
【機器學習基礎(chǔ)】對"樣本不均衡"的處理
作者:時晴 煉丹小仙女
樣本不均的問題大家已經(jīng)很常見了,我們總是能看到某一個類目的數(shù)量遠高于其他類目,舉個例子,曝光轉(zhuǎn)化數(shù)遠低于曝光未轉(zhuǎn)化數(shù)。樣本不均嚴重影響了模型的效果,甚至影響到我們對模型好壞的判斷,因為模型對占比比較高的類目準確率非常高,對占比很低的類目預估的偏差特別大,但是由于占比較高的類目對loss/metric影響較大,我們會認為得到了一個較優(yōu)的模型。比如像是異常檢測問題,我們直接返回沒有異常,也能得到一個很高的準確率。
重采樣
這個是目前使用頻率最高的方式,可以對“多數(shù)”樣本降采樣,也可以對“少數(shù)”樣本過采樣,如下圖所示:
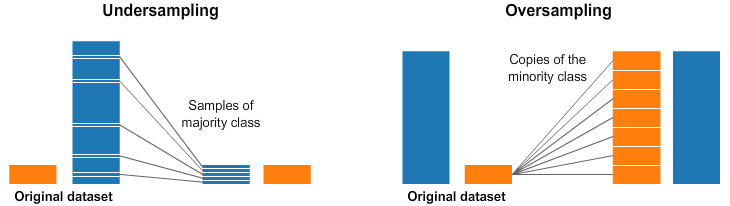
重采樣的缺點也比較明顯,過采樣對少數(shù)樣本"過度捕撈",降采樣會丟失大量信息。
重采樣的方案也有很多,最簡單的就是隨機過采樣/降采樣,使得各個類別的數(shù)量大致相同。還有一些復雜的采樣方式,比如先對樣本聚類,在需要降采樣的樣本上,按類別進行降采樣,這樣能丟失較少的信息。過采樣的話,可以不用簡單的copy,可以加一點點"噪聲",生成更多的樣本。
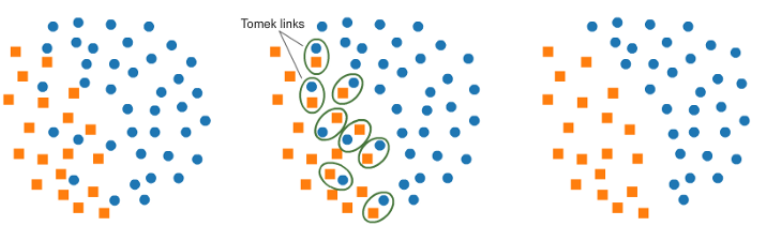
Tomek links
Tomek連接指的是在空間上"最近"的樣本,但是是不同類別的樣本。刪除這些pair中,占大多數(shù)類別的樣本。通過這種降采樣方式,有利于分類模型的學習,如下圖所示:
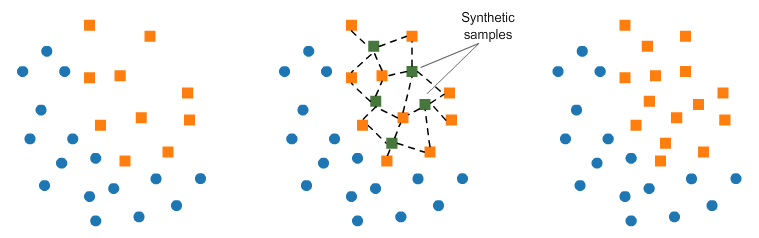
SMOTE
這個方法可以給少數(shù)樣本做擴充,SMOTE在樣本空間中少數(shù)樣本隨機挑選一個樣本,計算k個鄰近的樣本,在這些樣本之間插入一些樣本做擴充,反復這個過程,知道樣本均衡,如下圖所示:
NearMiss
這是個降采樣的方法,通過距離計算,刪除掉一些無用的點。
NearMiss-1:在多數(shù)類樣本中選擇與最近的3個少數(shù)類樣本的平均距離最小的樣本。
NearMiss-2:在多數(shù)類樣本中選擇與最遠的3個少數(shù)類樣本的平均距離最小的樣本。
NearMiss-3:對于每個少數(shù)類樣本,選擇離它最近的給定數(shù)量的多數(shù)類樣本。
NearMiss-1考慮的是與最近的3個少數(shù)類樣本的平均距離,是局部的;NearMiss-2考慮的是與最遠的3個少數(shù)類樣本的平均距離,是全局的。NearMiss-1方法得到的多數(shù)類樣本分布也是“不均衡”的,它傾向于在比較集中的少數(shù)類附近找到更多的多數(shù)類樣本,而在孤立的(或者說是離群的)少數(shù)類附近找到更少的多數(shù)類樣本,原因是NearMiss-1方法考慮的局部性質(zhì)和平均距離。NearMiss-3方法則會使得每一個少數(shù)類樣本附近都有足夠多的多數(shù)類樣本,顯然這會使得模型的精確度高、召回率低。
評估指標
為了避免對模型的誤判,避免使用Accuracy,可以用confusion matrix,precision,recall,f1-score,AUC,ROC等指標。
懲罰項
對少數(shù)樣本預測錯誤增大懲罰,是一個比較直接的方式。
使用多種算法
模型融合不止能提升效果,也能解決樣本不均的問題,經(jīng)驗上,樹模型對樣本不均的解決幫助很大,特別是隨機森林,Random Forest,XGB,LGB等。因為樹模型作用方式類似于if/else,所以迫使模型對少數(shù)樣本也非常重視。
正確的使用K-fold
當我們對樣本過采樣時,對過采樣的樣本使用k-fold,那么模型會過擬合我們過采樣的樣本,所以交叉驗證要在過采樣前做。在過采樣過程中,應(yīng)當增加些隨機性,避免過擬合。
使用多種重采樣的訓練集
這種方法可以使用更多的數(shù)據(jù)獲得一個泛化性較強的模型。用所有的少數(shù)樣本,和多種采樣的多數(shù)樣本,構(gòu)建多個模型得到多個模型做融合,可以取得不錯的效果。
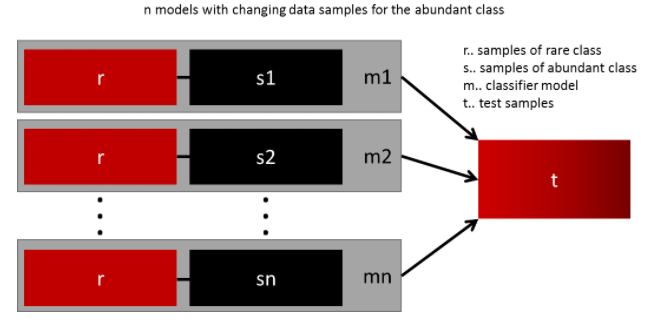
重采樣使用不同rate
這個方法和上面的方法很類似,嘗試使用各種不同的采樣率,訓練不同的模型。
沒有什么解決樣本不均最好的方法,以上內(nèi)容也沒有枚舉出所有的解決方案,最好的方案就是嘗試使用各種方案。
往期精彩回顧
本站qq群851320808,加入微信群請掃碼: