
在pandas中利用hdf5高效存儲數(shù)據(jù)

點擊上方"藍字"關注我們
記錄? ?分享? ?成長
1 簡介
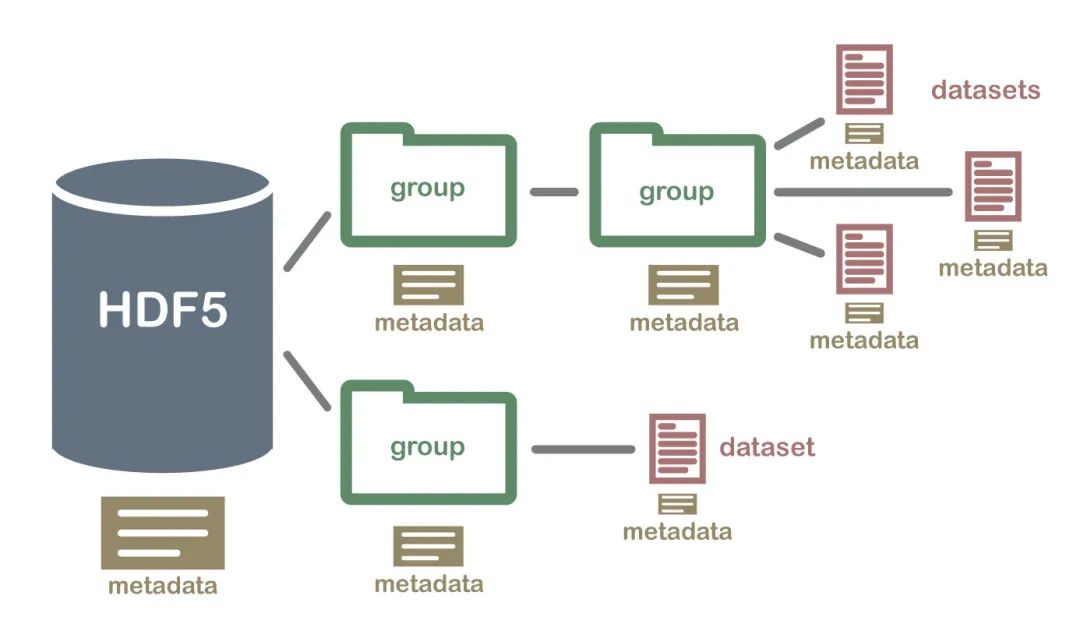
HDF5(Hierarchical Data Formal)是用于存儲大規(guī)模數(shù)值數(shù)據(jù)的較為理想的存儲格式。
其文件后綴名為h5,存儲讀取速度非常快,且可在文件內(nèi)部按照明確的層次存儲數(shù)據(jù),同一個HDF5可以看做一個高度整合的文件夾,其內(nèi)部可存放不同類型的數(shù)據(jù)。
在Python中操縱HDF5文件的方式主要有兩種,一是利用pandas中內(nèi)建的一系列HDF5文件操作相關的方法來將pandas中的數(shù)據(jù)結構保存在HDF5文件中,二是利用h5py模塊來完成從Python原生數(shù)據(jù)結構向HDF5格式的保存。
本文就將針對pandas中讀寫HDF5文件的方法進行介紹。
2 利用pandas操縱HDF5文件
2.1 寫出文件
pandas中的HDFStore()用于生成管理HDF5文件IO操作的對象,其主要參數(shù)如下:
?「path」:字符型輸入,用于指定h5文件的名稱(不在當前工作目錄時需要帶上完整路徑信息)
「mode」:用于指定IO操作的模式,與Python內(nèi)建的open()中的參數(shù)一致,默認為'a',即當指定文件已存在時不影響原有數(shù)據(jù)寫入,指定文件不存在時則新建文件;'r',只讀模式;'w',創(chuàng)建新文件(會覆蓋同名舊文件);'r+',與'a'作用相似,但要求文件必須已經(jīng)存在;
「complevel」:int型,用于控制h5文件的壓縮水平,取值范圍在0-9之間,越大則文件的壓縮程度越大,占用的空間越小,但相對應的在讀取文件時需要付出更多解壓縮的時間成本,默認為0,代表不壓縮
?
下面我們創(chuàng)建一個HDF5 IO對象store:
import?pandas?as?pd
store?=?pd.HDFStore('demo.h5')
'''查看store類型'''
print(store)
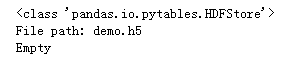
可以看到store對象屬于pandas的io類,通過上面的語句我們已經(jīng)成功的初始化名為demo.h5的的文件,本地也相應的會出現(xiàn)對應文件。
接下來我們創(chuàng)建pandas中不同的兩種對象,并將它們共同保存到store中,首先創(chuàng)建Series對象:
import?numpy?as?np
#創(chuàng)建一個series對象
s?=?pd.Series(np.random.randn(5),?index=['a',?'b',?'c',?'d',?'e'])
s

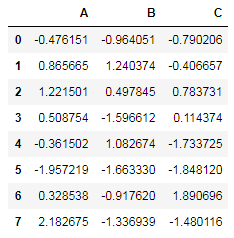
接著我們創(chuàng)建一個DataFrame對象:
#創(chuàng)建一個dataframe對象
df?=?pd.DataFrame(np.random.randn(8,?3),
?????????????????columns=['A',?'B',?'C'])
df
第一種方式利用鍵值對將不同的數(shù)據(jù)存入store對象中:
store['s'],?store['df']?=?s,?df
第二種方式利用store對象的put()方法,其主要參數(shù)如下:
?「key」:指定h5文件中待寫入數(shù)據(jù)的key
「value」:指定與key對應的待寫入的數(shù)據(jù)
「format」:字符型輸入,用于指定寫出的模式,'fixed'對應的模式速度快,但是不支持追加也不支持檢索;'table'對應的模式以表格的模式寫出,速度稍慢,但是支持直接通過store對象進行追加和表格查詢操作
?
使用put()方法將數(shù)據(jù)存入store對象中:
store.put(key='s',?value=s);store.put(key='df',?value=df)
既然是鍵值對的格式,那么可以查看store的items屬性(注意這里store對象只有items和keys屬性,沒有values屬性):
store.items

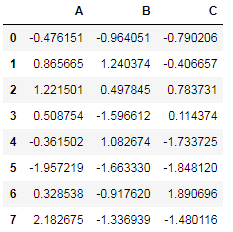
調(diào)用store對象中的數(shù)據(jù)直接用對應的鍵名來索引即可:
store['df']
刪除store對象中指定數(shù)據(jù)的方法有兩種,一是使用remove()方法,傳入要刪除數(shù)據(jù)對應的鍵:
store.remove('s')
二是使用Python中的關鍵詞del來刪除指定數(shù)據(jù):
del?store['s']
這時若想將當前的store對象持久化到本地,只需要利用close()方法關閉store對象即可,而除了通過定義一個確切的store對象的方式之外,還可以從pandas中的數(shù)據(jù)結構直接導出到本地h5文件中:
#創(chuàng)建新的數(shù)據(jù)框
df_?=?pd.DataFrame(np.random.randn(5,5))
#導出到已存在的h5文件中,這里需要指定key
df_.to_hdf(path_or_buf='demo.h5',key='df_')
#創(chuàng)建于本地demo.h5進行IO連接的store對象
store?=?pd.HDFStore('demo.h5')
#查看指定h5對象中的所有鍵
print(store.keys())

2.2 讀入文件
在pandas中讀入HDF5文件的方式主要有兩種,一是通過上一節(jié)中類似的方式創(chuàng)建與本地h5文件連接的IO對象,接著使用鍵索引或者store對象的get()方法傳入要提取數(shù)據(jù)的key來讀入指定數(shù)據(jù):
store?=?pd.HDFStore('demo.h5')
'''方式1'''
df1?=?store['df']
'''方式2'''
df2?=?store.get('df')
df1?==?df2

可以看出這兩種方式都能順利讀取鍵對應的數(shù)據(jù)。
第二種讀入h5格式文件中數(shù)據(jù)的方法是pandas中的read_hdf(),其主要參數(shù)如下:
?「path_or_buf」:傳入指定h5文件的名稱
「key」:要提取數(shù)據(jù)的鍵
?
需要注意的是利用read_hdf()讀取h5文件時對應文件不可以同時存在其他未關閉的IO對象,否則會報錯,如下例:
print(store.is_open)
df?=?pd.read_hdf('demo.h5',key='df')

把IO對象關閉后再次提取:
store.close()
print(store.is_open)
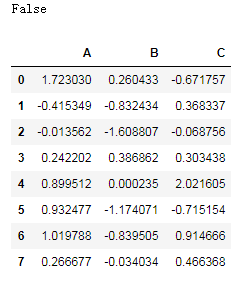
df?=?pd.read_hdf('demo.h5',key='df')
df
2.3 性能測試
接下來我們來測試一下對于存儲同樣數(shù)據(jù)的csv格式文件、h5格式的文件,在讀取速度上的差異情況:
這里我們首先創(chuàng)建一個非常大的數(shù)據(jù)框,由一億行x5列浮點類型的標準正態(tài)分布隨機數(shù)組成,接著分別用pandas中寫出HDF5和csv格式文件的方式持久化存儲:
import?pandas?as?pd
import?numpy?as?np
import?time
store?=?pd.HDFStore('store.h5')
#生成一個1億行,5列的標準正態(tài)分布隨機數(shù)表
df?=?pd.DataFrame(np.random.rand(100000000,5))
start1?=?time.clock()
store['df']?=?df
store.close()
print(f'HDF5存儲用時{time.clock()-start1}秒')
start2?=?time.clock()
df.to_csv('df.csv',index=False)
print(f'csv存儲用時{time.clock()-start2}秒')
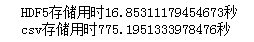
在寫出同樣大小的數(shù)據(jù)框上,HDF5比常規(guī)的csv快了將近50倍,而且兩者存儲后的文件大小也存在很大差異:
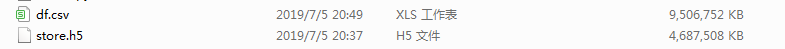
csv比HDF5多占用將近一倍的空間,這還是在我們沒有開啟HDF5壓縮的情況下,接下來我們關閉所有IO連接,運行下面的代碼來比較對上述兩個文件中數(shù)據(jù)還原到數(shù)據(jù)框上兩者用時差異:
import?pandas?as?pd
import?time
start1?=?time.clock()
store?=?pd.HDFStore('store.h5',mode='r')
df1?=?store.get('df')
print(f'HDF5讀取用時{time.clock()-start1}秒')
start2?=?time.clock()
df2?=?pd.read_csv('df.csv')
print(f'csv讀取用時{time.clock()-start2}秒')
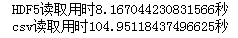
HDF5用時僅為csv的1/13,因此在涉及到數(shù)據(jù)存儲特別是規(guī)模較大的數(shù)據(jù)時,HDF5是你不錯的選擇。
以上就是本文的全部內(nèi)容,歡迎在評論區(qū)與我進行討論~
加入我們的知識星球【Python大數(shù)據(jù)分析】
愛上數(shù)據(jù)分析!

Python大數(shù)據(jù)分析
data creates?value
掃碼關注我們