
神經(jīng)符號(hào)學(xué)習(xí): 神經(jīng)網(wǎng)絡(luò)+邏輯推理
-
提出具有理論收斂保證的DeepLogic框架,該框架進(jìn)行神經(jīng)感知和邏輯推理的聯(lián)合學(xué)習(xí),使它們可以相互增強(qiáng),以提高神經(jīng)符號(hào)推理的性能和可解釋性。
-
提出源自一階邏輯的深度邏輯模塊(DLM),能夠從基本邏輯運(yùn)算符構(gòu)造和學(xué)習(xí)邏輯公式。
- 提出了深度邏輯優(yōu)化(DLO)算法,通過理論上量化神經(jīng)感知和邏輯推理之間的相互監(jiān)督信號(hào)來保證神經(jīng)感知和邏輯推理的聯(lián)合學(xué)習(xí)。
2 DeepLogic框架 神經(jīng)符號(hào)學(xué)習(xí)研究同時(shí)感知和推理的問題,其輸入是語義數(shù)據(jù),輸出是未知的復(fù)雜關(guān)系。為避免任務(wù)分解,不應(yīng)給出要學(xué)習(xí)的語義輸入的符號(hào)屬性。DeepLogic框架從數(shù)學(xué)角度描述了問題表述和建模,并提出了用于聯(lián)合學(xué)習(xí)神經(jīng)感知和符號(hào)推理的深度&邏輯優(yōu)化(DLO)算法。 通過我們提出的DeepLogic框架,我們可以通過1位監(jiān)督信號(hào)來共同學(xué)習(xí)感知能力和邏輯公式,指示語義輸入是否滿足給定的公式,如圖1所示。 前向傳遞(頂部)從語義輸入x通過中間符號(hào)屬性z到最終演繹標(biāo)簽y進(jìn)行順序處理。 例如,推理一下1,2和3的關(guān)系。首先,系統(tǒng)通過神經(jīng)感知模型將這些圖像識(shí)別為符號(hào):?、?和?。然后,邏輯推理模型對?、?、?之間的關(guān)系進(jìn)行推理,得出滿足邏輯公式:“?加?等于?”的結(jié)論。在后向傳遞中(左下/右下),感知模型θ和符號(hào)系統(tǒng)φ的參數(shù)分別以另一個(gè)作為監(jiān)督進(jìn)行迭代優(yōu)化。
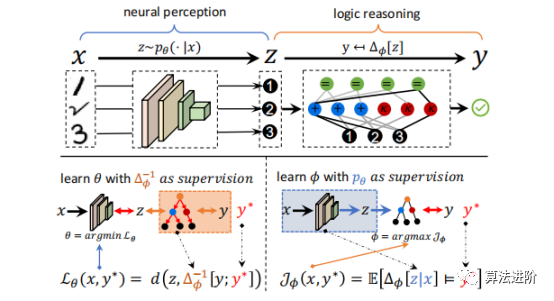 圖1 DeepLogic框架 3 深度邏輯模塊(DLM)
深度邏輯模塊(DLM),能夠?qū)ι窠?jīng)感知和邏輯推理進(jìn)行建模。特別是,擬議的DLM具有以下優(yōu)點(diǎn):
圖1 DeepLogic框架 3 深度邏輯模塊(DLM)
深度邏輯模塊(DLM),能夠?qū)ι窠?jīng)感知和邏輯推理進(jìn)行建模。特別是,擬議的DLM具有以下優(yōu)點(diǎn):
-
DLM不依賴外部知識(shí),易于實(shí)現(xiàn);
-
DLM通過由淺入深的邏輯層堆疊,自適應(yīng)適應(yīng)各種場景;
- DLM能夠利用監(jiān)督信息來優(yōu)化pθ和pφ,保證神經(jīng)感知和邏輯推理的聯(lián)合學(xué)習(xí)。
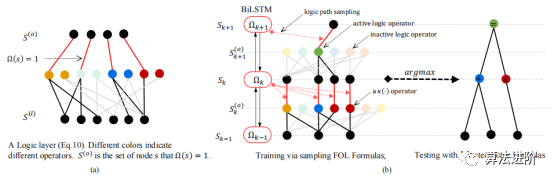
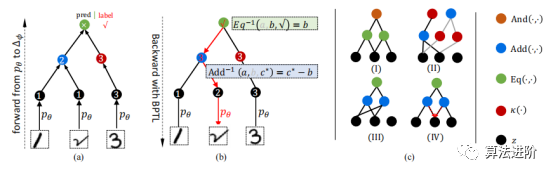 圖 3(a)DeepLogic 從 pθ 到 Δφ 的前向傳播。(b)DeepLogic 使用 BPTL 算法的反向傳播(算法1)。(c)Deeplogic 公式的幾種情況說明:(I)“And(Eq(Z1,Z2),Eq(Z2, Z3))”的公式;(II)兩層定義同一個(gè)術(shù)語“Add(Z1,Z2)”的情況(黑線和灰線);(III)和(IV)公式的病態(tài)/自沖突情況;(III)中,方程始終為“True”,而在(IV)中,BPTL算法會(huì)在中間節(jié)點(diǎn)遇到自沖突。 5 實(shí)驗(yàn)
在本節(jié)中,我們在三個(gè)邏輯推理數(shù)據(jù)集上評(píng)估所提出的DeepLogic框架的性能、收斂性、穩(wěn)定性和泛化能力。第一個(gè)和第二個(gè)數(shù)據(jù)集是根據(jù)具有多個(gè)屬性和不同規(guī)則的MNIST手動(dòng)構(gòu)建的,而第三個(gè)數(shù)據(jù)集是廣泛使用的推理數(shù)據(jù)集,旨在評(píng)估機(jī)器的推理能力。 5.1 MNIST-ADD MNIST-ADD是一個(gè)簡單的個(gè)位數(shù)加法數(shù)據(jù)集。任務(wù)是在給定三個(gè)MNIST圖像和1位“True/False”標(biāo)簽的情況下學(xué)習(xí)“個(gè)位數(shù)加法”公式。該數(shù)據(jù)集包括20,000個(gè)用于訓(xùn)練的實(shí)例和20,000個(gè)用于測試的實(shí)例。我們使用不同的分割策略將數(shù)據(jù)集進(jìn)一步分割為α和β分割。在β分割中,測試集具有與訓(xùn)練集中的實(shí)例不同的附加實(shí)例。這種設(shè)置也稱為“訓(xùn)練/測試分布偏移”,這對于神經(jīng)網(wǎng)絡(luò)來說很難解決。 結(jié)果總結(jié)如表1。 在MNSIT-ADd-α和MNIST-ADD-β數(shù)據(jù)集上,DNN模型過度擬合訓(xùn)練集。盡管嘗試使用改變模型大小和dropout等方法,但效果不佳。DNN模型在邏輯準(zhǔn)確性方面表現(xiàn)較差,尤其是在處理不平衡的β分裂時(shí)。與ABL模型相比,我們的模型更加靈活,無需Prolog程序即可達(dá)到更高的精度。最后,通過邏輯的反向傳播有助于為感知模型提供監(jiān)督。
圖 3(a)DeepLogic 從 pθ 到 Δφ 的前向傳播。(b)DeepLogic 使用 BPTL 算法的反向傳播(算法1)。(c)Deeplogic 公式的幾種情況說明:(I)“And(Eq(Z1,Z2),Eq(Z2, Z3))”的公式;(II)兩層定義同一個(gè)術(shù)語“Add(Z1,Z2)”的情況(黑線和灰線);(III)和(IV)公式的病態(tài)/自沖突情況;(III)中,方程始終為“True”,而在(IV)中,BPTL算法會(huì)在中間節(jié)點(diǎn)遇到自沖突。 5 實(shí)驗(yàn)
在本節(jié)中,我們在三個(gè)邏輯推理數(shù)據(jù)集上評(píng)估所提出的DeepLogic框架的性能、收斂性、穩(wěn)定性和泛化能力。第一個(gè)和第二個(gè)數(shù)據(jù)集是根據(jù)具有多個(gè)屬性和不同規(guī)則的MNIST手動(dòng)構(gòu)建的,而第三個(gè)數(shù)據(jù)集是廣泛使用的推理數(shù)據(jù)集,旨在評(píng)估機(jī)器的推理能力。 5.1 MNIST-ADD MNIST-ADD是一個(gè)簡單的個(gè)位數(shù)加法數(shù)據(jù)集。任務(wù)是在給定三個(gè)MNIST圖像和1位“True/False”標(biāo)簽的情況下學(xué)習(xí)“個(gè)位數(shù)加法”公式。該數(shù)據(jù)集包括20,000個(gè)用于訓(xùn)練的實(shí)例和20,000個(gè)用于測試的實(shí)例。我們使用不同的分割策略將數(shù)據(jù)集進(jìn)一步分割為α和β分割。在β分割中,測試集具有與訓(xùn)練集中的實(shí)例不同的附加實(shí)例。這種設(shè)置也稱為“訓(xùn)練/測試分布偏移”,這對于神經(jīng)網(wǎng)絡(luò)來說很難解決。 結(jié)果總結(jié)如表1。 在MNSIT-ADd-α和MNIST-ADD-β數(shù)據(jù)集上,DNN模型過度擬合訓(xùn)練集。盡管嘗試使用改變模型大小和dropout等方法,但效果不佳。DNN模型在邏輯準(zhǔn)確性方面表現(xiàn)較差,尤其是在處理不平衡的β分裂時(shí)。與ABL模型相比,我們的模型更加靈活,無需Prolog程序即可達(dá)到更高的精度。最后,通過邏輯的反向傳播有助于為感知模型提供監(jiān)督。
表1:MNIST-ADD數(shù)據(jù)集上的準(zhǔn)確性,其中EXTRA SUP表示模型是否使用額外的感知監(jiān)督或僅一位邏輯監(jiān)督進(jìn)行訓(xùn)練,EXTRA TOOL表示模型是否使用任何額外的工具
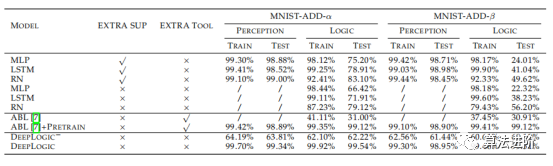
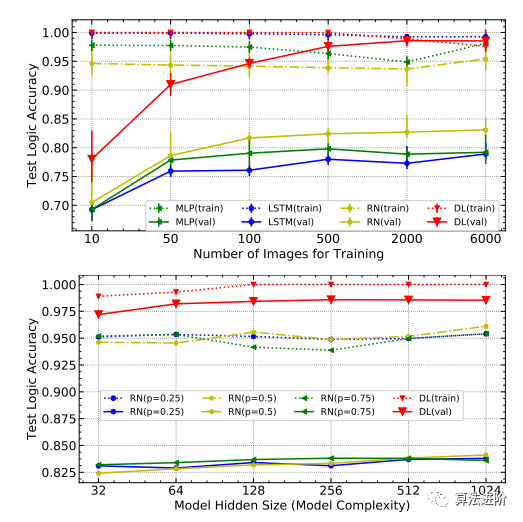
圖 4 上圖: 在 MNIST-ADD- α上使用不同尺度的訓(xùn)練圖像測試準(zhǔn)確性, DL 是 DeepLogic 的縮寫; 下圖: 測試不同模型隱藏大小以及 RN 和 DL 的不同 dropout 概 率的準(zhǔn)確性。
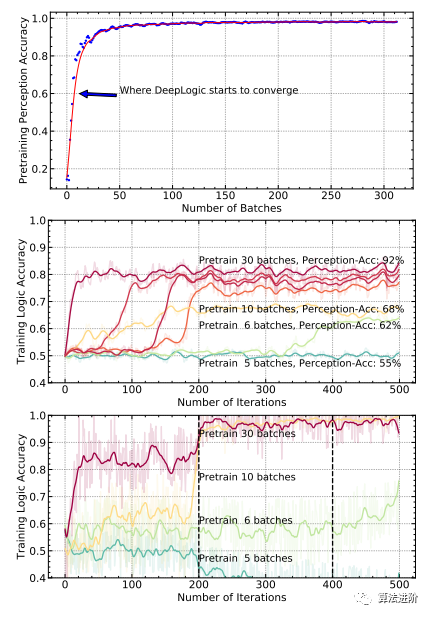
圖 5 上 圖 : 在 MNIST-ADD- α數(shù)據(jù)集上預(yù)訓(xùn)練 p θ時(shí)的 PERCEPTION 準(zhǔn)確度; 中圖: 在 MNIST-ADD- α數(shù)據(jù)集上使用不同批次的預(yù)訓(xùn) 練數(shù)據(jù)訓(xùn)練 DeepLogic- 的 LOGIC 準(zhǔn)確性; 下圖: 在 MNIST-ADD- α數(shù)據(jù)集上使用不同批次的預(yù) 訓(xùn)練數(shù)據(jù)訓(xùn)練 DeepLogic 的 LOGIC 準(zhǔn)確 性。 主要發(fā)現(xiàn)是: 1 )更多的預(yù)訓(xùn)練批次確保了更好的準(zhǔn)確性; 2 ) DeepLogic 最終收斂只需要很少 的預(yù)訓(xùn)練。
模型穩(wěn)定性。 此任務(wù)采用兩個(gè)術(shù)語層和一個(gè)公式層來學(xué)習(xí)特定邏輯,但實(shí)際應(yīng)用可能受限。 實(shí)驗(yàn)表明(表3) ,系統(tǒng)在不同設(shè)置下學(xué)習(xí)效果不同,模型收斂容易,對不同初始化具有魯棒性。
表3 MNIST-ADD數(shù)據(jù)集中不同設(shè)置下學(xué)習(xí)的典型公式。M表示術(shù)語層數(shù),N表示公式層數(shù)。最后一列是5次隨機(jī)試驗(yàn)中成功收斂的百分比。

C-MNIST-RULE是MNIST-ADD的擴(kuò)展,其中包含一個(gè)額外的屬性“顏色”和兩個(gè)額外的公式“級(jí)數(shù)”和“互斥”。請注意,我們對MNIST-ADD和C-MNIST-RULE使用相同的DeepLogic模型,唯一的區(qū)別在于輸出公式Δφ的數(shù)量,在C-MNIST-RULE中為1,而在C-MNIST-RULE中為3。DeepLogic能夠同時(shí)學(xué)習(xí)多個(gè)公式和感知。
C-MNIST-RULE包含多個(gè)規(guī)則和屬性,其中我們對MNIST圖像進(jìn)行著色以添加顏色屬性,并根據(jù)Raven的漸進(jìn)矩陣(RPM)實(shí)現(xiàn)三個(gè)規(guī)則。與MNIST-ADD類似,C-MNISTRULE數(shù)據(jù)集包含20,000個(gè)訓(xùn)練實(shí)例和20,000個(gè)測試實(shí)例。
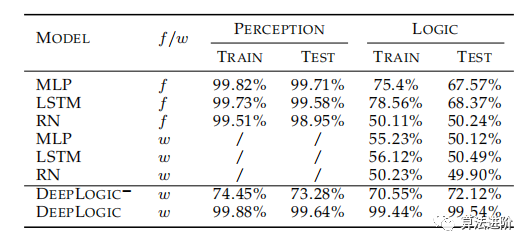
表2展示了不同模型在C-MNIST-RULE上的準(zhǔn)確性。其中f表示模型使用額外的符號(hào)注釋進(jìn)行訓(xùn)練,w表示不涉及額外的符號(hào)注釋。DeepLogic?不進(jìn)一步訓(xùn)練pθ。DeepLogic和DeepLogic?均經(jīng)過10個(gè)批次的預(yù)訓(xùn)練。LOGIC是最終預(yù)測y的準(zhǔn)確性,而PERCEPTION是預(yù)測隱藏符號(hào)z的準(zhǔn)確性。
表2 不同模型在C-MNIST-RULE的準(zhǔn)確性
-
與 CMNIST-RULE 上沒有符號(hào)注釋的結(jié)果相比,純基于 DNN 的方法性能較差。
- 基于純DNN的方法在額外符號(hào)注釋的幫助下收斂,這也與[15]一致,其中純DNN甚至ResNet無法比沒有額外注釋的隨機(jī)猜測表現(xiàn)得更好。
-
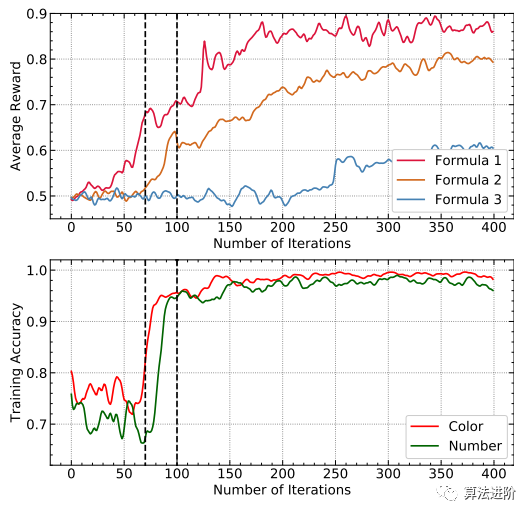
公式1收斂速度快。
-
收斂公式1監(jiān)督Color屬性收斂。
- 融合的Color屬性進(jìn)一步促進(jìn)了公式2和其他公式的學(xué)習(xí)。
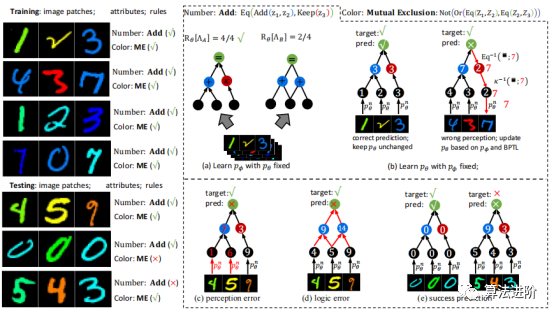
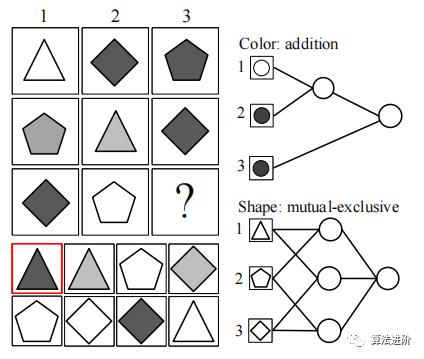
圖 8 RPM 任務(wù)中 的 DLM 模塊圖示。 圖像被視為輸入,然后輸入邏輯層,其中邏輯操作是 從所有 可能的候選組合中選擇的。
Soft-DLM模塊替換CoPINet中的原始融合方法后,性能得到顯著提升, 如表4所示, 特別是在“2×2”和“3×3”的情況下。這驗(yàn)證了DeepLogic的泛化能力和在連續(xù)領(lǐng)域的潛力。表4 在RAVEN數(shù)據(jù)集上測試準(zhǔn)確性。ACC是最終的準(zhǔn)確率,其他列代表不同的任務(wù)配置

更多精彩內(nèi)容請點(diǎn)擊:AI領(lǐng)域文章精選! 關(guān)注??公眾號(hào),后臺(tái)回復(fù)【DeepLogic】可下載論文及代碼
