我們加載一個優(yōu)化器,在本例中,SGD的學習率為0.01,momentum 為0.9。我們在優(yōu)化器中注冊模型的所有參數(shù)。
optim?=?torch.optim.SGD(model.parameters(),?lr=1e-2,?momentum=0.9)最后,我們調(diào)用
.step()來執(zhí)行梯度下降,優(yōu)化器通過存儲在.grad中的梯度來調(diào)整每個參數(shù)。optim.step()?#梯度下降現(xiàn)在,你已經(jīng)具備了訓練神經(jīng)網(wǎng)絡所需所有條件。下面幾節(jié)詳細介紹了Autograd包的工作原理——可以跳過它們。
Autograd中的求導
先來看一下
autograd是如何收集梯度的。我們創(chuàng)建兩個張量a和b并設置requires_grad = True以跟蹤它的計算。import?torch
a?=?torch.tensor([2.,?3.],?requires_grad=True)
b?=?torch.tensor([6.,?4.],?requires_grad=True)接著在
a和b的基礎上創(chuàng)建張量Q
Q?=?3*a**3?-?b**2假設
a和b是一個神經(jīng)網(wǎng)絡的權重,Q是它的誤差,在神經(jīng)網(wǎng)絡訓練中,我們需要w.r.t參數(shù)的誤差梯度,即當我們調(diào)用
同樣,我們也可以將Q的.backward()時,autograd計算這些梯度并把它們存儲在張量的?.grad屬性中。我們需要在Q.backward()中顯式傳遞gradient,gradient是一個與Q相同形狀的張量,它表示Q w.r.t本身的梯度,即Q聚合為一個標量并隱式向后調(diào)用,如Q.sum().backward()。
external_grad?=?torch.tensor([1.,?1.])
Q.backward(gradient=external_grad)現(xiàn)在梯度都被存放在
a.grad和b.grad中#?檢查一下存儲的梯度是否正確
print(9*a**2?==?a.grad)
print(-2*b?==?b.grad)可選閱讀----用autograd進行向量計算
在數(shù)學上,如果你有一個向量值函數(shù)??? =??(??? ) ,則??? 相對于??? 的梯度是雅可比矩陣:
一般來說,torch.autograd是一個計算雅可比向量積的引擎。也就是說,給定任何向量??=(??1??2...????)??,計算乘積?????。如果??恰好是標量函數(shù)的梯度??=??(??? ),即?然后根據(jù)鏈式法則,雅可比向量乘積將是??相對于??? 的梯度
雅可比向量積的這種特性使得將外部梯度饋送到具有非標量輸出的模型中非常方便。
external_grad?代表.圖計算
從概念上講,autograd在由函數(shù)對象組成的有向無環(huán)圖(DAG)中保存數(shù)據(jù)(tensor)和所有執(zhí)行的操作(以及產(chǎn)生的新tensor)的記錄,在這個DAG中,葉節(jié)點是輸入數(shù)據(jù),根節(jié)點是輸出數(shù)據(jù),通過從根節(jié)點到葉節(jié)點跟蹤這個圖,您可以使用鏈式法則自動計算梯度。
在前向傳播中,autograd同時完成兩件事情:
運行所請求的操作來計算結果tensor 保持DAG中操作的梯度 在反向傳播中,當在DAG根節(jié)點上調(diào)用
.backward()時,反向傳播啟動,autograd接下來完成:
計算每一個 .grad_fn的梯度將它們累加到各自張量的.grad屬性中 利用鏈式法則,一直傳播到葉節(jié)點 下面是DAG的可視化表示的示例。圖中,箭頭表示前向傳播的方向,節(jié)點表示向前傳遞中每個操作的向后函數(shù)。藍色標記的葉節(jié)點代表葉張量?
a和b
注意
DAG在PyTorch中是動態(tài)的。值得注意的是圖是重新開始創(chuàng)建的; 在調(diào)用每一個``.backward()``后,autograd開始填充一個新圖,這就是能夠在模型中使用控制流語句的原因。你可以根據(jù)需求在每次迭代時更改形狀、大小和操作。
torch.autograd追蹤所有requires_grad為True的張量的相關操作。對于不需要梯度的張量,將此屬性設置為False將其從梯度計算DAG中排除。操作的輸出張量將需要梯度,即使只有一個輸入張量requires_grad=True。x?=?torch.rand(5,?5)
y?=?torch.rand(5,?5)
z?=?torch.rand((5,?5),?requires_grad=True)
a?=?x?+?y
print(f"Does?`a`?require?gradients??:?{a.requires_grad}")
b?=?x?+?z
print(f"Does?`b`?require?gradients?:?{b.requires_grad}")在神經(jīng)網(wǎng)絡中,不計算梯度的參數(shù)通常稱為凍結參數(shù)。如果您事先知道您不需要這些參數(shù)的梯度,那么“凍結”部分模型是很有用的(這通過減少autograd計算帶來一些性能好處)。另外一個常見的用法是微調(diào)一個預訓練好的網(wǎng)絡,在微調(diào)的過程中,我們凍結大部分模型——通常,只修改分類器來對新的<標簽>做出預測,讓我們通過一個小示例來演示這一點。與前面一樣,我們加載一個預先訓練好的resnet18模型,并凍結所有參數(shù)。
from?torch?import?nn,?optim
model?=?torchvision.models.resnet18(pretrained=True)
#?凍結網(wǎng)絡中所有的參數(shù)
for?param?in?model.parameters():
????param.requires_grad?=?False假設我們想在一個有10個標簽的新數(shù)據(jù)集上微調(diào)模型。在resnet中,分類器是最后一個線性層模型
model.fc。我們可以簡單地用一個新的線性層(默認未凍結)代替它作為我們的分類器。model.fc?=?nn.Linear(512,?10)現(xiàn)在除了
model.fc的參數(shù)外,模型的其他參數(shù)均被凍結,參與計算的參數(shù)是model.fc的權值和偏置。#?只優(yōu)化分類器
optimizer?=?optim.SGD(model.fc.parameters(),?lr=1e-2,?momentum=0.9)注意,盡管我們注冊了優(yōu)化器中所有參數(shù),但唯一參與梯度計算(并因此在梯度下降中更新)的參數(shù)是分類器的權值和偏差。torch.no_grad()中也具有相同的功能。
拓展閱讀
[就地修改操作以及多線程Autograd]:(https://pytorch.org/docs/stable/notes/autograd.html) [反向模式autodiff的示例]:(https://colab.research.google.com/drive/1VpeE6UvEPRz9HmsHh1KS0XxXjYu533EC)
(三)神經(jīng)網(wǎng)絡
可以使用
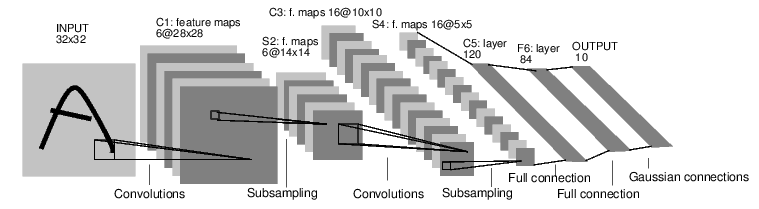
torch.nn包來構建神經(jīng)網(wǎng)絡. 你已知道autograd包,nn包依賴autograd包來定義模型并求導.一個nn.Module包含各個層和一個forward(input)方法,該方法返回output.例如,我們來看一下下面這個分類數(shù)字圖像的網(wǎng)絡.
他是一個簡單的前饋神經(jīng)網(wǎng)絡,它接受一個輸入,然后一層接著一層的輸入,直到最后得到結果。
神經(jīng)網(wǎng)絡的典型訓練過程如下:
定義神經(jīng)網(wǎng)絡模型,它有一些可學習的參數(shù)(或者權重); 在數(shù)據(jù)集上迭代; 通過神經(jīng)網(wǎng)絡處理輸入; 計算損失(輸出結果和正確值的差距大小) 將梯度反向傳播會網(wǎng)絡的參數(shù); 更新網(wǎng)絡的參數(shù),主要使用如下簡單的更新原則: weight = weight - learning_rate * gradient定義網(wǎng)絡
我們先定義一個網(wǎng)絡:
import?torch
import?torch.nn?as?nn
import?torch.nn.functional?as?F
class?Net(nn.Module):
????def?__init__(self):
????????super(Net,?self).__init__()
????????#?1?input?image?channel,?6?output?channels,?3x3?square?convolution
????????#?kernel
????????self.conv1?=?nn.Conv2d(1,?6,?3)
????????self.conv2?=?nn.Conv2d(6,?16,?3)
????????#?an?affine?operation:?y?=?Wx?+?b
????????self.fc1?=?nn.Linear(16?*?6?*?6,?120)??#?6*6?from?image?dimension?
????????self.fc2?=?nn.Linear(120,?84)
????????self.fc3?=?nn.Linear(84,?10)
????def?forward(self,?x):
????????#?Max?pooling?over?a?(2,?2)?window
????????x?=?F.max_pool2d(F.relu(self.conv1(x)),?(2,?2))
????????#?If?the?size?is?a?square?you?can?only?specify?a?single?number
????????x?=?F.max_pool2d(F.relu(self.conv2(x)),?2)
????????x?=?x.view(-1,?self.num_flat_features(x))
????????x?=?F.relu(self.fc1(x))
????????x?=?F.relu(self.fc2(x))
????????x?=?self.fc3(x)
????????return?x
????def?num_flat_features(self,?x):
????????size?=?x.size()[1:]??#?all?dimensions?except?the?batch?dimension
????????num_features?=?1
????????for?s?in?size:
????????????num_features?*=?s
????????return?num_features
net?=?Net()
print(net)Net(
(conv1): Conv2d(1, 6, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=576, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)你只需定義
forward函數(shù),backward函數(shù)(計算梯度)在使用autograd時自動為你創(chuàng)建.你可以在forward函數(shù)中使用Tensor的任何操作。
net.parameters()返回模型需要學習的參數(shù)。params?=?list(net.parameters())
print(len(params))
print(params[0].size())??#?conv1's?.weight10
torch.Size([6, 1, 3, 3])構造一個隨機的3232的輸入,注意:這個網(wǎng)絡(LeNet)期望的輸入大小是3232.如果使用MNIST數(shù)據(jù)集來訓練這個網(wǎng)絡,請把圖片大小重新調(diào)整到32*32.
input?=?torch.randn(1,?1,?32,?32)
out?=?net(input)
print(out)tensor([[-0.0765, 0.0522, 0.0820, 0.0109, 0.0004, 0.0184, 0.1024, 0.0509,
0.0917, -0.0164]], grad_fn=) 將所有參數(shù)的梯度緩存清零,然后進行隨機梯度的的反向傳播.
net.zero_grad()
out.backward(torch.randn(1,?10))注意
``torch.nn``只支持小批量輸入,整個torch.nn包都只支持小批量樣本,而不支持單個樣本 例如,``nn.Conv2d``將接受一個4維的張量,每一維分別是(樣本數(shù)*通道數(shù)*高*寬). 如果你有單個樣本,只需使用`input.unsqueeze(0)`來添加其它的維數(shù). 在繼續(xù)之前,我們回顧一下到目前為止見過的所有類.
回顧
torch.Tensor-支持自動編程操作(如backward())的多維數(shù)組。同時保持梯度的張量。nn.Module-神經(jīng)網(wǎng)絡模塊.封裝參數(shù),移動到GPU上運行,導出,加載等nn.Parameter-一種張量,當把它賦值給一個Module時,被自動的注冊為參數(shù).autograd.Function-實現(xiàn)一個自動求導操作的前向和反向定義, 每個張量操作都會創(chuàng)建至少一個Function節(jié)點,該節(jié)點連接到創(chuàng)建張量并對其歷史進行編碼的函數(shù)。現(xiàn)在,我們包含了如下內(nèi)容:
定義一個神經(jīng)網(wǎng)絡 處理輸入和調(diào)用 backward剩下的內(nèi)容:
計算損失值 更新神經(jīng)網(wǎng)絡的權值 損失函數(shù)
一個損失函數(shù)接受一對(output, target)作為輸入(output為網(wǎng)絡的輸出,target為實際值),計算一個值來估計網(wǎng)絡的輸出和目標值相差多少。
在nn包中有幾種不同的損失函數(shù).一個簡單的損失函數(shù)是:
nn.MSELoss,它計算輸入和目標之間的均方誤差。例如:
output?=?net(input)
target?=?torch.randn(10)??#?a?dummy?target,?for?example
target?=?target.view(1,?-1)??#?make?it?the?same?shape?as?output
criterion?=?nn.MSELoss()
loss?=?criterion(output,?target)
print(loss)tensor(1.5801, grad_fn=) 現(xiàn)在,你反向跟蹤
loss,使用它的.grad_fn屬性,你會看到向下面這樣的一個計算圖: input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d -> view -> linear -> relu -> linear -> relu -> linear -> MSELoss -> loss所以, 當你調(diào)用
loss.backward(),整個圖被區(qū)分為損失以及圖中所有具有requires_grad = True的張量,并且其.grad?張量的梯度累積。為了說明,我們反向跟蹤幾步:
print(loss.grad_fn)??#?MSELoss
print(loss.grad_fn.next_functions[0][0])??#?Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0])??#?ReLU反向傳播
為了反向傳播誤差,我們所需做的是調(diào)用
loss.backward().你需要清除已存在的梯度,否則梯度將被累加到已存在的梯度。現(xiàn)在,我們將調(diào)用
loss.backward(),并查看conv1層的偏置項在反向傳播前后的梯度。net.zero_grad()?????#?zeroes?the?gradient?buffers?of?all?parameters
print('conv1.bias.grad?before?backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad?after?backward')
print(net.conv1.bias.grad)conv1.bias.grad before backward
tensor([0., 0., 0., 0., 0., 0.])
conv1.bias.grad after backward
tensor([ 0.0013, 0.0068, 0.0096, 0.0039, -0.0105, -0.0016])現(xiàn)在,我們知道了該如何使用損失函數(shù)
稍后閱讀:
神經(jīng)網(wǎng)絡包包含了各種用來構成深度神經(jīng)網(wǎng)絡構建塊的模塊和損失函數(shù),一份完整的文檔查看這里
唯一剩下的內(nèi)容:
更新網(wǎng)絡的權重 更新權重
實踐中最簡單的更新規(guī)則是隨機梯度下降(SGD).
weight=weight?learning_rate?gradient我們可以使用簡單的Python代碼實現(xiàn)這個規(guī)則。
learning_rate?=?0.01
for?f?in?net.parameters():
????f.data.sub_(f.grad.data?*?learning_rate)然而,當你使用神經(jīng)網(wǎng)絡是,你想要使用各種不同的更新規(guī)則,比如
SGD,Nesterov-SGD,Adam,?RMSPROP等.為了能做到這一點,我們構建了一個包torch.optim實現(xiàn)了所有的這些規(guī)則.使用他們非常簡單:import?torch.optim?as?optim
#?create?your?optimizer
optimizer?=?optim.SGD(net.parameters(),?lr=0.01)
#?in?your?training?loop:
optimizer.zero_grad()???#?zero?the?gradient?buffers
output?=?net(input)
loss?=?criterion(output,?target)
loss.backward()
optimizer.step()????#?Does?the?update注意
觀察如何使用
optimizer.zero_grad()手動將梯度緩沖區(qū)設置為零。這是因為梯度是反向傳播部分中的說明那樣是累積的。
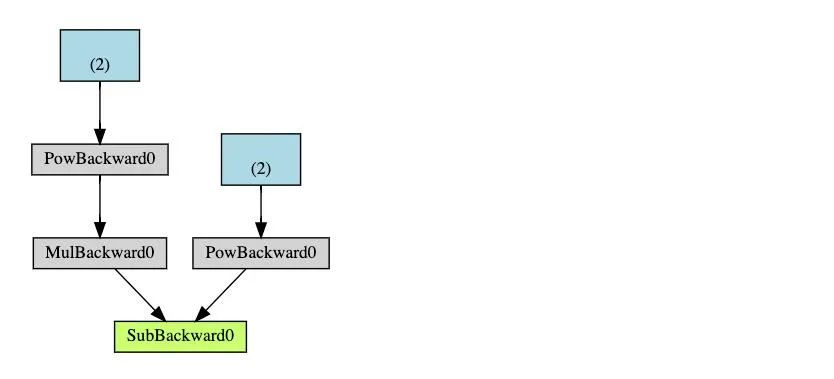
(四)訓練一個分類器
你已經(jīng)學會如何去定義一個神經(jīng)網(wǎng)絡,計算損失值和更新網(wǎng)絡的權重。
你現(xiàn)在可能在思考:數(shù)據(jù)哪里來呢?
