
面試官問:重復(fù)的請求如何過濾?
為什么要做重復(fù)請求的過濾呢?不過濾不行嗎?
過濾重復(fù)請求很難嗎?加一個請求ID不就好了嗎?
每個技術(shù)難點的話題,肯定是由一個產(chǎn)品需求引發(fā)的,俗話說:如果沒有產(chǎn)品經(jīng)理,程序員將不需要聽診器,但是會失業(yè)!!
產(chǎn)生背景
重復(fù)請求能夠?qū)ο到y(tǒng)造成傷害是架構(gòu)中很難避免的一個設(shè)計問題,一般情況下,讀請求很少會造成致命性的故障,主要是系統(tǒng)的寫請求,很多時候一個重復(fù)寫的動作,會是我們程序員加班的緣由。比如:用戶使用積分兌換物品,重復(fù)的請求會造成用戶積分的重復(fù)扣減,而作為線上系統(tǒng),如果日志等輔助打的不好的話,排查原因其實需要很多時間。
一般的產(chǎn)品經(jīng)理設(shè)計系統(tǒng)的時候并不會涉及到這類異常情況,但是一旦出現(xiàn)問題,產(chǎn)品經(jīng)理就會找到程序員罵娘,多么悲哀的故事,人家付出5分精力設(shè)計的系統(tǒng),我們卻要花費10分的精力去編碼和維護(hù)。
重復(fù)的業(yè)務(wù)請求,有的時候?qū)ο到y(tǒng)造成的影響很大,所以程序員在設(shè)計的時候尤其要注意,產(chǎn)生的原因有很多:
黑客進(jìn)行了攔截,人為的重放了請求 客戶端因為某些原因,用戶在很短的時間內(nèi)重放了請求 一些中間件(比如網(wǎng)關(guān))重放了請求 未知的其他情況
道理很簡單,用一張圖表達(dá)的會更清爽一些
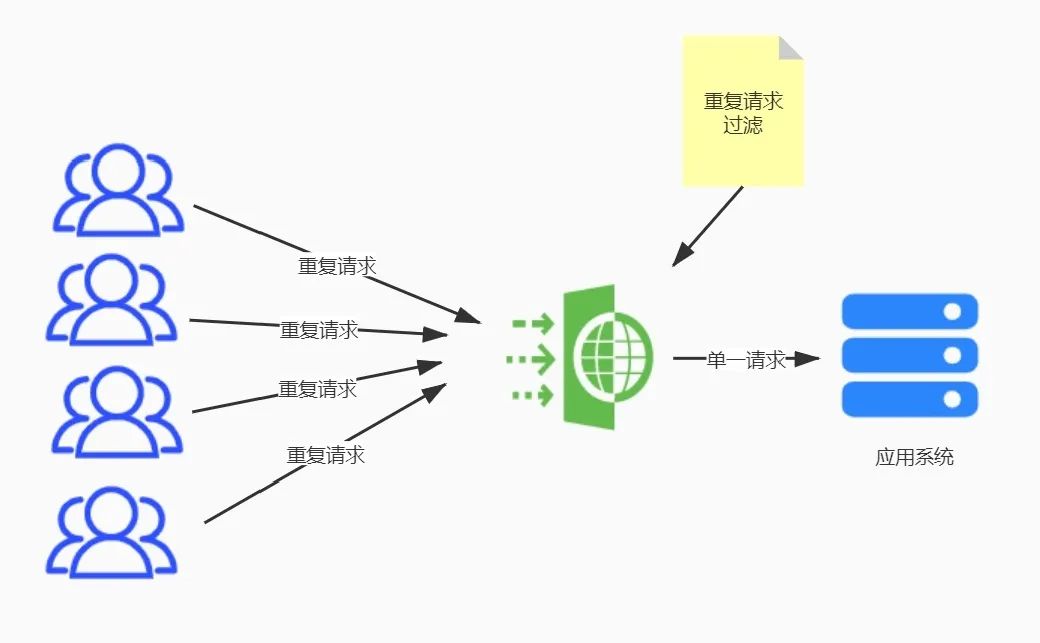
抽象出來是不是很簡單?但是落地卻并非像這張圖一樣簡單!!
從這張圖上一眼就可以看到,整個過程的重點難點在于過濾器這個邏輯設(shè)計部分,這部分可以和業(yè)務(wù)代碼融合在一起,有的時候也可以相分離,比如:有的網(wǎng)關(guān)可以內(nèi)嵌腳本(比如:lua),就完全可以做到和業(yè)務(wù)無關(guān),但是通常情況下,落地的代碼卻和業(yè)務(wù)息息相關(guān)。
客戶端處理
客戶端處理重復(fù)請求是一種可以有效過濾正常請求的手段,為什么這么說呢?當(dāng)一個用戶正常操作的時候,客戶端完全可以利用loading的方式或者其他過濾重復(fù)手段來達(dá)到目的,比如:當(dāng)用戶點擊一個按鈕的時候,彈出loading窗口方式用戶再次操作。
再比如:客戶端可以設(shè)置一個類似于布隆過濾的數(shù)據(jù)結(jié)構(gòu),配合對應(yīng)的過濾算法也可以達(dá)到過濾重復(fù)請求的效果。
不過,客戶端的任何解決方案也只是治標(biāo)不治本,畢竟,客戶端在整個系統(tǒng)架構(gòu)中,是最不可靠的終端。
請求標(biāo)識
重復(fù)請求過濾的關(guān)鍵在于過濾器的邏輯設(shè)計,目前最常用,落地最多當(dāng)屬使用請求ID的方式。大體流程如下:
客戶端發(fā)送請求的時候,會生成隨機(jī)的請求ID,隨著業(yè)務(wù)參數(shù)一起傳送到服務(wù)端 服務(wù)端會根據(jù)傳送上來的請求ID做是否重復(fù)的判斷
服務(wù)器的判斷邏輯其實有很多落地方案了,比如最常見的利用redis來存儲請求ID,以下是偽代碼(NetCore):
public?class?Para
{
????public?string?ReqId{get?;set?;}??
????//其他業(yè)務(wù)參數(shù)
}
public?bool?IsExsit(Para?p)
{
????//利用redis來判斷當(dāng)前的key是否存在
?????bool?isExsit=redisMethond(p.ReqId);
?????//如果存在,則說明是重復(fù)請求,如果不存在說明不是重復(fù)請求,并且添加到redis
?????if(!isExsit){
?????????AddRedis(p.ReqId);
?????}
?????return?isExsit;
}
一般網(wǎng)上的文章都到此為止了,這種方案有沒有問題呢?答案:有
問題1
正常的客戶端重復(fù)請求,一般情況下真的會根據(jù)我們寫的代碼過濾掉重復(fù)請求,為什么說一般情況呢?那是因為分布式的原因,極限情況下也會導(dǎo)致重復(fù)的請求到業(yè)務(wù)處理端,比如以下情況:
請求被路由到了A服務(wù)器,A服務(wù)器會去請求Redis,判斷是否有相同的請求ID存在,如果是第一次請求,Redis會返回不存在 同樣的時間,客戶端或者黑客重放了同樣的請求,這個請求被路由到了B服務(wù)器,B服務(wù)器同樣會請求Redis來判斷是否存在,這個時候由于A服務(wù)器還沒回寫Redis,所以B服務(wù)器得到的結(jié)果也是不存在該請求 這樣就導(dǎo)致了業(yè)務(wù)端收到了兩次同樣的請求,會導(dǎo)致業(yè)務(wù)不可預(yù)期的結(jié)果
可見,一個小小重復(fù)過濾請求,可能還需要分布式鎖的出場才可以
問題2
即便請求中加了唯一的請求ID,但是這個ID并沒有安全保證,或者說,這個ID是可以篡改的。當(dāng)黑客攔截到請求,隨便改一下請求ID,在重放就搞定你了。所以,加的請求ID,還需要一個安全機(jī)制來保證安全,不然這個參數(shù)其實意義不大。
業(yè)務(wù)簽名
由于單純添加請求ID,并不能解決問題,所以我們需要一種保證請求ID的機(jī)制,目前來看,普遍的落地方案是根據(jù)業(yè)務(wù)參數(shù)生成摘要,也就是所謂的加簽操作。加簽操作可以有效的防止參數(shù)被篡改。如果你做過微信相關(guān)的開發(fā),你會發(fā)現(xiàn)和微信服務(wù)器的交互也是基于加簽操作的。而生成的簽名可以作為請求ID,以下是偽代碼:
????//客戶端生成簽名
????string?sigh=MD5($"參數(shù)1=值1&參數(shù)2=值2&time=當(dāng)前時間戳")
以上只是例子,雖然MD5算法有產(chǎn)生重復(fù)數(shù)據(jù)的可能性,但是對于當(dāng)前這個業(yè)務(wù)場景來說足夠了。細(xì)心的同學(xué)會發(fā)現(xiàn),參數(shù)當(dāng)中加了一個時間戳的參數(shù),這個是我故意加的,這個時間戳在這個場景下會出現(xiàn)問題,什么問題呢?
時間戳問題
當(dāng)前的請求場景是要過濾重復(fù)的請求,什么樣的請求算是重復(fù)請求呢?關(guān)鍵是這個定義要明確,我看了很多重復(fù)過濾請求的文章,重復(fù)請求這個概念其實定義的不好,這個是和具體業(yè)務(wù)場景相關(guān)的。舉個栗子:當(dāng)用戶一秒內(nèi)重復(fù)點擊某個按鈕算是重復(fù)請求,那10秒內(nèi)重復(fù)點擊呢?用戶一秒之內(nèi)對同一個商品下單算重復(fù)請求,那10秒內(nèi)呢?
這個定義就涉及到了上面所說的時間戳參數(shù)的問題,時間戳是否要參與生成簽名,要根據(jù)具體的業(yè)務(wù)場景來定義,不過,我還是要建議,請求的參數(shù)中帶上時間戳,無論它參不參與簽名,至于為什么這么做,當(dāng)時間長了你就知道了
寫在最后
過濾重復(fù)請求這個需求,并沒有像想象中那么容易,并非只要加上一個請求ID就完事了,它涉及到安全以及分布式的問題,在某些場景下(比如:秒殺)還會涉及到性能以及高可用等非功能性問題,所以那些說:只需要一個請求ID就能過濾的同學(xué),請不要再誤導(dǎo)別人了,技術(shù)是神圣不可侵犯的。
還是那句話:具體的業(yè)務(wù)影響到具體的代碼實現(xiàn),脫離業(yè)務(wù)講架構(gòu)其實就是耍流氓