
Pandas | 5 種技巧高效利用value-counts
點(diǎn)擊上方“程序員大白”,選擇“星標(biāo)”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)

value_counts() 方法返回一個(gè)序列 Series,該序列包含每個(gè)值的數(shù)量。也就是說,對(duì)于數(shù)據(jù)框中的任何列,value-counts () 方法會(huì)返回該列每個(gè)項(xiàng)的計(jì)數(shù)。
語法
Series.value_counts()
參數(shù)

圖源:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.value_counts.html
基本用法
作者通過以下數(shù)據(jù)集來觀察 value-count () 函數(shù)的基本用法,其中 Demo 中使用了 Titanic 數(shù)據(jù)集。她還在 Kaggle 上發(fā)布了一個(gè)配套的 notebook。
代碼鏈接:https://www.kaggle.com/parulpandey/five-ways-to-use values -counts

導(dǎo)入數(shù)據(jù)集
首先導(dǎo)入必要的庫和數(shù)據(jù)集,這是每個(gè)數(shù)據(jù)分析流程的基本步驟。
# Importing necessary librariesimport pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline# Reading in the data
train = pd.read_csv( ../input/titanic/train.csv )
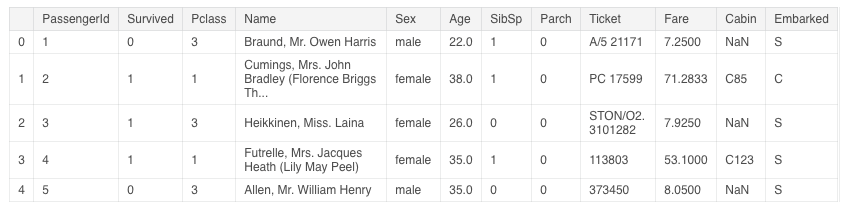
了解數(shù)據(jù)集的前幾行內(nèi)容
train.head()
統(tǒng)計(jì)無效值數(shù)量
train.isnull().sum()

由上圖可見,Age、Cabin 和 Embarked 列都有無效值。通過這些分析,我們就對(duì)數(shù)據(jù)集有了初步的了解。現(xiàn)在就讓我們來看一下 value_counts() 是如何對(duì)這個(gè)數(shù)據(jù)集進(jìn)行進(jìn)一步探索的,那 5 個(gè)高效方法又是什么呢?
默認(rèn)參數(shù)值下的 value_counts()
首先在數(shù)據(jù)集的 Embarked 列上使用 value_counts (),這樣會(huì)對(duì)該列中出現(xiàn)的每個(gè)值進(jìn)行計(jì)數(shù)。
train[ Embarked ].value_counts()
-------------------------------------------------------------------
S 644
C 168
Q 77
這個(gè)函數(shù)會(huì)對(duì)給定列里面的每個(gè)值進(jìn)行計(jì)數(shù)并進(jìn)行降序排序,無效值也會(huì)被排除。我們很容易就能看出,Southampton 出發(fā)的人最多,其次是 Cherbourg 和 Queenstown。
如何用 value_counts() 求各個(gè)值的相對(duì)頻率
有時(shí)候,百分比比單純計(jì)數(shù)更能體現(xiàn)數(shù)量的相對(duì)關(guān)系。當(dāng) normalize = True 時(shí),返回的對(duì)象將包含各個(gè)值的相對(duì)頻率。默認(rèn)情況下,normalize 參數(shù)被設(shè)為 False。
train[ Embarked ].value_counts(normalize=True)
-------------------------------------------------------------------
S 0.724409
C 0.188976
Q 0.086614
因此,知道有 72% 的人從 Southampton 出發(fā)比單純知道 644 個(gè)人從 Southampton 出發(fā)要直觀得多。
如何實(shí)現(xiàn)升序的 value_counts()
默認(rèn)情況下,value_counts () 返回的序列是降序的。我們只需要把參數(shù) ascending 設(shè)置為 True,就可以把順序變成升序。
train[ Embarked ].value_counts(ascending=True)
-------------------------------------------------------------------
Q 77
C 168
S 644
如何用 value_counts() 展示 NaN 值的計(jì)數(shù)
默認(rèn)情況下,無效值(NaN)是不會(huì)被包含在結(jié)果中的。但是跟之前一樣的,只需要把 dropna 參數(shù)設(shè)置成 False,你也就可以對(duì)無效值進(jìn)行計(jì)數(shù)。
train[ Embarked ].value_counts(dropna=False)
-------------------------------------------------------------------
S 644
C 168
Q 77
NaN 2
我們可以很直觀地觀察到該列內(nèi)有兩個(gè)無效值。
如何用 value_counts() 將連續(xù)數(shù)據(jù)放進(jìn)離散區(qū)間
這是 value_counts() 所有功能中作者最喜歡的,也是利用最充分的。改變參數(shù) bin 的值,value_counts 就可以將連續(xù)數(shù)據(jù)放進(jìn)離散區(qū)間。這個(gè)選項(xiàng)只有當(dāng)數(shù)據(jù)是數(shù)字型時(shí)才會(huì)有用。它跟 pd.cut 函數(shù)很像,讓我們來看一下它是如何在 Fare 這一列大顯身手的吧!
# applying value_counts on a numerical column without the bin parametertrain[ Fare ].value_counts()
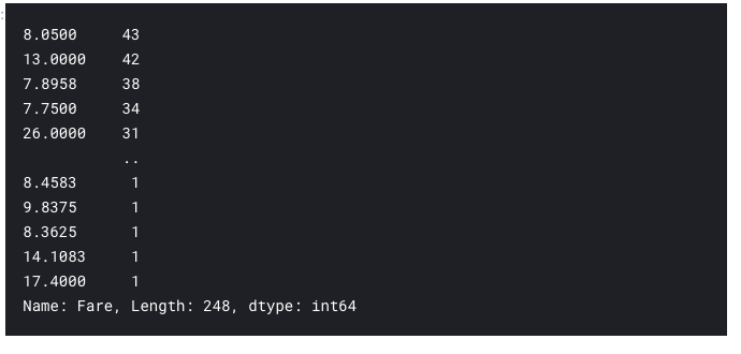
這個(gè)結(jié)果并不能告訴我們什么信息,因?yàn)轭悇e太多了。所以讓我們把它集合到 7 個(gè)區(qū)間里。
train[ Fare ].value_counts(bins=7)
區(qū)間化(Binning)之后的結(jié)果更容易理解。我們可以很容易地看到,大多數(shù)人支付的票款低于 73.19。此外,我們還可以發(fā)現(xiàn),有五個(gè)區(qū)間是我們需要的,并且沒有乘客的最后兩個(gè)區(qū)間是沒用的。
因此,我們可以看到,value_counts() 函數(shù)是一個(gè)非常方便的工具,我們可以使用這一行代碼進(jìn)行一些有趣的分析。
原文鏈接:
https://towardsdatascience.com/getting-more-value-from-the-pandas-value-counts-aa17230907a6
推薦閱讀
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學(xué),西湖大學(xué)和上海交通大學(xué)的碩士博士運(yùn)營(yíng)維護(hù)的號(hào),大家樂于分享高質(zhì)量文章,喜歡總結(jié)知識(shí),歡迎關(guān)注[程序員大白],大家一起學(xué)習(xí)進(jìn)步!