
工具介紹:使用 Optuna 進行超參數(shù)調(diào)優(yōu)

在機器學習中,除了一般可學習的參數(shù)外,還有一些參數(shù)需要預先設置,稱為超參數(shù)。
超參數(shù)的值對于模型的性能至關重要,尋找在驗證集上性能最佳的超參數(shù)稱為超參數(shù)優(yōu)化,然而這并不是一項簡單的任務。
可以通過搜索方法來選擇比較好的超參數(shù)。比如,Grid Search?和?Random Search?之類的方法。后者貌似帶有一定隨機性,但往往表現(xiàn)得比前者好。因為它以不均勻的間隔搜索超參數(shù)空間,避免了?Grid Search?的很多冗余操作。
除了這種搜索方式,我們還可以使用像 Optuna 這樣的更加靈活強大的工具來應對這項任務。先安裝它,
pip?install?optuna
1流程及簡例
一個典型的 Optuna 的優(yōu)化程序中只有三個最核心的概念,
objective,負責定義待優(yōu)化的目標函數(shù)并指定參數(shù)的范圍。trial,對應目標函數(shù)objective的單次試驗。study,負責管理整個優(yōu)化過程,決定優(yōu)化的方式、總試驗的次數(shù)、試驗結(jié)果的記錄等功能。
.簡例 .
例如,在定義域
我們就用這個例子來練練手,代碼如下。
import?optuna
?
def?objective(trial):
????x?=?trial.suggest_uniform('x',?0,?1)
????y?=?trial.suggest_uniform('y',?0,?1)
????return?(x?+?y)?**?2
?
study?=?optuna.create_study(direction='minimize')
study.optimize(objective,?n_trials=100)
?
print(study.best_params)
print(study.best_value)
{'x': 0.00136012038661543, 'y': 0.0003168904600867363}
2.8123653799567168e-06
首先,定義一個
objective函數(shù),即,其參數(shù) 和 采樣自兩個均勻分布。 然后,
Optuna創(chuàng)建了一個study,指定了優(yōu)化的方式為最小化并且最大實驗次數(shù)為100,然后將目標函數(shù)傳入其中,開始優(yōu)化過程。最后,輸出在
100次試驗中找到的最佳參數(shù)組合。
注意,上面例子是拿來演示它的使用流程,并不是拿它去解一般的最優(yōu)化問題。
.可視化 .
等 study 結(jié)束,下一步就是查看結(jié)果,可以使用 Optuna 的內(nèi)置可視化函數(shù)來查看 study 的各項進度。
下面用 plotly 來作多個方式的可視化。如果沒有安裝過,則安裝它 pip install plotly。
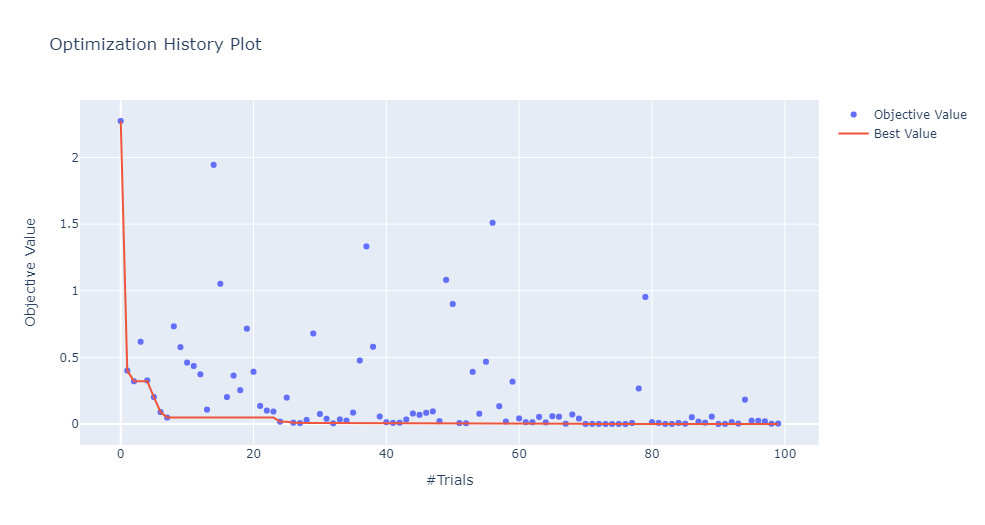
下圖顯示了模型在多次迭代中的性能演化。預期的行為是模型性能隨著搜索次數(shù)的增加而提高。
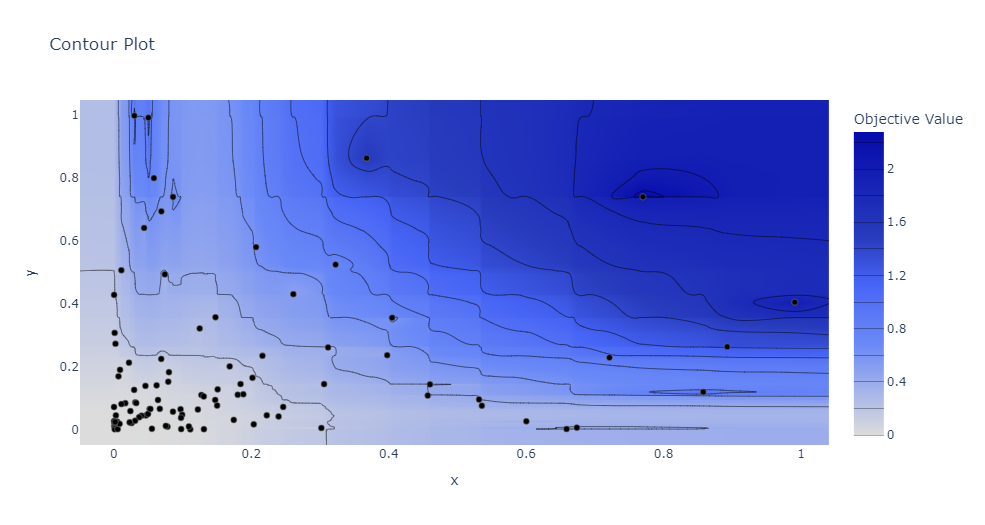
在 study.optimize 執(zhí)行結(jié)束以后,調(diào)用 plot_contour,并將 study 和需要可視化的參數(shù)傳入該方法,Optuna 將返回一張等高線圖。
例如,當在上面的例子中,我們想要查看參數(shù)
optuna.visualization.plot_contour(study,?params=['x',?'y'])
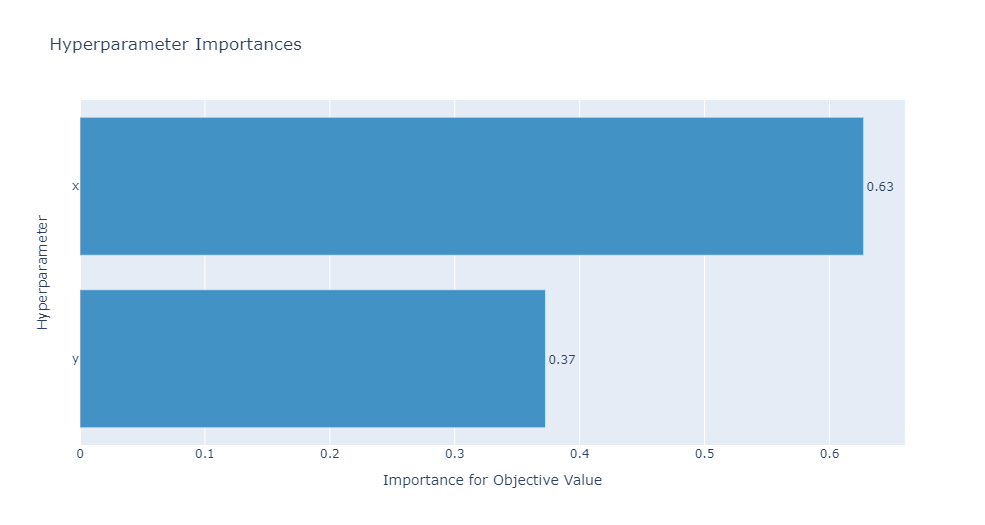
還有其他形式的一些圖,如通過展示超參數(shù)重要性可以了解到哪些超參數(shù)對模型的性能影響較大。
optuna.visualization.plot_param_importances(study)
2CNN 超參數(shù)優(yōu)化例子
本文接下來結(jié)合 PyTorch 和 Optuna,來實驗 CNN 模型在 MNIST 數(shù)據(jù)集上的超參數(shù)優(yōu)化。
import?matplotlib.pyplot?as?plt
import?numpy?as?np
import?torch
import?torch.nn?as?nn
import?torch.optim?as?optim
from?torch.utils.data?import?Dataset,?DataLoader,TensorDataset,random_split,SubsetRandomSampler,?ConcatDataset
from?torch.nn?import?functional?as?F
import?torchvision
from?torchvision?import?datasets,transforms
import?torchvision.transforms?as?transforms
import?optuna
import?os
DEVICE?=?torch.device("cuda:0"?if?torch.cuda.is_available()?else?"cpu")
CLASSES?=?10
DIR?=?os.getcwd()
EPOCHS?=?10
LOG_INTERVAL?=?10
train_dataset?=?torchvision.datasets.MNIST('classifier_data',?train=True,?download=True)
m=len(train_dataset)
transform?=?torchvision.transforms.Compose([
????torchvision.transforms.ToTensor()
])
train_dataset.transform=transform
定義具體的卷積神經(jīng)網(wǎng)絡,并增加參數(shù) trial 來設置要采樣的超參數(shù)。
class?ConvNet(nn.Module):
????def?__init__(self,?trial):
????????#?We?optimize?dropout?rate?in?a?convolutional?neural?network.
????????super(ConvNet,?self).__init__()
????????self.conv1?=?nn.Conv2d(in_channels=1,?out_channels=16,?kernel_size=5,?stride=1,?padding=2)
????????self.conv2?=?nn.Conv2d(in_channels=16,?out_channels=32,?kernel_size=5,?stride=1,?padding=2)
????????dropout_rate?=?trial.suggest_float("dropout_rate",?0,?0.5,step=0.1)
????????self.drop1=nn.Dropout2d(p=dropout_rate)???
????????
????????fc2_input_dim?=?trial.suggest_int("fc2_input_dim",?32,?128,32)
????????self.fc1?=?nn.Linear(32??7??7,?fc2_input_dim)
????????dropout_rate2?=?trial.suggest_float("dropout_rate2",?0,?0.3,step=0.1)
????????self.drop2=nn.Dropout2d(p=dropout_rate2)
????????self.fc2?=?nn.Linear(fc2_input_dim,?10)
????def?forward(self,?x):
????????x?=?F.relu(F.max_pool2d(self.conv1(x),kernel_size?=?2))
????????x?=?F.relu(F.max_pool2d(self.conv2(x),kernel_size?=?2))
????????x?=?self.drop1(x)
????????x?=?x.view(x.size(0),-1)
????????x?=?F.relu(self.fc1(x))
????????x?=?self.drop2(x)
????????x?=?self.fc2(x)
????????return?x
定義函數(shù)來獲取訓練集中不同 batch_size 大小的批次數(shù)據(jù)。它將 train_dataset 和 batch_size 作為輸入,并返回訓練和驗證數(shù)據(jù)加載器對象。
def?get_mnist(train_dataset,batch_size):
????train_data,?val_data?=?random_split(train_dataset,?[int(m-m0.2),?int(m0.2)])
????#?The?dataloaders?handle?shuffling,?batching,?etc...
????train_loader?=?torch.utils.data.DataLoader(train_data,?batch_size=batch_size)
????valid_loader?=?torch.utils.data.DataLoader(val_data,?batch_size=batch_size)
????return?train_loader,?valid_loader
接下來是定義目標函數(shù),它通過采樣程序來選擇每次試驗的超參數(shù)值,并返回在該試驗中驗證集上的準確度。
def?objective(trial):
????#?Generate?the?model.
????model?=?ConvNet(trial).to(DEVICE)
????#?Generate?the?optimizers.
????#?try?RMSprop?and?SGD
????'''
????optimizer_name?=?trial.suggest_categorical("optimizer",?["RMSprop",?"SGD"])
????momentum?=?trial.suggest_float("momentum",?0.0,?1.0)
????lr?=?trial.suggest_float("lr",?1e-5,?1e-1,?log=True)
????optimizer?=?getattr(optim,?optimizer_name)(model.parameters(),?lr=lr,momentum=momentum)
????'''
????#try?Adam,?AdaDelta?adn?Adagrad
????
????optimizer_name?=?trial.suggest_categorical("optimizer",?["Adam",?"Adadelta","Adagrad"])
????lr?=?trial.suggest_float("lr",?1e-5,?1e-1,log=True)
????optimizer?=?getattr(optim,?optimizer_name)(model.parameters(),?lr=lr)
????batch_size=trial.suggest_int("batch_size",?64,?256,step=64)
????criterion=nn.CrossEntropyLoss()
????#?Get?the?MNIST?imagesset.
????train_loader,?valid_loader?=?get_mnist(train_dataset,batch_size)
????
????#?Training?of?the?model.
????for?epoch?in?range(EPOCHS):
????????model.train()
???????
????????for?batch_idx,?(images,?labels)?in?enumerate(train_loader):
????????????#?Limiting?training?images?for?faster?epochs.
????????????#if?batch_idx?*?BATCHSIZE?>=?N_TRAIN_EXAMPLES:
????????????#????break
????????????images,?labels?=?images.to(DEVICE),?labels.to(DEVICE)
????????????optimizer.zero_grad()
????????????output?=?model(images)
????????????loss?=?criterion(output,?labels)
????????????loss.backward()
????????????optimizer.step()
????????#?Validation?of?the?model.
????????model.eval()
????????correct?=?0
????????with?torch.no_grad():
????????????for?batch_idx,?(images,?labels)?in?enumerate(valid_loader):
????????????????#?Limiting?validation?images.
???????????????#?if?batch_idx?*?BATCHSIZE?>=?N_VALID_EXAMPLES:
????????????????#????break
????????????????images,?labels?=?images.to(DEVICE),?labels.to(DEVICE)
????????????????output?=?model(images)
????????????????#?Get?the?index?of?the?max?log-probability.
????????????????pred?=?output.argmax(dim=1,?keepdim=True)
????????????????correct?+=?pred.eq(labels.view_as(pred)).sum().item()
????????accuracy?=?correct?/?len(valid_loader.dataset)
????????trial.report(accuracy,?epoch)
????????#?Handle?pruning?based?on?the?intermediate?value.
????????if?trial.should_prune():
????????????raise?optuna.exceptions.TrialPruned()
????return?accuracy
接著,創(chuàng)建一個 study 對象來最大化目標函數(shù),然后使用 optimize 來展開試驗,實驗次數(shù)設為 20 次。
study?=?optuna.create_study(direction='maximize')
study.optimize(objective,?n_trials=20)
trial?=?study.best_trial
print('Accuracy:?{}'.format(trial.value))
print("Best?hyperparameters:?{}".format(trial.params))
Accuracy: 0.98925
Best hyperparameters: {'dropout_rate': 0.0, 'fc2_input_dim': 64, 'dropout_rate2': 0.1, 'optimizer': 'Adam', 'lr': 0.006891576863485639, 'batch_size': 256}
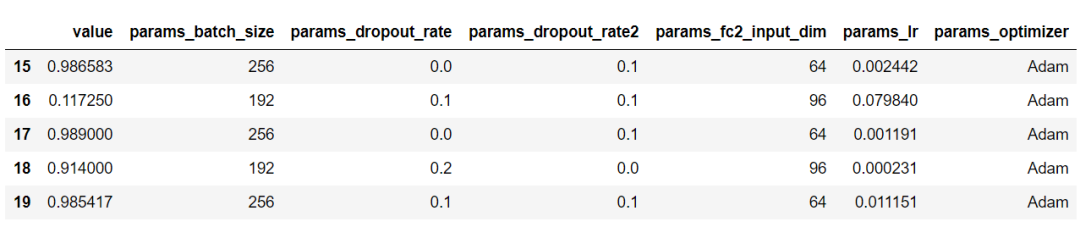
df?=?study.trials_dataframe().drop(['state','datetime_start','datetime_complete','duration','number'],?axis=1)
df.tail(5)
3可視化 study
先通過下面代碼看一下各超參數(shù)的總體優(yōu)化進展情況。
optuna.visualization.plot_optimization_history(study)
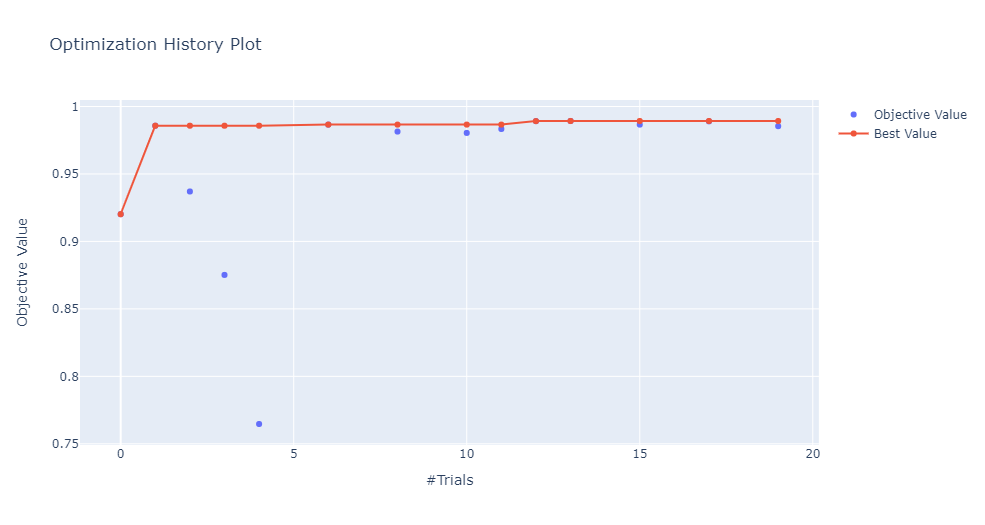
以及還可以查看不同超參數(shù)組合的等值線圖,下圖中只關注批次大小和學習率。
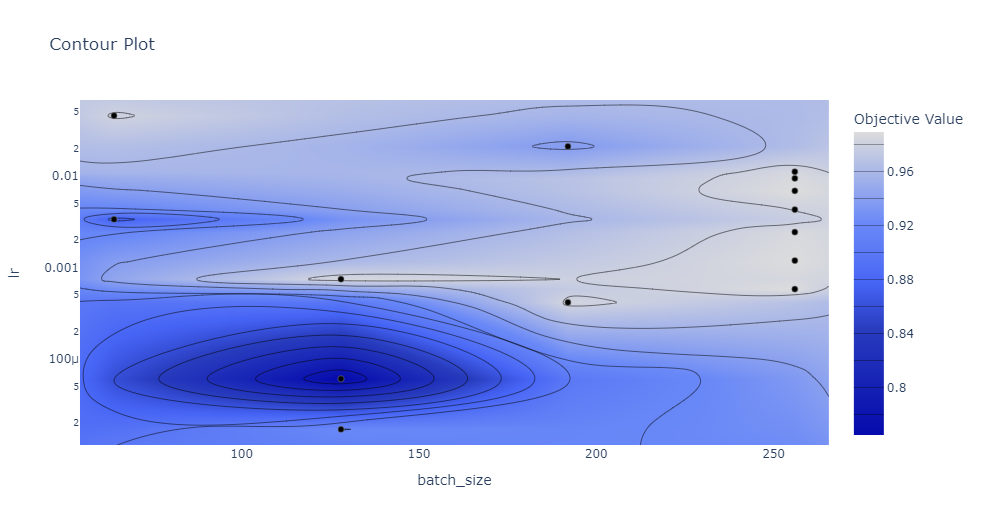
.超參數(shù)重要性 .
查看各個超參數(shù)對目標值的影響大小。
optuna.visualization.plot_param_importances(study)
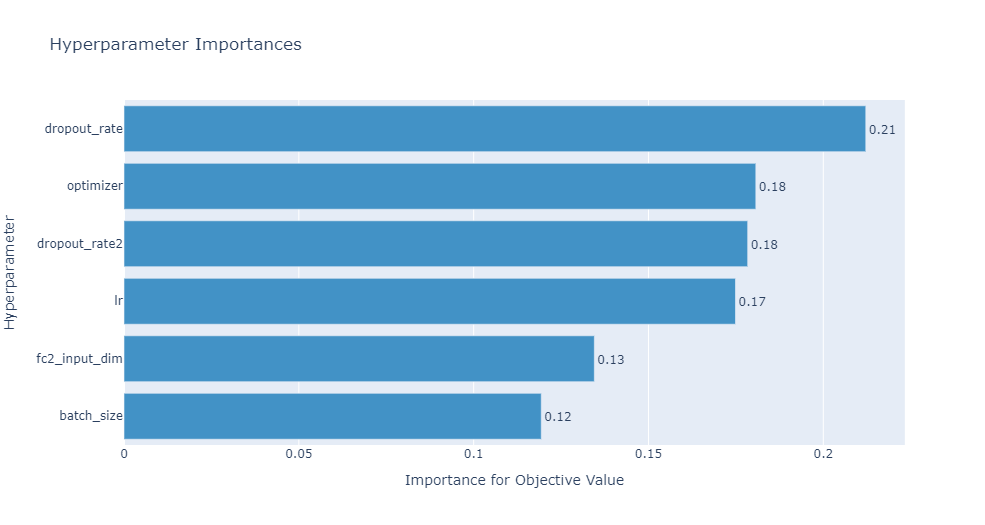
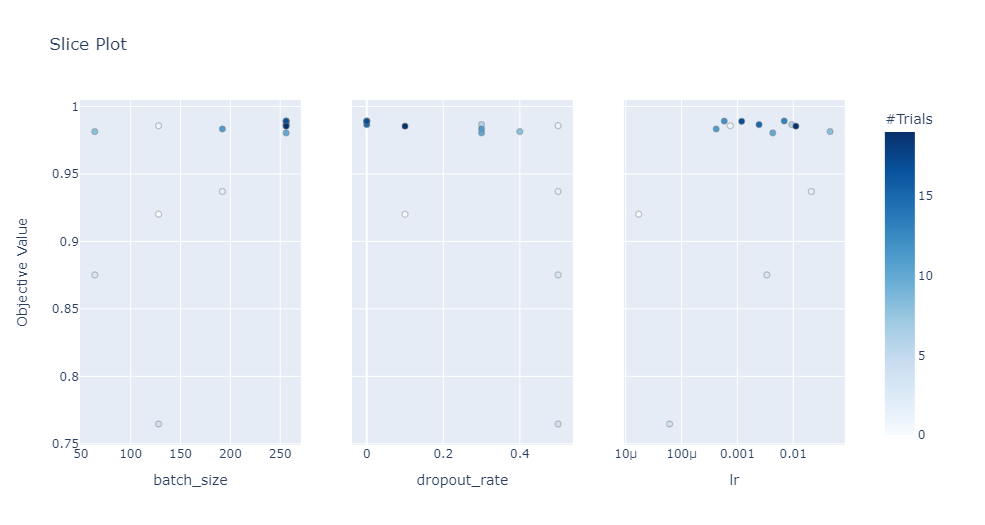
.單個超參數(shù)切片 .
查看不同的單個超參數(shù)在多次試驗中的變化情況,顏色對應試驗次數(shù)。
optuna.visualization.plot_slice(study,?params=['dropout_rate',?'batch_size',?'lr'])
4小結(jié)
參考資料
