
用 Python 爬取 QQ 空間說說和相冊(cè)

文 |?某某白米飯
來源:Python 技術(shù)「ID: pythonall」
感分割線") QQ 空間在 2005 年被騰訊開發(fā),已經(jīng)經(jīng)歷了 15 個(gè)年頭,在還沒有微信的年代,看網(wǎng)友發(fā)表的心情、心事、照片大多都在 QQ 空間的里。它承載了80、90 后的大量青春,下面我們一起用 selenium 模塊導(dǎo)出說說和相冊(cè)回憶青春吧
QQ 空間在 2005 年被騰訊開發(fā),已經(jīng)經(jīng)歷了 15 個(gè)年頭,在還沒有微信的年代,看網(wǎng)友發(fā)表的心情、心事、照片大多都在 QQ 空間的里。它承載了80、90 后的大量青春,下面我們一起用 selenium 模塊導(dǎo)出說說和相冊(cè)回憶青春吧
安裝 selenium
selenium 是一個(gè)在瀏覽器中運(yùn)行,以模擬用戶操作瀏覽器的方式獲取網(wǎng)頁源碼,使用 pip 安裝 selenium 模塊
pip?install?selenium
查看 chrome 瀏覽器版本并下載 對(duì)應(yīng)的 chrome 瀏覽器驅(qū)動(dòng)
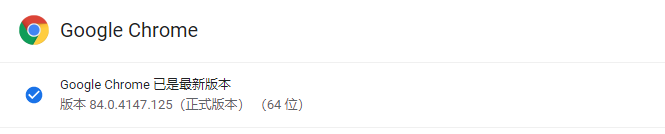
在 http://npm.taobao.org/mirrors/chromedriver 網(wǎng)址中找到相同版本的 chrome 驅(qū)動(dòng),并放在 python 程序運(yùn)行的同一個(gè)文件夾中
登陸
按 F12 檢擦網(wǎng)頁源代碼,找到登錄和密碼的文本框,如下圖所示
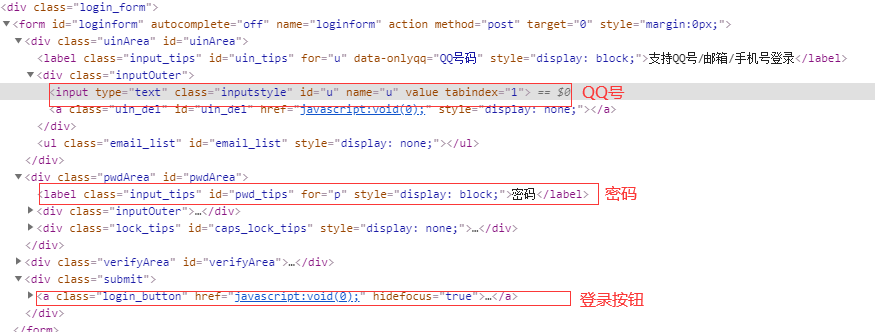
def?login(login_qq,password,?business_qq):
????'''
????登陸
????:param?login_qq:?登陸用的QQ
????:param?password:?登陸的QQ密碼
????:param?business_qq:?業(yè)務(wù)QQ
????:return:?driver
????'''
????driver?=?webdriver.Chrome()
????driver.get('https://user.qzone.qq.com/{}/311'.format(business_qq))??#?URL
????driver.implicitly_wait(10)??#?隱示等待,為了等待充分加載好網(wǎng)址
????driver.find_element_by_id('login_div')
????driver.switch_to.frame('login_frame')??#?切到輸入賬號(hào)密碼的frame
????driver.find_element_by_id('switcher_plogin').click()??##點(diǎn)擊‘賬號(hào)密碼登錄’
????driver.find_element_by_id('u').clear()??##清空賬號(hào)欄
????driver.find_element_by_id('u').send_keys(login_qq)??#?輸入賬號(hào)
????driver.find_element_by_id('p').clear()??#?清空密碼欄
????driver.find_element_by_id('p').send_keys(password)??#?輸入密碼
????driver.find_element_by_id('login_button').click()??#?點(diǎn)擊‘登錄’
????driver.switch_to.default_content()
????driver.implicitly_wait(10)
????time.sleep(5)
????try:
????????driver.find_element_by_id('QM_OwnerInfo_Icon')
????????return?driver
????except:
????????print('不能訪問'?+?business_qq)
????????return?None
說說
登錄 QQ 后默認(rèn)的頁面就在說說的界面,顯示一頁的說說是滾動(dòng)加載的,必須要多次下拉滾動(dòng)條后才能獲取到該頁所有的說說,然后用 BeautifulSoup 模塊構(gòu)建對(duì)象解析頁面,下圖是放說說的 iframe
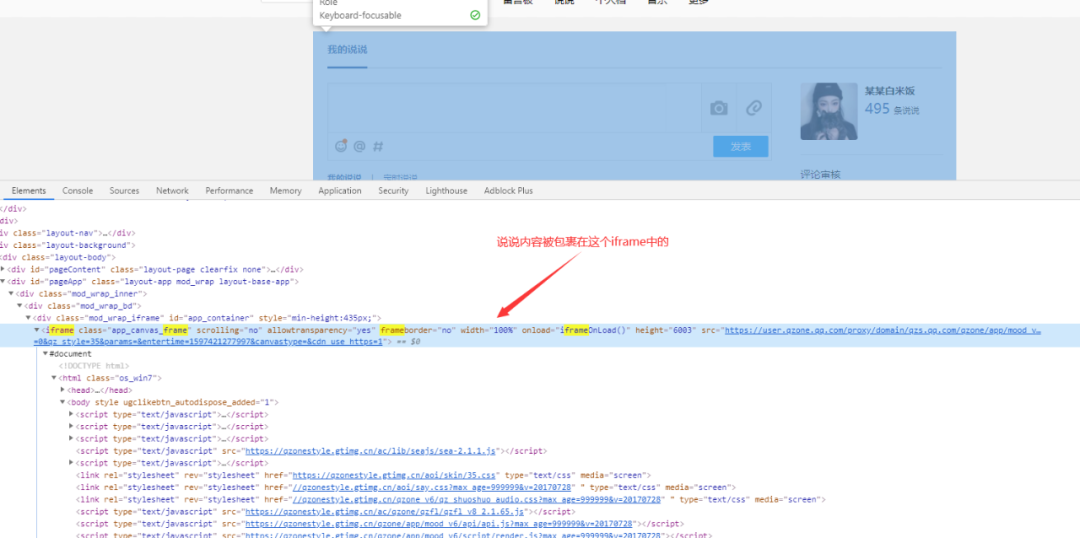
def?get_shuoshuo(driver):
????
????page?=?1
????while?True:
????????#?下拉滾動(dòng)條
????????for?j?in?range(1,?5):
????????????driver.execute_script("window.scrollBy(0,5000)")
????????????time.sleep(2)
????????#?切換?frame
????????driver.switch_to.frame('app_canvas_frame')
????????#?構(gòu)建?BeautifulSoup?對(duì)象
????????bs?=?BeautifulSoup(driver.page_source.encode('GBK',?'ignore').decode('gbk'))
????????#?找到頁面上的所有說說
????????pres?=?bs.find_all('pre',?class_='content')
????????for?pre?in?pres:
????????????shuoshuo?=?pre.text
????????????tx?=?pre.parent.parent.find('a',?class_="c_tx?c_tx3?goDetail")['title']
????????????print(tx?+?":"?+?shuoshuo)
????????#?頁數(shù)判斷
????????page?=?page?+?1
????????maxPage?=?bs.find('a',?title='末頁').text
????????if?int(maxPage)?????????????break
????????driver.find_element_by_link_text(u'下一頁').click()
????????#?回到主文檔
????????driver.switch_to.default_content()
????????#?等待頁面加載
????????time.sleep(3)
相冊(cè)
下載相冊(cè)里面的照片需要 selenium 模塊模擬鼠標(biāo)一步步點(diǎn)擊頁面,先點(diǎn)擊上方的相冊(cè)按鈕,進(jìn)去就是多個(gè)相冊(cè)的列表,下圖是單個(gè)相冊(cè)的超鏈接
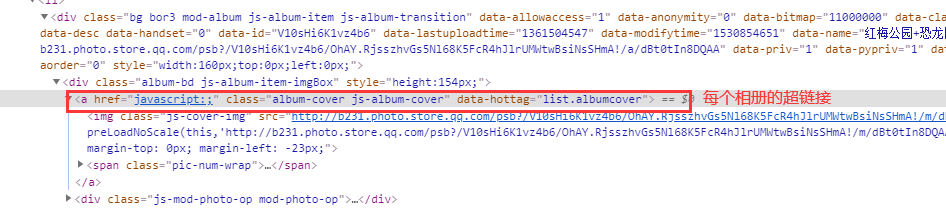
在單個(gè)相冊(cè)中點(diǎn)擊照片,界面如下圖
def?get_photo(driver):
????
????#?照片下載路徑
????photo_path?=?"C:/Users/xxx/Desktop/photo/{}/{}.jpg"
????
????#?相冊(cè)索引
????photoIndex?=?1
????while?True:
????????#?回到主文檔
????????driver.switch_to.default_content()
????????#?driver.switch_to.parent_frame()
????????#?點(diǎn)擊頭部的相冊(cè)按鈕
????????driver.find_element_by_xpath('//*[@id="menuContainer"]/div/ul/li[3]/a').click()
????????#等待加載
????????driver.implicitly_wait(10)
????????time.sleep(3)
????????#?切換?frame
????????driver.switch_to.frame('app_canvas_frame')
????????#?各個(gè)相冊(cè)的超鏈接
????????a?=?driver.find_elements_by_class_name('album-cover')
????????#?單個(gè)相冊(cè)
????????a[photoIndex].click()
????????driver.implicitly_wait(10)
????????time.sleep(3)
????????#?相冊(cè)的第一張圖
????????p?=?driver.find_elements_by_class_name('item-cover')[0]
????????p.click()
????????time.sleep(3)
????????#?相冊(cè)大圖在父frame,切換到父frame
????????driver.switch_to.parent_frame()
????????#?循環(huán)相冊(cè)中的照片
????????while?True:
????????????#?照片url地址和名稱
????????????img?=?driver.find_element_by_id('js-img-disp')
????????????src?=?img.get_attribute('src').replace('&t=5',?'')
????????????name?=?driver.find_element_by_id("js-photo-name").text
????????????#?下載
????????????urlretrieve(src,?photo_path.format(qq,?name))
????????????#?取下面的?當(dāng)前照片張數(shù)/總照片數(shù)量
????????????counts?=?driver.find_element_by_xpath('//*[@id="js-ctn-infoBar"]/div/div[1]/span').text
????????????counts?=?counts.split('/')
????????????#?最后一張的時(shí)候退出照片瀏覽
????????????if?int(counts[0])?==?int(counts[1]):
????????????????#?右上角的?X?按鈕
????????????????driver.find_element_by_xpath('//*[@id="js-viewer-main"]/div[1]/a').click()
????????????????break
????????????#?點(diǎn)擊?下一張,網(wǎng)頁加載慢,所以10次加載
????????????for?i?in?(1,?10):
????????????????if?driver.find_element_by_id('js-btn-nextPhoto'):
????????????????????n?=?driver.find_element_by_id('js-btn-nextPhoto')
????????????????????ActionChains(driver).click(n).perform()
????????????????????break
????????????????else:
????????????????????time.sleep(5)
????????#?相冊(cè)數(shù)量比較,是否下載了全部的相冊(cè)
????????photoIndex?=?photoIndex?+?1
????????if?len(a)?<=?photoIndex:
????????????break
示例結(jié)果

總結(jié)
大家在看十幾年前的說說和照片是不是感覺滿滿的黑歷史快要溢出屏幕了。時(shí)光荏苒、歲月如梭,愿一切安好。
PS:公號(hào)內(nèi)回復(fù)「Python」即可進(jìn)入Python 新手學(xué)習(xí)交流群,一起 100 天計(jì)劃!
老規(guī)矩,兄弟們還記得么,右下角的 “在看” 點(diǎn)一下,如果感覺文章內(nèi)容不錯(cuò)的話,記得分享朋友圈讓更多的人知道!


【代碼獲取方式】