關于數(shù)據(jù)
通常,當你處理圖像,文本,音頻和視頻數(shù)據(jù)時,你可以使用標準的Python包來加載數(shù)據(jù)到一個numpy數(shù)組中.然后把這個數(shù)組轉(zhuǎn)換成torch.*Tensor。
對于圖像,有諸如Pillow,OpenCV包等非常實用 對于音頻,有諸如scipy和librosa包 對于文本,可以用原始Python和Cython來加載,或者使用NLTK和SpaCy 對于視覺,我們創(chuàng)建了一個 torchvision包,包含常見數(shù)據(jù)集的數(shù)據(jù)加載,比如Imagenet,CIFAR10,MNIST等,和圖像轉(zhuǎn)換器,也就是torchvision.datasets和torch.utils.data.DataLoader。
這提供了巨大的便利,也避免了代碼的重復。
在這個教程中,我們使用CIFAR10數(shù)據(jù)集,它有如下10個類別:’airplane’,’automobile’,’bird’,’cat’,’deer’,’dog’,’frog’,’horse’,’ship’,’truck’。這個數(shù)據(jù)集中的圖像大小為3*32*32,即,3通道,32*32像素。

訓練一個圖像分類器
我們將按照下列順序進行:
使用 torchvision加載和歸一化CIFAR10訓練集和測試集.定義一個卷積神經(jīng)網(wǎng)絡 定義損失函數(shù) 在訓練集上訓練網(wǎng)絡 在測試集上測試網(wǎng)絡
1. 加載和歸一化CIFAR10
使用torchvision加載CIFAR10是非常容易的。
%matplotlib?inline
import?torch
import?torchvision
import?torchvision.transforms?as?transforms
torchvision的輸出是[0,1]的PILImage圖像,我們把它轉(zhuǎn)換為歸一化范圍為[-1, 1]的張量。
注意
如果在Windows上運行時出現(xiàn)BrokenPipeError,嘗試將torch.utils.data.DataLoader()的num_worker設置為0。
transform?=?transforms.Compose(
????[transforms.ToTensor(),
?????transforms.Normalize((0.5,?0.5,?0.5),?(0.5,?0.5,?0.5))])
trainset?=?torchvision.datasets.CIFAR10(root='./data',?train=True,
????????????????????????????????????????download=True,?transform=transform)
trainloader?=?torch.utils.data.DataLoader(trainset,?batch_size=4,
??????????????????????????????????????????shuffle=True,?num_workers=2)
testset?=?torchvision.datasets.CIFAR10(root='./data',?train=False,
???????????????????????????????????????download=True,?transform=transform)
testloader?=?torch.utils.data.DataLoader(testset,?batch_size=4,
?????????????????????????????????????????shuffle=False,?num_workers=2)
classes?=?('plane',?'car',?'bird',?'cat',
???????????'deer',?'dog',?'frog',?'horse',?'ship',?'truck')
#這個過程有點慢,會下載大約340mb圖片數(shù)據(jù)。
我們展示一些有趣的訓練圖像。
import?matplotlib.pyplot?as?plt
import?numpy?as?np
#?functions?to?show?an?image
def?imshow(img):
????img?=?img?/?2?+?0.5?????#?unnormalize
????npimg?=?img.numpy()
????plt.imshow(np.transpose(npimg,?(1,?2,?0)))
????plt.show()
#?get?some?random?training?images
dataiter?=?iter(trainloader)
images,?labels?=?dataiter.next()
#?show?images
imshow(torchvision.utils.make_grid(images))
#?print?labels
print('?'.join('%5s'?%?classes[labels[j]]?for?j?in?range(4)))
2. 定義一個卷積神經(jīng)網(wǎng)絡
從之前的神經(jīng)網(wǎng)絡一節(jié)復制神經(jīng)網(wǎng)絡代碼,并修改為接受3通道圖像取代之前的接受單通道圖像。
import?torch.nn?as?nn
import?torch.nn.functional?as?F
class?Net(nn.Module):
????def?__init__(self):
????????super(Net,?self).__init__()
????????self.conv1?=?nn.Conv2d(3,?6,?5)
????????self.pool?=?nn.MaxPool2d(2,?2)
????????self.conv2?=?nn.Conv2d(6,?16,?5)
????????self.fc1?=?nn.Linear(16?*?5?*?5,?120)
????????self.fc2?=?nn.Linear(120,?84)
????????self.fc3?=?nn.Linear(84,?10)
????def?forward(self,?x):
????????x?=?self.pool(F.relu(self.conv1(x)))
????????x?=?self.pool(F.relu(self.conv2(x)))
????????x?=?x.view(-1,?16?*?5?*?5)
????????x?=?F.relu(self.fc1(x))
????????x?=?F.relu(self.fc2(x))
????????x?=?self.fc3(x)
????????return?x
net?=?Net()
3. 定義損失函數(shù)和優(yōu)化器
我們使用交叉熵作為損失函數(shù),使用帶動量的隨機梯度下降。
import?torch.optim?as?optim
criterion?=?nn.CrossEntropyLoss()
optimizer?=?optim.SGD(net.parameters(),?lr=0.001,?momentum=0.9)
4. 訓練網(wǎng)絡
這是開始有趣的時刻,我們只需在數(shù)據(jù)迭代器上循環(huán),把數(shù)據(jù)輸入給網(wǎng)絡,并優(yōu)化。
for?epoch?in?range(2):??#?loop?over?the?dataset?multiple?times
????running_loss?=?0.0
????for?i,?data?in?enumerate(trainloader,?0):
????????#?get?the?inputs;?data?is?a?list?of?[inputs,?labels]
????????inputs,?labels?=?data
????????#?zero?the?parameter?gradients
????????optimizer.zero_grad()
????????#?forward?+?backward?+?optimize
????????outputs?=?net(inputs)
????????loss?=?criterion(outputs,?labels)
????????loss.backward()
????????optimizer.step()
????????#?print?statistics
????????running_loss?+=?loss.item()
????????if?i?%?2000?==?1999:????#?print?every?2000?mini-batches
????????????print('[%d,?%5d]?loss:?%.3f'?%
??????????????????(epoch?+?1,?i?+?1,?running_loss?/?2000))
????????????running_loss?=?0.0
print('Finished?Training')
保存一下我們的訓練模型
PATH?=?'./cifar_net.pth'
torch.save(net.state_dict(),?PATH)
點擊這里查看關于保存模型的詳細介紹
5. 在測試集上測試網(wǎng)絡
我們在整個訓練集上訓練了兩次網(wǎng)絡,但是我們還需要檢查網(wǎng)絡是否從數(shù)據(jù)集中學習到東西。
我們通過預測神經(jīng)網(wǎng)絡輸出的類別標簽并根據(jù)實際情況進行檢測,如果預測正確,我們把該樣本添加到正確預測列表。
第一步,顯示測試集中的圖片一遍熟悉圖片內(nèi)容。
dataiter?=?iter(testloader)
images,?labels?=?dataiter.next()
#?print?images
imshow(torchvision.utils.make_grid(images))
print('GroundTruth:?',?'?'.join('%5s'?%?classes[labels[j]]?for?j?in?range(4)))
接下來,讓我們重新加載我們保存的模型(注意:保存和重新加載模型在這里不是必要的,我們只是為了說明如何這樣做):
net?=?Net()
net.load_state_dict(torch.load(PATH))
現(xiàn)在我們來看看神經(jīng)網(wǎng)絡認為以上圖片是什么?
