Pandas數(shù)據(jù)清理,看這一篇就夠了
作者介紹
吐血整理數(shù)據(jù)人常用Pandas數(shù)據(jù)清理(附代碼)
全文干貨,閱讀請(qǐng)自備奶茶解渴(wink)。
數(shù)據(jù)行業(yè)的從業(yè)者都知道數(shù)據(jù)清理是整個(gè)數(shù)據(jù)分析周期(見下圖)最重要也是最耗時(shí)的步驟。沒有“干凈”的、符合特定規(guī)范的數(shù)據(jù)輸入,就沒有有效的結(jié)果引導(dǎo)決策,更糟糕的是,數(shù)據(jù)清理不完整或者錯(cuò)誤甚至?xí)`導(dǎo)決策,GIGO (garbage in, garbage out)就是我們數(shù)據(jù)人最想避免的情況。

Source: Quora
備注:The step of data preparation is also known as Data Cleaning or Data Wrangling。
這篇文章是我通過工作中處理大幾十個(gè)公司的數(shù)據(jù)遇到的問題而做的總結(jié),問題都源于工業(yè)界實(shí)際應(yīng)用案例,大家可以當(dāng)作備考、面試、工作的cheat sheet,還不快點(diǎn)贊收藏~
本文所有相關(guān)代碼已上傳至GitHub,請(qǐng)自行下載。
點(diǎn)擊下方卡片,回復(fù) “數(shù)據(jù)處理”
即可獲取本文所有相關(guān)代碼
本文的方法都盡量致力于用最短的代碼、最快的運(yùn)行速度來解決問題,當(dāng)然,如果有更好的方法歡迎大家留言。
建議:閱讀code前,大家可以先想想當(dāng)你們遇到這些問題會(huì)怎么寫,先思考再“抄作業(yè)”看解析,印象會(huì)更加深刻哦。
Note:數(shù)據(jù)清理好習(xí)慣 - 代碼run完,記得要double check清理結(jié)果。
問題一:合并多個(gè)excel文件的多個(gè)工作表
完整代碼:
df = pd.DataFrame()# the glob module is used to retrieve files/pathnames matching a specified patterndir_filenames = sorted(glob('./*.xlsx')) # all excel files from current directoryfor dir_file in dir_filenames:dict_xlsx = pd.read_excel(dir_file, sheet_name=None)workbook = pd.concat([v_df.assign(Sheet = k) for k,v_df in dict_xlsx.items()], ignore_index=True)df = pd.concat([df,workbook],ignore_index=True)print(f'shape of merged files:{df.shape}')解析:總體思路是讀取每個(gè)工作簿,再讀取每個(gè)工作簿的工作表,list comprehension內(nèi)循環(huán)合并表,外循環(huán)合并工作簿glob用于返回符合某個(gè)pattern的路徑和文件名glob('./*.xlsx') 返回當(dāng)前目錄下的所有Excel文件名python的built-in function sorted()不改變?cè)璴ist,要賦值給新的variable才實(shí)現(xiàn)排序pd.read_excel(dir_file, sheet_name=None) 返回dictionary,key是sheet name, value是工作表的數(shù)據(jù)[v_df.assign(Sheet = k) for k,v_df in dict_xlsx.items()]是list comprehension,通常能簡(jiǎn)化代碼的同時(shí)加快代碼的運(yùn)行速度df.assign()是新加一列,記錄工作表名稱pd.concat([])是縱向合并數(shù)據(jù)的好方法
問題二:查看空值和處理空值
完整代碼:
count_null_series = df.isnull().sum() # returns seriescount_null_df = pd.DataFrame(data=count_null_series, columns=['Num_Nulls'])# what % of the null values take for that columnpct_null_df = pd.DataFrame(data=count_null_series/len(df), columns=['Pct_Nulls'])null_stats = pd.concat([count_null_df, pct_null_df],axis=1)null_stats
結(jié)果:
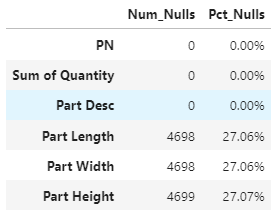
解析:df.isnull().sum()會(huì)算出每列缺失值的數(shù)量,再算一個(gè)缺失值占本列的百分比可以讓自己更清楚數(shù)據(jù)的情況和下一步如何清理缺失值。
處理缺失值:
- 時(shí)間序列的數(shù)據(jù)常用df[col_name].fillna(method="ffill",inplace=True),ffill表示按上一個(gè)值填充- 不同列補(bǔ)不同的值df.fillna(value={col1:50, col2:67, col3:100}, inplace=True)- 以當(dāng)列的平均值彌補(bǔ)空值df.where(pd.notna(df), df.mean(), axis="columns", inplace=True)- 任意選定的列為空就刪除該行df.dropna(subset=subset_list, inplace=True)- 當(dāng)一半的行為空,刪除該列df.dropna(thresh=len(df)*N, axis=1, inplace=True)
問題三:刪除多列
有沒有小伙伴像我一樣,當(dāng)數(shù)據(jù)有很多無關(guān)不重要的列,而不愿意copy paste列名去drop的童鞋,這里提供用column index一行搞定刪除多列的問題。
完整代碼:
df.info()df.drop(df.columns[start_ind:stop_ind],axis=1,inplace=True)df.info()
當(dāng)列很多的時(shí)候,每個(gè)column對(duì)應(yīng)的index一個(gè)個(gè)數(shù)可太麻煩了,df.info()是一個(gè)非常簡(jiǎn)潔又高效的方法。他會(huì)返回dataframe的行數(shù),列數(shù),列名對(duì)應(yīng)的index,數(shù)據(jù)類型,非空值和memory usage。
所以第一個(gè)df.info()就是為了找出你要?jiǎng)h的列明的起始index和終止index,注意,如果你要?jiǎng)h2-4列,stop_index應(yīng)該是5才會(huì)把第4列刪掉。第二個(gè)df.info()是為了double check最后的數(shù)據(jù)列都是你想要的,如果還有要?jiǎng)h列還可以循環(huán)進(jìn)行這樣的步驟。
問題四:批量改列名
完整代碼:
df.rename(columns= {'Order_No_1':'OrderID','ItemNo':'ItemID'}, inplace=True)# remove special characters from column namedf.columns = df.columns.str.replace('[&,#,@,(,)]', '')# remove leading/trailing space and add _ to in-between spacesdf.columns = df.columns.str.strip().str.replace(' ','_')
df.rename()是常見的改列名的方法,在這里想格外強(qiáng)調(diào)后兩行代碼,是批量格式化列名的“黑科技”。
note:數(shù)據(jù)工作中,文件命名的convention(約定習(xí)俗)是不留空格,要么加’_’,要么加’-‘,要么CamelCase,這同樣適用于數(shù)據(jù)的列名命名,因?yàn)橛?jì)算機(jī)不擅于處理/解析空格。
問題五:批量更改數(shù)據(jù)格式
for c in ['OrderID','ItemID','Class']:df[c] = df[c].astype('str')
問題六:處理重復(fù)值
完整代碼:
len_df = len(df)len_drop = len(df.drop_duplicates(subset = subset_list))len_diff = len_df-len_dropprint(f'difference of length:{len_diff}')if len_diff>0:dups = df[df.duplicated(keep=False)].sort_values(by=sort_list)df_drop = df.drop_duplicates(subset=subset_list, keep='last')
解析:df.drop_duplicates(subset = subset_list)會(huì)返回基于指定列subset_list去重后的dataframe。如果發(fā)現(xiàn)有重復(fù)值,
df.duplicated(keep=False).sort_values(by=sort_list)這段代碼可以讓你有方向的進(jìn)行比較,keep=False是保證重復(fù)值都展示出來的必備參數(shù),sort_values()是保證重復(fù)值挨著出現(xiàn),方便你接下來決策如何處理他們。以上代碼列舉了保留重復(fù)值最后一項(xiàng)的例子(keep='last')。
問題七:處理日期和時(shí)間
當(dāng)我們收到了這樣的數(shù)據(jù),dtype是object,要如何把他轉(zhuǎn)化成date format并且分離出time和hour呢?

代碼:
# split by comma, retrieve the first columndf['date_com'] = df['date_com'].str.split(',', expand=True)[0]# format要和原日期的格式一致,最后總會(huì)返回YYYY-MM-DD HH:MM:SS格式的datetimedf['date_com'] = pd.to_datetime(df['date_com'], format='%Y-%m-%d %H:%M:%S')
返回結(jié)果:
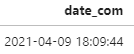
如果要進(jìn)一步分離date和time:
df['Date'] = df['date_com'].dt.datedt_lst = df['date_com'].str.split(' ', n=1, expand = True)df['Time'] = dt_lst[1]# extract hour from Timetime_lst = df['date_com'].str.split(':', n=1, expand = True)df['Hour'] = time_lst[0] #str
今天的分享先到這里,感覺有學(xué)到新知識(shí)記得點(diǎn)贊轉(zhuǎn)發(fā)加關(guān)注哦。下期見。
點(diǎn)擊下方卡片,回復(fù) “數(shù)據(jù)處理”
即可獲取本文所有相關(guān)代碼
--END--
老表推薦
圖書介紹:《Python網(wǎng)絡(luò)編程從入門到精通》編寫秉承讓更多的 Python 愛好者能看懂的原則,以讓讀者以較少的時(shí)間、較低的成本,快速掌握 Python 網(wǎng)絡(luò)編程為目標(biāo)。每個(gè)步驟都很詳盡,讀者可按步驟操作,還配有相應(yīng)代碼,方便讀者實(shí)現(xiàn)網(wǎng)絡(luò)編程的開發(fā)。
掃碼即可加我微信
老表朋友圈經(jīng)常有贈(zèng)書/紅包福利活動(dòng)
學(xué)習(xí)更多: 整理了我開始分享學(xué)習(xí)筆記到現(xiàn)在超過250篇優(yōu)質(zhì)文章,涵蓋數(shù)據(jù)分析、爬蟲、機(jī)器學(xué)習(xí)等方面,別再說不知道該從哪開始,實(shí)戰(zhàn)哪里找了 優(yōu)秀的讀者都知道,“點(diǎn)贊”傳統(tǒng)美德不能丟