
Kubernetes容量規(guī)劃 | 如何調(diào)整集群的資源占用
Kubernetes 容量規(guī)劃是基礎(chǔ)架構(gòu)工程師必須面對的主要挑戰(zhàn)之一,因為了解 Kubernetes 的資源要求和限制并非易事。
您可能預(yù)留了更多的資源,以確保容器不會用完內(nèi)存或受到 CPU 限制。如果您處于這種情況,那么即使不使用這些資源,也要向云廠商付費,這也將使調(diào)度變得更加困難。這就是為什么 Kubernetes 容量規(guī)劃始終是集群的穩(wěn)定性和可靠性與正確使用資源之間的平衡。
在本文中,您將學(xué)習(xí)如何識別未使用的資源以及如何合理分配群集的容量。
不要成為貪婪的開發(fā)者
在某些情況下,容器需要的資源超出了限制。如果只是一個容器,它可能不會對您的賬戶產(chǎn)生重大影響。但是,如果所有容器中都發(fā)生這種情況,則在大型群集中將產(chǎn)生幾筆額外費用。
更不用說 Pod 占用資源太大,這可能需要你會花費更多的精力來發(fā)現(xiàn)占用資源過多的問題。畢竟,對于 Kubernetes 來說,占用資源過多的 Pod 調(diào)度起來相對困難。
介紹兩個開源工具來幫助您進(jìn)行 Kubernetes 的容量規(guī)劃:
kube-state-metrics:一個附加代理,用于生成和公開集群級別的指標(biāo)。 CAdvisor:容器的資源使用分析器。
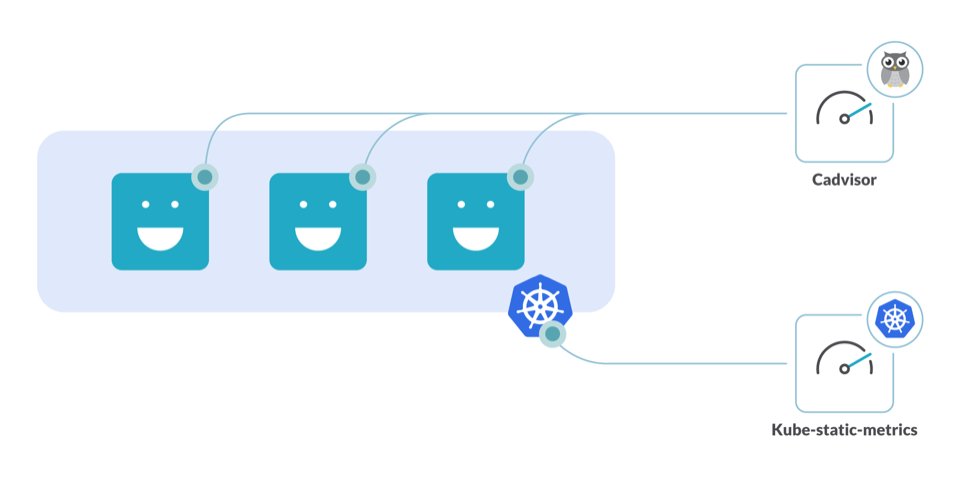
通過在群集中運行這些工具,您將能夠避免資源利用不足并調(diào)整群集資源占用的大小。
如何檢測未充分利用的資源
CPU
CPU 資源占用是最難調(diào)整的閾值之一,如果調(diào)整的太小可能限制服務(wù)的計算能力,如果調(diào)整的太大又會造成該節(jié)點多數(shù)計算資源處于空閑狀態(tài)。
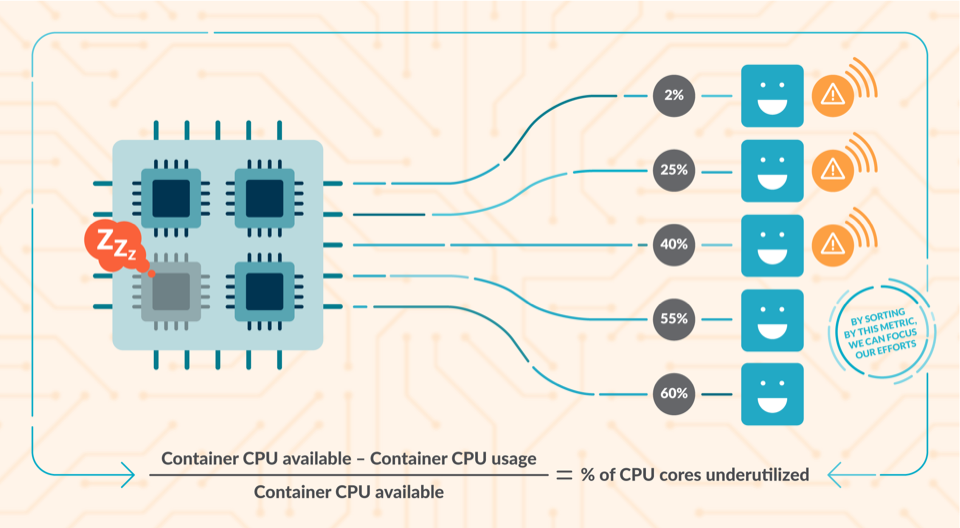
檢測空閑 CPU 資源
利用給出的container_cpu_usage_seconds_total、kube_pod_container_resource_requests參數(shù),可以檢測到 CPU 核心利用情況。
sum((rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[30m]) - on (namespace,pod,container) group_left avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="cpu"})) * -1 >0)
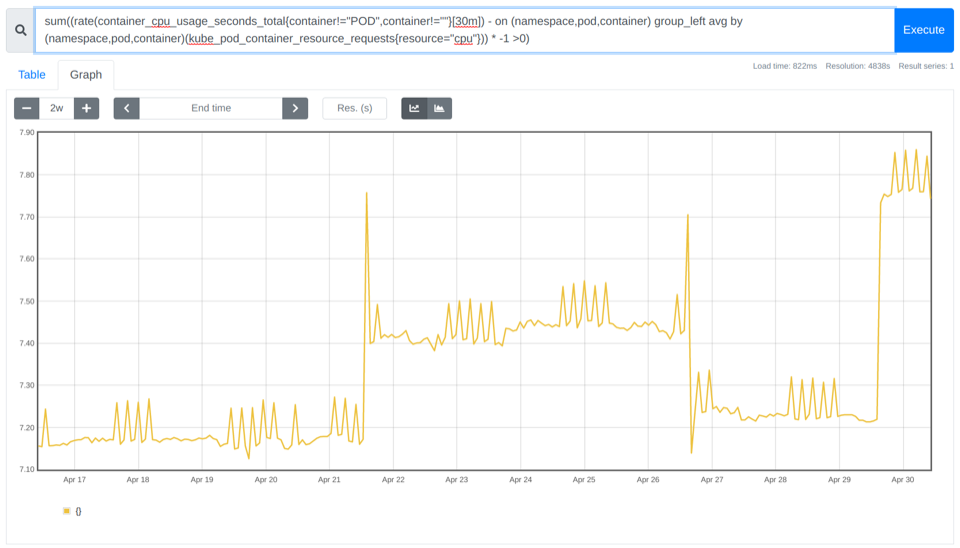 在上面的示例中,您可以看到在~7.10 和~7.85 之間沒有使用內(nèi)核。
在上面的示例中,您可以看到在~7.10 和~7.85 之間沒有使用內(nèi)核。
如何識別那些命名空間浪費了更多的 CPU 內(nèi)核
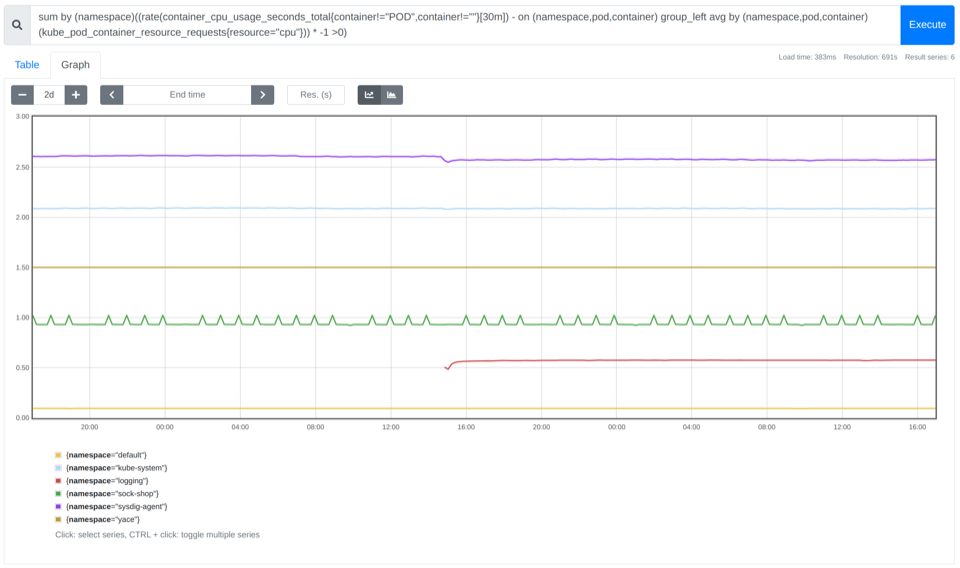
通過使用 PromQL 按名稱空間匯總過去的查詢,您可以獲得更細(xì)粒度的使用情況。通過這些信息,使您能夠向超大命名空間而且不充分利用資源的部門算賬。
sum by (namespace)((rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[30m]) - on (namespace,pod,container) group_left avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="cpu"})) * -1 >0)
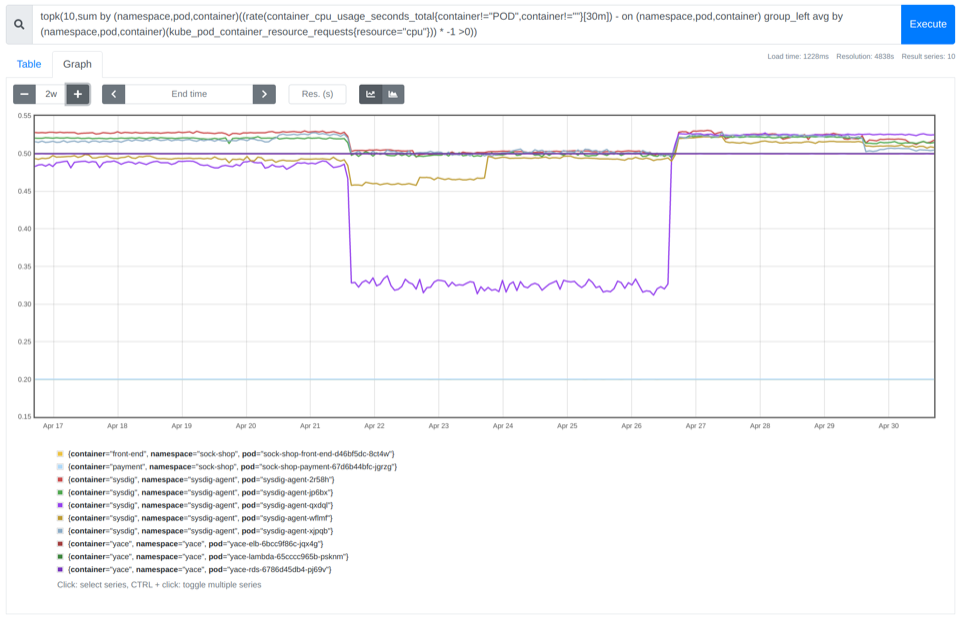
查找 CPU 占用前 10 的容器
正如我們在 PromQL 入門指南中介紹的那樣,您可以使用該 topk 函數(shù)輕松獲取 PromQL 查詢的最佳結(jié)果。像這樣:
topk(10,sum by (namespace,pod,container)((rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[30m]) - on (namespace,pod,container) group_left avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="cpu"})) * -1 >0))
內(nèi)存
正確進(jìn)行內(nèi)存規(guī)劃至關(guān)重要。如果您內(nèi)存使用率過高,則該節(jié)點將在內(nèi)存不足時開始逐出 Pod。但是內(nèi)存也是有限的,因此設(shè)置越好,每個節(jié)點可以容納的 Pod 就越多。
檢測未使用的內(nèi)存
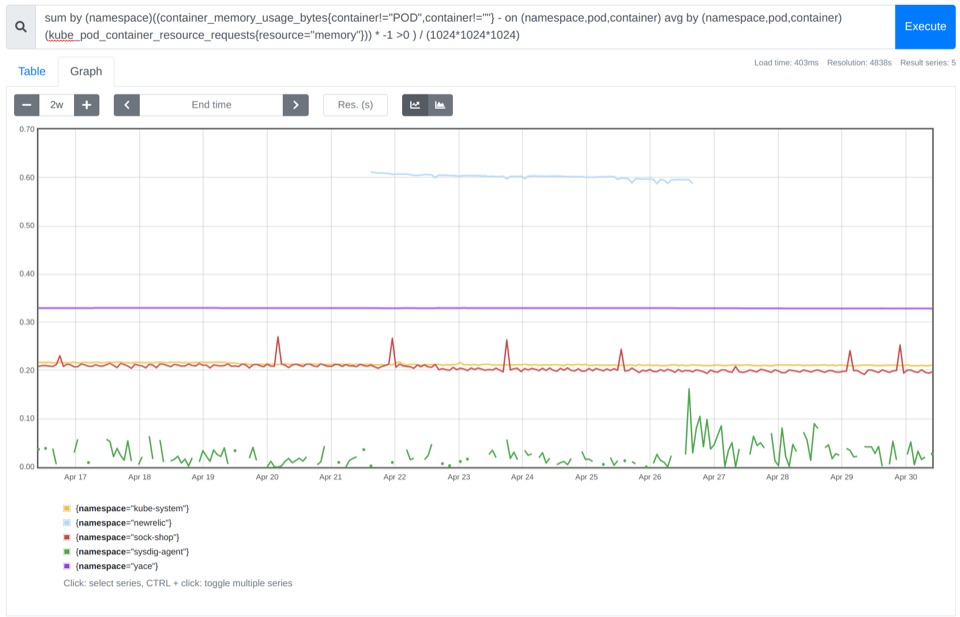
您可以使用container_memory_usage_bytes、kube_pod_container_resource_requests查看您浪費了多少內(nèi)存。
sum((container_memory_usage_bytes{container!="POD",container!=""} - on (namespace,pod,container) avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="memory"})) * -1 >0 ) / (1024*1024*1024)

在上面的示例中,您可以看到可以為該集群節(jié)省 0.8gb 的成本。
如何識別哪些命名空間浪費了更多的內(nèi)存
就像我們使用 CPU 一樣,我們可以按命名空間進(jìn)行聚合。
sum by (namespace)((container_memory_usage_bytes{container!="POD",container!=""} - on (namespace,pod,container) avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="memory"})) * -1 >0 ) / (1024*1024*1024)
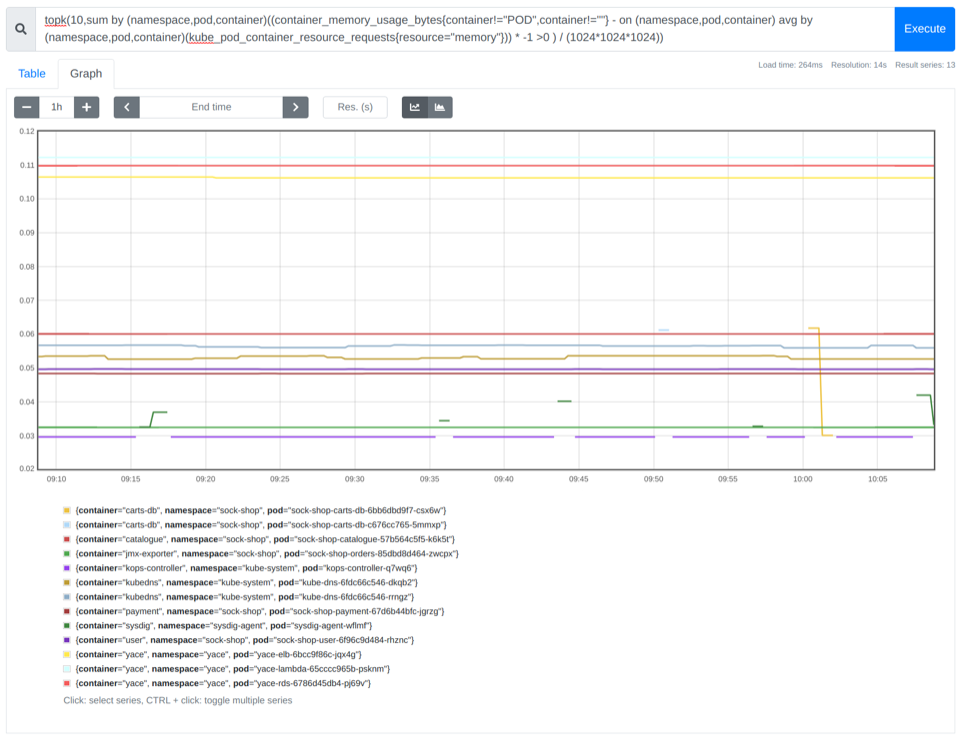
查找內(nèi)存過大的前 10 個容器
同樣,使用該 topk 函數(shù),我們可以確定在每個命名空間內(nèi)浪費更多內(nèi)存的前 10 個容器。
topk(10,sum by (namespace,pod,container)((container_memory_usage_bytes{container!="POD",container!=""} - on (namespace,pod,container) avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="memory"})) * -1 >0 ) / (1024*1024*1024))
如何對容器的資源利用進(jìn)行優(yōu)化
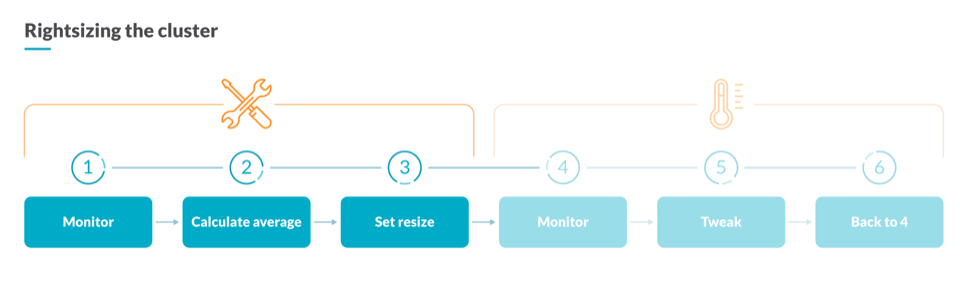
在 Kubernetes 容量規(guī)劃中,要保留足夠的計算資源,您需要分析容器的當(dāng)前資源使用情況。為此,您可以使用此 PromQL 查詢來計算屬于同一工作負(fù)載的所有容器的平均 CPU 利用率。將工作負(fù)載理解為Deployment、StatefulSet、DaemonSet。
avg by (namespace,owner_name,container)((rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m])) * on(namespace,pod) group_left(owner_name) avg by (namespace,pod,owner_name)(kube_pod_owner{owner_kind=~"DaemonSet|StatefulSet|Deployment"}))
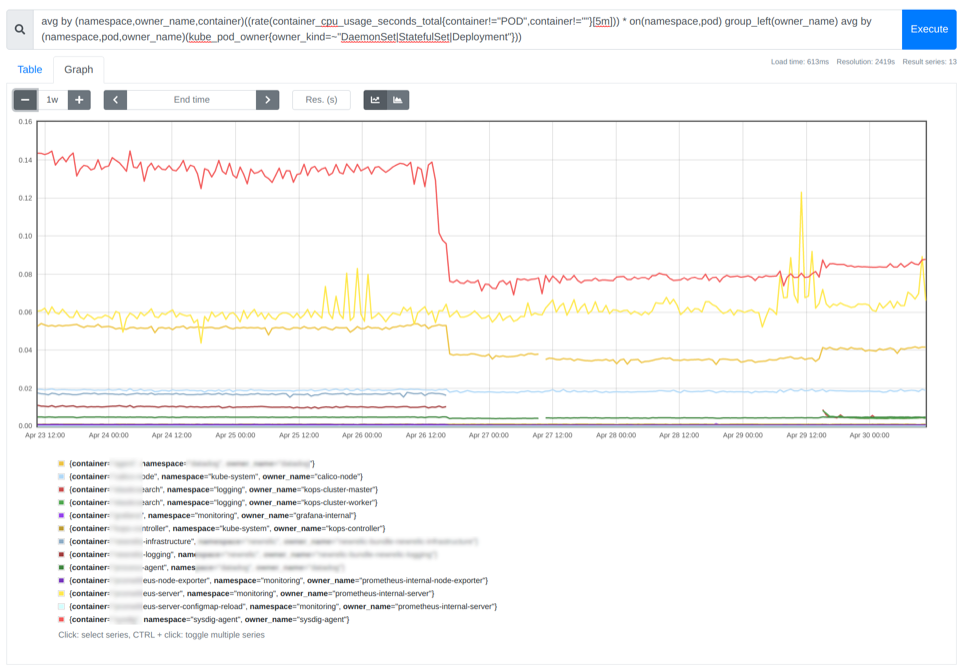
在上圖中,您可以看到每個容器的平均 CPU 利用率。根據(jù)經(jīng)驗,可以將容器的 Request 設(shè)置為 CPU 或內(nèi)存平均使用率的 85%到 115%之間的值。
如何衡量優(yōu)化的影響
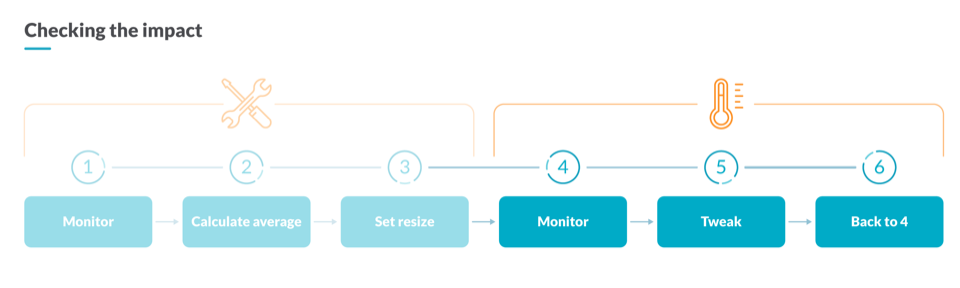
在執(zhí)行了一些 Kubernetes 容量規(guī)劃操作之后,您需要檢查更改對基礎(chǔ)架構(gòu)的影響。為此,您可以將未充分利用的 CPU 內(nèi)核現(xiàn)在與一周前的值進(jìn)行比較,以評估優(yōu)化后的影響。
sum((rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[30m]) - on (namespace,pod,container) group_left avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="cpu"})) * -1 >0) - sum((rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[30m] offset 1w) - on (namespace,pod,container) group_left avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="cpu"} offset 1w )) * -1 >0)
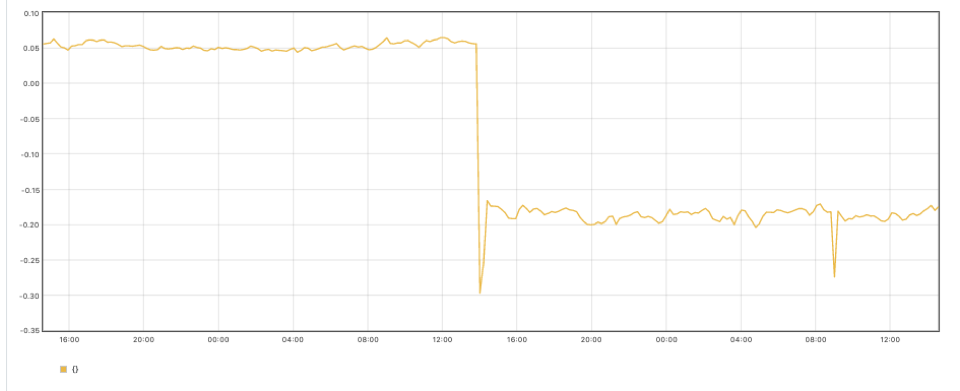
在上圖中,您可以看到優(yōu)化之后,集群中未使用的 CPU 更少了。
總結(jié)
現(xiàn)在您知道了貪婪的開發(fā)者的后果以及如何檢測平臺資源的過度分配。此外,您還學(xué)習(xí)了如何對容器的請求進(jìn)行容量設(shè)置以及如何衡量優(yōu)化的影響。
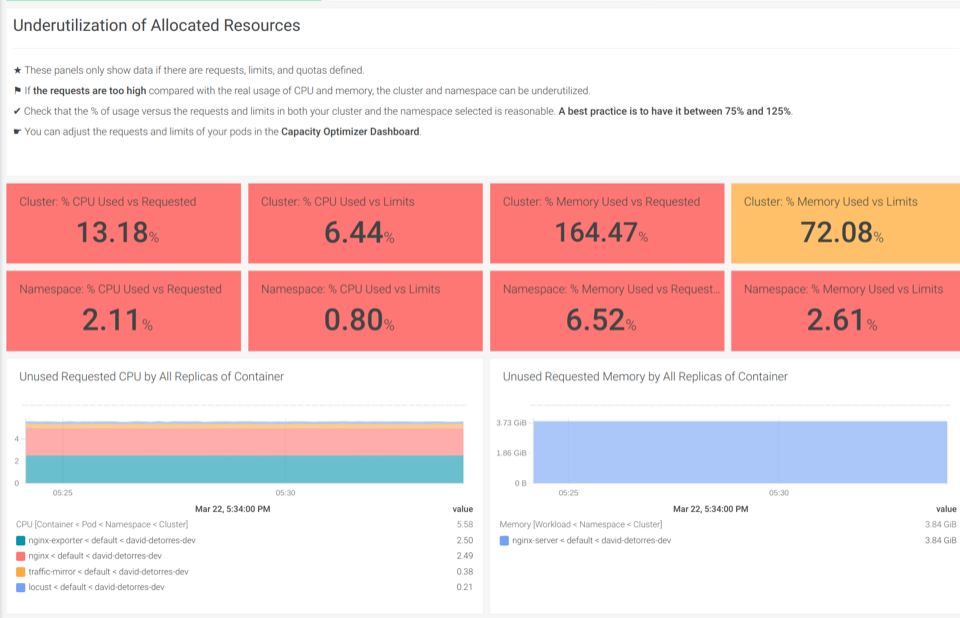
這些技巧應(yīng)該是構(gòu)建全面的 Kubernetes 容量規(guī)劃儀表板的良好起點,并獲得包含優(yōu)化平臺資源所需的單一面板。
更多文檔請參考 [1][2][3][4]
參考資料
度量工具: https://github.com/kubernetes/kube-state-metrics
[2]度量工具: https://github.com/google/cadvisor
[3]PromQL: https://sysdig.com/blog/getting-started-with-promql-cheatsheet/
[4]內(nèi)存不足的錯誤: https://sysdig.com/blog/troubleshoot-kubernetes-oom/
關(guān)注「開源Linux」加星標(biāo),提升IT技能
