
pandas常用字符串處理方法看這一篇就夠了

添加微信號"CNFeffery"加入技術交流群
?本文示例代碼及文件已上傳至我的
?Github倉庫https://github.com/CNFeffery/DataScienceStudyNotes
1 簡介
在日常開展數(shù)據(jù)分析的過程中,我們經常需要對字符串類型數(shù)據(jù)進行處理,此類過程往往都比較繁瑣,而pandas作為表格數(shù)據(jù)分析利器,其內置的基于Series.str訪問器的諸多針對字符串進行處理的方法,以及一些top-level級的內置函數(shù),則可以幫助我們大大提升字符串型數(shù)據(jù)處理的效率。
本文我就將帶大家學習pandas中常用的一些高效字符串處理方法,提升日常數(shù)據(jù)處理分析效率??:

2 pandas常用字符串處理方法
pandas中的常用字符串處理方法,可分為以下幾類:
2.1 拼接合成類方法
這一類方法主要是基于原有的Series數(shù)據(jù),按照一定的規(guī)則,利用拼接或映射等方法合成出新的Series,主要有:
2.1.1 利用join()方法按照指定連接符進行字符串連接
當原有的Series中每個元素均為列表,且列表中元素均為字符串時,就可以利用str.join()來將每個列表按照指定的連接符進行連接,主要參數(shù)有:
「sep:」?str型,必選,用于設置連接符
它除了可以簡化我們常規(guī)使用apply()配合'連接符'.join(列表)實現(xiàn)的等價過程之外,還可以在列表中包含非字符型元素時自動跳過此次拼接返回缺失值,譬如下面的例子:
s?=?pd.Series([
????['a',?'b',?'c'],
????[1,?'a',?'b'],
????list('pandas')
])
s.str.join('-')

2.1.2 利用cat()方法進行字符串拼接
當需要對整個序列進行拼接,或者將多個序列按位置進行元素級拼接時,就可以使用str.cat()方法來加速這個過程,其主要參數(shù)有:
「others:」?序列型,可選,用于傳入待進行按位置元素級拼接的字符串序列對象 「sep:」?str型,可選,用于設置連接符,默認為 ''「na_rep:」?str型,可選,用于設置對缺失值的替換值,默認為 None時:當 others參數(shù)未設置時,返回的拼接結果中缺失項自動跳過當 others參數(shù)設置時,兩邊的序列對應位置上存在缺失值時,拼接結果對應位置返回缺失值
下面是一些簡單的例子:

2.2 判斷類方法
判斷類方法在這里指的是針對字符型Series,按照一定的條件判斷從而返回與原序列等長的bool型序列,可進一步輔助數(shù)據(jù)篩選等操作,在pandas中此類字符串處理方法主要有:
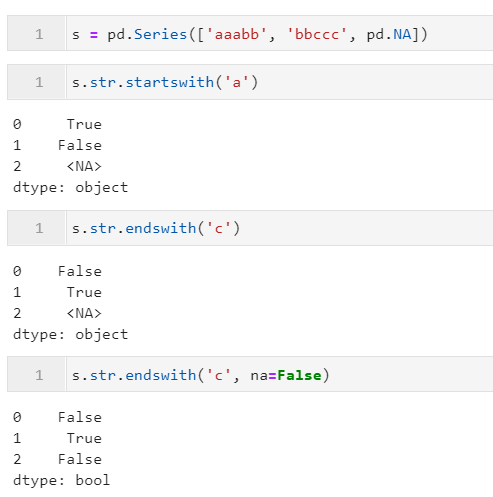
2.2.1 利用startswith()與endswith()匹配字符串首尾
當我們需要判斷字符型Series中的每個元素是否以某段字符片段開頭或結尾時,就可以使用到startswith()/endswith(),它們的參數(shù)一致:
「pat:」?str型,用于定義要檢查的字符片段 「na:」?任意對象,當對應位置元素為空值時,用于自定義該位置返回判斷結果,默認為 NaN,會原值返回,通常建議設置為False
下面是一些簡單的例子:
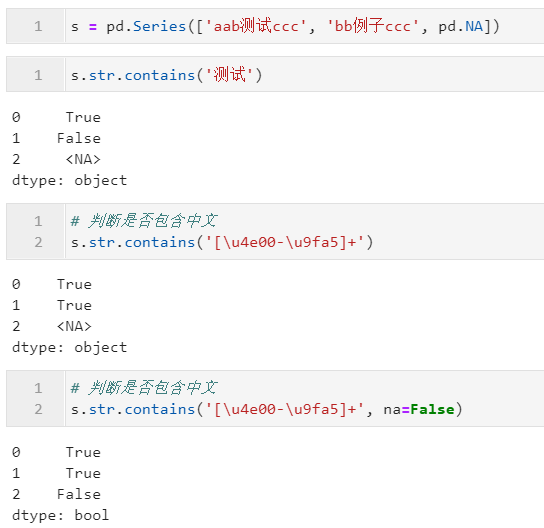
2.2.2 利用contains()判斷是否包含指定模式
當我們想要判斷字符型Series中每個元素,是否包含指定的字符片段或正則模式時,則可以使用到str.contains()方法,其主要參數(shù)有:
「pat:」?str型,必選,用于定義要檢查的字符模式,當 regex=True時表示正則表達式,當regex=False時,表示原始字符串片段「flags:」?int型,可選,對應 re模塊中的flags參數(shù),用于配合正則表達式模式,實現(xiàn)更多功能,譬如re.IGNORECASE即代表大小寫忽略「na:」?用于自定義遇到缺失值時返回的對象,通常建議設置為 False「regex:」?bool型,用于設置是否將 pat參數(shù)視為正則表達式進行解析,默認為True
下面是一些簡單的例子:
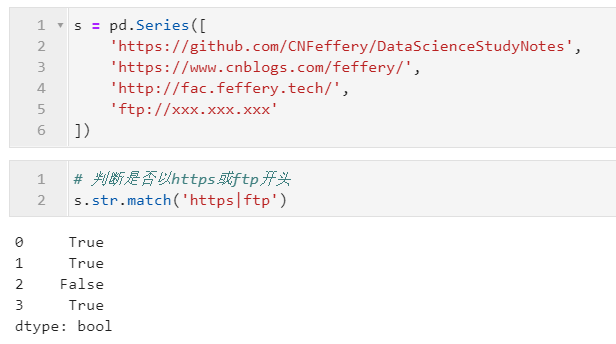
2.2.3 利用match()判斷是否以指定正則模式開頭
類似前面介紹的startswith(),不同的是,match()支持正則表達式,可以幫助掌握正則表達式的用戶拓展匹配能力,其主要參數(shù)有:
「pat:」?str型,必選,用于定義要檢查的字符模式,當 regex=True時表示正則表達式,當regex=False時,表示原始字符串片段「flags:」?int型,可選,對應 re模塊中的flags參數(shù),用于配合正則表達式模式,實現(xiàn)更多功能,譬如re.IGNORECASE即代表大小寫忽略「na:」?用于自定義遇到缺失值時返回的對象,通常建議設置為 False
下面是一些簡單的例子:
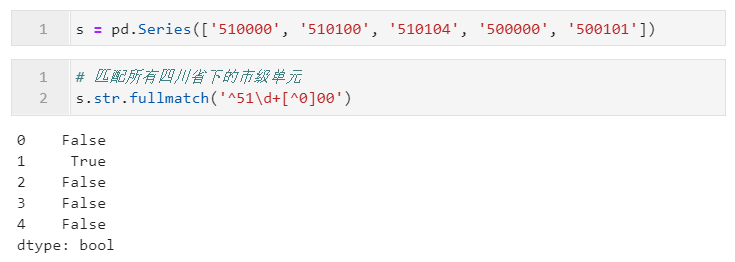
2.2.4 利用fullmatch()判斷字符串是否完整滿足指定正則模式
上面介紹的match()局限性在于只能從開頭匹配是否滿足指定正則表達式,而從pandas1.1.0版本開始,新增了fullmatch()方法,可以幫助我們傳入正則表達式來判斷目標字符串是否可以「完全匹配」,其參數(shù)同match(),下面是一個簡單的例子:
2.3 生成型方法
「生成型」方法這里指的是,基于原有的單列字符型Series數(shù)據(jù),按照一定的規(guī)則產生出新計算結果的一系列方法,pandas中常用的有:
2.3.1 利用slice()進行字符切片
當我們想要對字符型Series進行元素級的切片操作時,就可以用到str.slice(),其三個參數(shù)依次為start、stop和step,分別代表切片的開始下標、結束下標與步長,與Python原生的切片方式一致,下面是一些簡單的例子(也可以直接使用類似Python中[start:stop:step]):

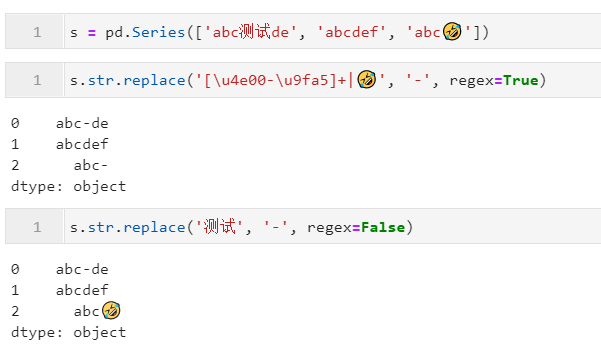
2.3.2 利用replace()對指定字符片段或正則模式進行替換
當我們希望對字符型Series進行元素級的字符片段/正則模式替換時,就可以使用到str.replace()方法,其除了常規(guī)的pat、flags、regex等參數(shù)外,還有特殊的參數(shù)n用于設置每個元素字符串(默認為-1即不限制次數(shù)),參數(shù)repl用于設置填充的新內容,從開頭開始總共替換幾次,下面是一些簡單的例子:
2.3.3 利用split()按照指定字符片段或正則模式拆分字符串
利用str.split()方法,我們可以基于指定的字符片段或正則模式對原始字符Series進行元素級拆分,主要參數(shù)有pat、n,同上文類似的參數(shù)設定,另外還有特殊參數(shù)expand來設定對于是否以DataFrame中不同列的形式存儲拆分結果,默認為False。下面是一些簡單的例子:

