
Pandas快速上手!
我根據(jù)之前整理的一些pandas知識(shí),總結(jié)了一個(gè)pandas的快速入門(mén)的知識(shí)框架。有了這些知識(shí),然后去通過(guò)項(xiàng)目實(shí)戰(zhàn),然后再補(bǔ)充。希望能幫助大家快速上手。

Pandas入門(mén)知識(shí)框架
1. 什么是Pandas?熊貓?
Pandas 可以說(shuō)是基于 NumPy 構(gòu)建的含有更高級(jí)數(shù)據(jù)結(jié)構(gòu)和分析能力的工具包, 實(shí)現(xiàn)了類(lèi)似Excel表的功能,可以對(duì)二維數(shù)據(jù)表進(jìn)行很方便的操作。
在數(shù)據(jù)分析工作中,Pandas 的使用頻率是很高的,一方面是因?yàn)?Pandas 提供的基礎(chǔ)數(shù)據(jù)結(jié)構(gòu) DataFrame 與 json 的契合度很高,轉(zhuǎn)換起來(lái)就很方便。另一方面,如果我們?nèi)粘5臄?shù)據(jù)清理工作不是很復(fù)雜的話(huà),你通常用幾句 Pandas 代碼就可以對(duì)數(shù)據(jù)進(jìn)行規(guī)整。
Pandas的核心數(shù)據(jù)結(jié)構(gòu):Series 和 DataFrame 這兩個(gè)核心數(shù)據(jù)結(jié)構(gòu)。他們分別代表著一維的序列和二維的表結(jié)構(gòu)。基于這兩種數(shù)據(jù)結(jié)構(gòu),Pandas 可以對(duì)數(shù)據(jù)進(jìn)行導(dǎo)入、清洗、處理、統(tǒng)計(jì)和輸出。
快速掌握Pandas,就要快速學(xué)會(huì)這兩種核心數(shù)據(jù)結(jié)構(gòu)。
2. 兩種核心數(shù)據(jù)結(jié)構(gòu)
2.1 Series
Series 是個(gè)定長(zhǎng)的字典序列。說(shuō)是定長(zhǎng)是因?yàn)樵诖鎯?chǔ)的時(shí)候,相當(dāng)于兩個(gè) ndarray,這也是和字典結(jié)構(gòu)最大的不同。因?yàn)樵谧值涞慕Y(jié)構(gòu)里,元素的個(gè)數(shù)是不固定的。
Series 有兩個(gè)基本屬性:index 和 values。在 Series 結(jié)構(gòu)中,index 默認(rèn)是 0,1,2,……遞增的整數(shù)序列,當(dāng)然我們也可以自己來(lái)指定索引,比如 index=[‘a(chǎn)’, ‘b’, ‘c’, ‘d’]。
import?pandas?as?pd
from?pandas?import?Series,?DataFrame
x1?=?Series([1,2,3,4])
x2?=?Series(data=[1,2,3,4],?index=['a',?'b',?'c',?'d'])
print?x1
print?x2
上面這個(gè)例子中,x1 中的 index 采用的是默認(rèn)值,x2 中 index 進(jìn)行了指定。我們也可以采用字典的方式來(lái)創(chuàng)建 Series,比如:
d?=?{'a':1,?'b':2,?'c':3,?'d':4}
x3?=?Series(d)
print?x3?
Series的增刪改查
創(chuàng)建一個(gè)Series
In?[85]:?ps?=?pd.Series(data=[-3,2,1],index=['a','f','b'],dtype=np.float32)?????
In?[86]:?ps?????????????????????????????????????????????????????????????????????
Out[86]:?
a???-3.0
f????2.0
b????1.0
dtype:?float32增加元素append
In?[112]:?ps.append(pd.Series(data=[-8.0],index=['f']))?????????????????????????
Out[112]:?
a????4.0
f????2.0
b????1.0
f???-8.0
dtype:?float64刪除元素drop
In?[119]:?ps????????????????????????????????????????????????????????????????????
Out[119]:?
a????4.0
f????2.0
b????1.0
dtype:?float32
In?[120]:?psd?=?ps.drop('f')????????????????????????????????????????????????????
In?[121]:?psd??????????????????????????????????????????????????????????????????
Out[121]:?
a????4.0
b????1.0
dtype:?float32注意不管是 append 操作,還是 drop 操作,都是發(fā)生在原數(shù)據(jù)的副本上,不是原數(shù)據(jù)上。
修改元素
通過(guò)標(biāo)簽修改對(duì)應(yīng)數(shù)據(jù),如下所示:In?[123]:?psn???????????????????????????????????????????????????????????????????
Out[123]:?
a????4.0
f????2.0
b????1.0
f???-8.0
dtype:?float64
In?[124]:?psn['f']?=?10.0???????????????????????????????????????????????????????
In?[125]:?psn???????????????????????????????????????????????????????????????????
Out[125]:?
a?????4.0
f????10.0
b?????1.0
f????10.0
dtype:?float64Series里面允許標(biāo)簽相同, 且如果相同, 標(biāo)簽都會(huì)被修改。
訪(fǎng)問(wèn)元素
一種通過(guò)默認(rèn)的整數(shù)索引,在 Series 對(duì)象未被顯示的指定 label 時(shí),都是通過(guò)索引訪(fǎng)問(wèn);另一種方式是通過(guò)標(biāo)簽訪(fǎng)問(wèn)。In?[126]:?ps????????????????????????????????????????????????????????????????????
Out[126]:?
a????4.0
f????2.0
b????1.0
dtype:?float32
In?[128]:?ps[2]?#?索引訪(fǎng)問(wèn)??????????????????????????????
Out[128]:?1.0
In?[127]:?ps['b']??#?標(biāo)簽訪(fǎng)問(wèn)?????????????????????????????????????????????????????????????
Out[127]:?1.0
2.2 DataFrame
DataFrame 類(lèi)型數(shù)據(jù)結(jié)構(gòu)類(lèi)似數(shù)據(jù)庫(kù)表。它包括了行索引和列索引,我們可以將 DataFrame 看成是由相同索引的 Series 組成的字典類(lèi)型。
import?pandas?as?pd
from?pandas?import?Series,?DataFrame
data?=?{'Chinese':?[66,?95,?93,?90,80],'English':?[65,?85,?92,?88,?90],'Math':?[30,?98,?96,?77,?90]}
df1=?DataFrame(data)
df2?=?DataFrame(data,?index=['ZhangFei',?'GuanYu',?'ZhaoYun',?'HuangZhong',?'DianWei'],?columns=['English',?'Math',?'Chinese'])
print?df1
print?df2
在后面的案例中,我一般會(huì)用 df, df1, df2 這些作為 DataFrame 數(shù)據(jù)類(lèi)型的變量名,我們以例子中的 df2 為例,列索引是[‘English’, ‘Math’, ‘Chinese’],行索引是[‘ZhangFei’, ‘GuanYu’, ‘ZhaoYun’, ‘HuangZhong’, ‘DianWei’],所以 df2 的輸出是:
????????????English??Math??Chinese
ZhangFei?????????65????30???????66
GuanYu???????????85????98???????95
ZhaoYun??????????92????96???????93
HuangZhong???????88????77???????90
DianWei??????????90????90???????80
2.2.1基本操作
(1)數(shù)據(jù)的導(dǎo)入與輸出
Pandas 允許直接從 xlsx,csv 等文件中導(dǎo)入數(shù)據(jù),也可以輸出到 xlsx, csv 等文件,非常方便。
需要說(shuō)明的是,在運(yùn)行的過(guò)程可能會(huì)存在缺少 xlrd 和 openpyxl 包的情況,到時(shí)候如果缺少了,可以在命令行模式下使用“pip install”命令來(lái)進(jìn)行安裝。
import?pandas?as?pd
from?pandas?import?Series,?DataFrame
score?=?DataFrame(pd.read_excel('data.xlsx'))
score.to_excel('data1.xlsx')
print?score
關(guān)于數(shù)據(jù)導(dǎo)入, pandas提供了強(qiáng)勁的讀取支持, 比如讀寫(xiě)CSV文件, read_csv()函數(shù)有38個(gè)參數(shù)之多, 這里面有一些很有用, 主要可以分為下面幾個(gè)維度來(lái)梳理:
基本參數(shù)
filepathorbuffer: 數(shù)據(jù)的輸入路徑, 可以是文件路徑, 也可是是URL或者實(shí)現(xiàn)read方法的任意對(duì)象sep: 數(shù)據(jù)文件的分隔符, 默認(rèn)為逗號(hào)delim_whitespace: 表示分隔符為空白字符, 可以是一個(gè)空格, 兩個(gè)空格header: 設(shè)置導(dǎo)入DataFrame的列名稱(chēng), 如果names沒(méi)賦值, header會(huì)選取數(shù)據(jù)文件的第一行作為列名index_col: 表示哪個(gè)或者哪些列作為indexusecols: 選取數(shù)據(jù)文件的哪些列到DataFrame中prefix: 當(dāng)導(dǎo)入的數(shù)據(jù)沒(méi)有header時(shí), 設(shè)置此參數(shù)會(huì)自動(dòng)加一個(gè)前綴通用解析參數(shù)
dtype:讀取數(shù)據(jù)時(shí)修改列的類(lèi)型converters: 實(shí)現(xiàn)對(duì)列數(shù)據(jù)的變化操作skip_rows: 過(guò)濾行nrows: 設(shè)置一次性讀入的文件行數(shù),它在讀入大文件時(shí)很有用,比如 16G 內(nèi)存的PC無(wú)法容納幾百 G 的大文件。skip_blank_lines: 過(guò)濾掉空行時(shí)間處理相關(guān)參數(shù)
parse_dates: 如果導(dǎo)入的某些列為時(shí)間類(lèi)型,但是導(dǎo)入時(shí)沒(méi)有為此參數(shù)賦值,導(dǎo)入后就不是時(shí)間類(lèi)型 date_parser: 定制某種時(shí)間類(lèi)型 分開(kāi)讀入相關(guān)參數(shù):
分塊讀入內(nèi)存,尤其單機(jī)處理大文件時(shí)會(huì)很有用。iterator: iterator 取值 boolean,default False,返回一個(gè) TextFileReader 對(duì)象,以便逐塊處理文件。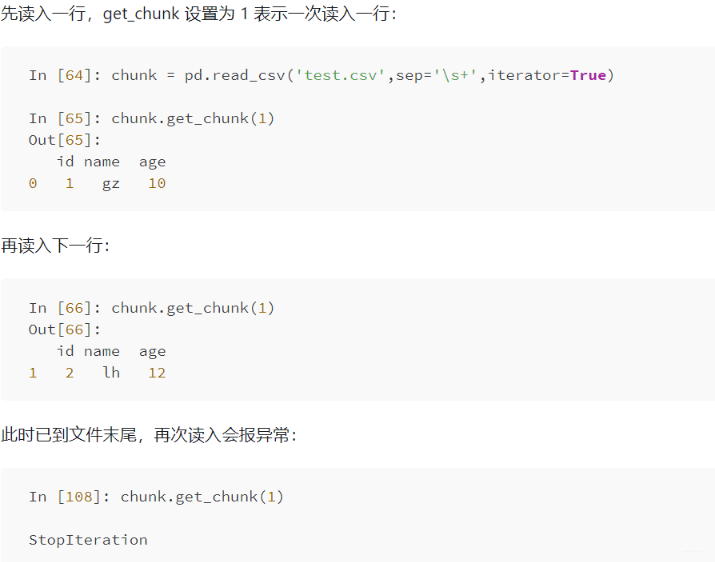
chunksize: 整型,默認(rèn)為 None,設(shè)置文件塊的大小。 格式和壓縮相關(guān)參數(shù)
id name ?age 0 ? 1 ? gz ? 10 1 ? 2 ? lh ? 12
-?`thousands`: str,default None,千分位分割符,如?`,`?或者?`.`。
-?`encoding`:?指定字符集類(lèi)型,通常指定為?‘utf-8’compression
compression 參數(shù)取值為 {‘infer’, ‘gzip’, ‘bz2’, ‘zip’, ‘xz’, None},默認(rèn) ‘infer’,直接使用磁盤(pán)上的壓縮文件。如果使用 infer 參數(shù),則使用 gzip、bz2、zip 或者解壓文件名中以 ‘.gz’、‘.bz2’、‘.zip’ 或 ‘xz’ 這些為后綴的文件,否則不解壓。如果使用 zip,那么 ZIP 包中必須只包含一個(gè)文件。設(shè)置為 None 則不解壓。手動(dòng)壓縮本文一直使用的 test.csv 為 test.zip 文件,然后打開(kāi)In?[73]:??df?=?pd.read_csv('test.zip',sep='\s+',compression='zip')
In?[74]:?df
Out[74]:
具體這些參數(shù)怎么用, 可以看https://gitbook.cn/gitchat/column/5e37978dec8d9033cf916b5d/topic/5e3bcef3ec8d9033cf92466f
(2)數(shù)據(jù)清洗
數(shù)據(jù)清洗是數(shù)據(jù)準(zhǔn)備過(guò)程中必不可少的環(huán)節(jié),Pandas 也為我們提供了數(shù)據(jù)清洗的工具,在后面數(shù)據(jù)清洗的章節(jié)中會(huì)給你做詳細(xì)的介紹,這里簡(jiǎn)單介紹下 Pandas 在數(shù)據(jù)清洗中的使用方法。
(2.1)刪除 DataFrame 中的不必要的列或行
Pandas 提供了一個(gè)便捷的方法 drop() 函數(shù)來(lái)刪除我們不想要的列或行
df2?=?df2.drop(columns=['Chinese'])
想把“張飛”這行刪掉。
df2?=?df2.drop(index=['ZhangFei'])
(2.2)重命名列名 columns,讓列表名更容易識(shí)別
如果你想對(duì) DataFrame 中的 columns 進(jìn)行重命名,可以直接使用 rename(columns=new_names, inplace=True) 函數(shù),比如我把列名 Chinese 改成 YuWen,English 改成 YingYu。
df2.rename(columns={'Chinese':?'YuWen',?'English':?'Yingyu'},?inplace?=?True)
(2.3)去重復(fù)的值
數(shù)據(jù)采集可能存在重復(fù)的行,這時(shí)只要使用 drop_duplicates() 就會(huì)自動(dòng)把重復(fù)的行去掉
df?=?df.drop_duplicates()?#去除重復(fù)行
(2.4)格式問(wèn)題
更改數(shù)據(jù)格式
這是個(gè)比較常用的操作,因?yàn)楹芏鄷r(shí)候數(shù)據(jù)格式不規(guī)范,我們可以使用 astype 函數(shù)來(lái)規(guī)范數(shù)據(jù)格式,比如我們把 Chinese 字段的值改成 str 類(lèi)型,或者 int64 可以這么寫(xiě)
df2['Chinese'].astype('str')?
df2['Chinese'].astype(np.int64)?
數(shù)據(jù)間的空格
有時(shí)候我們先把格式轉(zhuǎn)成了 str 類(lèi)型,是為了方便對(duì)數(shù)據(jù)進(jìn)行操作,這時(shí)想要?jiǎng)h除數(shù)據(jù)間的空格,我們就可以使用 strip 函數(shù):
#刪除左右兩邊空格
df2['Chinese']=df2['Chinese'].map(str.strip)
#刪除左邊空格
df2['Chinese']=df2['Chinese'].map(str.lstrip)
#刪除右邊空格
df2['Chinese']=df2['Chinese'].map(str.rstrip)
如果數(shù)據(jù)里有某個(gè)特殊的符號(hào),我們想要?jiǎng)h除怎么辦?同樣可以使用 strip 函數(shù),比如 Chinese 字段里有美元符號(hào),我們想把這個(gè)刪掉,可以這么寫(xiě):
df2['Chinese']=df2['Chinese'].str.strip('$')
(2.5)大小寫(xiě)轉(zhuǎn)換
大小寫(xiě)是個(gè)比較常見(jiàn)的操作,比如人名、城市名等的統(tǒng)一都可能用到大小寫(xiě)的轉(zhuǎn)換,在 Python 里直接使用 upper(), lower(), title() 函數(shù),方法如下:
#全部大寫(xiě)
df2.columns?=?df2.columns.str.upper()
#全部小寫(xiě)
df2.columns?=?df2.columns.str.lower()
#首字母大寫(xiě)
df2.columns?=?df2.columns.str.title()
(2.6)查找空值
數(shù)據(jù)量大的情況下,有些字段存在空值 NaN 的可能,這時(shí)就需要使用 Pandas 中的 isnull 函數(shù)進(jìn)行查找。比如,我們輸入一個(gè)數(shù)據(jù)表如下: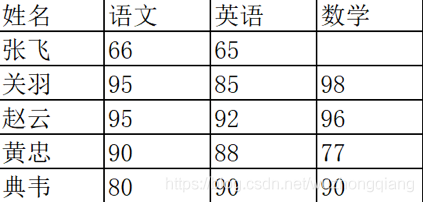
如果我們想看下哪個(gè)地方存在空值 NaN,可以針對(duì)數(shù)據(jù)表 df 進(jìn)行 df.isnull(),結(jié)果如下: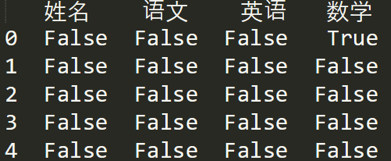
如果我想知道哪列存在空值,可以使用 df.isnull().any(),結(jié)果如下: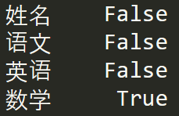
2.2.2 使用apply函數(shù)對(duì)數(shù)據(jù)進(jìn)行清洗
apply 函數(shù)是 Pandas 中自由度非常高的函數(shù),使用頻率也非常高。比如我們想對(duì) name 列的數(shù)值都進(jìn)行大寫(xiě)轉(zhuǎn)化可以用:
df['name']?=?df['name'].apply(str.upper)
我們也可以定義個(gè)函數(shù),在 apply 中進(jìn)行使用。比如定義 double_df 函數(shù)是將原來(lái)的數(shù)值 *2 進(jìn)行返回。然后對(duì) df1 中的“語(yǔ)文”列的數(shù)值進(jìn)行 *2 處理,可以寫(xiě)成:
def?double_df(x):
???????????return?2*x
df1[u'語(yǔ)文']?=?df1[u'語(yǔ)文'].apply(double_df)
我們也可以定義更復(fù)雜的函數(shù),比如對(duì)于 DataFrame,我們新增兩列,其中’new1’列是“語(yǔ)文”和“英語(yǔ)”成績(jī)之和的 m 倍,'new2’列是“語(yǔ)文”和“英語(yǔ)”成績(jī)之和的 n 倍,我們可以這樣寫(xiě):
def?plus(df,n,m):
????df['new1']?=?(df[u'語(yǔ)文']+df[u'英語(yǔ)'])?*?m
????df['new2']?=?(df[u'語(yǔ)文']+df[u'英語(yǔ)'])?*?n
????return?df
df1?=?df1.apply(plus,axis=1,args=(2,3,))
2.3 數(shù)據(jù)統(tǒng)計(jì)
在數(shù)據(jù)清洗后,我們就要對(duì)數(shù)據(jù)進(jìn)行統(tǒng)計(jì)了。Pandas 和 NumPy 一樣,都有常用的統(tǒng)計(jì)函數(shù),如果遇到空值 NaN,會(huì)自動(dòng)排除。常用的統(tǒng)計(jì)函數(shù)包括:
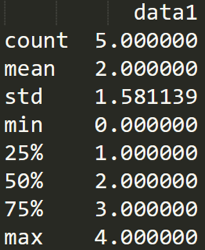
表格中有一個(gè) describe() 函數(shù),統(tǒng)計(jì)函數(shù)千千萬(wàn),describe() 函數(shù)最簡(jiǎn)便。它是個(gè)統(tǒng)計(jì)大禮包,可以快速讓我們對(duì)數(shù)據(jù)有個(gè)全面的了解。下面我直接使用 df1.descirbe() 輸出結(jié)果為:
df1?=?DataFrame({'name':['ZhangFei',?'GuanYu',?'a',?'b',?'c'],?'data1':range(5)})
print?df1.describe()
2.4 數(shù)據(jù)表合并
有時(shí)候我們需要將多個(gè)渠道源的多個(gè)數(shù)據(jù)表進(jìn)行合并,一個(gè) DataFrame 相當(dāng)于一個(gè)數(shù)據(jù)庫(kù)的數(shù)據(jù)表,那么多個(gè) DataFrame 數(shù)據(jù)表的合并就相當(dāng)于多個(gè)數(shù)據(jù)庫(kù)的表合并。
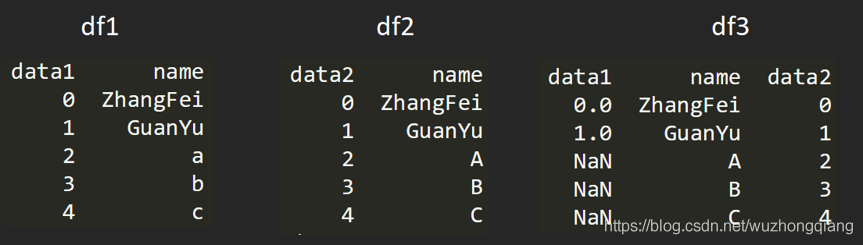
比如我要?jiǎng)?chuàng)建兩個(gè) DataFrame:
df1?=?DataFrame({'name':['ZhangFei',?'GuanYu',?'a',?'b',?'c'],?'data1':range(5)})
df2?=?DataFrame({'name':['ZhangFei',?'GuanYu',?'A',?'B',?'C'],?'data2':range(5)})
兩個(gè) DataFrame 數(shù)據(jù)表的合并使用的是 merge() 函數(shù),有下面 5 種形式:
比如我們可以基于 name 這列進(jìn)行連接。基于指定列進(jìn)行連接
df3?=?pd.merge(df1,?df2,?on='name')

2. inner內(nèi)連接
inner 內(nèi)鏈接是 merge 合并的默認(rèn)情況,inner 內(nèi)連接其實(shí)也就是鍵的交集,在這里 df1, df2 相同的鍵是 name,所以是基于 name 字段做的連接:
df3?=?pd.merge(df1,?df2,?how='inner')
3. left左連接
左連接是以第一個(gè) DataFrame 為主進(jìn)行的連接,第二個(gè) DataFrame 作為補(bǔ)充。
df3?=?pd.merge(df1,?df2,?how='left')
右連接是以第二個(gè) DataFrame 為主進(jìn)行的連接,第一個(gè) DataFrame 作為補(bǔ)充。right右連接
df3?=?pd.merge(df1,?df2,?how='right')
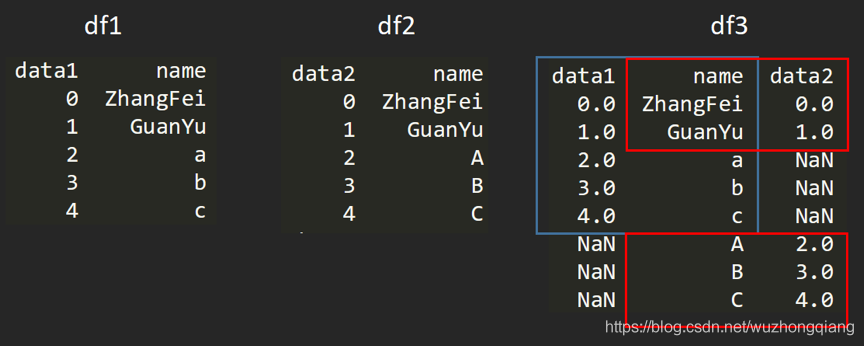
5. outer外連接
外連接相當(dāng)于求兩個(gè) DataFrame 的并集。
df3?=?pd.merge(df1,?df2,?how='outer')
2.5 DataFram的行級(jí)遍歷
盡管 Pandas 已經(jīng)盡可能向量化,讓使用者盡可能避免 for 循環(huán),但是有時(shí)不得已,還得要遍歷 DataFrame。Pandas 提供 iterrows、itertuples 兩種行級(jí)遍歷。
使用
iterrows遍歷打印所有行,在 IPython 里輸入以下行:def?iterrows_time(df):
for?i,row?in?df.iterrows():
????print(row)訪(fǎng)問(wèn)每一行某個(gè)元素的時(shí)候, 可以通過(guò)列名直接訪(fǎng)問(wèn):

使用
itertuples遍歷打印每行:def?itertuples_time(df):
for?nt?in?df.itertuples():
????print(nt)這個(gè)效率更高, 比上面那個(gè)節(jié)省6倍多的時(shí)間, 所在數(shù)據(jù)量非常大的時(shí)候, 推薦后者。訪(fǎng)問(wèn)每一行某個(gè)元素的時(shí)候, 需要
getattr函數(shù)
使用
iteritems遍歷每一行這個(gè)訪(fǎng)問(wèn)每一行元素的時(shí)候, 用的是每一列的數(shù)字索引

3. 如何用SQL方式打開(kāi)Pandas
Pandas 的 DataFrame 數(shù)據(jù)類(lèi)型可以讓我們像處理數(shù)據(jù)表一樣進(jìn)行操作,比如數(shù)據(jù)表的增刪改查,都可以用 Pandas 工具來(lái)完成。不過(guò)也會(huì)有很多人記不住這些 Pandas 的命令,相比之下還是用 SQL 語(yǔ)句更熟練,用 SQL 對(duì)數(shù)據(jù)表進(jìn)行操作是最方便的,它的語(yǔ)句描述形式更接近我們的自然語(yǔ)言。
事實(shí)上,在 Python 里可以直接使用 SQL 語(yǔ)句來(lái)操作 Pandas。
這里給你介紹個(gè)工具:pandasql。
pandasql 中的主要函數(shù)是 sqldf,它接收兩個(gè)參數(shù):一個(gè) SQL 查詢(xún)語(yǔ)句,還有一組環(huán)境變量 globals() 或 locals()。這樣我們就可以在 Python 里,直接用 SQL 語(yǔ)句中對(duì) DataFrame 進(jìn)行操作,舉個(gè)例子:
import?pandas?as?pd
from?pandas?import?DataFrame
from?pandasql?import?sqldf,?load_meat,?load_births
df1?=?DataFrame({'name':['ZhangFei',?'GuanYu',?'a',?'b',?'c'],?'data1':range(5)})
pysqldf?=?lambda?sql:?sqldf(sql,?globals())
sql?=?"select?*?from?df1?where?name?='ZhangFei'"
print?pysqldf(sql)
運(yùn)行結(jié)果
???data1??????name
0??????0??ZhangFei
上面代碼中,定義了:
pysqldf?=?lambda?sql:?sqldf(sql,?globals())
在這個(gè)例子里,輸入的參數(shù)是 sql,返回的結(jié)果是 sqldf 對(duì) sql 的運(yùn)行結(jié)果,當(dāng)然 sqldf 中也輸入了 globals 全局參數(shù),因?yàn)樵?sql 中有對(duì)全局參數(shù) df1 的使用。
參考
極客時(shí)間《數(shù)據(jù)分析實(shí)戰(zhàn)45講》課程:https://time.geekbang.org/ Pandas的基本使用:http://note.youdao.com/noteshare?id=28264a6b8536e4448e0bf3de701cd230&sub=25080C078C444E6E8B0C809C88BD0C76 python數(shù)據(jù)分析實(shí)用小抄:https://www.cnblogs.com/nxld/p/6687253.html 像Excel一樣使用python進(jìn)行數(shù)據(jù)分析:https://www.cnblogs.com/nxld/p/6756492.html 50道練習(xí)帶你玩轉(zhuǎn)Pandas:https://mp.weixin.qq.com/s/39yPBJ7DWSMs_aIxtlpXCw AI基礎(chǔ):Pandas簡(jiǎn)易入門(mén):https://mp.weixin.qq.com/s/uLBJc_iIize8a9B491U7VQ Pandas常用用法:https://www.freesion.com/article/7330378876/
- END -
機(jī)??器學(xué)習(xí)算法交流群,邀您加入!!!
入群:提問(wèn)求助;認(rèn)識(shí)行業(yè)內(nèi)同學(xué),交流進(jìn)步;共享資源...
掃描??下方二維碼,備注“加群”
整理不易,點(diǎn)贊三連↓