
這波操作看麻了!一億行數(shù)據(jù),從71s到1.7s的優(yōu)化之路.
你好呀,我是歪歪。
春節(jié)期間關(guān)注到了一個關(guān)于 Java 方面的比賽,很有意思。由于是開源的,我把項目拉下來試圖學(xué)(白)習(xí)(嫖)別人的做題思路,在這期間一度讓我產(chǎn)生了一個自我懷疑:
他們寫的 Java 和我會的 Java 是同一個 Java 嗎?

不能讓我一個人懷疑,所以這篇文章我打算帶你盤一下這個比賽,并且試圖讓你也產(chǎn)生懷疑。
賽題
在 2024 年 1 月 1 日,一個叫做 Gunnar Morling 的帥哥,發(fā)了這樣一篇文章:
https://www.morling.dev/blog/one-billion-row-challenge/

文章的標(biāo)題叫做《The One Billion Row Challenge》,一億行挑戰(zhàn),簡稱就是 1BRC,挑戰(zhàn)的時間是一月份整個月。
賽題的內(nèi)容非常簡單,你只需要看懂這個文件就行了:

文件的每一行記錄的是一個氣象站的溫度值。氣象站和溫度分號分隔,溫度值只會保留一位小數(shù)。
參賽者只需要解析這個文件,然后并計算出每個氣象站的最小、最大和平均溫度。按照字典序的格式輸出就行了:

出題人還配了一個簡圖:
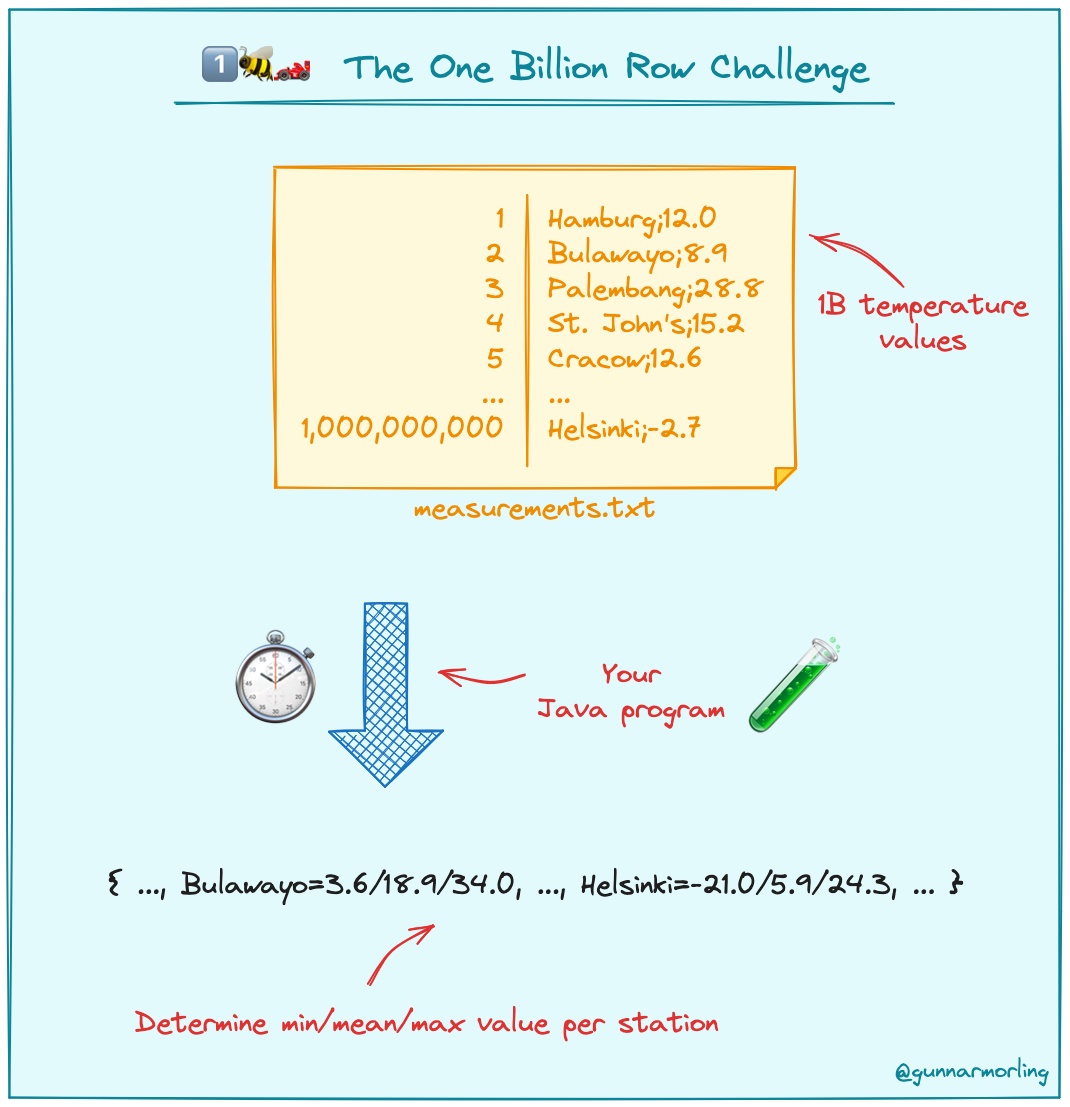
需求非常明確、簡單,對不對?
為了讓你徹底明白,我再給你舉一個具體的例子。
假設(shè)文件中的內(nèi)容是這樣的:
chengdu;12.0
guangzhou;7.2;
chengdu;6.3
beijing;-3.6;
chengdu;23.0
shanghai;9.8;
chengdu;24.3
beijing;17.8;
那么 chengdu (成都)的最低氣溫是 6.3,最高氣溫是 24.3,平均氣溫是(12.0+6.3+23.0+24.3)/4=16.4,就是這么樸實無華的計算方式。
最終結(jié)果輸出的時候,再注意一下字典序就行。
這有啥好挑戰(zhàn)的呢?
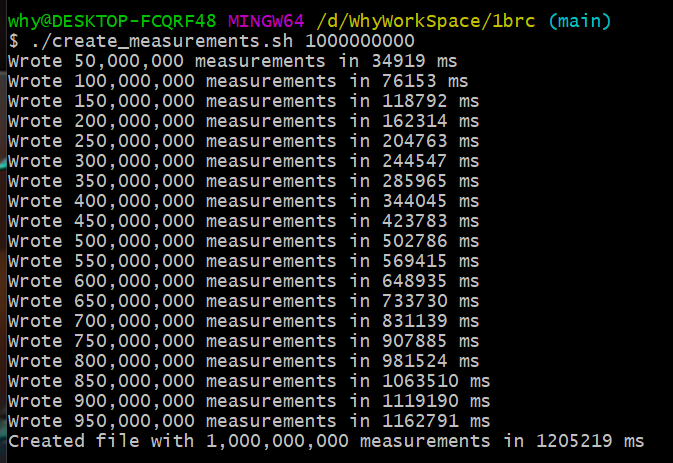
難點在于出題人給出的這個文件有 10 億行數(shù)據(jù)。
在我的垃圾電腦上,光是跑出題人提供的數(shù)據(jù)生成的腳本,就跑了 20 分鐘:
跑出來之后文件大小都有接近 13G,記事本打都打不開:
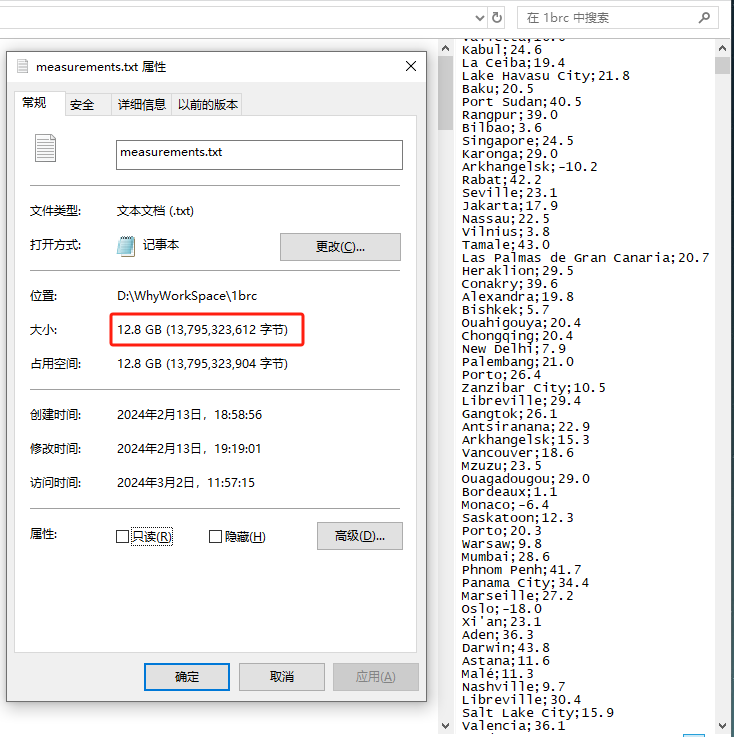
所以挑戰(zhàn)點就在于“一億行”數(shù)據(jù)。
具體的一些規(guī)則描述和細節(jié)補充,都在 github 上放好了:
https://github.com/gunnarmorling/1brc
針對這個挑戰(zhàn),出題人還提供了一個基線版本:
https://github.com/gunnarmorling/1brc/blob/main/src/main/java/dev/morling/onebrc/CalculateAverage_baseline.java
首先封裝了一個 MeasurementAggregator 對象,里面放的就是要記錄的最小溫度、最大溫度、總溫度和總數(shù)。
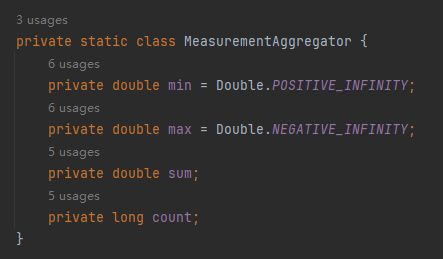
整個核心代碼就二三十行,使用了流式編程:
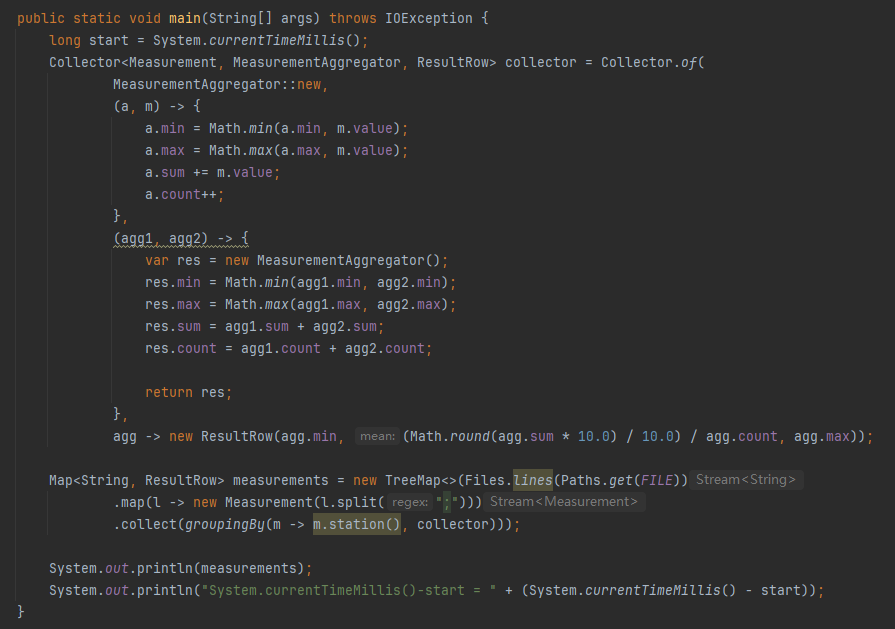
首先是一行行的讀取文本,接著每一行都按照分號進行拆分,取出對應(yīng)的氣象站和溫度值。
然后按照氣象站維度進行 groupingBy 聚合,并且計算最大值、最小值和平均值。
在計算平均值的時候,為了避免浮點計算,還特意將溫度乘 10,轉(zhuǎn)換為 int 類型。
最后用 TreeMap 按字典序輸出各個氣象站的溫度數(shù)據(jù)。
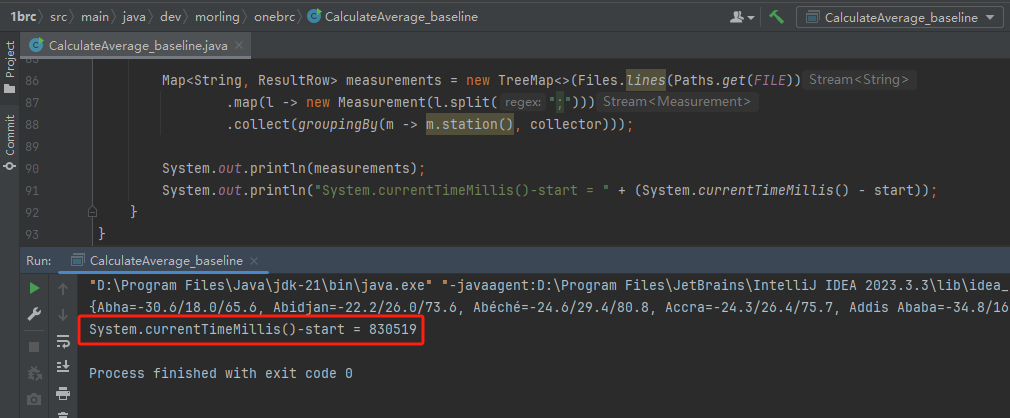
這個基線版本官方的數(shù)據(jù)是在跑分環(huán)境下,2 分鐘內(nèi)可以運行完畢。
而在我的電腦上跑了接近 14 分鐘:
很正常,畢竟人家的測評環(huán)境配置都是很高的:
Results are determined by running the program on a Hetzner AX161 dedicated server (32 core AMD EPYC? 7502P (Zen2), 128 GB RAM).
參加挑戰(zhàn)的各路大神,最終拿出的 TOP 10 成績是這樣的:
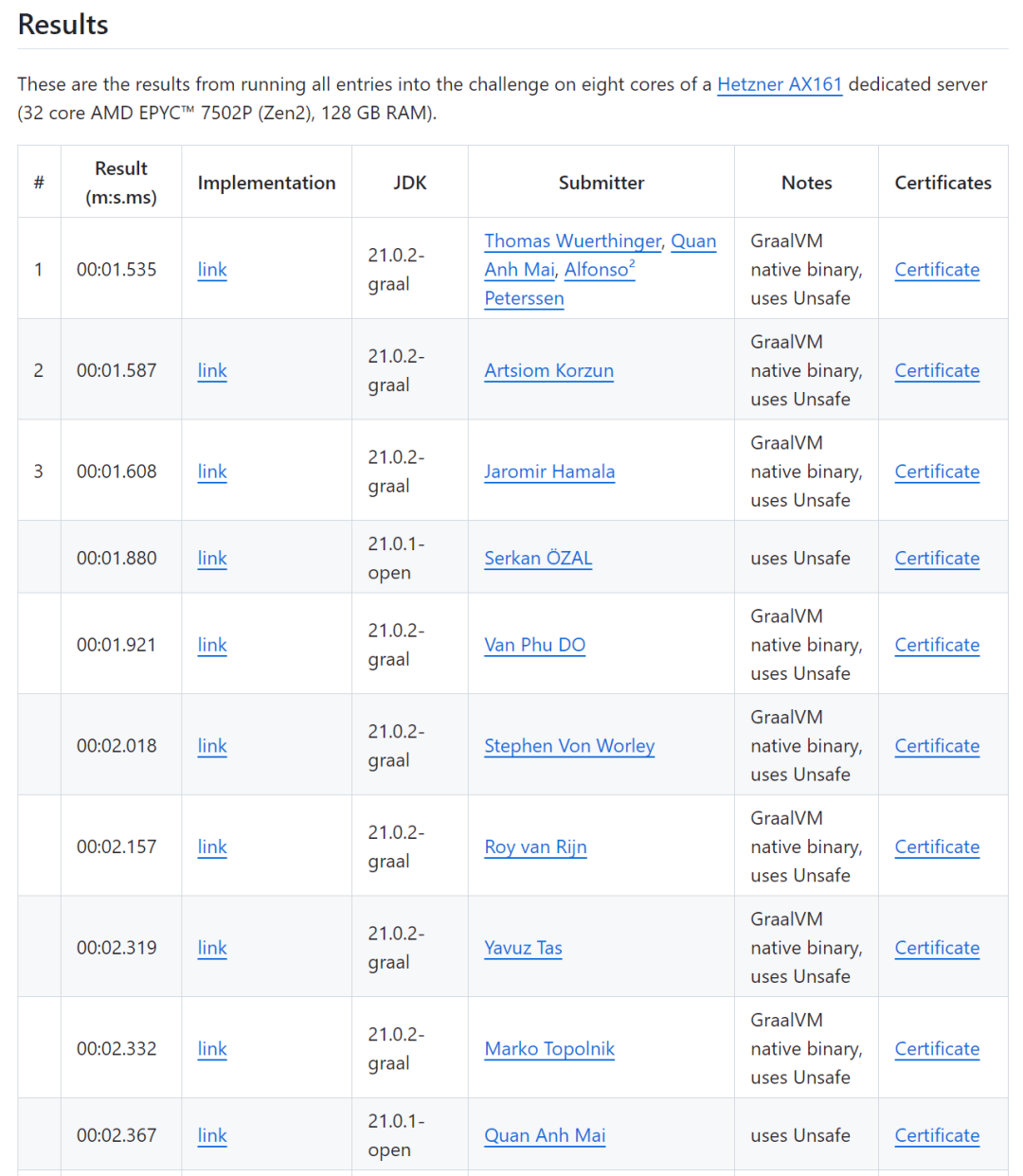
當(dāng)時看到這個成績的瞬間,我人都是麻的,第一個疑問是:我靠,13G 的文件啊?1.5s 內(nèi)完成了讀取、解析、計算的過程?這不可能啊,光是讀取 13G 大小的文件,也需要一點時間吧?

但是需要注意的是,歪師傅有這個想法是走入了一個小誤區(qū),就是我以為這 13G 的文件一次性加載不完成,怎么快速的從硬盤把文件讀取到內(nèi)存中也是一個考點。
后來發(fā)現(xiàn)是我多慮了,人家直接就說了,不用考慮這一點,跑分成績運行的時候,文件直接就在內(nèi)存中:

所以,最終的成績中不包含讀取文件的時間。
但是也很牛逼了啊,畢竟有一億條數(shù)據(jù)。
第一名
我嘗試著看了一下第一名的代碼:
https://github.com/gunnarmorling/1brc/blob/main/src/main/java/dev/morling/onebrc/CalculateAverage_thomaswue.java
過于硬核,實在是看不懂。我只能通過作者寫的一點注釋、方法名稱、代碼提交記錄去嘗試?yán)斫馑拇a。
在他的代碼開頭的部分,有這樣的一段描述:

這是他的破題思路,結(jié)合了這些信息之后再去看代碼,稍微好一點,但是我發(fā)現(xiàn)他里面還是有非常多的微操、太多針對性的優(yōu)化導(dǎo)致代碼可讀性較差,雖然他的代碼加上注釋一共也才 400 多行,然而我看還是看不懂。
我隨便截個代碼片段吧:

問 GPT 這個哥們,他也是能說個大概出來:

所以我放棄了理解第一名的代碼,開始去看第二名,發(fā)現(xiàn)也是非常的晦澀難懂,再到第三名...
最后,我產(chǎn)生了文章開始時的疑問:他們寫的 Java 和我會的 Java 是同一個 Java 嗎?
但是有一說一,雖然我看不懂他們的某些操作,但是會發(fā)現(xiàn)他們整體的思路都幾乎是一致。
雖然我沒有看懂第一名的代碼,但是我還是專門列出了這一個小節(jié),給你指個路,有興趣你可以去看看。
另外,獲得第一名的老哥,其實是一個巨佬:
是 GraalVM 項目的負(fù)責(zé)人之一:

巨人肩膀
在官方的 github 項目的最后,有這樣的一個部分:
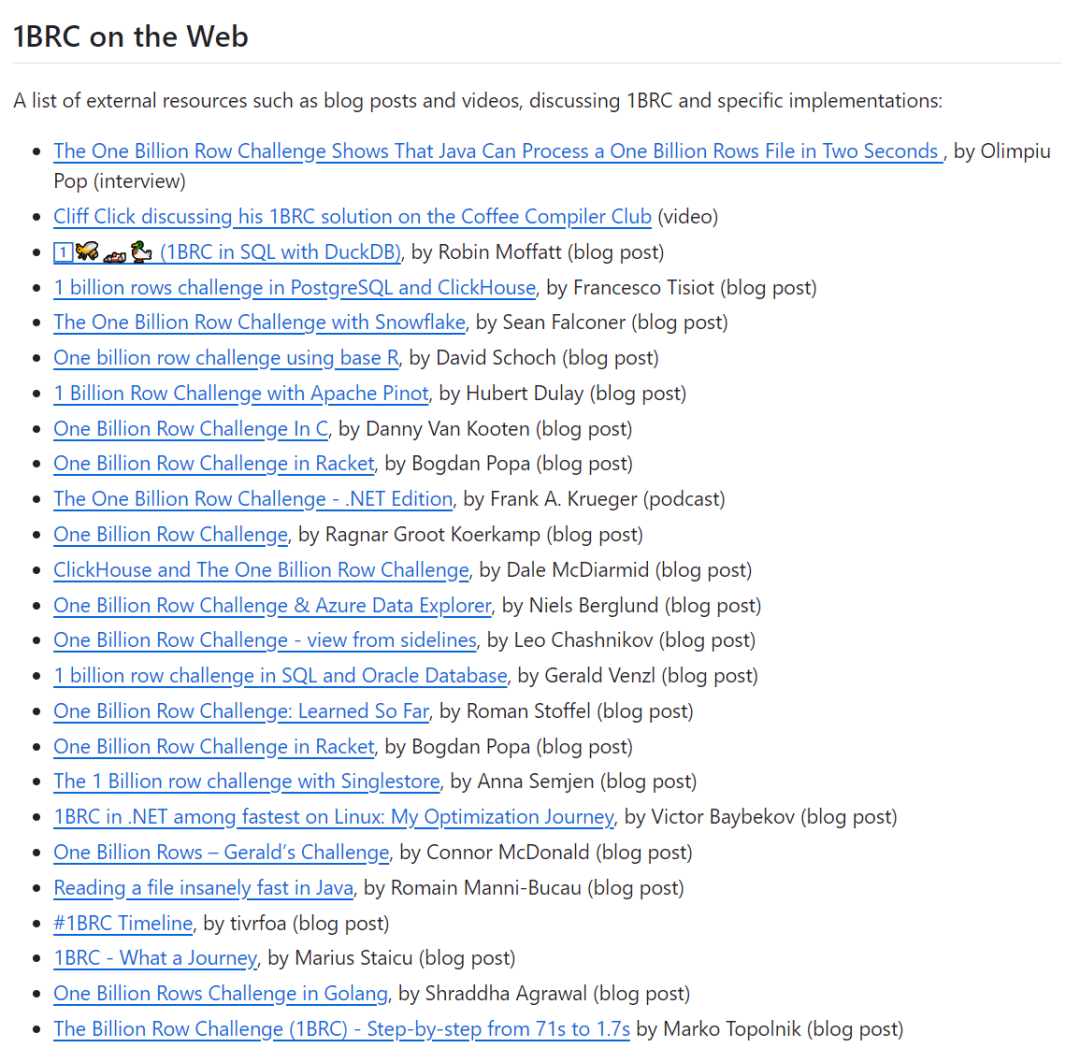
其中最后一篇文章,是一個叫做 Marko Topolnik 的老哥寫的。
我看了一下,這個哥們的官方成績是 2.332 秒,榜單第九名:

但是按照他自己的描述,在比賽結(jié)束后他還繼續(xù)優(yōu)化了代碼,最終可以跑到 1.7s,排名第四。
在他的文章中詳細的描述了他的挑戰(zhàn)過程和思路。
我就站在巨人的肩膀上,帶大家看看這位大佬從 71s 到 1.7s 的破題之道:
https://questdb.io/blog/billion-row-challenge-step-by-step/
最常規(guī)的代碼
首先,他給了一個常規(guī)實現(xiàn)的代碼,和基線版本的代碼大同小異,只不過是使用了并行流來處理:
https://github.com/mtopolnik/billion-row-challenge/blob/main/src/Blog1.java
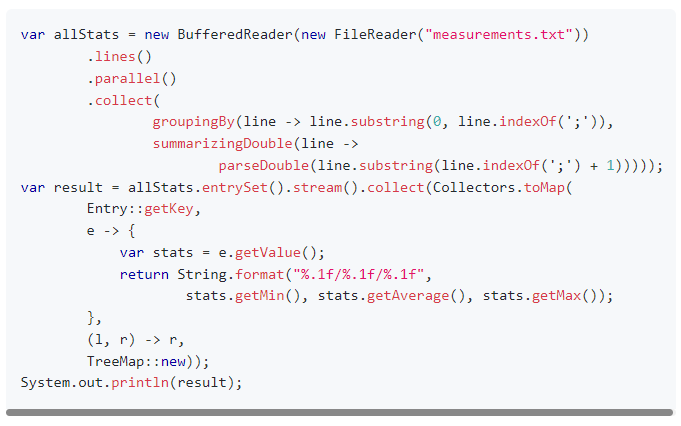
平時看到流式編程我是有點頭疼的,需要稍微的反應(yīng)一下,但是在看了前三名的最終代碼后再看這個代碼,我覺得很親切。
根據(jù)作者的描述,這段代碼:
- 使用并行 Java 流,將所有 CPU 核心都用起來了。
- 也不會陷入任何已知的性能陷阱,比如 Java 正則表達式
在一臺裝有 OpenJDK 21.0.2 的 Hetzner CCX33 機器上,跑完需要的時間為 71 秒。
第 0 版優(yōu)化:換個好的 JVM
叫做第 0 版優(yōu)化的原因是作者對于代碼其實啥也沒動,只是換了一個 JVM:

默認(rèn)使用 GraalVM 之后,最常規(guī)的代碼,運行時間從 71s 到了 66s,相當(dāng)于白撿了 5s,我問就你香不香。
同時作者還提到一句話:
When we get deeper into optimizing and bring down the runtime to 2-3 seconds, eliminating the JVM startup provides another 150-200ms in relief. That becomes a big deal.
當(dāng)我們把程序優(yōu)化到運行時間只需要 2-3 秒的時候,使用 GraalVM,會消除 JVM 的啟動時間,從而提供額外的 150-200ms 的提升。
到那個時候,這個就變得非常重要了。
數(shù)據(jù)指標(biāo)很重要
在正式進入優(yōu)化之前,作者先介紹了他使用到的三個非常重要的工具:

關(guān)于工具我就不過多介紹了,這里單獨提一嘴主要是想表達一個貫穿整個優(yōu)化過程的中心思想:數(shù)據(jù)指標(biāo)很重要。
你只有收集到了當(dāng)前程序足夠多的運行指標(biāo),才能對你進行下一步優(yōu)化時提供直觀的、優(yōu)化方向上的指導(dǎo)。
工欲善其事必先利其器,就是這個道理。
第一版優(yōu)化:并行 I/O 搞起來
通過查看當(dāng)前代碼對應(yīng)的火焰圖:
https://questdb.io/html/blog/profile-blog1

通過火焰圖以及觀察 GC 情況,作者發(fā)現(xiàn)當(dāng)前耗時的地方注意是這三個地方:

- BufferedReader 將每行文本輸出為字符串
- 處理每一行的字符串
- 垃圾收集 (GC):使用 VisualGC 可以看到,差不多每秒要 GC 10 次甚至更多。
可以發(fā)現(xiàn) BufferedReader 占用了大量的性能,因為當(dāng)前讀取文件還是一行行讀取的嘛,性能很差。
于是大多數(shù)人意識到的第一件事就是采用并行化 I/O。
所以,我們需要把待處理的文件分塊。分多少塊呢?
有多少個線程就分成多少個塊,每個線程各自處理一個塊,這樣性能就上去了。
文件分塊讀取,大家自然而然的就想到了 mmap 相關(guān)的方法。
mmap 可以用 ByteBuffer API 來搞事情,但是使用的索引是 int 類型,所以可映射的大小有 2GB 的限制。
前面說了,在這個挑戰(zhàn)中,光是文件大小就有 13G,所以 2GB 是捉襟見肘的。
但是在 JDK 21 中,支持一個叫做 MemorySegment 的東西,也可以干 mmap 一樣的事情,但是它的索引使用的是 long,相當(dāng)于沒有內(nèi)存限制了。
除了使用 MemorySegment 外,還有一些細節(jié)的處理,比如找到正確的分割文件的位置、啟動線程、等待線程處理完成等等。
處理這些細節(jié)會導(dǎo)致這一版的代碼從最初的 17 行增加到了 120 行。
這是優(yōu)化后的代碼地址:
https://github.com/mtopolnik/billion-row-challenge/blob/main/src/Blog2.java
在這個賽題下,我們肯定是需要再循環(huán)中進行數(shù)據(jù)的解析和處理的,所以循環(huán)就是非常重要的一個點。
我們可以關(guān)注一下代碼中的循環(huán)部分,這里面有一個小細節(jié):

這個循環(huán)是每個線程在按塊讀取文件大小,里面用到了 findByte 方法和 stringAt 方法。
在第一個版本中,我們是用的 BufferedReader 把一行內(nèi)容以字符串的形式讀進來,然后按照分號分隔,并生成城市和溫度兩個字符串。
這個過程就涉及到三個字符串了。
但是這個哥們的思路是啥?
自定義一個 findByte 方法,先找到分號的位置,然后把下標(biāo)返回回去。
再用自定義的 stringAt 方法,結(jié)合前面找到的下標(biāo),直接解析出“城市和溫度”這兩個字符串,減少了整行讀取的內(nèi)存消耗。
相當(dāng)于少了一億個字符串,在字符串處理和 GC 方面取得了不錯的表現(xiàn)。
這一波操作下來,處理時間直接從 66s 下降到了 17s:

然后再看火焰圖:
https://questdb.io/html/blog/profile-blog2-variant1

可以發(fā)現(xiàn) GC 的時間幾乎消失了。
CPU 現(xiàn)在大部分時間都花在自定義的 stringAt 上。還有相當(dāng)多的時間花在 Map.computeIfAbsent 方法 、Double.parseDouble 方法和 findByte 方法
其中 Double.parseDouble 方法是解析溫度用的。
作者打算先把這個地方給攻下來。
第二版優(yōu)化:優(yōu)化溫度解析方法
在這版優(yōu)化中,作者直接將溫度解析為整數(shù)。
首先,目前的做法是,首先分配一個字符串,然后對其調(diào)用 parseDouble() 方法,最后轉(zhuǎn)換為整數(shù)以進行高效的存儲和計算。
但是,其實我們應(yīng)該直接創(chuàng)建整數(shù)出來,沒必要走字符串繞一圈。
同時我們知道,溫度的取值范圍是 [-99.9,99.9],所以針對這個范圍,我們搞個自定義方法就行了:
private int parseTemperature(long semicolonPos) {
long off = semicolonPos + 1;
int sign = 1;
byte b = chunk.get(JAVA_BYTE, off++);
if (b == '-') {
sign = -1;
b = chunk.get(JAVA_BYTE, off++);
}
int temp = b - '0';
b = chunk.get(JAVA_BYTE, off++);
if (b != '.') {
temp = 10 * temp + b - '0';
// we found two integer digits. The next char is definitely '.', skip it:
off++;
}
b = chunk.get(JAVA_BYTE, off);
temp = 10 * temp + b - '0';
return sign * temp;
}
這波操作下來,處理時間又減少了 6s,來到了 11s:
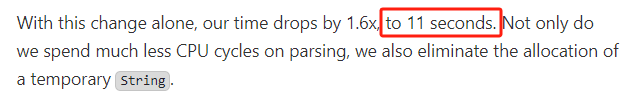
再看對應(yīng)火焰圖:
https://questdb.io/html/blog/profile-blog2-variant2

溫度解析部分的耗時占比從 21.43% 降低到 6%,說明是一次正確的優(yōu)化。
接下來,可以再搞一搞 stringAt 方法了。
第三版優(yōu)化:自定義哈希表
首先,要優(yōu)化 stringAt 方法,我們得知道它是干啥的。
我們看一眼代碼:
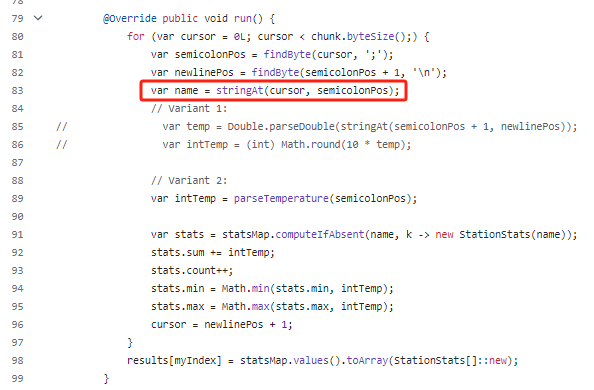
在經(jīng)歷了上一波優(yōu)化之后,stringAt 目前在代碼中的唯一作用就是為了獲取氣象站的名稱。
而獲取到這個名稱的唯一目的是看看當(dāng)前的 HashMap 中有沒有這個氣象站的數(shù)據(jù),如果沒有就新建一個 StationStats 對象,如果有就把之前的 StationStats 對象拿出來進行數(shù)據(jù)維護。
此外,在賽題中還有這樣的一個信息,雖然有一億行數(shù)據(jù),但是只有 413 個氣象站:

既然 key 的大小是可控的,那基于這個條件,作者想了一個什么樣的騷操作呢?
他直接不用 HashMap 了,自定義了一個哈希表,長這樣的:
https://github.com/mtopolnik/billion-row-challenge/blob/main/src/Blog3.java

主要看一下代碼中的 findAcc 方法,你就能明白它是干啥的了:
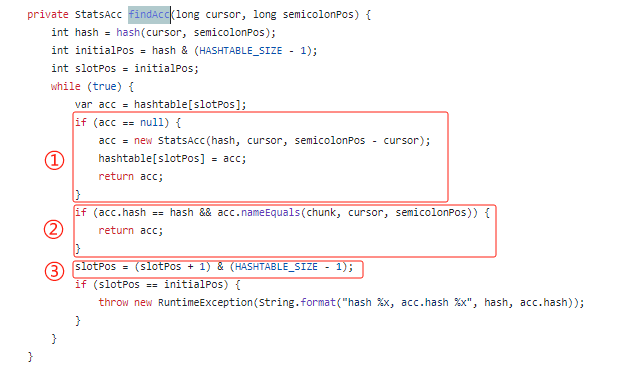
通過 hash 方法計算出指定字符串,即氣象站名稱的 hash 值之后,從自定義的 hashtable 中取出該位置的數(shù)據(jù)。
首先標(biāo)號為 ① 的地方,如果沒有取到數(shù)據(jù),則說明沒有這個氣象站的數(shù)據(jù),新建一個放好,返回就完事。
如果取到了數(shù)據(jù),來到標(biāo)號為 ② 的地方,看看取到的數(shù)據(jù)和當(dāng)前要放的數(shù)據(jù)對應(yīng)的氣象站名稱是不是一樣的。
如果是則說明已經(jīng)有了,取出來,然后返回。
如果不是,說明啥情況?
說明 hash 沖突了,來到標(biāo)號為 ③ 的地方進行下標(biāo)加一的動作。
然后再次進行循環(huán)。
來,你告訴我,這是什么手法?
這不就是開放尋址來解決 hash 沖突嗎?
所以 findAcc 方法,就可以替代 computeIfAbsent 方法。
通過自定義的 StatsAcc 哈希表來代替原生的 HashMap。
而且前面說了,key 的大小是可控的,如果自定義 hash 表的初始化大小控制的合適,那么整個 hash 沖突的情況也不會非常嚴(yán)重。
這一波組合拳下來,運行時間來到了 6.6s,火焰圖變成了這樣:
https://questdb.io/html/blog/profile-blog3

大量的時間花在了前面分析的 findAcc 方法上。
同時作者提到了這樣一句話:

同樣的代碼,如果放到 OpenJDK 上跑需要運行 9.6s,比 GraalVM 慢了 3.3s。
我滴個乖乖,這就是一個 45% 的性能提升啊。
第四版優(yōu)化:使用 Unsafe 和 SWAR
在這一版優(yōu)化開始之前,作者先寫了這樣一段話:

大概意思就是說,到目前為止,我們用到的都是常規(guī)且有效的解決方案,并且是 Java 標(biāo)準(zhǔn)、安全的用法。
即使止步于此也能學(xué)到很多優(yōu)化技巧,可以在實際的項目中進行使用。
如果你繼續(xù)往下探索,那么:
Readability and maintainability also take a big hit, while providing diminishing returns in performance. But, a challenge is a challenge, and the contestants pressed on without looking back!
可讀性和可維護性也會受到重創(chuàng),同時性能的收益會遞減。但是,挑戰(zhàn)就是挑戰(zhàn),參賽者們繼續(xù)努力,沒有回頭!
簡單來說,作者的意思就是打個預(yù)防針:接下來就要開始上強度了。
所以,在這個版本中,作者應(yīng)用一些排名靠前的選上都在用的方案:
- 使用 sun.misc.Unsafe 而不是 MemorySegment,來避免邊界檢查
- 避免重新讀取相同的輸入字節(jié):重復(fù)使用加載的值進行哈希和分號搜索
- 每次處理 8 個字節(jié)的數(shù)據(jù),使用 SWAR 技術(shù)找到分號分隔符。
- 使用 merykitty 老哥提供的牛逼的 SWAR(SIMD Within A Register)代碼解析溫度。
這是這一版的代碼:
https://github.com/mtopolnik/billion-row-challenge/blob/main/src/Blog4.java
比如其中關(guān)于循環(huán)處理數(shù)據(jù)的部分,看起來就很之前很不一樣了:
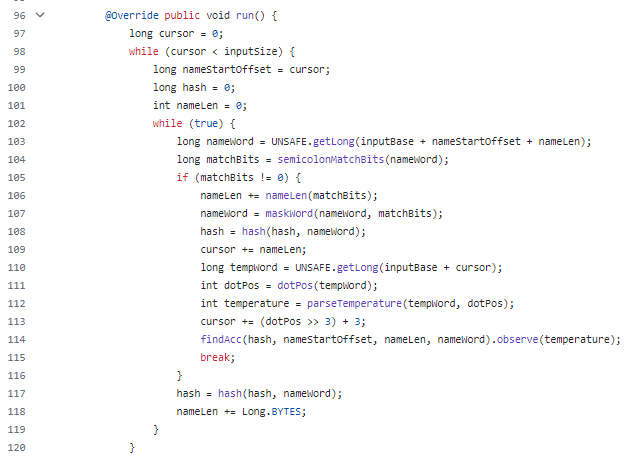
然后你再看里面 semicolonMatchBits、nameLen、maskWord、dotPos、parseTemperature 這些方法的調(diào)用,直接就是一個懵逼的狀態(tài),看著頭都大了:

但是你仔細看,你會發(fā)現(xiàn)這幾個方法是作者從其他人那邊學(xué)來的:
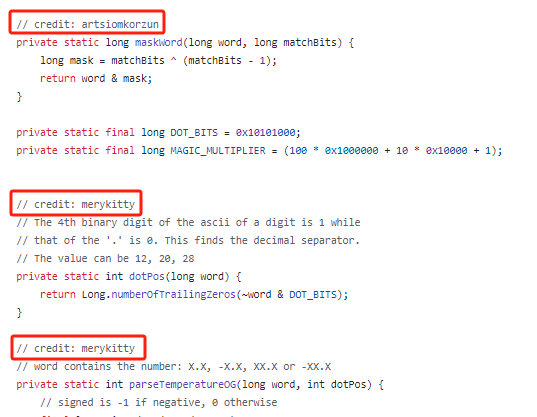
比如這個叫做 merykitty 的老哥,提供了解析溫度的代碼,雖然作者加入了大量的注釋說明,但是我也只是大概就看懂了不到三層吧。
這里面大量的使用了位運算的技巧,同時你仔細看:幾乎沒有 if 判斷的存在。這是重點,用直接的位運算替換了分支指令,從而減少了分支預(yù)測錯誤的成本。
此外,還有很多我第一次見、叫不上名字的奇技淫巧。
通過這一波“我看不懂,但是我大受震撼”的操作搞下來,時間降低到了 2.4s:

第五版優(yōu)化:統(tǒng)計學(xué)用起來
現(xiàn)在,我們的火焰圖變成了這樣:
https://questdb.io/html/blog/profile-blog4

耗時主要還是在于 findAcc 方法:

而 findAcc 方法的耗時在于 nameEquals 方法,判斷當(dāng)前氣象站名稱是否出現(xiàn)過:

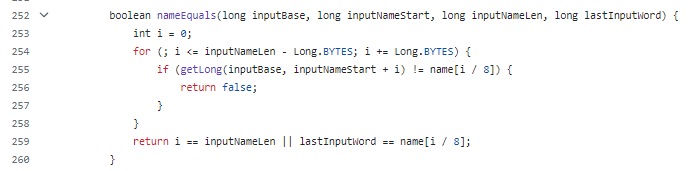
但是這個方法里面有個 if 判斷,以字節(jié)為單位比較兩個字符串的內(nèi)容,每次比較 8 個字節(jié)。
首先,它通過循環(huán)逐步比較兩個字符串中的對應(yīng)字節(jié)。在每次迭代中,它使用 getLong 方法從輸入字符串中獲取一個 64 位的長整型值,并與另一個字符串中的相應(yīng)位置進行比較。如果發(fā)現(xiàn)不相等的字節(jié),則返回 false,表示兩個字符串不相等。
如果循環(huán)結(jié)束后沒有發(fā)現(xiàn)不相等的字節(jié),它會繼續(xù)檢查是否已經(jīng)比較了輸入字符串的所有字節(jié),或者最后一個輸入字符串的字節(jié)與相應(yīng)位置的字符串字節(jié)相等,那么表示兩個字符串相等,則返回 true。
那么問題就來了?
如果氣象站名稱長度全都是小于 8 個字節(jié),會出現(xiàn)啥情況?
假設(shè)有這樣的一個前提條件,是不是我們就不用在 for 循環(huán)中進行 if 判斷了,直接一把就比較完成了?
很可惜,沒有這樣一個提前條件。
但是,如果在數(shù)據(jù)集中,氣象站名稱長度絕大部分都小于 8 個字節(jié)那是不是就可以單獨處理一下?
那到底數(shù)據(jù)分布是怎么樣的呢?
這個問題問題出去的一瞬間,統(tǒng)計學(xué)啪的一下就站出來了:這個老子在行,我算算。
所以,作者寫了一個程序來統(tǒng)計分析數(shù)據(jù)集中氣象站名稱的長度:
https://github.com/mtopolnik/billion-row-challenge/blob/main/src/Statistics.java
基于程序運行結(jié)果,最終的結(jié)論如下:

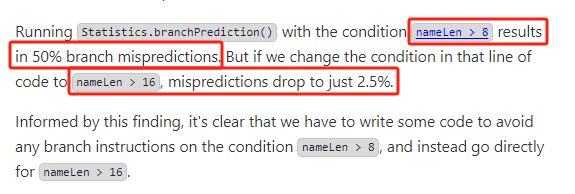
通過分析作者發(fā)現(xiàn),賽題的數(shù)據(jù)集中氣象站名稱長度幾乎均勻分布在 8 字節(jié)以上和 8 字節(jié)以下。
運行 Statistics.branchPrediction 方法,當(dāng)條件是 nameLen > 8 時導(dǎo)致了 50% 的分支預(yù)測失敗。
也就是說,一億數(shù)據(jù)中有一半的數(shù)據(jù),都是小于 8 字節(jié)的,都是不用特意進行 if 判斷的。
但如果將條件更改為 nameLen > 16,那么預(yù)測失敗率將降至 2.5%。
根據(jù)這一發(fā)現(xiàn),很明顯,如果要進一步優(yōu)化代碼,就需要編寫一些特定的代碼來避免在 nameLen > 8 上使用任何 if 判斷,直接使用 nameLen > 16 就行。
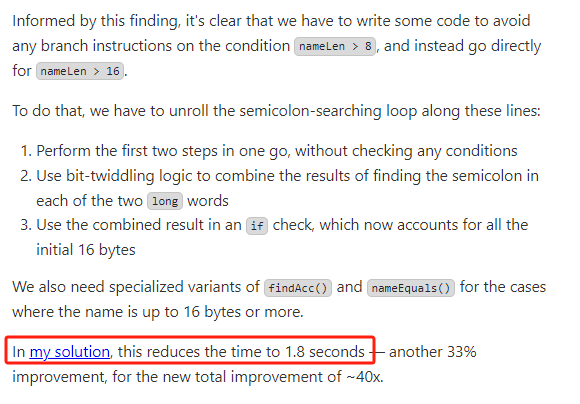
這是這一版的最終代碼,可讀性越來越差了:
https://github.com/mtopolnik/billion-row-challenge/blob/main/src/Blog5.java
但是最終的成績是 1.8s:
哦,對了,如果你對于分支預(yù)測技術(shù)不太清楚,那你可能看得比較懵。
但是分支預(yù)測,在性能挑戰(zhàn)中,特別是最后大家比分都咬的非常緊的情況下,每次都是屢立奇功,戰(zhàn)功赫赫,屬于高手間過招殺手锏級別的優(yōu)化手段。
繼續(xù)優(yōu)化
再后面作者還有這兩個部分。
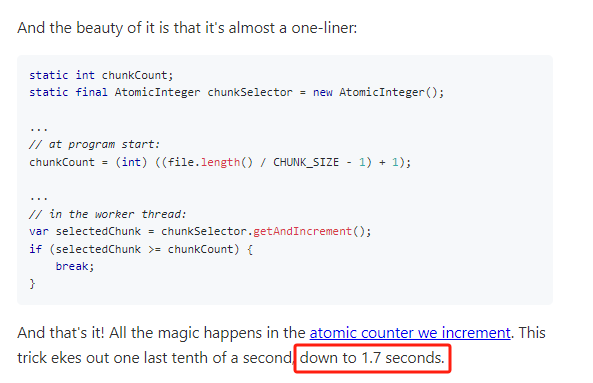
消除啟動/清理成本:

使用更小的文件分塊和工作竊取機制:

這后面就完全是基于這個賽題進行定制化的優(yōu)化,可移植性不強了,作者就沒有進行詳細描述,再加上一個我也是沒怎么看明白,就不展開講了。
反正這兩個組合拳下來,又搞了 0.1s 的時間下來,最終的成績?yōu)?1.7s:
我實在是學(xué)不動了,有興趣的同學(xué)可以自己去看看原文的對應(yīng)部分。

寫在后面
其實關(guān)于這篇文章,我原想法是看懂前三名的代碼,然后對代碼進行解析、對比,找到他們思路的共同點和差異點,但是后來他們的代碼確實我看不懂,所以我放棄了這個想法。
但是我知道,只要我愿意花時間、有足夠的時間,我肯定可以慢慢地把他們的這幾百行代碼啃透,但是我也只是想了想而已,很快就放棄了這個思路。
我想如果是大學(xué)的時候,我看到這個比賽,我會覺得,真牛逼,我得好好研究一下。
然而現(xiàn)在不一樣了,參加工作了,看到了這個比賽,我還是會覺得,真牛逼,但是對我寫業(yè)務(wù)代碼幫助不大,就不深究了,淺嘗輒止。
大學(xué)的時候?qū)W習(xí)是靠自己無窮的精力和對于掌握新知識的樂趣撐著,現(xiàn)在學(xué)習(xí)主要靠一時沖動。
但是我還是強烈建議感興趣的朋友,按照我問中提到的地址,自己去研究一波別人提交的代碼。
也許你也會產(chǎn)生一樣的疑問:他們寫的 Java 和我會的 Java 是同一個 Java 嗎?
我的答案是:不是的,他們寫的 Java 是自己熱愛的 Java,我們寫的 Java 只是掙錢的 Java。
沒有高低貴賤之分,但是能讓你不經(jīng)意間,從業(yè)務(wù)代碼的深海中抬頭看一眼,看到自己熟悉的領(lǐng)域中,更廣闊的世界。
好啦,本文的技術(shù)部分就到這里了。
下面這個環(huán)節(jié)叫做[荒腔走板],技術(shù)文章后面我偶爾會記錄、分享點生活相關(guān)的事情,和技術(shù)毫無關(guān)系。我知道看起來很突兀,但是我喜歡,因為這是一個普通博主的生活氣息。
荒腔走板

周末的時候去成都龍泉山的高空棧道上走了一圈,高確實是高,但是看得并不遠。
一路上我都在和 Max 同學(xué)吐槽成都的天氣,準(zhǔn)確的說,是吐槽成都冬天和秋天的天氣。
秋天就不說了,一句歌詞帶過:在這座陰雨的小城里...
成都的冬天保守點說,可能有三分之二都是圖片中這樣的天氣。
身處盆地,霧散不開,導(dǎo)致冬天的太陽真的太少了,只會在中午大概十一點多的時候稍微的意思一下,讓你瞅一眼之后它藏起來準(zhǔn)備下班了,藍天白云就更少了。
周末的太陽,那就更少見了。
只有夏天好一點,但是夏天又熱得不行,完全離不開空調(diào)。
成都是個生活便利的城市一點不假,但是對于從四季分明的地區(qū)過來的朋友,它真的就不夠友好了,甚至是致郁的。
我記得以前成都有冬天的幾次周末出了大太陽,然后上了微博熱搜。有評論說:不虧是網(wǎng)紅城市,出個太陽都能上熱搜。
但是你確實得理解成都人民在秋天和冬天的周末看到太陽的欣喜若狂。
每一個有太陽的周末,都是值得記錄的日子,每一塊草坪上都會長滿了四面八方涌來的成都人。
什么,你問我為什么不提春天?
成都的春天,只有半個月的時間,加兩個班就悄悄咪咪的溜走了,不值一提。
所以有非常多的朋友來成都問我玩什么?
我的回答都是,來成都市里面可以玩的地方非常少,都是人文風(fēng)景,而且天氣大多都不好,看不到好景色。如果要看自然風(fēng)光,首推川西環(huán)線(可惜大多數(shù)人沒有這么多時間),然后九寨溝什么的,總之成都好玩的地方在成都周邊
但是你要是來吃東西的,那就不一樣了,在市里面你可以吃到非常非常多的好吃的:
火鍋 串 串 干鍋 冒菜 抄手 米粉 豆花 鍋盔 涼粉 涼糕 冰粉 三大炮 缽缽雞 冷鍋魚 冷吃兔 肥腸粉 毛血旺 冷沾沾 擔(dān)擔(dān)面 口水雞 韓包子 鐘水餃 懶湯圓 葉兒粑 甜水面 奶湯面 龍抄手 炒龍蝦 江油肥腸 牛肉焦餅 龍眼包子 夫妻肺片 珍珠丸子 水煮肉片 李莊白肉 燈影牛肉 瀘州黃粑 雞絲涼面 麻婆豆腐 蹺腳牛肉 蓮茸層層酥 酥盒回鍋肉 紅鍋黃辣丁...
那個不巴適!
·············· END ··············

推薦?? : 單表最好不超過2000萬條數(shù)據(jù)?
推薦?? : 準(zhǔn)備去大廠和剛?cè)ゴ髲S的,全文背誦,常看常新。
推薦?? : 線程池參數(shù)請不要這樣設(shè)置。
推薦?? : 一個普通程序員磕磕絆絆,又閃閃發(fā)光的十年。
你好呀,我是歪歪。我沒進過一線大廠,沒創(chuàng)過業(yè),也沒寫過書,更不是技術(shù)專家,所以也沒有什么亮眼的title。
當(dāng)年高考,隨緣調(diào)劑到了某二本院校計算機專業(yè)。純屬誤打誤撞,進入程序員的行列,之后開始了運氣爆棚的程序員之路。
說起程序員之路還是有點意思,可以 點擊藍字,查看我的程序員之路。