outputs?=?net(images)
輸出是10個標簽的概率。一個類別的概率越大,神經(jīng)網(wǎng)絡越認為他是這個類別。所以讓我們得到最高概率的標簽。
_,?predicted?=?torch.max(outputs,?1)
print('Predicted:?',?'?'.join('%5s'?%?classes[predicted[j]]
??????????????????????????????for?j?in?range(4)))
這結果看起來非常的好。
接下來讓我們看看網(wǎng)絡在整個測試集上的結果如何。
correct?=?0
total?=?0
with?torch.no_grad():
????for?data?in?testloader:
????????images,?labels?=?data
????????outputs?=?net(images)
????????_,?predicted?=?torch.max(outputs.data,?1)
????????total?+=?labels.size(0)
????????correct?+=?(predicted?==?labels).sum().item()
print('Accuracy?of?the?network?on?the?10000?test?images:?%d?%%'?%?(
????100?*?correct?/?total))
結果看起來好于偶然,偶然的正確率為10%,似乎網(wǎng)絡學習到了一些東西。
那在什么類上預測較好,什么類預測結果不好呢?
class_correct?=?list(0.?for?i?in?range(10))
class_total?=?list(0.?for?i?in?range(10))
with?torch.no_grad():
????for?data?in?testloader:
????????images,?labels?=?data
????????outputs?=?net(images)
????????_,?predicted?=?torch.max(outputs,?1)
????????c?=?(predicted?==?labels).squeeze()
????????for?i?in?range(4):
????????????label?=?labels[i]
????????????class_correct[label]?+=?c[i].item()
????????????class_total[label]?+=?1
for?i?in?range(10):
????print('Accuracy?of?%5s?:?%2d?%%'?%?(
????????classes[i],?100?*?class_correct[i]?/?class_total[i]))
接下來干什么?
我們?nèi)绾卧贕PU上運行神經(jīng)網(wǎng)絡呢?
在GPU上訓練
你是如何把一個Tensor轉(zhuǎn)換GPU上,你就如何把一個神經(jīng)網(wǎng)絡移動到GPU上訓練。這個操作會遞歸遍歷有所模塊,并將其參數(shù)和緩沖區(qū)轉(zhuǎn)換為CUDA張量。
device?=?torch.device("cuda:0"?if?torch.cuda.is_available()?else?"cpu")
#?Assume?that?we?are?on?a?CUDA?machine,?then?this?should?print?a?CUDA?device:
#假設我們有一臺CUDA的機器,這個操作將顯示CUDA設備。
print(device)
接下來假設我們有一臺CUDA的機器,然后這些方法將遞歸遍歷所有模塊并將其參數(shù)和緩沖區(qū)轉(zhuǎn)換為CUDA張量:
net.to(device)
請記住,你也必須在每一步中把你的輸入和目標值轉(zhuǎn)換到GPU上:
inputs,?labels?=?inputs.to(device),?labels.to(device)
為什么我們沒注意到GPU的速度提升很多?那是因為網(wǎng)絡非常的小。
實踐:
嘗試增加你的網(wǎng)絡的寬度(第一個nn.Conv2d的第2個參數(shù), 第二個nn.Conv2d的第一個參數(shù),他們需要是相同的數(shù)字),看看你得到了什么樣的加速。
實現(xiàn)的目標:
深入了解了PyTorch的張量庫和神經(jīng)網(wǎng)絡 訓練了一個小網(wǎng)絡來分類圖片
在多GPU上訓練
如果你希望使用所有GPU來更大的加快速度,請查看選讀:[數(shù)據(jù)并行]:(https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html)
接下來做什么?
訓練神經(jīng)網(wǎng)絡玩電子游戲 在ImageNet上訓練最好的ResNet 使用對抗生成網(wǎng)絡來訓練一個人臉生成器 使用LSTM網(wǎng)絡訓練一個字符級的語言模型 更多示例 更多教程 在論壇上討論PyTorch 在Slack上與其他用戶聊天
往期精彩回顧
本站qq群704220115,加入微信群請掃碼: