
數(shù)據(jù)分析實戰(zhàn),文末代碼下載,Python實現(xiàn)房產(chǎn)數(shù)據(jù)分析與可視化
背景
在上一篇文章《用Python開發(fā)爬蟲爬取某房產(chǎn)網(wǎng)站數(shù)據(jù)》的末尾,我們講到,雖然用Python開發(fā)爬蟲腳本,順利把某房產(chǎn)網(wǎng)站的數(shù)據(jù)給爬取下來了,但是我朋友老板安排的工作并沒有完成,我們還需要對這份數(shù)據(jù)進行分析并生成分析報告,所以,這篇文章就接著上篇文章,講解一下,如果用Python做一份好看又好用的數(shù)據(jù)分析報告。
Python庫的選擇
話說,工欲善其事,必先利其器,雖然我們已經(jīng)選擇Python來完成剩余的工作,但是我們需要考慮具體選擇使用Pytho的哪些利器來幫助我們更快更好地完成剩余的工作。
我們可以看一下,在這個任務中,主要涉及到四類工作要完成:
csv文件的讀取; 對讀取的數(shù)據(jù),按照我們要分析的指標進行數(shù)據(jù)處理和指標計算; 根據(jù)數(shù)據(jù)分析的結(jié)果,生成可視化的數(shù)據(jù)圖表; 通過web頁面展示數(shù)據(jù)分析結(jié)果報告;
我們下面就根據(jù)這四類工作,來看看我們分別選擇Python的哪些庫來幫助我們完成工作。
1.數(shù)據(jù)處理和分析庫
對類似csv、excel等格式文件的讀取和處理,其實就是對一維和二維數(shù)據(jù)的處理,對此類數(shù)據(jù)的處理,Python中常用的庫是Pandas,其提供的數(shù)據(jù)結(jié)構(gòu)中的Series對應一維數(shù)據(jù),DataFrame對應二維數(shù)據(jù),同時Pandas也提供了大量的高效內(nèi)置函數(shù)和操作來實現(xiàn)對內(nèi)存中一維和二維數(shù)據(jù)的處理。
而對于更高維度數(shù)據(jù)比如矩陣的計算,Python中則需要用Nunpy庫來完成。numpy是以矩陣為基礎(chǔ)的數(shù)學計算模塊,提供高性能的矩陣運算,數(shù)組結(jié)構(gòu)為ndarray,可以把它看作是多維數(shù)組(ndarray)的容器,可以對數(shù)組執(zhí)行元素級計算以及直接對數(shù)組執(zhí)行數(shù)學運算的函數(shù)。
Pandas是基于Numpy數(shù)組構(gòu)建的,但二者最大的不同是pandas是專門為處理表格和混雜數(shù)據(jù)設(shè)計的,比較契合統(tǒng)計分析中的表結(jié)構(gòu),而numpy更適合處理統(tǒng)一的數(shù)值數(shù)組數(shù)據(jù)。
所以,第1步和第2步的工作,我們基本依靠Pandas庫就能完成,不過,這次的數(shù)據(jù)分析報告中,我也用到了Numpy庫的直方圖計算的功能,后面會詳細講到。
2.數(shù)據(jù)可視化庫
而第3步的工作,其實是一個數(shù)據(jù)可視化的任務,在Python中可以用于進行數(shù)據(jù)可視化的庫,常用的主要有三個:
Matplotlib Seanborn Pyecharts
Matplotlib
Matplotlib可以說是Python數(shù)據(jù)可視化庫的鼻祖了,他是Python編程語言及其數(shù)值計算包NumPy的可視化操作界面,其中pyplot是matplotlib的一個模塊,提供了類似MATLAB的接口。其可以和Numpy、Pandas無縫結(jié)合,但一些圖標的樣式不夠美觀,而且原生不支持生成動態(tài)可交互的圖表,雖然可以通過改變使用的后端來實現(xiàn),但相對還是比較麻煩一些,而且如果想要在一個web頁面中實現(xiàn)一個動態(tài)可交互的圖表,目前沒有什么特別好的辦法,最近matplotlib在更面向web交互方面有了很多進展,比如新的HTML5/Canvas后端,可以從如下地址了解一下:
http://code.google.com/p/mplh5canvas/
但還沒有完全完成。
Seanborn
Seaborn跟matplotlib最大的區(qū)別就是它的默認繪圖風格和色彩搭配都具有現(xiàn)代美感,其實他是在matplotlib的基礎(chǔ)上進行了更高級的API封裝,讓你能用更少的代碼去調(diào)用matplotlib的方法,從而使得作圖更加容易。但matplotlib存在的動態(tài)交互性的問題他同樣存在。
Pyecharts
說到Pyecharts則不得不提到ECharts,這個可是在前端數(shù)據(jù)可視化領(lǐng)域非常知名的庫了,畢竟他出自我的老東家百度的前端工程師之手,最開始在百度內(nèi)部孵化,我在百度工作期間,還和后來參與到ECharts開發(fā)的核心工程師有過其他項目合作。后來2018年捐贈給Apache基金會,成為ASF孵化級項目,并于2021年正式畢業(yè),成為Apache頂級項目。
而Pyecharts則是基于ECharts實現(xiàn)的python版本,支持大量豐富的可視化圖表類型,而且相比前兩個庫最大的優(yōu)勢在于,能夠非常方便地生成支持交互性(如鼠標點選、拖拽、縮放等)的圖片,且可動態(tài)地展示在web頁面上。
基于以上的對比分析,鑒于這次我希望給我朋友生成一個動態(tài)可交互的web數(shù)據(jù)分析報告頁面,在這一點上,Pyecharts無疑更有優(yōu)勢,于是這次我們就用Pyecharts庫來進行我們的數(shù)據(jù)可視化展現(xiàn)。
3.Web應用庫
在這個領(lǐng)域Python的選擇主要有兩個:
Django Flask
Django是用 Python 開發(fā)的一個免費開源的 Web 框架,提供了許多網(wǎng)站后臺開發(fā)經(jīng)常用到的模塊,本身自帶了相當多的功能,這些功能是由官方和社區(qū)共同維護的,因而是個大而全的較重的框架,所以耦合度相比flask會高一些,做二次修改難度更高。
相比之下,F(xiàn)lask是一個免費的開放源代碼的輕量型的Web框架,F(xiàn)lask不包含例如上載處理,ORM(對象關(guān)系映射器),數(shù)據(jù)庫抽象層,身份驗證,表單驗證等web應用常用功能模塊(這些Django提供了),但是可以使用預先存在的外部庫來集成這些功能,因此是一個更靈活、擴展性更好的Web框架。
而我們這次的場景,僅僅只需要提供一個靜態(tài)的web頁面用于展示數(shù)據(jù)可視化結(jié)果,并不涉及其他復雜的web應用功能,因此,F(xiàn)lask是我們的不二之選。
開始我們的數(shù)據(jù)可視化分析之旅
好了,選擇好了我們的工具之后,我們就要正式開始我們的數(shù)據(jù)可視化分析之旅了。我們先來看一下我們要分析的這一份數(shù)據(jù),如下圖所示:
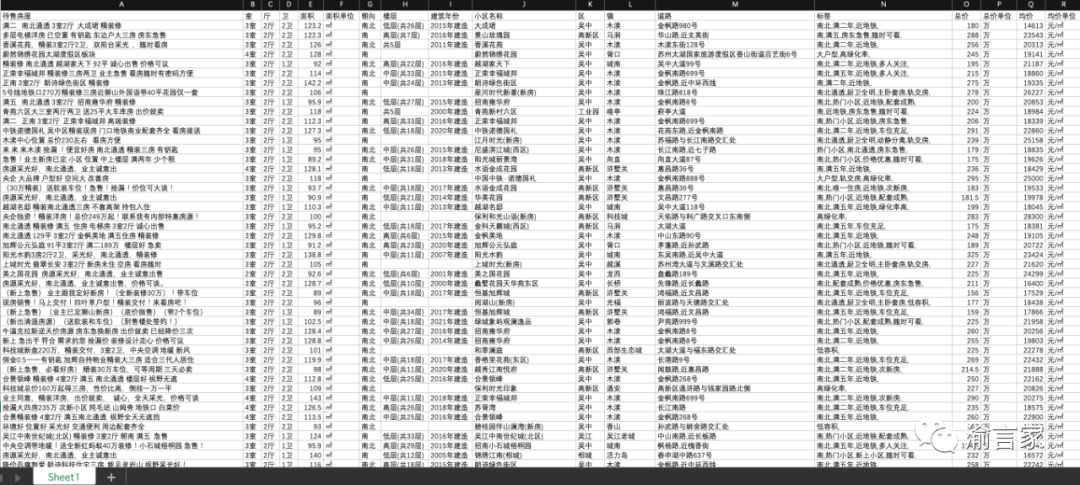
我們爬取到的房產(chǎn)數(shù)據(jù),主要是蘇州二手房的房源信息,主要包括了待售房源的戶型、面積、朝向、樓層、建筑年份、小區(qū)名稱、小區(qū)所在的城區(qū)-鎮(zhèn)-街道、房子被打的標簽、總價、單價等信息。
數(shù)據(jù)讀取到內(nèi)存的過程使用Pandas來完成很簡單,這里就不贅述了。接下來重點講一下數(shù)據(jù)分析和可視化圖表的生成。根據(jù)要分析的數(shù)據(jù)指標,這次我們主要用到了Pyecharts的5類圖表組件,分別是Bar(柱狀圖)、Pie(餅圖)、Histogram(直方圖) 、Scatter(散點圖)、Map(地圖)和WordCloud(詞云圖),接下來就分別介紹一下。
Bar(柱狀圖)
因為我們這次要分析的是二手房的數(shù)據(jù),關(guān)于房子,我們最關(guān)心的就是不同類型房子的價格,比如不同戶型、不同面積、不同小區(qū)的房子總價和單價的情況,而柱狀圖特別適合按不同數(shù)據(jù)類型進行數(shù)值的呈現(xiàn)。
因此這次的數(shù)據(jù)分析報告中,在分析按房屋面積區(qū)間的房屋單價、按房子戶型的房屋單價以及小區(qū)房價Top10這三個數(shù)據(jù)圖表中,我們使用了柱狀圖來呈現(xiàn)數(shù)據(jù)分析結(jié)果
接下來我們就以小區(qū)房價Top10為例,來看一下如何生成柱狀圖。
其實主要過程包括兩個步驟(PS:后續(xù)每個圖表都按著兩個步驟來介紹):
數(shù)據(jù)計算處理 數(shù)據(jù)可視化處理
我們先來看第一步的數(shù)據(jù)計算處理。因為要找到這個城市小區(qū)房價的Top10,所以我們主要完成如下幾個計算步驟:
根據(jù)原始數(shù)據(jù)表中的”小區(qū)名稱“字段進行g(shù)roup by; 對每個分組,對”均價“字段求平均值; 對上述結(jié)果的”均價“字段按降序進行排序; 對排序結(jié)果取前10項結(jié)果;
完成上述四個計算步驟的代碼如下所示:
def unit_price_analysis_by_estate(df,isembed):
#獲取要分析的數(shù)據(jù)列
analysis_df = df.loc[:,['小區(qū)名稱','均價']]
analysis_df.loc[:,'小區(qū)名稱'] = analysis_df.loc[:,'小區(qū)名稱'].astype('str')
#對小區(qū)名稱分組,然后按照分組計算單價均價
group = analysis_df.groupby('小區(qū)名稱',as_index=False)
group_df = group.mean()
group_df.loc[:,'均價'] = group_df.loc[:,'均價'].astype('int')
#按照均價列降序排序
group_df.sort_values('均價',ascending=False, inplace=True)
#取Top10
top10_df = group_df.head(10)
#為了橫向柱狀圖展示,再從低到高排序一下
top10_df.sort_values('均價',ascending=True,inplace=True)
......
其實如果是生成常規(guī)的縱向柱狀圖的話,上面的代碼里最后一步是不需要的。但因為要生成橫向柱狀圖,需要對縱向柱狀圖進行一個reverse()操作,在reverse()操作后如果要保持從上至下降序的順序,我們的對Top10的排序結(jié)果也需要倒置一下。
接下來就是柱狀圖的數(shù)據(jù)可視化圖表生成部分了,這部分代碼如下:
bar = (
Bar(init_opts=opts.InitOpts(width="1500px"))
.add_xaxis(top10_df['小區(qū)名稱'].tolist())
.add_yaxis("房價單價",top10_df['均價'].tolist(),itemstyle_opts=opts.ItemStyleOpts(color=JsCode(top10_color_function)))
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title="蘇州各小區(qū)二手房房價TOP10"),
xaxis_opts=opts.AxisOpts(axislabel_opts={'interval':'0'}),
legend_opts=opts.LegendOpts(is_show=False))
)
關(guān)于代碼里詳細的參數(shù)設(shè)置我就不一一解釋了,大家可以去Pyecharts的官網(wǎng)查看到每個圖表非常詳細的參數(shù)解釋和demo代碼。
在這里唯一額外提一下的,就是關(guān)于如何給柱狀圖不同的柱子設(shè)置不同的顏色,需要我們提供一個自定義的js函數(shù)來實現(xiàn),Pyecharts提供了這樣的機制,可以讓我們嵌入這樣的js函數(shù)來完成部分自定義的功能,比如我是這樣來實現(xiàn)的:
top10_color_function = """
function (params) {
if (params.value > 58000 && params.value < 59000) {
return 'red';
} else if (params.value > 59000 && params.value < 60000) {
return 'blue';
}else if (params.value > 60000 && params.value < 61000){
return 'green'
}else if (params.value > 61000 && params.value < 61800){
return 'purple'
}else if (params.value > 61800 && params.value < 70000){
return 'brown'
}else if (params.value > 70000 && params.value < 73000){
return 'gray'
}else if (params.value > 73000 && params.value < 79000){
return 'orange'
}else if (params.value > 79000 && params.value < 85000){
return 'pink'
}else if (params.value > 85000 && params.value < 100000){
return 'navy'
}
return 'gold';
}
"""
在這個函數(shù)中,我們需要根據(jù)每個柱子實際數(shù)值的大小,來劃分區(qū)間,以決定每個柱子的顏色。
完成上述兩個步驟后,我們的橫向柱狀圖就生成了,如下圖所示:

從上圖可以看到,當我們把鼠標移到某個柱子上的時候,會出現(xiàn)相應的浮層,展示當前柱子代表的category的數(shù)值。也即,就如我們之前提到的,Pyecharts的圖表是動態(tài)可交互的圖表。
另外,從圖中我們可以看到,蘇州玲瓏灣花園小區(qū)是蘇州二手房房價最貴的小區(qū),尤其是七區(qū)和八區(qū),至于為什么,大家可以自行上百度搜索看看。
Pie(餅圖)
餅圖一般用來分析不同類型的數(shù)量的占比。在這次的數(shù)據(jù)報告中,因為是對二手房的分析,所以我們想看一下待售賣的二手房中,不同建筑年份的房子數(shù)量占比情況,據(jù)此可以看看哪些年份的老房子是賣的比較多的。
數(shù)據(jù)計算處理步驟:
因為原數(shù)據(jù)表中沒有待售房屋數(shù)這一列,因此我們先增加一列,用于后續(xù)計算; 對建筑年份列進行g(shù)roup by; 對每個分組進行統(tǒng)計計數(shù),結(jié)果寫入新增加的待售房屋數(shù)列;
代碼實現(xiàn)如下:
def add_sale_estate_col(row):
return 0
def sale_estate_analysis_by_year(df,isembed):
#增加一列待售房屋數(shù),初始值均為0
df.loc[:,'待售房屋數(shù)'] = df.apply(add_sale_estate_col,axis=1)
#獲取要用作數(shù)據(jù)分析的兩列:建筑年份和待售房屋數(shù)
analysis_df = df.loc[:,['建筑年份','待售房屋數(shù)']]
#因為建筑年份列有空值,先預處理一下
analysis_df.dropna(inplace=True)
#按照建筑年份進行分組
group = analysis_df.groupby('建筑年份',as_index=False)
#對每個分組進行統(tǒng)計計數(shù)
group_df = group.count()
group_df.loc[:,'待售房屋數(shù)'] = group_df.loc[:,'待售房屋數(shù)'].astype('int')
......
接下來就是餅圖的數(shù)據(jù)可視化圖表生成部分了,這部分代碼如下:
pie = Pie(init_opts=opts.InitOpts(width='800px', height='600px', bg_color='white'))
pie.add("pie",[list(z) for z in zip(group_df['建筑年份'].tolist(),group_df['待售房屋數(shù)'].tolist())]
,radius=['40%', '60%']
,center=['50%', '50%']
,label_opts=opts.LabelOpts(
position="outside",
formatter="{b}:{c}:go7utgvlrp%",)
).set_global_opts(
title_opts=opts.TitleOpts(title='蘇州二手房不同建筑年份的待售數(shù)量', pos_left='300', pos_top='20',
title_textstyle_opts=opts.TextStyleOpts(color='black', font_size=16)),
legend_opts=opts.LegendOpts(is_show=False))
在這部分代碼中需要額外提一下的是如下這部分代碼:
[list(z) for z in zip(group_df['建筑年份'].tolist()
因為Pie需要的數(shù)據(jù)格式,是元組數(shù)組的形式,因此在上面的代碼中,我們使用zip()這個函數(shù),來將兩個Series對應的元素拼接成元組。
我們最后生成的餅圖如下所示:
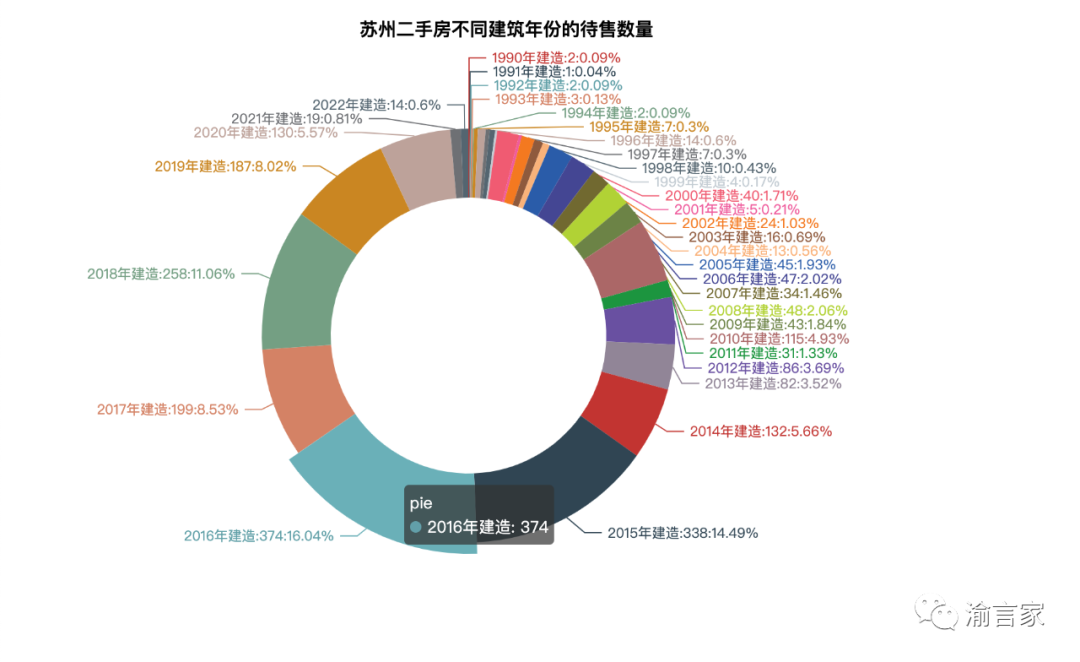
從上圖我們可以看到,蘇州待售的數(shù)量較多的二手房,大多是2015-2019年期間建成的,也即距今的房齡不超過10年。2021年及后的房子明顯少了很多,應該是跟滿二的政策有關(guān)系。
Histogram(直方圖)
直方圖又稱質(zhì)量分布圖,是一種統(tǒng)計報告圖,由一系列高度不等的縱向條紋或線段表示數(shù)據(jù)分布的情況。一般用橫軸表示數(shù)據(jù)類型,縱軸表示分布情況。為了構(gòu)建直方圖,第一步是將值的范圍分段,即將整個值的范圍分成一系列間隔,然后計算每個間隔中有多少值。
關(guān)于我們要分析的二手房數(shù)據(jù),我們最關(guān)心的還是房價的分布情況,比如不同單價和總價的房子在不同價格區(qū)間的分布數(shù)量情況。
因此,我們用直方圖來分析蘇州二手房不同單價和總價的房子數(shù)量的分布。
數(shù)據(jù)計算處理步驟:
將要分析的數(shù)據(jù)字段進行分段; 對每個分段,計算該分段里的分布數(shù)量;
上面兩個計算步驟,在Python的Numpy庫里,提供了一個叫histogram()的函數(shù),能夠直接幫我們來實現(xiàn),見下面代碼所示:
import numpy as np
def unit_price_analysis_by_histogram(df,isembed):
hist,bin_edges = np.histogram(df['均價'],bins=100)
bar = (
Bar()
.add_xaxis([str(x) for x in bin_edges[:-1]])
.add_yaxis('價格分布',[float(x) for x in hist],category_gap=0)
.set_global_opts(
title_opts=opts.TitleOpts(title='蘇州二手房房價-單價分布-直方圖',pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False)
)
)
......
從上面代碼里我們可以看到,我們把均價字段分成了100個間隔區(qū)間,bin_edges就是劃分出來的100個區(qū)間,然后我們計算每個區(qū)間里的分布數(shù)量,hist就是分布數(shù)量的計算結(jié)果
這樣我們畫出來的直方圖如下所示(以二手房單價直方圖為例):

從上圖我們可以看到,蘇州二手房的單價,大部分集中在17000-21000這個價格區(qū)間,單價低于10000或高于30000的房子相對就比較少了。
Scatter(散點圖)
散點圖一般用在回歸分析中,是一種數(shù)據(jù)點在直角坐標系平面上的分布圖,用兩組數(shù)據(jù)構(gòu)成多個坐標點,考察坐標點的分布,判斷兩變量之間是否存在某種關(guān)聯(lián)的分布模式
對于我們要分析的蘇州二手房數(shù)據(jù),我們可能會關(guān)心,哪些因素是跟二手房的房價有關(guān)系的,以及是什么關(guān)系,比如如果我們想知道房子面積跟房子單價之間是什么關(guān)系?那我們可以畫一個面積-單價的散點圖來看看。
因為我們的原始數(shù)據(jù)中已經(jīng)有面積和均價兩個字段,因此不需要我們做更多的數(shù)據(jù)計算處理,我們直接來看這部分的實現(xiàn)代碼:
df.sort_values('面積',ascending=True, inplace=True)
square = df['面積'].to_list()
unit_price = df['均價'].to_list()
scatter = (
Scatter()
.add_xaxis(xaxis_data=square)
.add_yaxis(
series_name='',
y_axis=unit_price,
symbol_size=4,
label_opts=opts.LabelOpts(is_show=False)
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(type_='value'),
yaxis_opts=opts.AxisOpts(type_='value'),
title_opts=opts.TitleOpts(title='蘇州二手房面積-單價關(guān)系圖',pos_left='center')
)
)
我們畫出來的散點圖如下所示:
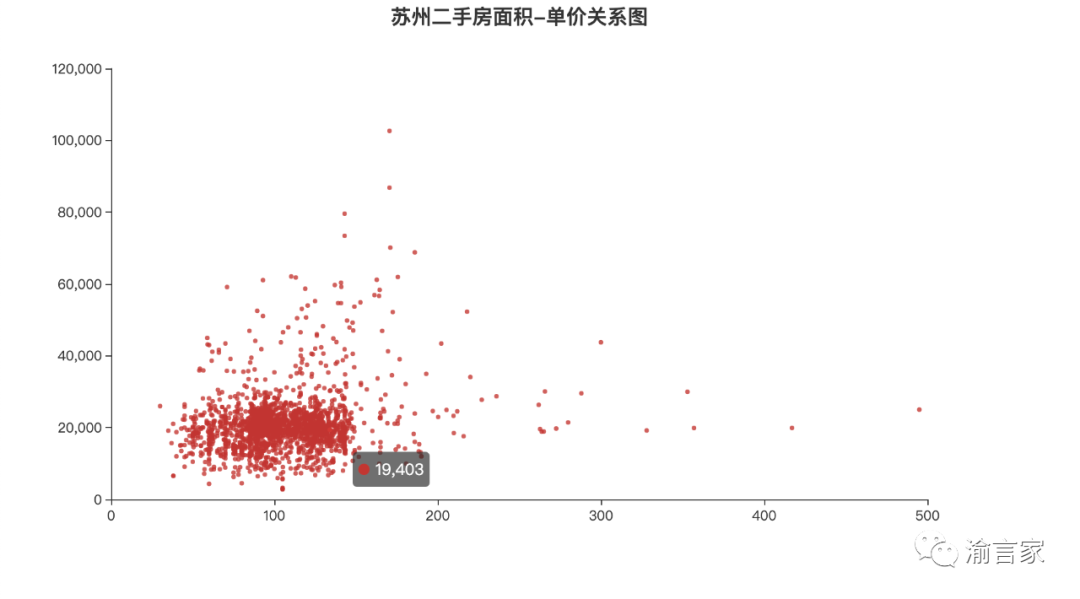
從上圖我們可以看出,蘇州二手房的單價跟房子面積并不是呈線性相關(guān)的關(guān)系,也即不是面積越大,單價越高,房子單價的高點出現(xiàn)在100-200平方這個區(qū)間,然后隨著面積逐漸增大單價呈逐漸下降趨勢,因此是一個曲線相關(guān)的關(guān)系,而且這個曲線類似一個正態(tài)分布曲線。
Map(地圖)
在我們爬取到的蘇州二手房數(shù)據(jù)中,有小區(qū)所在的區(qū)-鎮(zhèn)-街道的地理位置信息,因此,我們可以結(jié)合地圖,直觀的來看一下蘇州不同區(qū)的二手房房價信息。
在做地圖展示之前,我們先要做一下如下數(shù)據(jù)計算處理:
獲取數(shù)據(jù)源中的區(qū)和均價兩個字段; 對區(qū)字段進行g(shù)roup by; 對分組后的數(shù)據(jù)求平均值; 為適配地圖組件的行政區(qū)劃名稱,對區(qū)字段進行一下轉(zhuǎn)換處理; 將數(shù)據(jù)轉(zhuǎn)換成地圖組件需要的二維數(shù)組的格式;
def transform_name(row):
district_name = row['區(qū)'].strip()
if district_name == '吳中' or district_name == '相城' or district_name == '吳江' or district_name == '虎丘' or district_name == '姑蘇' or district_name == '工業(yè)園':
district_name = district_name + '區(qū)'
if district_name == '常熟' or district_name == '張家港' or district_name == '太倉':
district_name = district_name + '市'
return district_name
data = []
#獲取要分析的數(shù)據(jù)列
analysis_df = df.loc[:,['區(qū)','均價']]
#按區(qū)列分組
group_df = analysis_df.groupby('區(qū)',as_index=False)
#根據(jù)分組對均價列求平均值
group_df = group_df.mean('均價')
#print(group_df)
#將區(qū)的名字做一下轉(zhuǎn)換,為下面的地圖匹配做準備
group_df['區(qū)'] = group_df.apply(transform_name,axis=1)
group_df.loc[:,'均價'] = group_df.loc[:,'均價'].astype('int')
#將數(shù)據(jù)轉(zhuǎn)換成map需要的數(shù)據(jù)格式
for index,row in group_df.iterrows():
district_array = [row['區(qū)'],row['均價']]
data.append(district_array)
數(shù)據(jù)處理完成后,我們就可以用地圖組件進行可視化渲染了:
map = (
Map()
.add('蘇州各區(qū)域二手房房價',data,'蘇州')
.set_global_opts(
title_opts=opts.TitleOpts(title='蘇州各區(qū)域二手房房價地圖',pos_left='center'),
visualmap_opts=opts.VisualMapOpts(max_=26000),
legend_opts=opts.LegendOpts(is_show=False)
)
)
最終我們可以看到蘇州二手房根據(jù)地圖展示的各區(qū)房價如下:

從地圖上可以很直觀的看到,虎丘區(qū)的平均房價是最高的。這里需要說明一下的是,因為Pyecharts的map組件的地理位置數(shù)據(jù)相對比較老了,所以沒有體現(xiàn)出蘇州最新的行政區(qū)域劃分,比如我們原始數(shù)據(jù)中的工業(yè)園區(qū)、高新區(qū)等數(shù)據(jù)沒法體現(xiàn)出來,時間原因,我沒有嘗試其他的map組件,大家有興趣可以自行試試。
WordCloud(詞云圖)
在我們爬取到的蘇州二手房數(shù)據(jù)中,有兩列純文本類型的字段,一個是待售房屋,一個是標簽,這兩列的文本描述了待售房源的一些特征信息,我們可以提前其中一些高頻特征,來看看購房者最關(guān)注的房屋關(guān)鍵詞有哪些
在這個分析場景中,我們會用到一個新的第三方庫jieba,這個庫可以對我們要分析的文本進行分詞,然后自動分析每個分詞出現(xiàn)的頻率并給出相應的權(quán)重,權(quán)重越高代表詞頻越高。
我們首先要進行一步數(shù)據(jù)處理,即把待售房屋字段和標簽字段的文本合并到一起,然后把合并之后的文本交給jieba進行處理,最后把jieba分詞計算處理的結(jié)果交給WordCloud圖表組件進行渲染,整個代碼實現(xiàn)如下所示:
txt = ''
for index,row in df.iterrows():
txt = txt+ str(row['待售房屋']) + ';'+ str(row['標簽']) + '\n'
word_weights = jieba.analyse.extract_tags(txt,topK=100,withWeight=True)
word_cloud=(
WordCloud()
.add(series_name='高頻詞語',data_pair=word_weights,word_size_range=[10,100])
.set_global_opts(
title_opts=opts.TitleOpts(
title='蘇州二手房銷售熱度詞',
title_textstyle_opts=opts.TextStyleOpts(font_size=23),
pos_left='center'
)
)
)
其中extract_tags()函數(shù)的topk參數(shù)表示要提取權(quán)重排序前多少名的結(jié)果
最終我們對蘇州二手房數(shù)據(jù)生成的詞云圖如下所示:

從上圖我們可以看到,交通、朝向是購房者第一位關(guān)注的房子信息,其次是是否有車位、是否滿五(二)唯一、是否精裝修等。
生成動態(tài)可交互的Web數(shù)據(jù)分析報告
好了,通過上面的步驟,我們已經(jīng)把要分析的數(shù)據(jù)可視化圖表都生成了,但我朋友總不能把這些圖表一個個的發(fā)給她老板看,除非她真的想看看新的機會了。我們需要把這些圖表放到一個web頁面上,生成一份完整的數(shù)據(jù)分析報告后,再遞呈老板審閱。所以,最后一步,我們來完成一個web頁面來完整地呈現(xiàn)這份數(shù)據(jù)分析報告。
這個步驟的實現(xiàn)主要包括如下三個部分組成:
用flask庫實現(xiàn)的app.py腳本,這個腳本主要干如下幾件事: 啟動一個web服務; 讀取我們要分析的原始數(shù)據(jù); 實現(xiàn)一個函數(shù)負責將讀取的數(shù)據(jù)傳給不同的數(shù)據(jù)圖表生成函數(shù),拿到生成的數(shù)據(jù)圖表對象,然后調(diào)用模版進行渲染; 綁定一個url路由關(guān)系,映射到步驟三的函數(shù); 用來渲染生成最終數(shù)據(jù)分析報告的HTML文件,這個文件主要干如下幾件事: 對每個數(shù)據(jù)圖表定義一個div; 使用ECharts組件對div進行初始化; 通過變量拿到flask返回的數(shù)據(jù)圖表數(shù)據(jù),對ECharts組件進行設(shè)置; HTML渲染和計算所依賴的靜態(tài)資源文件,主要有如下三個: echarts-wordcloud.min.js,主要用于詞云圖生成; jiang1_su1_su1_zhou1.js,主要用于蘇州地圖生成; echarts.min.js,是所有數(shù)據(jù)圖表依賴的基礎(chǔ)js;
如上三個部分需要按照如下的代碼目錄結(jié)構(gòu)來組織:

flask的app.py腳本的核心代碼如下:
from flask import Flask,render_template
import drawChart as dbc
import pandas as pd
app = Flask(__name__)
#讀取要分析的數(shù)據(jù)
fpath = 'path/filename.xlsx'
df = pd.read_excel(fpath,sheet_name="Sheet1",header=[0],engine='openpyxl')
#綁定url映射關(guān)系
@app.route("/show_all_analysis_chart")
def show_all_analysis_chart():
#獲取按面積區(qū)間的單價分析數(shù)據(jù)
unit_price_analysis_by_square = dbc.unit_price_analysis_by_square(df,False)
#獲取按室區(qū)分的單價分析數(shù)據(jù)
unit_price_analysis_by_layout = dbc.unit_price_analysis_by_layout(df,False)
#獲取蘇州各小區(qū)二手房房價TOP10
unit_price_analysis_by_estate = dbc.unit_price_analysis_by_estate(df,False)
#獲取不同建筑年份的待售房屋數(shù)
sale_estate_analysis_by_year = dbc.sale_estate_analysis_by_year(df,False)
#蘇州二手房房價-單價分布-直方圖
unit_price_analysis_by_histogram = dbc.unit_price_analysis_by_histogram(df,False)
#蘇州二手房房價-總價分布-直方圖
total_price_analysis_by_histogram = dbc.total_price_analysis_by_histogram(df,False)
#蘇州二手房面積-單價關(guān)系圖
unit_price_analysis_by_scatter = dbc.unit_price_analysis_by_scatter(df,False)
#蘇州二手房銷售熱度詞
hot_word_analysis_by_wordcloud = dbc.hot_word_analysis_by_wordcloud(df,False)
#蘇州各區(qū)域二手房房價
unit_price_analysis_by_map = dbc.unit_price_analysis_by_map(df,False)
return render_template("show_analysis_chart.html",
unit_price_analysis_by_square_option = unit_price_analysis_by_square.dump_options(),
unit_price_analysis_by_layout_option = unit_price_analysis_by_layout.dump_options(),
unit_price_analysis_by_estate_option = unit_price_analysis_by_estate.dump_options(),
sale_estate_analysis_by_year_option = sale_estate_analysis_by_year.dump_options(),
unit_price_analysis_by_histogram_option = unit_price_analysis_by_histogram.dump_options(),
total_price_analysis_by_histogram_option = total_price_analysis_by_histogram.dump_options(),
unit_price_analysis_by_scatter_option = unit_price_analysis_by_scatter.dump_options(),
hot_word_analysis_by_wordcloud_option = hot_word_analysis_by_wordcloud.dump_options(),
unit_price_analysis_by_map_option = unit_price_analysis_by_map.dump_options()
)
#啟動web應用
if __name__ == "__main__":
app.run()
Html的核心代碼如下:
<head>
<meta charset="UTF-8">
<title>蘇州二手房數(shù)據(jù)分析報告</title>
<script type="text/javascript" src="/static/echarts.min.js"></script>
<script type="text/javascript" src="/static/echarts-wordcloud.min.js"></script>
<script type="text/javascript" src="/static/jiang1_su1_su1_zhou1.js"></script>
</head>
<body>
<h1 align="center">蘇州二手房數(shù)據(jù)分析報告</h1>
<h2>1.蘇州二手房按面積區(qū)間的房屋單價</h2>
<div id="unit_price_analysis_by_square" style="width:900px; height:500px;"> </div>
<script type="text/javascript">
var unit_price_analysis_by_square_chart = echarts.init(document.getElementById('unit_price_analysis_by_square'));
var option = {{ unit_price_analysis_by_square_option | safe }};
unit_price_analysis_by_square_chart.setOption(option);
</script>
......
經(jīng)過如上步驟后,我們終于生成了我們心心念了好久的好看又好用的數(shù)據(jù)分析報告,如下圖所示:

總結(jié)
好了,到此為止,通過《用Python開發(fā)爬蟲爬取某房產(chǎn)網(wǎng)站數(shù)據(jù)》和這篇文章,我們完整地介紹了從爬取網(wǎng)站數(shù)據(jù)到數(shù)據(jù)處理、數(shù)據(jù)分析和生成數(shù)據(jù)可視化報告的完整過程。完整的代碼大家可以關(guān)注我的公眾號或從我的github獲取,github地址:
https://github.com/xiaoyuge/kingfish-python/tree/master/crawler/anjuke