
寫了一年golang,來(lái)聊聊進(jìn)程、線程與協(xié)程
進(jìn)程
在早期的單任務(wù)計(jì)算機(jī)中,用戶一次只能提交一個(gè)作業(yè),獨(dú)享系統(tǒng)的全部資源,同時(shí)也只能干一件事情。進(jìn)行計(jì)算時(shí)不能進(jìn)行 IO 讀寫,但 CPU 與 IO 的速度存在巨大差異,一個(gè)作業(yè)在 CPU 上所花費(fèi)的時(shí)間非常少,大部分時(shí)間在等待 IO。
為了更合理的利用 CPU 資源,把內(nèi)存劃分為多塊,不同程序使用各自的內(nèi)存空間互不干擾,這里單獨(dú)的程序就是一個(gè)進(jìn)程,CPU 可以在多個(gè)進(jìn)程之間切換執(zhí)行,讓 CPU 的利用率變高。
為了實(shí)現(xiàn) CPU 在多個(gè)進(jìn)程之間切換,需要保存進(jìn)程的上下文(如程序計(jì)數(shù)器、棧、內(nèi)核數(shù)據(jù)結(jié)構(gòu)等等),以便下次切換回來(lái)可以恢復(fù)執(zhí)行。還需要一種調(diào)度算法,Linux 中采用了基于時(shí)間片和優(yōu)先級(jí)的完全公平調(diào)度算法。
線程
多進(jìn)程的出現(xiàn)是為了解決 CPU 利用率的問(wèn)題,那為什么還需要線程?答案是為了減少上下文切換時(shí)的開(kāi)銷。
進(jìn)程在如下兩個(gè)時(shí)間點(diǎn)可能會(huì)讓出 CPU,進(jìn)行 CPU 切換:
進(jìn)程阻塞,如網(wǎng)絡(luò)阻塞、代碼層面的阻塞(如鎖)、系統(tǒng)調(diào)用等 進(jìn)程時(shí)間片用完,讓出 CPU
而進(jìn)程切換 CPU 時(shí)需要進(jìn)行這兩步:
切換頁(yè)目錄以使用新的地址空間 切換內(nèi)核棧和硬件上下文
進(jìn)程和線程在 Linux 中沒(méi)有本質(zhì)區(qū)別,他們最大的不同就是進(jìn)程有自己獨(dú)立的內(nèi)存空間,而線程(同進(jìn)程中)是共享內(nèi)存空間。
在進(jìn)程切換時(shí)需要轉(zhuǎn)換內(nèi)存地址空間,而線程切換沒(méi)有這個(gè)動(dòng)作,所以線程切換比進(jìn)程切換代價(jià)更小。
為什么內(nèi)存地址空間轉(zhuǎn)換這么慢?Linux 實(shí)現(xiàn)中,每個(gè)進(jìn)程的地址空間都是虛擬的,虛擬地址空間轉(zhuǎn)換到物理地址空間需要查頁(yè)表,這個(gè)查詢是很慢的過(guò)程,因此會(huì)用一種叫做 TLB 的 cache 來(lái)加速,當(dāng)進(jìn)程切換后,TLB 也隨之失效了,所以會(huì)變慢。
綜上,線程是為了降低進(jìn)程切換過(guò)程中的開(kāi)銷。
協(xié)程
當(dāng)我們的程序是 IO 密集型時(shí)(如 web 服務(wù)器、網(wǎng)關(guān)等),為了追求高吞吐,有兩種思路:
為每個(gè)請(qǐng)求開(kāi)一個(gè)線程處理,為了降低線程的創(chuàng)建開(kāi)銷,可以使用線程池技術(shù),理論上線程池越大,則吞吐越高,但線程池越大,CPU 花在切換上的開(kāi)銷也越大
線程的創(chuàng)建、銷毀都需要調(diào)用系統(tǒng)調(diào)用,每次請(qǐng)求都創(chuàng)建,高并發(fā)下開(kāi)銷就顯得很大,而且線程占用內(nèi)存是 MB 級(jí)別,數(shù)量不能太多
為什么線程越多 cpu 切換越多?準(zhǔn)確來(lái)說(shuō)是可執(zhí)行的線程越多,cpu 切換越多,因?yàn)椴僮飨到y(tǒng)的調(diào)度要保證絕對(duì)公平,有可執(zhí)行線程時(shí),一定是要雨露均沾,所以切換次數(shù)變多
使用異步非阻塞的開(kāi)發(fā)模型,用一個(gè)進(jìn)程或線程接收請(qǐng)求,然后通過(guò) IO 多路復(fù)用讓進(jìn)程或線程不阻塞,省去上下文切換的開(kāi)銷
這兩個(gè)方案,優(yōu)缺點(diǎn)都很明顯,方案1實(shí)現(xiàn)簡(jiǎn)單,但性能不高;方案2性能非常好,但實(shí)現(xiàn)起來(lái)復(fù)雜。有沒(méi)有介于這兩者之間的方案?既要簡(jiǎn)單,又要性能高,協(xié)程就解決了這個(gè)問(wèn)題。
協(xié)程是用戶視角的一種抽象,操作系統(tǒng)并沒(méi)有這個(gè)概念,其主要思想是在用戶態(tài)實(shí)現(xiàn)調(diào)度算法,用少量線程完成大量任務(wù)的調(diào)度。
協(xié)程需要解決線程遇到的幾個(gè)問(wèn)題:
內(nèi)存占用要小,且創(chuàng)建開(kāi)銷要小 減少上下文切換的開(kāi)銷
第一點(diǎn)好實(shí)現(xiàn),用戶態(tài)的協(xié)程,只是一個(gè)數(shù)據(jù)結(jié)構(gòu),無(wú)需系統(tǒng)調(diào)用,而且可以設(shè)計(jì)的很小,達(dá)到 KB 級(jí)別。
第二點(diǎn)只能減少上下文切換次數(shù)來(lái)解決,因?yàn)閰f(xié)程的本質(zhì)還是線程,其切換開(kāi)銷在用戶態(tài)是無(wú)法降低的,只能通過(guò)降低切換次數(shù)來(lái)達(dá)到總體上開(kāi)銷的減少,可以有如下手段:
讓可執(zhí)行的線程盡量少,這樣切換次數(shù)必然會(huì)少 讓線程盡可能的處于運(yùn)行狀態(tài),而不是阻塞讓出時(shí)間片
Goroutine
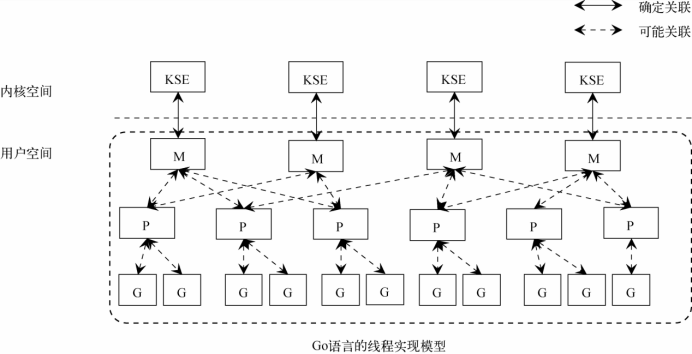
goroutine 是 golang 實(shí)現(xiàn)的協(xié)程,其特點(diǎn)是在語(yǔ)言層面就支持,使用起來(lái)非常方便,它的核心是MPG調(diào)度模型:
M:內(nèi)核線程 P:處理器,用來(lái)執(zhí)行 goroutine,它維護(hù)了本地可運(yùn)行隊(duì)列 G:goroutine,代碼和數(shù)據(jù)結(jié)構(gòu) S:調(diào)度器,維護(hù)M和P的信息
除此之外還有一個(gè)全局可運(yùn)行隊(duì)列。
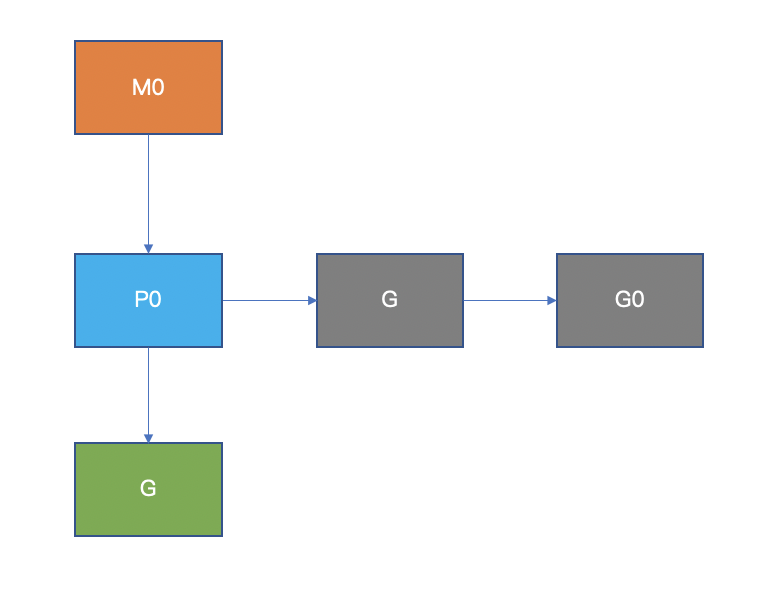
在 golang 中使用 go 關(guān)鍵字啟動(dòng)一個(gè) goroutine,它將會(huì)被掛到 P 的 runqueue 中,等待被調(diào)度
當(dāng) M0 中正在運(yùn)行的 G0 阻塞時(shí)(如執(zhí)行了一個(gè)系統(tǒng)調(diào)用),此時(shí) M0 會(huì)休眠,它將放棄掛載的 P0,以便被其他 M 調(diào)度到
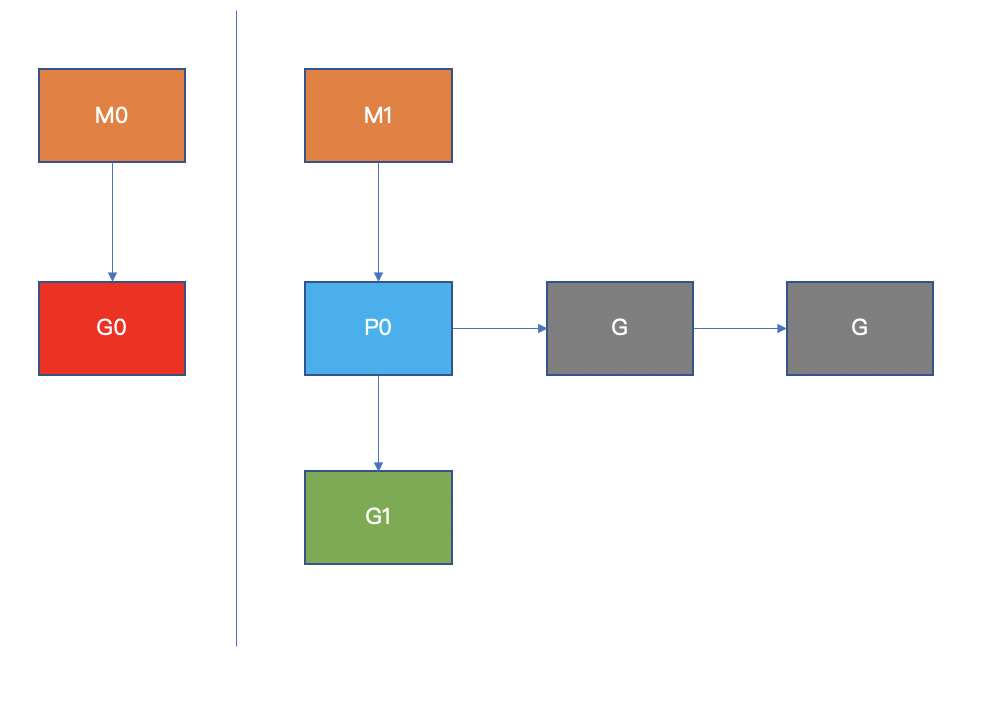
當(dāng) M0 系統(tǒng)調(diào)用結(jié)束后,會(huì)嘗試“偷”一個(gè) P,如果不成功,M0 將 G0 放到全局的 runqueue 中
P 會(huì)定期檢查全局 runqueue,保證自己消化完 G 后有事可做,同時(shí)也會(huì)從其他 P 里“偷” G
從上述看來(lái),MPG 模型似乎只限制了同時(shí)運(yùn)行的線程數(shù),但上下文切換只發(fā)生在可運(yùn)行的線程上,應(yīng)該是有一定的作用,當(dāng)然這只是一部分。
golang 在 runtime 層面攔截了可能導(dǎo)致線程阻塞的情況,并針對(duì)性優(yōu)化,他們可分為兩類:
網(wǎng)絡(luò) IO、channel 操作、鎖:只阻塞 G,M、P 可用,即線程不會(huì)讓出時(shí)間片 系統(tǒng)調(diào)用:阻塞 M,P 需要切換,線程會(huì)讓出時(shí)間片
所以綜合來(lái)看,goroutine 會(huì)比線程切換開(kāi)銷少。
總結(jié)
從單進(jìn)程到多進(jìn)程提高了 CPU 利用率;從進(jìn)程到線程,降低了上下文切換的開(kāi)銷;從線程到協(xié)程,進(jìn)一步降低了上下文切換的開(kāi)銷,使得高并發(fā)的服務(wù)可以使用簡(jiǎn)單的代碼寫出來(lái),技術(shù)的每一步發(fā)展都是為了解決實(shí)際問(wèn)題。
搜索關(guān)注微信公眾號(hào)"捉蟲大師",后端技術(shù)分享,架構(gòu)設(shè)計(jì)、性能優(yōu)化、源碼閱讀、問(wèn)題排查、踩坑實(shí)踐。