
【深度學(xué)習(xí)】翻譯:60分鐘入門(mén)PyTorch(二)——Autograd自動(dòng)求導(dǎo)
前言
原文翻譯自:Deep Learning with PyTorch: A 60 Minute Blitz
翻譯:林不清(https://www.zhihu.com/people/lu-guo-92-42-88)
目錄
60分鐘入門(mén)PyTorch(一)——Tensors
60分鐘入門(mén)PyTorch(二)——Autograd自動(dòng)求導(dǎo)
60分鐘入門(mén)Pytorch(三)——神經(jīng)網(wǎng)絡(luò)
60分鐘入門(mén)PyTorch(四)——訓(xùn)練一個(gè)分類(lèi)器
Autograd:自動(dòng)求導(dǎo)torch.autograd是pytorch自動(dòng)求導(dǎo)的工具,也是所有神經(jīng)網(wǎng)絡(luò)的核心。我們首先先簡(jiǎn)單了解一下這個(gè)包如何訓(xùn)練神經(jīng)網(wǎng)絡(luò)。
背景介紹
神經(jīng)網(wǎng)絡(luò)(NNs)是作用在輸入數(shù)據(jù)上的一系列嵌套函數(shù)的集合,這些函數(shù)由權(quán)重和誤差來(lái)定義,被存儲(chǔ)在PyTorch中的tensors中。
神經(jīng)網(wǎng)絡(luò)訓(xùn)練的兩個(gè)步驟:
前向傳播:在前向傳播中,神經(jīng)網(wǎng)絡(luò)通過(guò)將接收到的數(shù)據(jù)與每一層對(duì)應(yīng)的權(quán)重和誤差進(jìn)行運(yùn)算來(lái)對(duì)正確的輸出做出最好的預(yù)測(cè)。
反向傳播:在反向傳播中,神經(jīng)網(wǎng)絡(luò)調(diào)整其參數(shù)使得其與輸出誤差成比例。反向傳播基于梯度下降策略,是鏈?zhǔn)角髮?dǎo)法則的一個(gè)應(yīng)用,以目標(biāo)的負(fù)梯度方向?qū)?shù)進(jìn)行調(diào)整。
更加詳細(xì)的介紹可以參照下述地址:
[3Blue1Brown]:
https://www.youtube.com/watch?v=tIeHLnjs5U8
Pytorch應(yīng)用
來(lái)看一個(gè)簡(jiǎn)單的示例,我們從torchvision加載一個(gè)預(yù)先訓(xùn)練好的resnet18模型,接著創(chuàng)建一個(gè)隨機(jī)數(shù)據(jù)tensor來(lái)表示一有3個(gè)通道、高度和寬度為64的圖像,其對(duì)應(yīng)的標(biāo)簽初始化為一些隨機(jī)值。
%matplotlib?inline
import?torch,?torchvision
model?=?torchvision.models.resnet18(pretrained=True)
data?=?torch.rand(1,?3,?64,?64)
labels?=?torch.rand(1,?1000)
接下來(lái),我們將輸入數(shù)據(jù)向輸出方向傳播到模型的每一層中來(lái)預(yù)測(cè)輸出,這就是前向傳播。
prediction?=?model(data)?#?前向傳播
我們利用模型的預(yù)測(cè)輸出和對(duì)應(yīng)的權(quán)重來(lái)計(jì)算誤差,然后反向傳播誤差。完成計(jì)算后,您可以調(diào)用.backward()并自動(dòng)計(jì)算所有梯度。此張量的梯度將累積到.grad屬性中。
loss?=?(prediction?-?labels).sum()
loss.backward()?#?反向傳播
接著,我們加載一個(gè)優(yōu)化器,在本例中,SGD的學(xué)習(xí)率為0.01,momentum 為0.9。我們?cè)趦?yōu)化器中注冊(cè)模型的所有參數(shù)。
optim?=?torch.optim.SGD(model.parameters(),?lr=1e-2,?momentum=0.9)
最后,我們調(diào)用.step()來(lái)執(zhí)行梯度下降,優(yōu)化器通過(guò)存儲(chǔ)在.grad中的梯度來(lái)調(diào)整每個(gè)參數(shù)。
optim.step()?#梯度下降
現(xiàn)在,你已經(jīng)具備了訓(xùn)練神經(jīng)網(wǎng)絡(luò)所需所有條件。下面幾節(jié)詳細(xì)介紹了Autograd包的工作原理——可以跳過(guò)它們。
Autograd中的求導(dǎo)
先來(lái)看一下autograd是如何收集梯度的。我們創(chuàng)建兩個(gè)張量a和b并設(shè)置requires_grad = True以跟蹤它的計(jì)算。
import?torch
a?=?torch.tensor([2.,?3.],?requires_grad=True)
b?=?torch.tensor([6.,?4.],?requires_grad=True)
接著在a和b的基礎(chǔ)上創(chuàng)建張量Q
Q?=?3*a**3?-?b**2
假設(shè)a和b是一個(gè)神經(jīng)網(wǎng)絡(luò)的權(quán)重,Q是它的誤差,在神經(jīng)網(wǎng)絡(luò)訓(xùn)練中,我們需要w.r.t參數(shù)的誤差梯度,即
當(dāng)我們調(diào)用Q的.backward()時(shí),autograd計(jì)算這些梯度并把它們存儲(chǔ)在張量的 .grad屬性中。我們需要在Q.backward()中顯式傳遞gradient,gradient是一個(gè)與Q相同形狀的張量,它表示Q w.r.t本身的梯度,即
Q聚合為一個(gè)標(biāo)量并隱式向后調(diào)用,如Q.sum().backward()。external_grad?=?torch.tensor([1.,?1.])
Q.backward(gradient=external_grad)
現(xiàn)在梯度都被存放在a.grad和b.grad中
#?檢查一下存儲(chǔ)的梯度是否正確
print(9*a**2?==?a.grad)
print(-2*b?==?b.grad)
可選閱讀----用autograd進(jìn)行向量計(jì)算
在數(shù)學(xué)上,如果你有一個(gè)向量值函數(shù)??? =??(??? ) ,則??? 相對(duì)于??? 的梯度是雅可比矩陣:
一般來(lái)說(shuō),torch.autograd是一個(gè)計(jì)算雅可比向量積的引擎。也就是說(shuō),給定任何向量??=(??1??2...????)??,計(jì)算乘積?????。如果??恰好是標(biāo)量函數(shù)的梯度??=??(??? ),即 然后根據(jù)鏈?zhǔn)椒▌t,雅可比向量乘積將是??相對(duì)于??? 的梯度
雅可比向量積的這種特性使得將外部梯度饋送到具有非標(biāo)量輸出的模型中非常方便。external_grad 代表.
圖計(jì)算
從概念上講,autograd在由函數(shù)對(duì)象組成的有向無(wú)環(huán)圖(DAG)中保存數(shù)據(jù)(tensor)和所有執(zhí)行的操作(以及產(chǎn)生的新tensor)的記錄,在這個(gè)DAG中,葉節(jié)點(diǎn)是輸入數(shù)據(jù),根節(jié)點(diǎn)是輸出數(shù)據(jù),通過(guò)從根節(jié)點(diǎn)到葉節(jié)點(diǎn)跟蹤這個(gè)圖,您可以使用鏈?zhǔn)椒▌t自動(dòng)計(jì)算梯度。
在前向傳播中,autograd同時(shí)完成兩件事情:
- 運(yùn)行所請(qǐng)求的操作來(lái)計(jì)算結(jié)果tensor
- 保持DAG中操作的梯度
在反向傳播中,當(dāng)在DAG根節(jié)點(diǎn)上調(diào)用.backward()時(shí),反向傳播啟動(dòng),autograd接下來(lái)完成:
- 計(jì)算每一個(gè)
.grad_fn的梯度 - 將它們累加到各自張量的.grad屬性中
- 利用鏈?zhǔn)椒▌t,一直傳播到葉節(jié)點(diǎn)
下面是DAG的可視化表示的示例。圖中,箭頭表示前向傳播的方向,節(jié)點(diǎn)表示向前傳遞中每個(gè)操作的向后函數(shù)。藍(lán)色標(biāo)記的葉節(jié)點(diǎn)代表葉張量 a和b
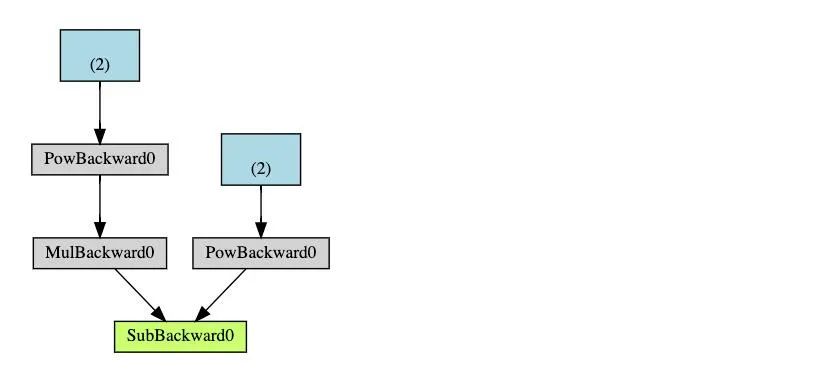
注意
DAG在PyTorch中是動(dòng)態(tài)的。值得注意的是圖是重新開(kāi)始創(chuàng)建的; 在調(diào)用每一個(gè)``.backward()``后,autograd開(kāi)始填充一個(gè)新圖,這就是能夠在模型中使用控制流語(yǔ)句的原因。你可以根據(jù)需求在每次迭代時(shí)更改形狀、大小和操作。
torch.autograd追蹤所有requires_grad為True的張量的相關(guān)操作。對(duì)于不需要梯度的張量,將此屬性設(shè)置為False將其從梯度計(jì)算DAG中排除。操作的輸出張量將需要梯度,即使只有一個(gè)輸入張量requires_grad=True。
x?=?torch.rand(5,?5)
y?=?torch.rand(5,?5)
z?=?torch.rand((5,?5),?requires_grad=True)
a?=?x?+?y
print(f"Does?`a`?require?gradients??:?{a.requires_grad}")
b?=?x?+?z
print(f"Does?`b`?require?gradients?:?{b.requires_grad}")
在神經(jīng)網(wǎng)絡(luò)中,不計(jì)算梯度的參數(shù)通常稱(chēng)為凍結(jié)參數(shù)。如果您事先知道您不需要這些參數(shù)的梯度,那么“凍結(jié)”部分模型是很有用的(這通過(guò)減少autograd計(jì)算帶來(lái)一些性能好處)。另外一個(gè)常見(jiàn)的用法是微調(diào)一個(gè)預(yù)訓(xùn)練好的網(wǎng)絡(luò),在微調(diào)的過(guò)程中,我們凍結(jié)大部分模型——通常,只修改分類(lèi)器來(lái)對(duì)新的<標(biāo)簽>做出預(yù)測(cè),讓我們通過(guò)一個(gè)小示例來(lái)演示這一點(diǎn)。與前面一樣,我們加載一個(gè)預(yù)先訓(xùn)練好的resnet18模型,并凍結(jié)所有參數(shù)。
from?torch?import?nn,?optim
model?=?torchvision.models.resnet18(pretrained=True)
#?凍結(jié)網(wǎng)絡(luò)中所有的參數(shù)
for?param?in?model.parameters():
????param.requires_grad?=?False
假設(shè)我們想在一個(gè)有10個(gè)標(biāo)簽的新數(shù)據(jù)集上微調(diào)模型。在resnet中,分類(lèi)器是最后一個(gè)線性層模型model.fc。我們可以簡(jiǎn)單地用一個(gè)新的線性層(默認(rèn)未凍結(jié))代替它作為我們的分類(lèi)器。
model.fc?=?nn.Linear(512,?10)
現(xiàn)在除了model.fc的參數(shù)外,模型的其他參數(shù)均被凍結(jié),參與計(jì)算的參數(shù)是model.fc的權(quán)值和偏置。
#?只優(yōu)化分類(lèi)器
optimizer?=?optim.SGD(model.fc.parameters(),?lr=1e-2,?momentum=0.9)
注意,盡管我們注冊(cè)了優(yōu)化器中所有參數(shù),但唯一參與梯度計(jì)算(并因此在梯度下降中更新)的參數(shù)是分類(lèi)器的權(quán)值和偏差。torch.no_grad()中也具有相同的功能。
拓展閱讀
- [就地修改操作以及多線程Autograd]:(https://pytorch.org/docs/stable/notes/autograd.html)
- [反向模式autodiff的示例]:(https://colab.research.google.com/drive/1VpeE6UvEPRz9HmsHh1KS0XxXjYu533EC)
往期精彩回顧
本站知識(shí)星球“黃博的機(jī)器學(xué)習(xí)圈子”(92416895)
本站qq群704220115。
加入微信群請(qǐng)掃碼: