
【154期】面試官:你能說說 Elasticsearch 查詢數(shù)據(jù)的工作原理是什么嗎?

閱讀本文大概需要 7 分鐘。
來自:https://doocs.gitee.io/#/
面試題
ES 寫入數(shù)據(jù)的工作原理是什么啊?ES 查詢數(shù)據(jù)的工作原理是什么啊?底層的 Lucene 介紹一下唄?倒排索引了解嗎?
面試官心理分析
問這個,其實(shí)面試官就是要看看你了解不了解 es 的一些基本原理,因?yàn)橛?es 無非就是寫入數(shù)據(jù),搜索數(shù)據(jù)。你要是不明白你發(fā)起一個寫入和搜索請求的時候,es 在干什么,那你真的是......
對 es 基本就是個黑盒,你還能干啥?你唯一能干的就是用 es 的 api 讀寫數(shù)據(jù)了。要是出點(diǎn)什么問題,你啥都不知道,那還能指望你什么呢?
面試題剖析
es 寫數(shù)據(jù)過程
客戶端選擇一個 node 發(fā)送請求過去,這個 node 就是 coordinating node(協(xié)調(diào)節(jié)點(diǎn))。coordinating node對 document 進(jìn)行路由,將請求轉(zhuǎn)發(fā)給對應(yīng)的 node(有 primary shard)。實(shí)際的 node 上的 primary shard處理請求,然后將數(shù)據(jù)同步到replica node。coordinating node如果發(fā)現(xiàn)primary node和所有replica node都搞定之后,就返回響應(yīng)結(jié)果給客戶端。
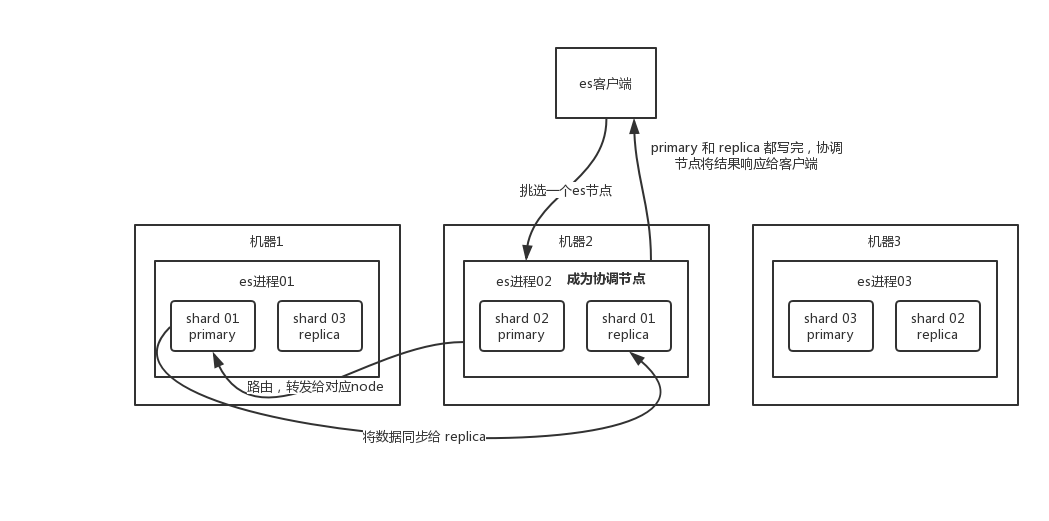
es 讀數(shù)據(jù)過程
可以通過 doc id 來查詢,會根據(jù) doc id 進(jìn)行 hash,判斷出來當(dāng)時把 doc id 分配到了哪個 shard 上面去,從那個 shard 去查詢。
客戶端發(fā)送請求到任意一個 node,成為 coordinate node。coordinate node對doc id進(jìn)行哈希路由,將請求轉(zhuǎn)發(fā)到對應(yīng)的 node,此時會使用round-robin隨機(jī)輪詢算法,在primary shard以及其所有 replica 中隨機(jī)選擇一個,讓讀請求負(fù)載均衡。接收請求的 node 返回 document 給 coordinate node。coordinate node返回 document 給客戶端。
es 搜索數(shù)據(jù)過程
es 最強(qiáng)大的是做全文檢索,就是比如你有三條數(shù)據(jù):
java真好玩兒啊
java好難學(xué)啊
j2ee特別牛Copy to clipboardErrorCopied
你根據(jù) java 關(guān)鍵詞來搜索,將包含 java 的 document 給搜索出來。es 就會給你返回:java真好玩兒啊,java好難學(xué)啊。
客戶端發(fā)送請求到一個 coordinate node。協(xié)調(diào)節(jié)點(diǎn)將搜索請求轉(zhuǎn)發(fā)到所有的 shard 對應(yīng)的 primary shard或replica shard,都可以。query phase:每個 shard 將自己的搜索結(jié)果(其實(shí)就是一些 doc id)返回給協(xié)調(diào)節(jié)點(diǎn),由協(xié)調(diào)節(jié)點(diǎn)進(jìn)行數(shù)據(jù)的合并、排序、分頁等操作,產(chǎn)出最終結(jié)果。fetch phase:接著由協(xié)調(diào)節(jié)點(diǎn)根據(jù) doc id去各個節(jié)點(diǎn)上拉取實(shí)際的document數(shù)據(jù),最終返回給客戶端。
寫請求是寫入 primary shard,然后同步給所有的 replica shard;讀請求可以從 primary shard 或 replica shard 讀取,采用的是隨機(jī)輪詢算法。
寫數(shù)據(jù)底層原理

先寫入內(nèi)存 buffer,在 buffer 里的時候數(shù)據(jù)是搜索不到的;同時將數(shù)據(jù)寫入 translog 日志文件。
如果 buffer 快滿了,或者到一定時間,就會將內(nèi)存 buffer 數(shù)據(jù) refresh 到一個新的 segment file 中,但是此時數(shù)據(jù)不是直接進(jìn)入 segment file 磁盤文件,而是先進(jìn)入 os cache 。這個過程就是 refresh 。
每隔 1 秒鐘,es 將 buffer 中的數(shù)據(jù)寫入一個新的 segment file ,每秒鐘會產(chǎn)生一個新的磁盤文件 segment file ,這個 segment file 中就存儲最近 1 秒內(nèi) buffer 中寫入的數(shù)據(jù)。
但是如果 buffer 里面此時沒有數(shù)據(jù),那當(dāng)然不會執(zhí)行 refresh 操作,如果 buffer 里面有數(shù)據(jù),默認(rèn) 1 秒鐘執(zhí)行一次 refresh 操作,刷入一個新的 segment file 中。
操作系統(tǒng)里面,磁盤文件其實(shí)都有一個東西,叫做 os cache ,即操作系統(tǒng)緩存,就是說數(shù)據(jù)寫入磁盤文件之前,會先進(jìn)入 os cache ,先進(jìn)入操作系統(tǒng)級別的一個內(nèi)存緩存中去。只要 buffer 中的數(shù)據(jù)被 refresh 操作刷入 os cache 中,這個數(shù)據(jù)就可以被搜索到了。
為什么叫 es 是準(zhǔn)實(shí)時的?NRT ,全稱 near real-time 。默認(rèn)是每隔 1 秒 refresh 一次的,所以 es 是準(zhǔn)實(shí)時的,因?yàn)閷懭氲臄?shù)據(jù) 1 秒之后才能被看到。可以通過 es 的 restful api 或者 java api ,手動執(zhí)行一次 refresh 操作,就是手動將 buffer 中的數(shù)據(jù)刷入 os cache 中,讓數(shù)據(jù)立馬就可以被搜索到。只要數(shù)據(jù)被輸入 os cache 中,buffer 就會被清空了,因?yàn)椴恍枰A?buffer 了,數(shù)據(jù)在 translog 里面已經(jīng)持久化到磁盤去一份了。
重復(fù)上面的步驟,新的數(shù)據(jù)不斷進(jìn)入 buffer 和 translog,不斷將 buffer 數(shù)據(jù)寫入一個又一個新的 segment file 中去,每次 refresh 完 buffer 清空,translog 保留。隨著這個過程推進(jìn),translog 會變得越來越大。當(dāng) translog 達(dá)到一定長度的時候,就會觸發(fā) commit 操作。
commit 操作發(fā)生第一步,就是將 buffer 中現(xiàn)有數(shù)據(jù) refresh 到 os cache 中去,清空 buffer。然后,將一個 commit point 寫入磁盤文件,里面標(biāo)識著這個 commit point 對應(yīng)的所有 segment file ,同時強(qiáng)行將 os cache 中目前所有的數(shù)據(jù)都 fsync 到磁盤文件中去。最后清空 現(xiàn)有 translog 日志文件,重啟一個 translog,此時 commit 操作完成。
這個 commit 操作叫做 flush 。默認(rèn) 30 分鐘自動執(zhí)行一次 flush ,但如果 translog 過大,也會觸發(fā) flush 。flush 操作就對應(yīng)著 commit 的全過程,我們可以通過 es api,手動執(zhí)行 flush 操作,手動將 os cache 中的數(shù)據(jù) fsync 強(qiáng)刷到磁盤上去。
translog 日志文件的作用是什么?你執(zhí)行 commit 操作之前,數(shù)據(jù)要么是停留在 buffer 中,要么是停留在 os cache 中,無論是 buffer 還是 os cache 都是內(nèi)存,一旦這臺機(jī)器死了,內(nèi)存中的數(shù)據(jù)就全丟了。所以需要將數(shù)據(jù)對應(yīng)的操作寫入一個專門的日志文件 translog 中,一旦此時機(jī)器宕機(jī),再次重啟的時候,es 會自動讀取 translog 日志文件中的數(shù)據(jù),恢復(fù)到內(nèi)存 buffer 和 os cache 中去。
translog 其實(shí)也是先寫入 os cache 的,默認(rèn)每隔 5 秒刷一次到磁盤中去,所以默認(rèn)情況下,可能有 5 秒的數(shù)據(jù)會僅僅停留在 buffer 或者 translog 文件的 os cache 中,如果此時機(jī)器掛了,會丟失 5 秒鐘的數(shù)據(jù)。但是這樣性能比較好,最多丟 5 秒的數(shù)據(jù)。也可以將 translog 設(shè)置成每次寫操作必須是直接 fsync 到磁盤,但是性能會差很多。
實(shí)際上你在這里,如果面試官沒有問你 es 丟數(shù)據(jù)的問題,你可以在這里給面試官炫一把,你說,其實(shí) es 第一是準(zhǔn)實(shí)時的,數(shù)據(jù)寫入 1 秒后可以搜索到;可能會丟失數(shù)據(jù)的。有 5 秒的數(shù)據(jù),停留在 buffer、translog os cache、segment file os cache 中,而不在磁盤上,此時如果宕機(jī),會導(dǎo)致 5 秒的數(shù)據(jù)丟失。
總結(jié)一下,數(shù)據(jù)先寫入內(nèi)存 buffer,然后每隔 1s,將數(shù)據(jù) refresh 到 os cache,到了 os cache 數(shù)據(jù)就能被搜索到(所以我們才說 es 從寫入到能被搜索到,中間有 1s 的延遲)。每隔 5s,將數(shù)據(jù)寫入 translog 文件(這樣如果機(jī)器宕機(jī),內(nèi)存數(shù)據(jù)全沒,最多會有 5s 的數(shù)據(jù)丟失),translog 大到一定程度,或者默認(rèn)每隔 30mins,會觸發(fā) commit 操作,將緩沖區(qū)的數(shù)據(jù)都 flush 到 segment file 磁盤文件中。
數(shù)據(jù)寫入 segment file 之后,同時就建立好了倒排索引。
刪除/更新數(shù)據(jù)底層原理
如果是刪除操作,commit 的時候會生成一個 .del 文件,里面將某個 doc 標(biāo)識為 deleted 狀態(tài),那么搜索的時候根據(jù) .del 文件就知道這個 doc 是否被刪除了。
如果是更新操作,就是將原來的 doc 標(biāo)識為 deleted 狀態(tài),然后新寫入一條數(shù)據(jù)。
buffer 每 refresh 一次,就會產(chǎn)生一個 segment file ,所以默認(rèn)情況下是 1 秒鐘一個 segment file ,這樣下來 segment file 會越來越多,此時會定期執(zhí)行 merge。每次 merge 的時候,會將多個 segment file 合并成一個,同時這里會將標(biāo)識為 deleted 的 doc 給物理刪除掉,然后將新的 segment file 寫入磁盤,這里會寫一個 commit point ,標(biāo)識所有新的 segment file ,然后打開 segment file 供搜索使用,同時刪除舊的 segment file 。
底層 lucene
簡單來說,lucene 就是一個 jar 包,里面包含了封裝好的各種建立倒排索引的算法代碼。我們用 Java 開發(fā)的時候,引入 lucene jar,然后基于 lucene 的 api 去開發(fā)就可以了。
通過 lucene,我們可以將已有的數(shù)據(jù)建立索引,lucene 會在本地磁盤上面,給我們組織索引的數(shù)據(jù)結(jié)構(gòu)。
倒排索引
在搜索引擎中,每個文檔都有一個對應(yīng)的文檔 ID,文檔內(nèi)容被表示為一系列關(guān)鍵詞的集合。例如,文檔 1 經(jīng)過分詞,提取了 20 個關(guān)鍵詞,每個關(guān)鍵詞都會記錄它在文檔中出現(xiàn)的次數(shù)和出現(xiàn)位置。
那么,倒排索引就是關(guān)鍵詞到文檔 ID 的映射,每個關(guān)鍵詞都對應(yīng)著一系列的文件,這些文件中都出現(xiàn)了關(guān)鍵詞。
舉個栗子。
有以下文檔:
| DocId | Doc |
|---|---|
| 1 | 谷歌地圖之父跳槽 Facebook |
| 2 | 谷歌地圖之父加盟 Facebook |
| 3 | 谷歌地圖創(chuàng)始人拉斯離開谷歌加盟 Facebook |
| 4 | 谷歌地圖之父跳槽 Facebook 與 Wave 項(xiàng)目取消有關(guān) |
| 5 | 谷歌地圖之父拉斯加盟社交網(wǎng)站 Facebook |
對文檔進(jìn)行分詞之后,得到以下倒排索引。
| WordId | Word | DocIds |
|---|---|---|
| 1 | 谷歌 | 1, 2, 3, 4, 5 |
| 2 | 地圖 | 1, 2, 3, 4, 5 |
| 3 | 之父 | 1, 2, 4, 5 |
| 4 | 跳槽 | 1, 4 |
| 5 | 1, 2, 3, 4, 5 | |
| 6 | 加盟 | 2, 3, 5 |
| 7 | 創(chuàng)始人 | 3 |
| 8 | 拉斯 | 3, 5 |
| 9 | 離開 | 3 |
| 10 | 與 | 4 |
| .. | .. | .. |
另外,實(shí)用的倒排索引還可以記錄更多的信息,比如文檔頻率信息,表示在文檔集合中有多少個文檔包含某個單詞。
那么,有了倒排索引,搜索引擎可以很方便地響應(yīng)用戶的查詢。比如用戶輸入查詢 Facebook ,搜索系統(tǒng)查找倒排索引,從中讀出包含這個單詞的文檔,這些文檔就是提供給用戶的搜索結(jié)果。
要注意倒排索引的兩個重要細(xì)節(jié):
倒排索引中的所有詞項(xiàng)對應(yīng)一個或多個文檔; 倒排索引中的詞項(xiàng)根據(jù)字典順序升序排列
上面只是一個簡單的例子,并沒有嚴(yán)格按照字典順序升序排列。
推薦閱讀:
【153期】面試官:談?wù)劤S玫腁rraylist和Linkedlist的區(qū)別
【152期】面試官:你能說出MySQL主從復(fù)制的幾種復(fù)制方式嗎?
【151期】談?wù)?ZooKeeper 的定位:能解決什么問題?不能解決什么問題?
微信掃描二維碼,關(guān)注我的公眾號
朕已閱 