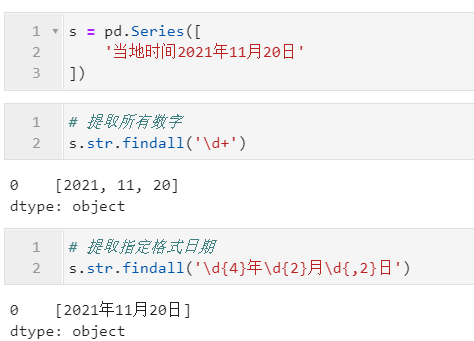
2.3.4 利用findall()提取符合指定模式的片段
利用findall(),可以按照指定的字符片段/正則模式對字符型Series進行元素級提取,可用的參數(shù)有pat、flags,下面是一些簡單的例子:
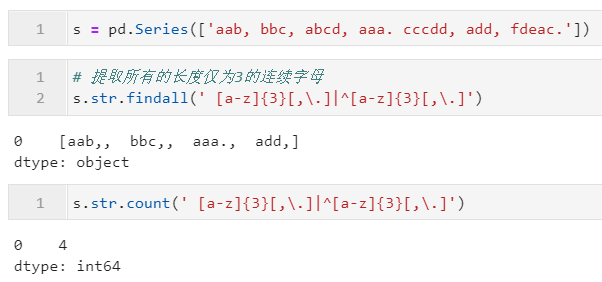
2.3.5 利用count()進行頻數(shù)統(tǒng)計
通過count(),我們可以對指定的字符片段/正則模式在字符型Series中每個字符串元素中出現(xiàn)的次數(shù)進行統(tǒng)計,其參數(shù)同上文中的findall(),下面是一些簡單的例子:
2.4 特殊型方法
除了上述介紹到的字符串處理方法外,pandas中還有一些特殊方法,可以配合字符串解決更多處理需求,典型的有:
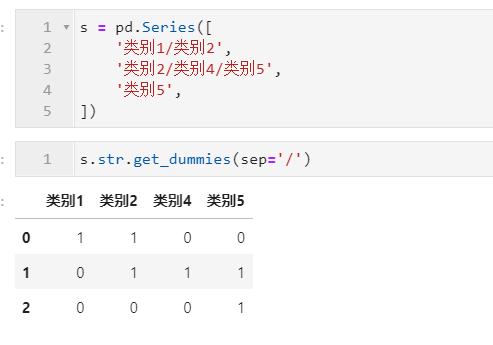
2.4.1 利用get_dummies()方法生成啞變量
在涉及到機器學習特征工程的過程中,我們可以使用到str.get_dummies()方法來對具有固定分隔符的字符串進行啞變量的生成,它只有一個參數(shù)sep,用于設置分隔符,暫時不支持正則模式:
2.4.2 利用pd.to_numeric()修復數(shù)值錯誤
有些情況下,我們從外部數(shù)據(jù)源(如excel表)中讀入的數(shù)據(jù),由于原始數(shù)據(jù)文件加工的問題,導致一些數(shù)值型字段中的某些單元格混入非數(shù)值型字符,如:
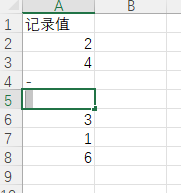
這種情況下,直接讀入的數(shù)據(jù),本應該為數(shù)值型的字段會變成object型:
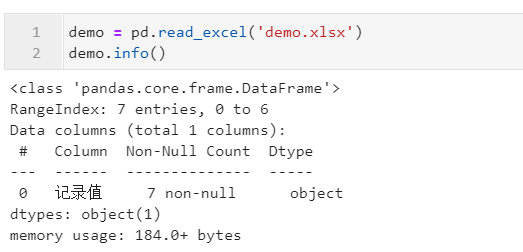
這種時候就可以利用pd.to_numeric()方法,設置參數(shù)errors='coerce',就可以將可以合法轉為數(shù)值型的記錄轉換為相應的數(shù)值,不合法的位置返回缺失值:

以上就是本文的全部內容,歡迎在評論區(qū)與我進行討論~
加入知識星球【我們談論數(shù)據(jù)科學】
400+小伙伴一起學習!
·?推薦閱讀?·