
構(gòu)建可以查找相似圖像的圖像搜索引擎的深度學(xué)習(xí)技術(shù)詳解

來源:DeepHub IMBA 本文約3400字,建議閱讀7分鐘
本文為你介紹如何查找相似圖像的理論基礎(chǔ)并且使用一個(gè)用于查找商標(biāo)的系統(tǒng)為例介紹相關(guān)的技術(shù)實(shí)現(xiàn)。
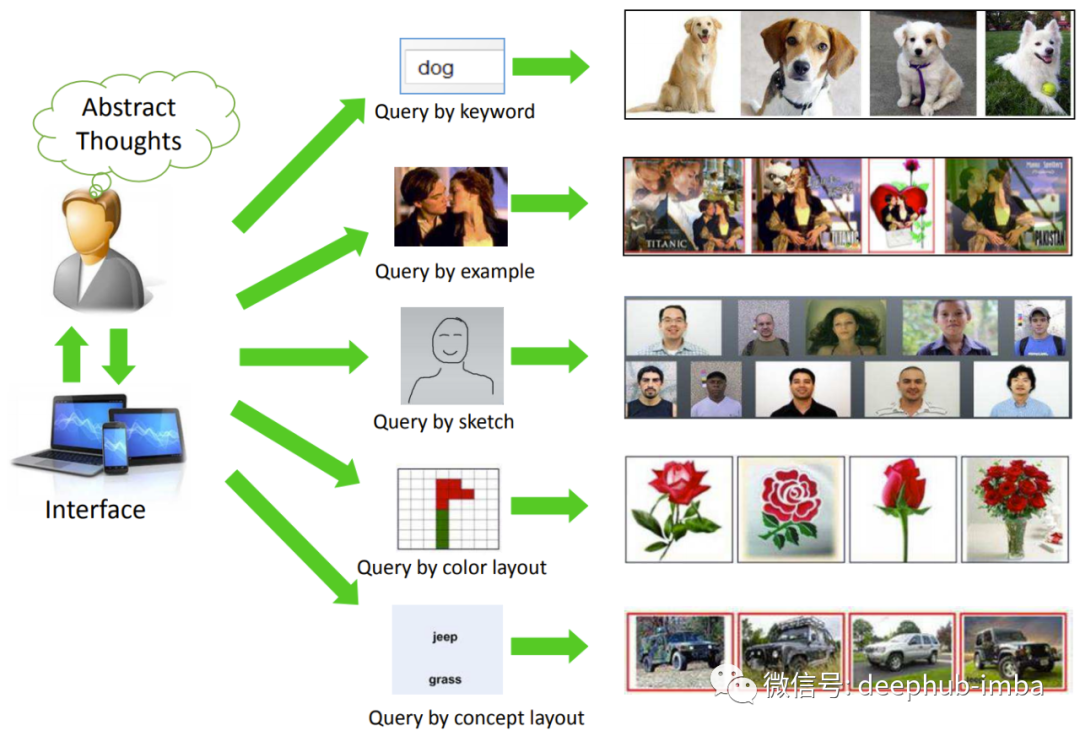
上圖來自文章Recent Advance in Content-based Image Retrieval: A Literature Survey (2017) arxiv:1706.06064
基礎(chǔ)服務(wù)組件
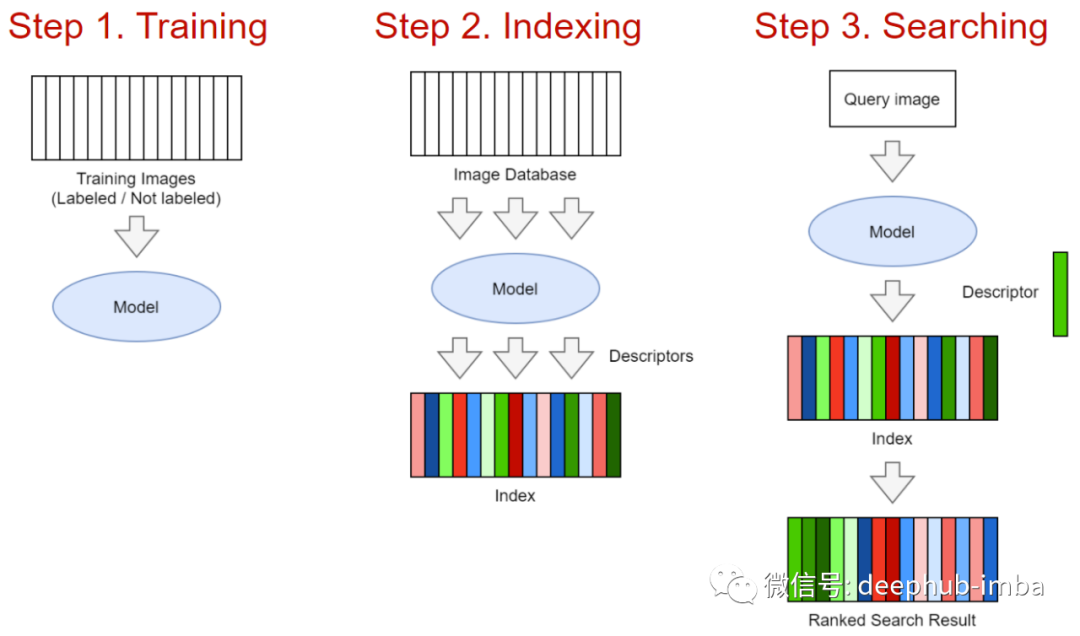
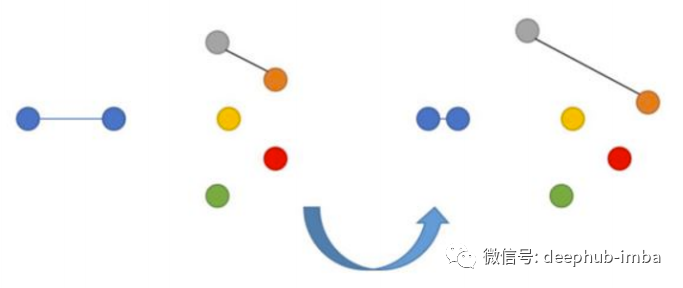
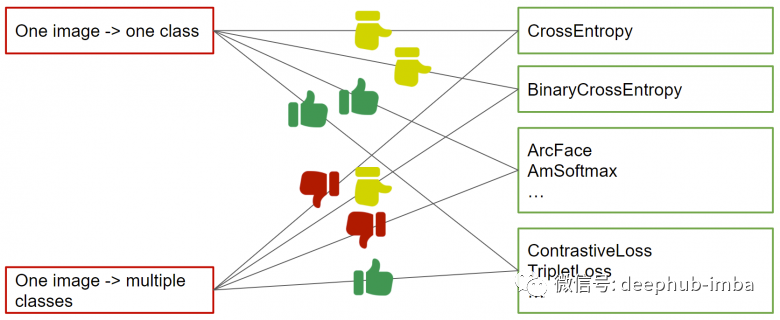
神經(jīng)網(wǎng)絡(luò)和度量學(xué)習(xí)
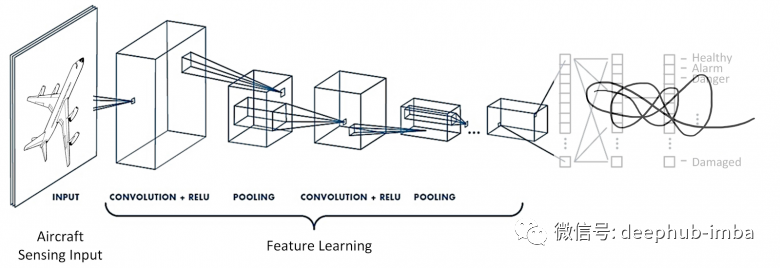
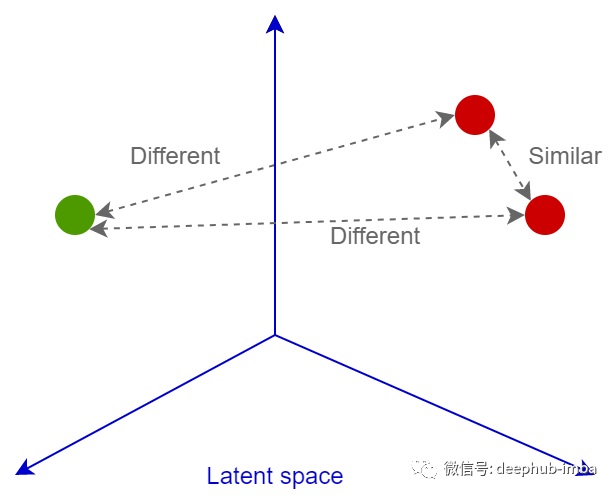
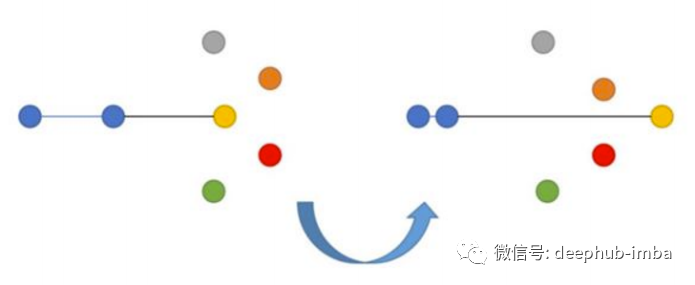
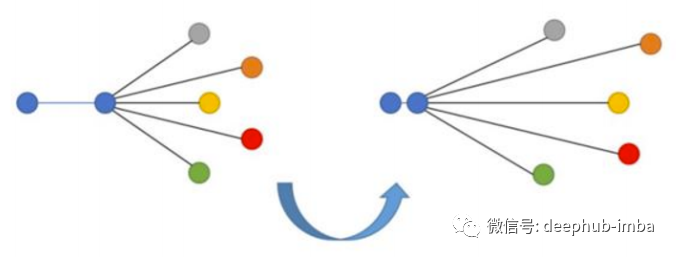
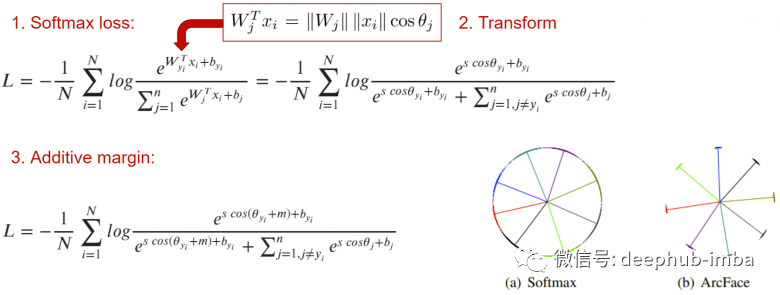
損失函數(shù)
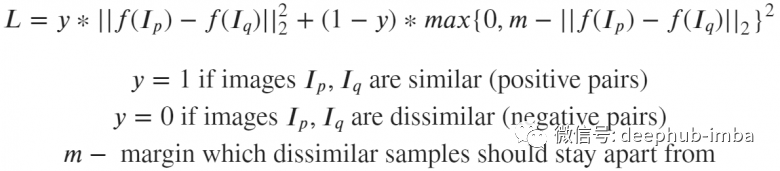


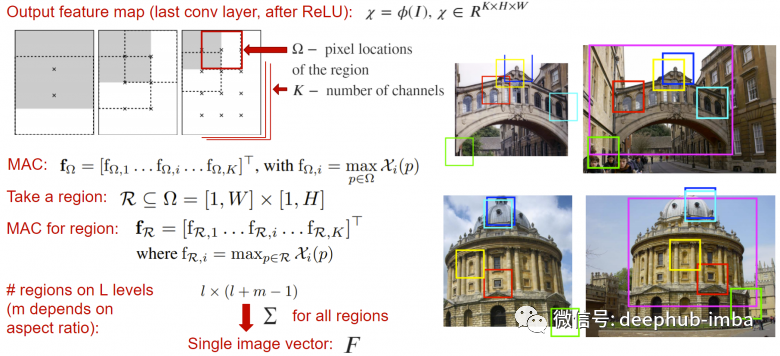
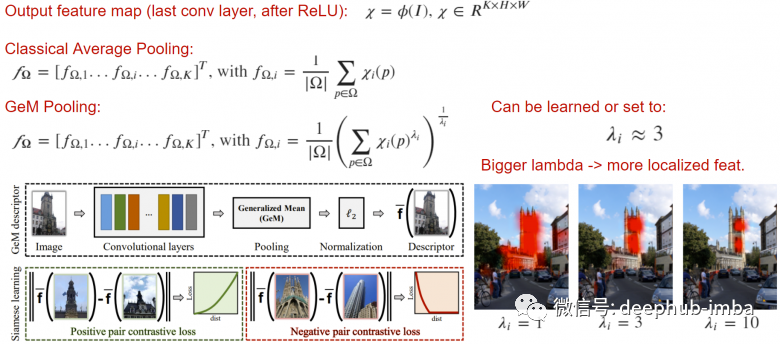
池化
距離的測量
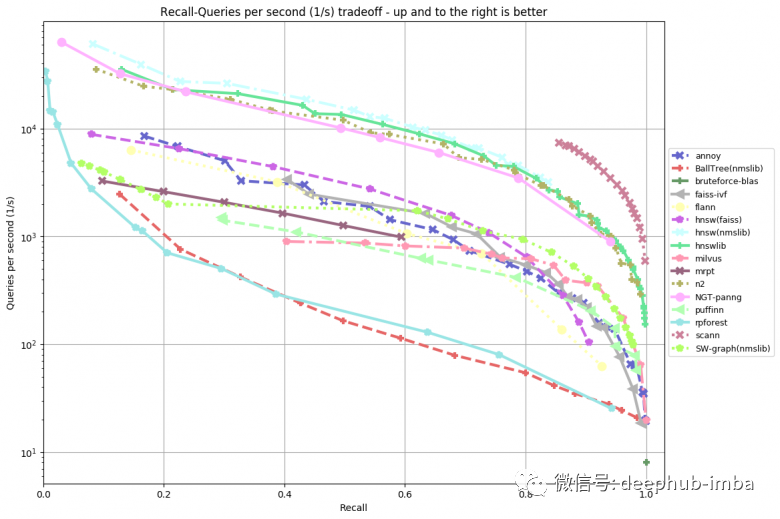
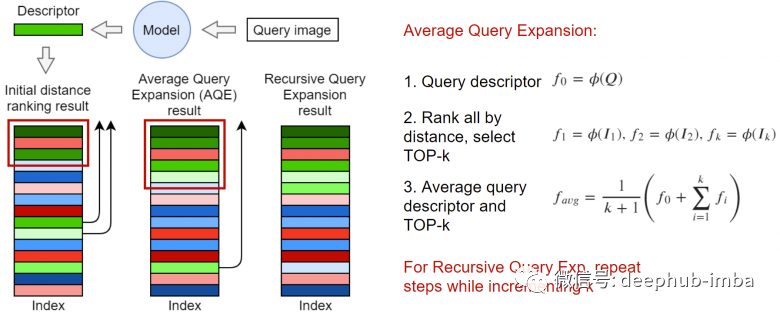

驗(yàn)證指標(biāo)

對給定查詢的相關(guān)樣本的數(shù)量非常敏感,可能產(chǎn)生對搜索質(zhì)量的非客觀評估,因?yàn)椴煌牟樵冇胁煌瑪?shù)量的相關(guān)結(jié)果 僅當(dāng)所有查詢的相關(guān)數(shù) >= k 時(shí),才有可能達(dá)到1


這個(gè)指標(biāo)回答了在top-k中是否找到了相關(guān)的結(jié)果 能夠穩(wěn)定且平均地處理請求

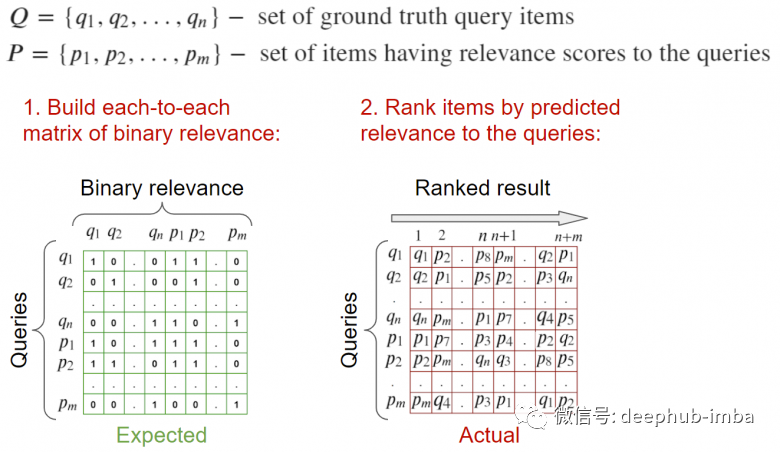
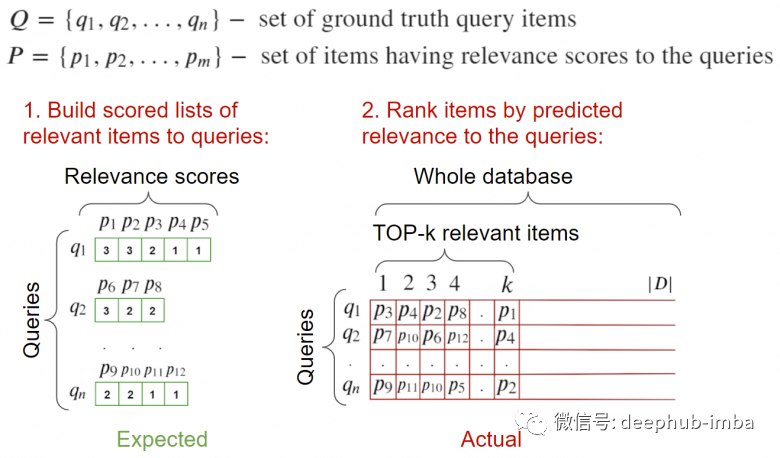
完整的樣例介紹


總結(jié)
評論
圖片
表情