
【NLP】DataCLUE: 國內(nèi)首個(gè)以數(shù)據(jù)為中心的AI測評
DataCLUE
以數(shù)據(jù)為中心的AI測評(含模型和數(shù)據(jù)分析報(bào)告)
DataCLUE: A Chinese Data-centric Language Evaluation Benchmark
Github項(xiàng)目地址:
https://github.com/CLUEbenchmark/DataCLUE
官網(wǎng):
www.CLUEbenchmarks.com/dataclue.html 或 www.clue.ai
內(nèi)容導(dǎo)引
| 章節(jié) | 描述 |
|---|---|
| 簡介 | 介紹以數(shù)據(jù)為中心的AI測評(DataCLUE)的背景 |
| 任務(wù)描述 | 任務(wù)描述 |
| 實(shí)驗(yàn)結(jié)果 | 針對各種不同方法,在FewCLUE上的實(shí)驗(yàn)對比 |
| 實(shí)驗(yàn)分析 | 對人類表現(xiàn)、模型能力和任務(wù)進(jìn)行分析 |
| 數(shù)據(jù)為中心的AI_方法論介紹 | 數(shù)據(jù)為中心的AI:方法論介紹 |
| DataCLUE有什么特點(diǎn) | 特點(diǎn)介紹 |
| 基線模型及運(yùn)行 | 支持多種基線模型 |
| DataCLUE測評及規(guī)則 | DataCLUE測評及規(guī)則 |
| 數(shù)據(jù)集介紹 | 介紹數(shù)據(jù)集及示例 |
| 貢獻(xiàn)與參與 | 如何參與項(xiàng)目或反饋問題 |
簡介
以數(shù)據(jù)為中心(Data-centric)的AI,是一種新型的AI探索方向。它的核心問題是如何通過系統(tǒng)化的改造你的數(shù)據(jù)(無論是輸入或者標(biāo)簽)來提高最終效果。傳統(tǒng)的AI是以模型為中心(Model-centric)的,主要考慮的問題是如何通過改造或優(yōu)化模型來提高最終效果,它通常建立在一個(gè)比較固定的數(shù)據(jù)集上。最新的數(shù)據(jù)顯示超過90%的論文都是以模型為中心的,通過模型創(chuàng)新或?qū)W習(xí)方法改進(jìn)提高效果,即使不少改進(jìn)影響可能效果并不是特別明顯。有些人認(rèn)為當(dāng)前的人工智能領(lǐng)域, 無論是自然語言處理(如BERT) 或計(jì)算機(jī)視覺(ResNet), 已經(jīng)存在很多成熟高效模型,并且模型可以很容易從開源網(wǎng)站如github獲得;而與此同時(shí),工業(yè)界實(shí)際落地 過程中可能有80%的時(shí)間用于 清洗數(shù)據(jù)、構(gòu)建高質(zhì)量數(shù)據(jù)集,或在迭代過程中獲得更多數(shù)據(jù),從而提升模型效果。正是看到了這種巨大的差別,在吳恩達(dá)等人的推動(dòng)下這種 以數(shù)據(jù)為中心 (Data-centric)的AI進(jìn)一步的系統(tǒng)化,并成為一個(gè)有具有巨大實(shí)用價(jià)值方法論。
DataCLUE是一個(gè)以數(shù)據(jù)為中心的AI測評。它基于CLUE benchmark,結(jié)合Data-centric的AI的典型特征,進(jìn)一步將Data-centric的AI應(yīng)用于 NLP領(lǐng)域,融入文本領(lǐng)域的特定并創(chuàng)造性豐富和發(fā)展了Data-centric的AI。在原始數(shù)據(jù)集外,它通過提供額外的高價(jià)值的數(shù)據(jù)和數(shù)據(jù)和模型分析報(bào)告(增值服務(wù))的形式, 使得融入人類的AI迭代過程(Human-in-the-loop AI pipeline)變得更加高效,并能較大幅度的提升最終效果。
任務(wù)描述
參與測評者需要改進(jìn)任務(wù)下的數(shù)據(jù)集來提升任務(wù)的最終效果;將使用固定的模型和程序代碼(公開)來訓(xùn)練數(shù)據(jù)集,并得到任務(wù)效果的數(shù)據(jù)。可以對訓(xùn)練集、驗(yàn)證集進(jìn)行修改或者移動(dòng)訓(xùn)練集和驗(yàn)證集建的數(shù)據(jù),也可以通過非爬蟲類手段新增數(shù)據(jù)來完善數(shù)據(jù)集。可以通過算法或程序或者結(jié)合人工的方式來改進(jìn)數(shù)據(jù)集。參與測評者需提交修改后的訓(xùn)練集和驗(yàn)證的壓縮包。
任務(wù)描述和統(tǒng)計(jì)

實(shí)驗(yàn)結(jié)果
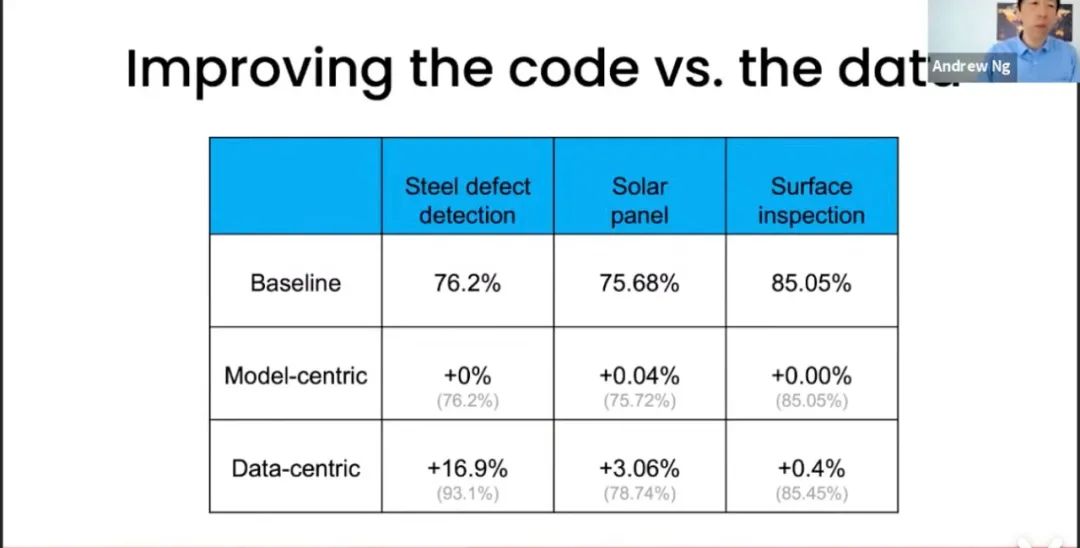
| IFLYTEK(acc) | |
|---|---|
| Human | 80.30 |
| Baseline | 56.42 |
| Model-centric | 59.31 |
| Data-centric | Report on 2021-09-15 |
實(shí)驗(yàn)分析
TODO 這里是實(shí)驗(yàn)分析 需要結(jié)合實(shí)驗(yàn)數(shù)據(jù)做一些說明。以模型為中心、以數(shù)據(jù)為中心效果是否一樣的呢,或者某種方式可以得到更好的效果。
數(shù)據(jù)為中心的AI-方法論介紹
這里簡單介紹一下以數(shù)據(jù)為中心的AI的方法論。包括一張圖介紹一下流程,并做一下說明;可以附加tips。
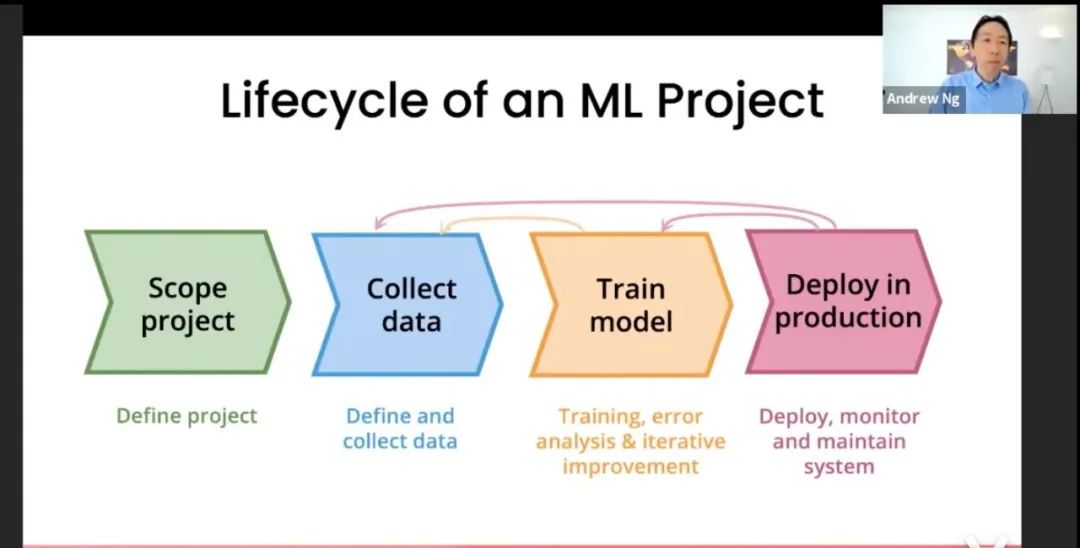
流程圖:1.定義任務(wù)-->2.收集數(shù)據(jù)--->3.訓(xùn)練模型-->4.部署模型
系統(tǒng)化方式、通過迭代形式改進(jìn)數(shù)據(jù)集:
#1.訓(xùn)練模型;
#2.錯(cuò)誤分析:發(fā)現(xiàn)算法模型在哪些類型的數(shù)據(jù)上表現(xiàn)不佳(如:數(shù)據(jù)過短導(dǎo)致語義沒有表達(dá)完全、一些類別間概念容易混淆導(dǎo)致標(biāo)簽可能不正確)
#3.改進(jìn)數(shù)據(jù):
1)更多數(shù)據(jù):數(shù)據(jù)增強(qiáng)、數(shù)據(jù)生成或搜集更多數(shù)據(jù)--->獲得更多的輸入數(shù)據(jù)。
2)更一致的標(biāo)簽定義:當(dāng)有些類別容易混淆的時(shí)候,改進(jìn)標(biāo)簽的定義--->基于清晰的標(biāo)簽定義,糾正部分?jǐn)?shù)據(jù)的標(biāo)簽。
#4.重復(fù)#1-#3的步驟。
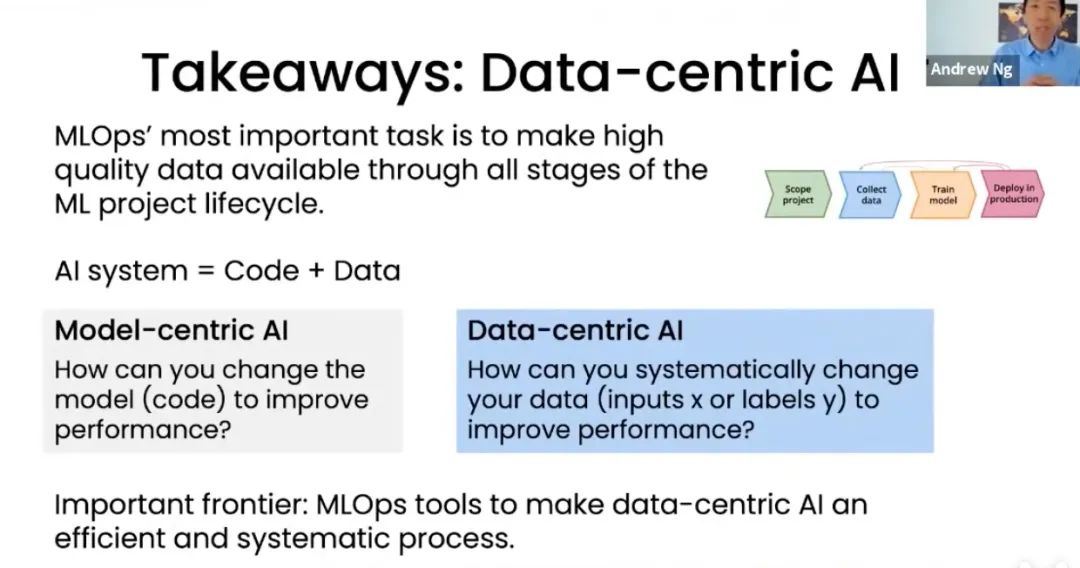
DataCLUE有什么特點(diǎn)
1、國內(nèi)首個(gè)以數(shù)據(jù)為中心的AI測評。之前的測評一般是在固定的數(shù)據(jù)集下使用不同的模型或?qū)W習(xí)方式來提升效果,而DataCLUE是需要改進(jìn)數(shù)據(jù)集。
2、它是中文NLP任務(wù)在以數(shù)據(jù)為中心的思想下的實(shí)踐。
3、更豐富的信息:除了常規(guī)的訓(xùn)練、驗(yàn)證和測試集外,它還額外提供了標(biāo)簽的定義、訓(xùn)練集中進(jìn)一步標(biāo)注后的高質(zhì)量數(shù)據(jù)。結(jié)合這些額外的信息,使得 融入人類的AI迭代閉環(huán)(Human-in-the-loop AI pipeline)可以變得更加高效,并且在發(fā)揮算法模型在數(shù)據(jù)迭代過程中可以有更多空間和潛力。
4、增值服務(wù):我們還額外提供模型訓(xùn)練和預(yù)測過程中的分析報(bào)告,為以數(shù)據(jù)為中心的AI的迭代過程變得更有方向和系統(tǒng)化。
基線模型及運(yùn)行
一鍵運(yùn)行.基線模型與代碼 Baseline with codes
使用方式:
1、克隆項(xiàng)目
git clone https://github.com/CLUEbenchmark/DataCLUE.git
進(jìn)入到項(xiàng)目目錄 cd DataCLUE
2、進(jìn)入到相應(yīng)的目錄
分類任務(wù)
例如:
cd ./baselines/models_pytorch/classifier_pytorch
3、運(yùn)行對應(yīng)任務(wù)的腳本(GPU方式): 會自動(dòng)下載模型和任務(wù)數(shù)據(jù)并開始運(yùn)行。
bash run_classifier_xxx.sh
如運(yùn)行: bash run_classifier_iflytek.sh 會開始iflytek任務(wù)的訓(xùn)練。
訓(xùn)練完后也會得到在驗(yàn)證集上的效果,見 ./output_dir/bert/checkpoint_eval_results.txt
DataCLUE測評及規(guī)則
1.測評方式:
修改訓(xùn)練集和驗(yàn)證集,并將壓縮包上傳到CLUE benchmark
使用如下命令得到壓縮包: zip dataclue_<team_name>_<data_string>.zip train.json dev.json 具體格式見:提交樣例
2.測評規(guī)則:
1.1 可以對訓(xùn)練集、驗(yàn)證集進(jìn)行修改(輸入文本或標(biāo)簽),或者移動(dòng)訓(xùn)練集和驗(yàn)證集的數(shù)據(jù);
1.2 可以通過非爬蟲類手段增加數(shù)據(jù)來完善訓(xùn)練和驗(yàn)證集。增加數(shù)據(jù)方式,包括但不限于:數(shù)據(jù)增強(qiáng)、文本生成、結(jié)合分析定向生成或添加。
1.3 可以通過算法或程序,或者結(jié)合人工的方式來改進(jìn)數(shù)據(jù)集;
2.1 鼓勵(lì)通過結(jié)合算法、模型和程序來改進(jìn)數(shù)據(jù)集,也同樣鼓勵(lì)算法模型結(jié)合人工進(jìn)行數(shù)據(jù)改進(jìn);但純?nèi)斯し绞降臄?shù)據(jù)改進(jìn),評審環(huán)節(jié)將不得分。
3.測評時(shí)間規(guī)劃:2021年9月12日---2021年12月12日
1) 報(bào)名開始與截止:2021年9月12日--2021年10月25日
2) 初賽:2021年9月12日--2021年10月30日。前80名并超過Data-centric的baseline進(jìn)入到復(fù)賽。初始選手,也將獲得數(shù)據(jù)和模型的分析報(bào)告(簡稱增值服務(wù))
訓(xùn)練集 & 驗(yàn)證集提供:2021年9月12;提交入口開放:2021年9月15日;每天22點(diǎn)更新一次在線成績。
3) 復(fù)賽:2021年11月1日--2021年12月5日。復(fù)賽時(shí),將提供額外高質(zhì)量標(biāo)注數(shù)據(jù)。前15名進(jìn)入到線上評審,進(jìn)行在線答辯。
4) 線上評審:2021年12月12日(下午2點(diǎn)-5點(diǎn))。最終成績:線上得分* 0.65 + 線上方案評審 * 0.35
線上方案評審:方案評審?fù)ㄟ^考察參賽隊(duì)伍提交方案的新穎性、實(shí)用性和解釋答辯表現(xiàn)力來打分,由5位評審老師打分;
每只隊(duì)伍有10分鐘的時(shí)間講解方案,5分鐘來回答問題。方案評審將以直播方法進(jìn)行。
數(shù)據(jù)集介紹
1、IFLYTEK 長文本分類數(shù)據(jù)集 Long Text classification 該數(shù)據(jù)集關(guān)于app應(yīng)用描述的長文本標(biāo)注數(shù)據(jù),包含和日常生活相關(guān)的各類應(yīng)用主題,共119個(gè)類別:"打車":0,"地圖導(dǎo)航":1,"免費(fèi)WIFI":2,"租車":3,…. ,"女性":115,"經(jīng)營":116,"收款":117,"其他":118(分別用0-118表示)。
數(shù)量,訓(xùn)練集:12133 ;驗(yàn)證集:2599
例子:
{"label": "110", "label_des": "社區(qū)超市", "sentence": "樸樸快送超市創(chuàng)立于2016年,專注于打造移動(dòng)端30分鐘即時(shí)配送一站式購物平臺,商品品類包含水果、蔬菜、肉禽蛋奶、海鮮水產(chǎn)、糧油調(diào)味、酒水飲料、休閑食品、日用品、外賣等。樸樸公司希望能以全新的商業(yè)模式,更高效快捷的倉儲配送模式,致力于成為更快、更好、更多、更省的在線零售平臺,帶給消費(fèi)者更好的消費(fèi)體驗(yàn),同時(shí)推動(dòng)中國食品安全進(jìn)程,成為一家讓社會尊敬的互聯(lián)網(wǎng)公司。,樸樸一下,又好又快,1.配送時(shí)間提示更加清晰友好2.保障用戶隱私的一些優(yōu)化3.其他提高使用體驗(yàn)的調(diào)整4.修復(fù)了一些已知bug"}
每一條數(shù)據(jù)有三個(gè)屬性,從前往后分別是 類別ID,類別名稱,文本內(nèi)容。學(xué)習(xí)資料
1、吳恩達(dá)新課:從以模型為中心到以數(shù)據(jù)為中心的AI(1小時(shí))
貢獻(xiàn)與參與
往期精彩回顧 本站qq群851320808,加入微信群請掃碼: