
美團外賣特征平臺的建設(shè)與實踐

1 背景
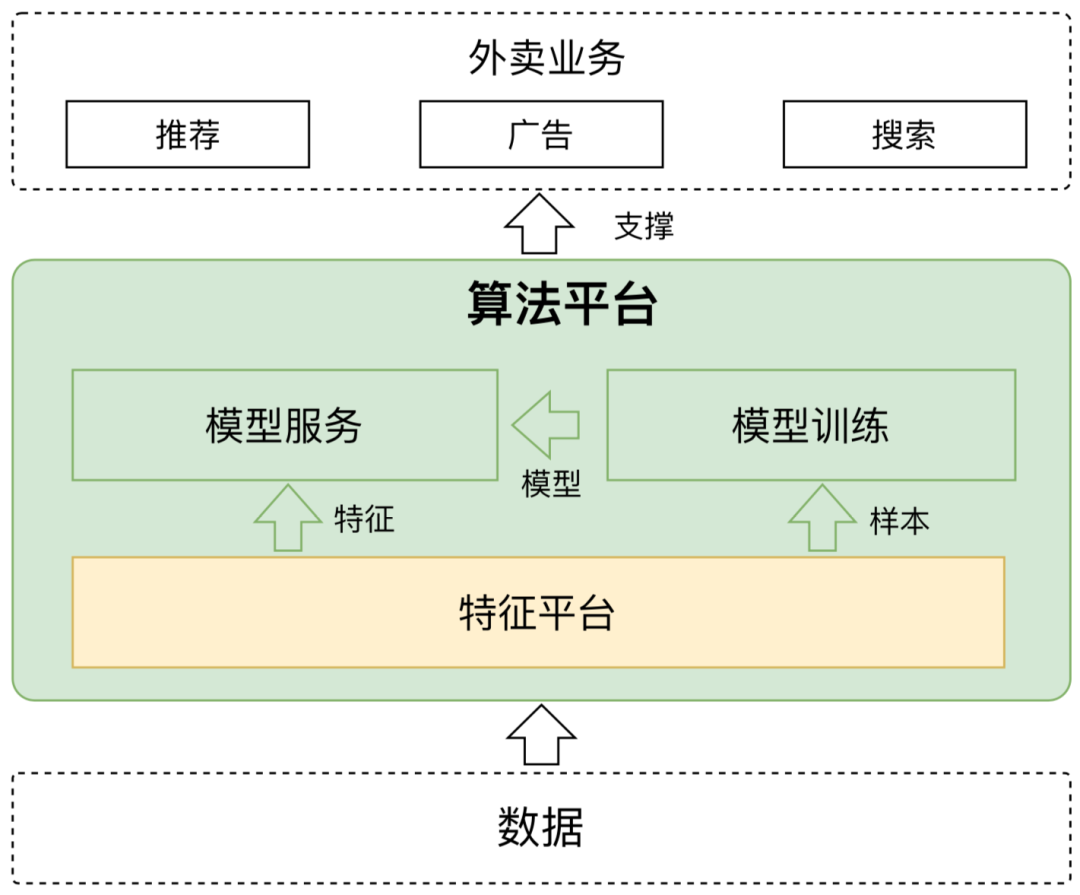
美團外賣業(yè)務(wù)種類繁多、場景豐富,根據(jù)業(yè)務(wù)特點可分為推薦、廣告、搜索三大業(yè)務(wù)線以及數(shù)個子業(yè)務(wù)線,比如商家推薦、菜品推薦、列表廣告、外賣搜索等等,滿足了數(shù)億用戶對外賣服務(wù)的全方面需求。而在每條業(yè)務(wù)線的背后,都涉及用戶、商家、平臺三方面利益的平衡:用戶需要精準的展現(xiàn)結(jié)果;商家需要盡可能多的曝光和轉(zhuǎn)化;平臺需要營收的最大化,而算法策略通過模型機制的優(yōu)化迭代,合理地維護這三方面的利益平衡,促進生態(tài)良性發(fā)展。
隨著業(yè)務(wù)的發(fā)展,外賣算法模型也在不斷演進迭代中。從之前簡單的線性模型、樹模型,到現(xiàn)在復(fù)雜的深度學(xué)習(xí)模型,預(yù)估效果也變得愈發(fā)精準。這一切除了受益于模型參數(shù)的不斷調(diào)優(yōu),也受益于外賣算法平臺對算力增長的工程化支撐。外賣算法平臺通過統(tǒng)一算法工程框架,解決了模型&特征迭代的系統(tǒng)性問題,極大地提升了外賣算法的迭代效率。
根據(jù)功能不同,外賣算法平臺可劃分為三部分:模型服務(wù)、模型訓(xùn)練和特征平臺。其中,模型服務(wù)用于提供在線模型預(yù)估,模型訓(xùn)練用于提供模型的訓(xùn)練產(chǎn)出,特征平臺則提供特征和樣本的數(shù)據(jù)支撐。本文將重點闡述外賣特征平臺在建設(shè)過程中遇到的挑戰(zhàn)以及優(yōu)化思路。
誠然,業(yè)界對特征系統(tǒng)的研究較為廣泛,比如微信FeatureKV存儲系統(tǒng)聚焦于解決特征數(shù)據(jù)快速同步問題,騰訊廣告特征工程聚焦于解決機器學(xué)習(xí)平臺中Pre-Trainer方面的問題,美團酒旅在線特征系統(tǒng)聚焦于解決高并發(fā)情形下的特征存取和生產(chǎn)調(diào)度問題,而外賣特征平臺則聚焦于提供從樣本生成->特征生產(chǎn)->特征計算的一站式鏈路,用于解決特征的快速迭代問題。
隨著外賣業(yè)務(wù)的發(fā)展,特征體量也在快速增長,外賣平臺面對的挑戰(zhàn)和壓力也不斷增大。目前,平臺已接入特征配置近萬個,特征維度近50種,日處理特征數(shù)據(jù)量幾十TB,日處理特征千億量級,日調(diào)度任務(wù)數(shù)量達數(shù)百個。面對海量的數(shù)據(jù)資源,平臺如何做到特征的快速迭代、特征的高效計算以及樣本的配置化生成?下文將分享美團外賣在平臺建設(shè)過程中的一些思考和優(yōu)化思路,希望能對大家有所幫助或啟發(fā)。
2 特征框架演進
2.1 舊框架的不足
外賣業(yè)務(wù)發(fā)展初期,為了提升策略迭代效率,算法同學(xué)通過積累和提煉,整理出一套通用的特征生產(chǎn)框架,該框架由三部分組成:特征統(tǒng)計、特征推送和特征獲取加載。如下圖所示:
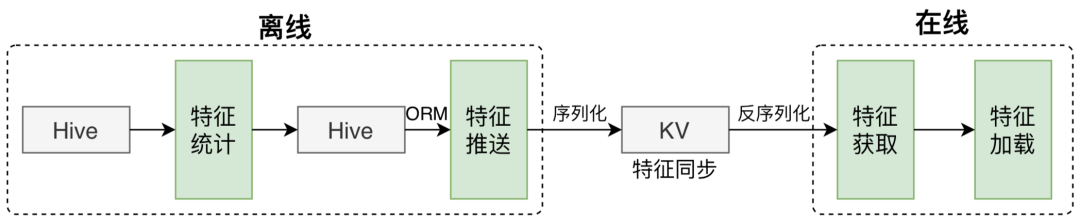
特征統(tǒng)計:基于基礎(chǔ)數(shù)據(jù)表,框架支持統(tǒng)計多個時段內(nèi)特定維度的總量、分布等統(tǒng)計類特征。 特征推送:框架支持將Hive表里的記錄映射成Domain對象,并將序列化后的結(jié)果寫入KV存儲。 特征獲取加載:框架支持在線從KV存儲讀取Domain對象,并將反序列化后的結(jié)果供模型預(yù)估使用。
該框架應(yīng)用在外賣多條業(yè)務(wù)線中,為算法策略的迭代提供了有力支撐。但隨著外賣業(yè)務(wù)的發(fā)展,業(yè)務(wù)線的增多,數(shù)據(jù)體量的增大,該框架逐漸暴露以下三點不足:
特征迭代成本高:框架缺乏配置化管理,新特征上線需要同時改動離線側(cè)和在線側(cè)代碼,迭代周期較長。 特征復(fù)用困難:外賣不同業(yè)務(wù)線間存在相似場景,使特征的復(fù)用成為可能,但框架缺乏對復(fù)用能力的很好支撐,導(dǎo)致資源浪費、特征價值無法充分發(fā)揮。 平臺化能力缺失:框架提供了特征讀寫的底層開發(fā)能力,但缺乏對特征迭代完整周期的平臺化追蹤和管理能力。
2.2 新平臺的優(yōu)勢
針對舊框架的不足,我們在2018年中旬開始著手搭建新版的特征平臺,經(jīng)過不斷的摸索、實踐和優(yōu)化,平臺功能逐漸完備,使特征迭代能力更上一層臺階。
特征平臺框架由三部分組成:訓(xùn)練樣本生成(離線)、特征生產(chǎn)(近線)以及特征獲取計算(在線),如下圖所示:
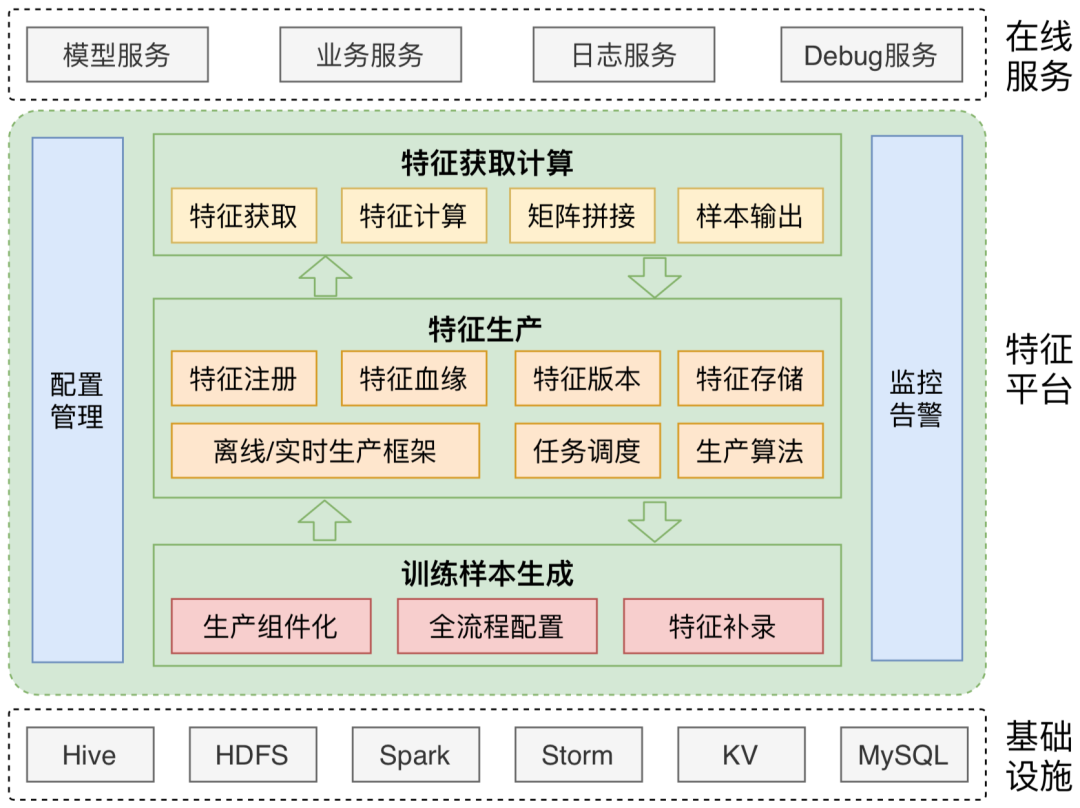
訓(xùn)練樣本生成:離線側(cè),平臺提供統(tǒng)一配置化的訓(xùn)練樣本生成能力,為模型的效果驗證提供數(shù)據(jù)支撐。 特征生產(chǎn):近線側(cè),平臺提供面對海量特征數(shù)據(jù)的加工、調(diào)度、存儲、同步能力,保證特征數(shù)據(jù)在線快速生效。 特征獲取計算:在線側(cè),平臺提供高可用的特征獲取能力和高性能的特征計算能力,靈活支撐多種復(fù)雜模型的特征需求。
目前,外賣特征平臺已接入外賣多條業(yè)務(wù)線,涵蓋數(shù)十個場景,為業(yè)務(wù)的策略迭代提供平臺化支持。其中,平臺的優(yōu)勢在于兩點:
業(yè)務(wù)提效:通過特征配置化管理能力、特征&算子&解決方案復(fù)用能力以及離線在線打通能力,提升了特征迭代效率,降低了業(yè)務(wù)的接入成本,助力業(yè)務(wù)快速拿到結(jié)果。 業(yè)務(wù)賦能:平臺以統(tǒng)一的標準建立特征效果評估體系,有助于特征在業(yè)務(wù)間的借鑒和流通,最大程度發(fā)揮出特征的價值。
3 特征平臺建設(shè)
3.1 特征生產(chǎn):海量特征的生產(chǎn)能力
特征同步的方式有多種,業(yè)界常見做法是通過開發(fā)MR任務(wù)/Spark任務(wù)/使用同步組件,從多個數(shù)據(jù)源讀取多個字段,并將聚合的結(jié)果同步至KV存儲。這種做法實現(xiàn)簡單,但存在以下問題:
特征重復(fù)拉取:同一特征被不同任務(wù)使用時,會導(dǎo)致特征被重復(fù)拉取,造成資源浪費。 缺乏全局調(diào)度:同步任務(wù)間彼此隔離,相互獨立,缺乏多任務(wù)的全局調(diào)度管理機制,無法進行特征復(fù)用、增量更新、全局限流等操作,影響特征的同步速度。 存儲方式不夠靈活健壯:新特征存儲時,涉及到上下游代碼/文件的改動,迭代成本高,特征數(shù)據(jù)異常時,需長時間重導(dǎo)舊數(shù)據(jù),回滾效率較低。
圍繞上述幾點問題,本文將從三個方面進行特征生產(chǎn)核心機制的介紹:
特征語義機制:用于解決平臺從數(shù)百個數(shù)據(jù)源進行特征拉取和轉(zhuǎn)化的效率問題。 特征多任務(wù)調(diào)度機制:用于解決海量特征數(shù)據(jù)的快速同步問題。 特征存儲機制:用于解決特征存儲在配置化和可靠性方面的問題。
3.1.1 特征語義
特征平臺目前已接入上游Hive表數(shù)百個、特征配置近萬個,其中大部分特征都需天級別的更新。那平臺如何從上游高效地拉取特征呢?直觀想法是從特征配置和上游Hive表兩個角度進行考慮:
特征配置角度:平臺根據(jù)每個特征配置,單獨啟動任務(wù)進行特征拉取。
優(yōu)點:控制靈活。 缺點:每個特征都會啟動各自的拉取任務(wù),執(zhí)行效率低且耗費資源。
上游Hive表角度:Hive表中多個特征字段,統(tǒng)一放至同一任務(wù)中拉取。
優(yōu)點:任務(wù)數(shù)量可控,資源占用低。 缺點:任務(wù)邏輯耦合較重,新增特征時需感知Hive表其它字段拉取邏輯,導(dǎo)致接入成本高。
上述兩種方案都存在各自問題,不能很好滿足業(yè)務(wù)需求。因此,特征平臺結(jié)合兩個方案的優(yōu)點,并經(jīng)過探索分析,提出了特征語義的概念:
特征語義:由特征配置中的上游Hive表、特征維度、特征過濾條件、特征聚合條件四個字段提取合并而成,本質(zhì)就是相同的查詢條件,比如:Select KeyInHive,f1,f2 From HiveSrc Where Condition Group by Group,此時該四個字段配置相同,可將F1、F2兩個特征的獲取過程可合并為一個SQL語句進行查詢,從而減少整體查詢次數(shù)。另外,平臺將語義合并過程做成自動化透明化,接入方只需關(guān)心新增特征的拉取邏輯,無需感知同表其它字段,從而降低接入成本。
特征平臺對特征語義的處理分為兩個階段:語義抽取和語義合并,如下圖所示:
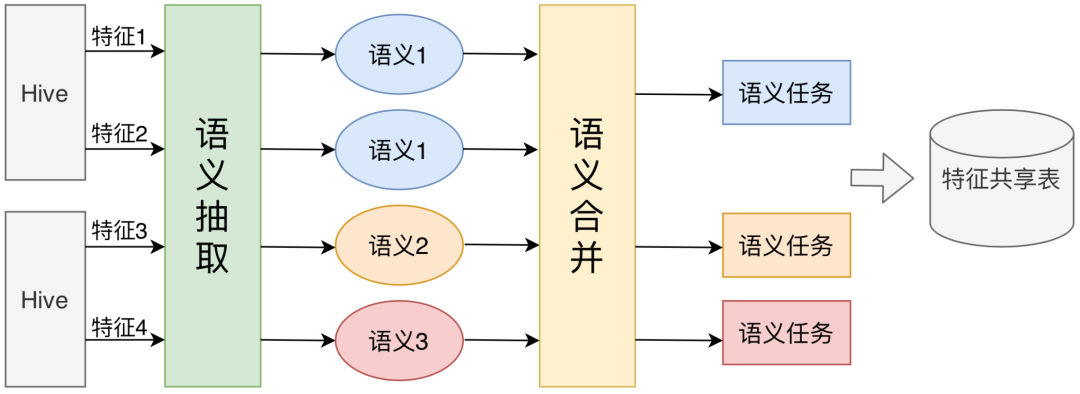
語義抽取:平臺解析特征配置,構(gòu)建SQL語法樹,通過支持多種形式判同邏輯(比如交換律、等效替換等規(guī)則),生成可唯一化表達的SQL語句。 語義合并:如果不同特征對應(yīng)的語義相同,平臺會將其抽取過程進行合并,比如:Select KeyInHive, Extract1 as f1, Extract2 as f2 From HiveSrc Where Condition Group by Group,其中Extract即特征的抽取邏輯,f1和f2的抽取邏輯可進行合并,并將最終抽取到的特征數(shù)據(jù)落地至特征共享表中存儲,供多業(yè)務(wù)方使用。
3.1.2 特征多任務(wù)調(diào)度
為了保證每天數(shù)十TB數(shù)據(jù)量的快速同步,特征平臺首先按照特征的處理流程:獲取、聚合和同步,分別制定了特征語義任務(wù)、特征聚合任務(wù)和特征同步任務(wù):
特征語義任務(wù):用于將特征數(shù)據(jù)從數(shù)據(jù)源拉取解析,并落地至特征共享表中。 特征聚合任務(wù):用于不同業(yè)務(wù)線(租戶)按照自身需求,從特征共享表中獲取特定特征并聚合,生成全量快照以及增量數(shù)據(jù)。 特征同步任務(wù):用于將增量數(shù)據(jù)(天級)和全量數(shù)據(jù)(定期)同步至KV存儲中。
同時,特征平臺搭建了多任務(wù)調(diào)度機制,將不同類型的任務(wù)進行調(diào)度串聯(lián),以提升特征同步的時效性,如下圖所示:
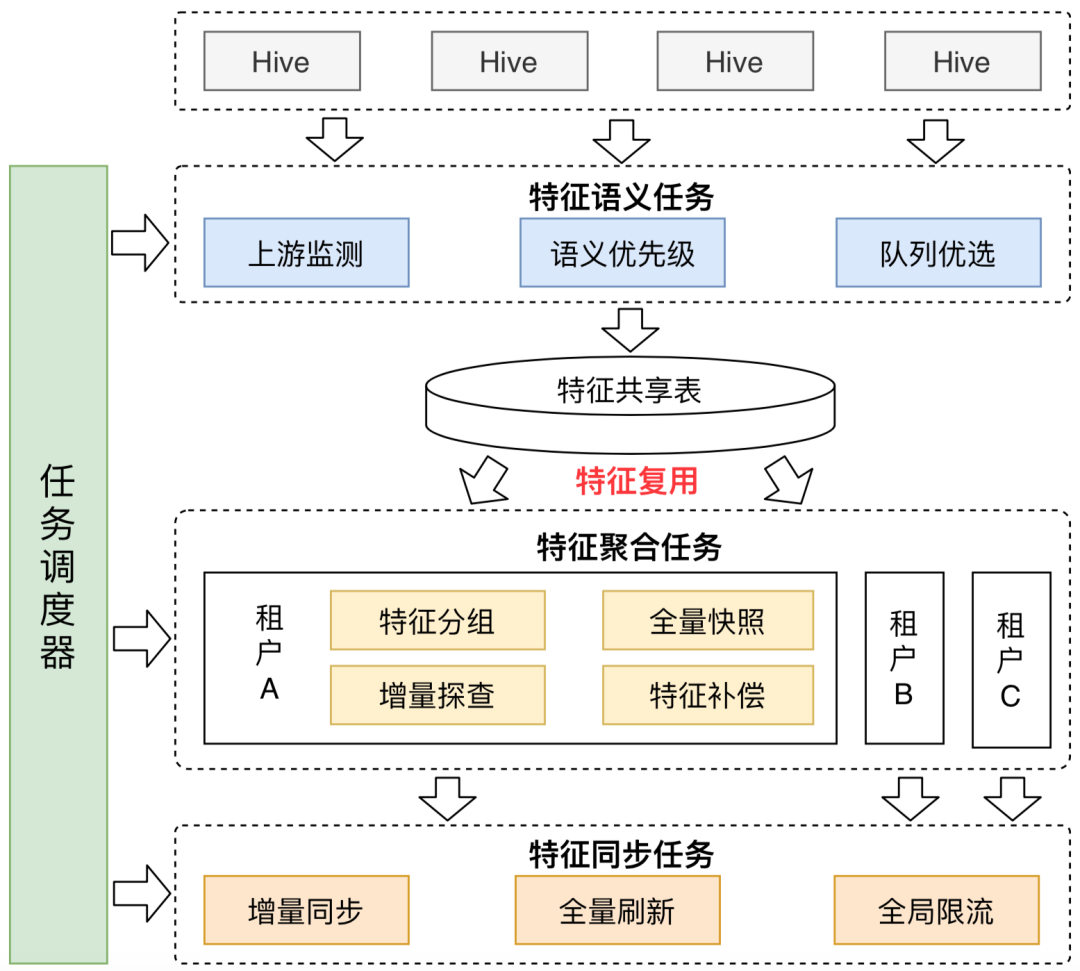
任務(wù)調(diào)度器:按照任務(wù)執(zhí)行順序,循環(huán)檢測上游任務(wù)狀態(tài),保證任務(wù)的有序執(zhí)行。 特征語義任務(wù)調(diào)度:當上游Hive表就緒后,執(zhí)行語義任務(wù)。 上游監(jiān)測:通過上游任務(wù)調(diào)度接口實時獲取上游Hive表就緒狀態(tài),就緒即拉取,保證特征拉取的時效性。 語義優(yōu)先級:每個語義都會設(shè)置優(yōu)先級,高優(yōu)先級語義對應(yīng)的特征會被優(yōu)先聚合和同步,保證重要特征的及時更新。 隊列優(yōu)選:平臺會獲取多個隊列的實時狀態(tài),并優(yōu)先選擇可用資源最多的隊列執(zhí)行語義任務(wù),提升任務(wù)執(zhí)行效率。 特征復(fù)用:特征的價值在于復(fù)用,特征只需接入平臺一次,就可在不同業(yè)務(wù)間流通,是一種業(yè)務(wù)賦能的體現(xiàn)。 特征統(tǒng)一存儲在特征共享表中,供下游不同業(yè)務(wù)方按需讀取,靈活使用。 特征的統(tǒng)一接入復(fù)用,避免相同數(shù)據(jù)的重復(fù)計算和存儲,節(jié)省資源開銷。 特征聚合任務(wù)調(diào)度:當上游語義任務(wù)就緒后,執(zhí)行聚合任務(wù)。 多租戶機制:多租戶是平臺面向多業(yè)務(wù)接入的基礎(chǔ),業(yè)務(wù)以租戶為單位進行特征管理,并為平臺分攤計算資源和存儲資源。 特征分組:特征分組將相同維度下的多個特征進行聚合,以減少特征Key的數(shù)量,避免大量Key讀寫對KV存儲性能造成的影響。 全量快照:平臺通過天級別聚合的方式生成特征全量快照,一方面便于增量數(shù)據(jù)探查,另一方面也避免歷史數(shù)據(jù)的丟失。 增量探查:通過將最新特征數(shù)據(jù)與全量快照的數(shù)值對比,探查出發(fā)生變化的特征,便于后續(xù)增量同步。 特征補償:因就緒延遲而未被當天同步的特征,可跨天進行補償同步,避免出現(xiàn)特征跨天丟失的問題。 特征同步任務(wù)調(diào)度:當上游聚合任務(wù)就緒后,執(zhí)行同步任務(wù)。 增量同步:將經(jīng)全量快照探查到的增量數(shù)據(jù),同步寫入KV存儲,大大降低數(shù)據(jù)寫入量,提升同步效率。 全量刷新:KV存儲中的數(shù)據(jù)由于過期時間限制,需定期進行全量刷新,避免出現(xiàn)特征過期導(dǎo)致的數(shù)據(jù)丟失問題。 全局限流:通過監(jiān)測同步任務(wù)的并行度以及KV存儲狀態(tài)指標,實時調(diào)整全局同步速度,在保證KV存儲穩(wěn)定性前提下,充分利用可用資源來提升特征同步效率。
3.1.3 特征存儲
3.1.3.1 特征動態(tài)序列化
特征數(shù)據(jù)通過聚合處理后,需存儲到HDFS/KV系統(tǒng)中,用于后續(xù)任務(wù)/服務(wù)的使用。數(shù)據(jù)的存儲會涉及到存儲格式的選型,業(yè)界常見的存儲格式有JSON、Object、Protobuf等,其中JSON配置靈活,Object支持自定義結(jié)構(gòu),Protobuf編碼性能好且壓縮比高。由于特征平臺支持的數(shù)據(jù)類型較為固定,但對序列化反序列化性能以及數(shù)據(jù)壓縮效果有較高要求,因此選擇Protobuf作為特征存儲格式。
Protobuf的常規(guī)使用方式是通過Proto文件維護特征配置。新增特征需編輯Proto文件,并編譯生成新版本JAR包,在離線&在線同時發(fā)布更新后,才能生產(chǎn)解析新增特征,導(dǎo)致迭代成本較高。Protobuf也提供了動態(tài)自描述和反射機制,幫助生產(chǎn)側(cè)和消費側(cè)動態(tài)適配消息格式的變更,避免靜態(tài)編譯帶來的JAR包升級成本,但代價是空間成本和性能成本均高于靜態(tài)編譯方式,不適用于高性能、低時延的線上場景。
針對該問題,特征平臺從特征元數(shù)據(jù)管理的角度,設(shè)計了一種基于Protobuf的特征動態(tài)序列化機制,在不影響讀寫性能前提下,做到對新增特征讀寫的完全配置化。
為方便闡述,先概述下Protobuf編碼格式。如下圖所示,Protobuf按“鍵-值”形式序列化每個屬性,其中鍵標識了該屬性的序號和類型。可以看出,從原理上,序列化主要要依賴鍵中定義的字段序號和類型。

因此,特征平臺通過從元數(shù)據(jù)管理接口查詢元數(shù)據(jù),來替換常規(guī)的Proto文件配置方式,去動態(tài)填充和解析鍵中定義的字段序號和類型,以完成序列化和反序列化,如下圖所示:
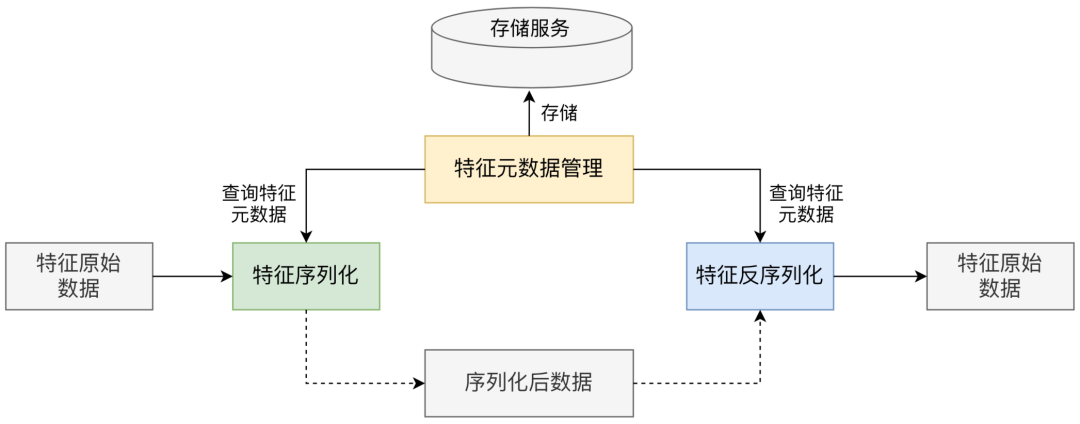
特征序列化:通過查詢特征元數(shù)據(jù),獲取特征的序號和類型,將特征序號填充至鍵的序號屬性中,并根據(jù)特征類型決定鍵的類型屬性以及特征值的填充方式。 特征反序列化:解析鍵的屬性,獲取特征序號,通過查詢特征元數(shù)據(jù),獲取對應(yīng)的特征類型,并根據(jù)特征類型決定特征值的解析方式(定長/變長)。
3.1.3.2 特征多版本
特征數(shù)據(jù)存儲于KV系統(tǒng)中,為在線服務(wù)提供特征的實時查詢。業(yè)界常見的特征在線存儲方式有兩種:單一版本存儲和多版本存儲。
單一版本存儲即覆蓋更新,用新數(shù)據(jù)直接覆蓋舊數(shù)據(jù),實現(xiàn)簡單,對物理存儲占用較少,但在數(shù)據(jù)異常的時候無法快速回滾。 多版本存儲相比前者,增加了版本概念,每一份數(shù)據(jù)都對應(yīng)特定版本,雖然物理存儲占用較多,但在數(shù)據(jù)異常的時候可通過版本切換的方式快速回滾,保證線上穩(wěn)定性。
因此,特征平臺選擇特征多版本作為線上數(shù)據(jù)存儲方式。
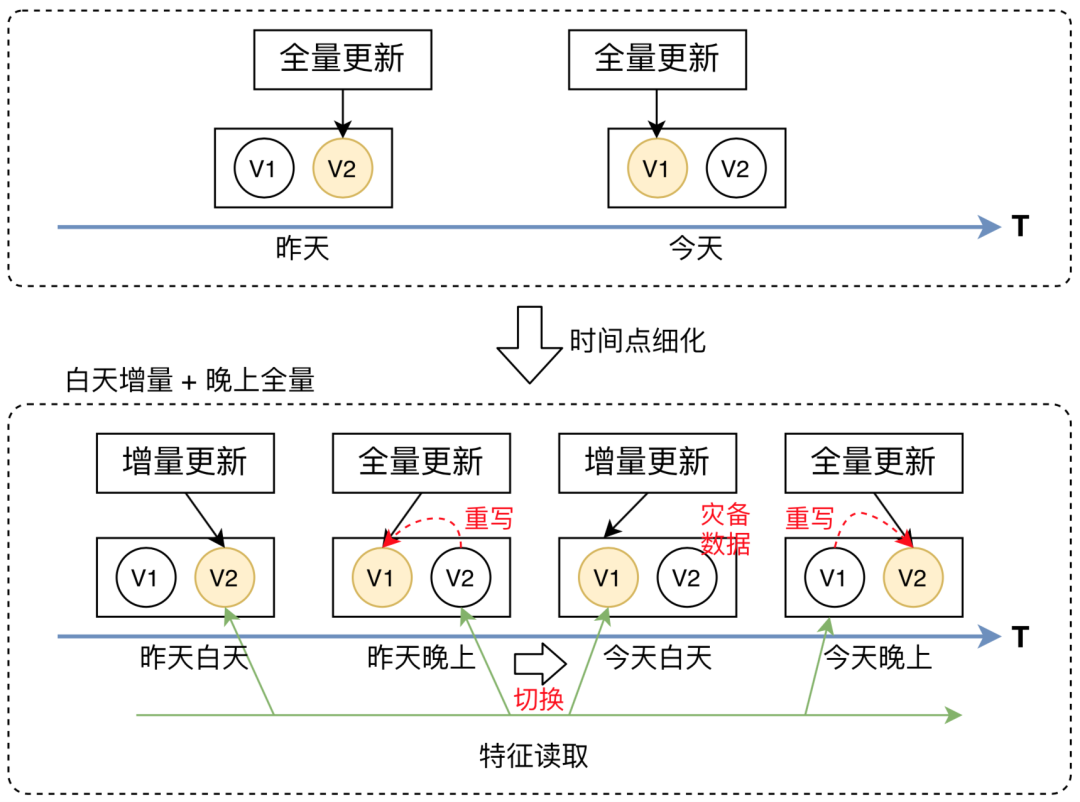
傳統(tǒng)的多版本方式是通過全量數(shù)據(jù)的切換實現(xiàn),即每天在全量數(shù)據(jù)寫入后再進行版本切換。然而,特征平臺存在增量和全量兩種更新方式,不能簡單復(fù)用全量的切換方式,需考慮增量和全量的依賴關(guān)系。因此,特征平臺設(shè)計了一種適用于增量&全量兩種更新方式下的版本切換方式(如下圖所示)。該方式以全量數(shù)據(jù)為基礎(chǔ),白天進行增量更新,版本保持不變,在增量更新結(jié)束后,定期進行全量更新(重寫),并進行版本切換。
3.2 特征獲取計算:高性能的特征獲取計算能力
特征獲取計算為模型服務(wù)、業(yè)務(wù)系統(tǒng)、離線訓(xùn)練提供特征的實時獲取能力和高性能的計算能力,是特征平臺能力輸出的重要途徑。
舊框架中,特征處理分散在業(yè)務(wù)系統(tǒng)中,與業(yè)務(wù)邏輯耦合嚴重,隨著模型規(guī)模增長和業(yè)務(wù)系統(tǒng)的架構(gòu)升級,特征處理性能逐漸成為瓶頸,主要存在以下問題:
需要代碼開發(fā):特征處理的代碼冗長,一方面會造成易增難改的現(xiàn)象,另一方面相同邏輯代碼重復(fù)拷貝較多,也會造成復(fù)用性逐漸變差,代碼質(zhì)量就會持續(xù)惡化。 潛在性能風險:大量實驗同時進行,每次處理特征并集,性能會互相拖累。 一致性難以保證:離線訓(xùn)練樣本和在線預(yù)估對特征的處理邏輯難以統(tǒng)一。
因此,我們在新平臺建設(shè)中,將特征處理邏輯抽象成獨立模塊,并對模塊的職責邊界做了清晰設(shè)定:通過提供統(tǒng)一API的方式,只負責特征的獲取和計算,而不關(guān)心業(yè)務(wù)流程上下文。在新的特征獲取和計算模塊設(shè)計中,我們主要關(guān)注以下兩個方面:
易用性:特征處理配置的易用性會影響到使用方的迭代效率,如果新增特征或更改特征計算邏輯需要代碼改動,勢必會拖慢迭代效率。 性能:特征處理過程需要實時處理大量特征的拉取和計算邏輯,其效率會直接影響到上游服務(wù)的整體性能。
圍繞以上兩點,本文將從下述兩個方面分別介紹特征獲取計算部分:
模型特征自描述MFDL:將特征計算流程配置化,提升特征使用的易用性。 特征獲取流程:統(tǒng)一特征獲取流程,解決特征獲取的性能問題。
3.2.1 模型特征自描述MFDL
模型特征處理是模型預(yù)處理的一部分,業(yè)界常用的做法有:
將特征處理邏輯和模型打包在一起,使用PMML或類似格式描述。優(yōu)點是配置簡潔;缺點是無法單獨更新模型文件或特征配置。
將特征處理邏輯和模型隔離,特征處理部分使用單獨的配置描述,比如JSON或CSV等格式。優(yōu)點是特征處理配置和模型文件分離,便于分開迭代;缺點是可能會引起特征配置和模型加載不一致性的問題,增加系統(tǒng)復(fù)雜度。
考慮到對存量模型的兼容,我們定義了一套自有的配置格式,能獨立于模型文件之外快速配置。基于對原有特征處理邏輯的梳理,我們將特征處理過程抽象成以下兩個部分:
模型特征計算:主要用來描述特征的計算過程。這里區(qū)分了原始特征和模型特征:將從數(shù)據(jù)源直接獲取到的特征稱之為原始特征,將經(jīng)過計算后輸入給模型的特征稱之為模型特征,這樣就可以實現(xiàn)同一個原始特征經(jīng)過不同的處理邏輯計算出不同的模型特征。
模型特征轉(zhuǎn)換:將生成的模型特征根據(jù)配置轉(zhuǎn)換成可以直接輸入給模型的數(shù)據(jù)格式。由于模型特征計算的結(jié)果不能被模型直接使用,還需要經(jīng)過一些轉(zhuǎn)換邏輯的處理,比如轉(zhuǎn)換成Tensor、Matrix等格式。
基于該兩點,特征平臺設(shè)計了MFDL(Model Feature Description Language)來完整的描述模型特征的生成流程,用配置化的方式描述模型特征計算和轉(zhuǎn)換過程。其中,特征計算部分通過自定義的DSL來描述,而特征轉(zhuǎn)換部分則針對不同類型的模型設(shè)計不同的配置項。通過將特征計算和轉(zhuǎn)換分離,就可以很方便的擴展支持不同的機器學(xué)習(xí)框架或模型結(jié)構(gòu)。
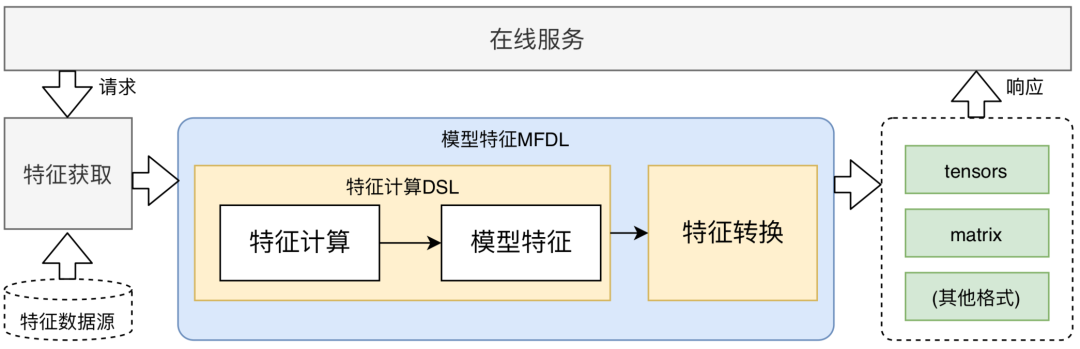
在MFDL流程中,特征計算DSL是模型處理的重點和難點。一套易用的特征計算規(guī)范需既要滿足特征處理邏輯的差異性,又要便于使用和理解。經(jīng)過對算法需求的了解和對業(yè)界做法的調(diào)研,我們開發(fā)了一套易用易讀且符合編程習(xí)慣的特征表達式,并基于JavaCC實現(xiàn)了高性能的執(zhí)行引擎,支持了以下特性:
特征類型:支持以下常用的特征數(shù)據(jù)結(jié)構(gòu): 單值類型(String/Long/Double):數(shù)值和文本類型特征。 Map類型:交叉或字典類型的特征。 List類型:Embedding或向量特征。 邏輯運算:支持常規(guī)的算術(shù)和邏輯運算,比如a>b?(a-b):0。 函數(shù)算子:邏輯運算只適合少量簡單的處理邏輯,而更多復(fù)雜的邏輯通常需要通過函數(shù)算子來完成。業(yè)務(wù)方既可以根據(jù)自己的需求編寫算子,也可快速復(fù)用平臺定期收集整理的常用算子,以降低開發(fā)成本,提升模型迭代效率。
特征計算DSL舉例如下所示:

基于規(guī)范化的DSL,一方面可以讓執(zhí)行引擎在執(zhí)行階段做一些主動優(yōu)化,包括向量化計算、并行計算等,另一方面也有助于使用方將精力聚焦于特征計算的業(yè)務(wù)邏輯,而不用關(guān)心實現(xiàn)細節(jié),既降低了使用門檻,也避免了誤操作對線上穩(wěn)定性造成的影響。
由于MFDL是獨立于模型文件之外的配置,因此特征更新迭代時只需要將新的配置推送到服務(wù)器上,經(jīng)過加載和預(yù)測后即可生效,實現(xiàn)了特征處理的熱更新,提升了迭代效率。同時,MFDL也是離線訓(xùn)練時使用的特征配置文件,結(jié)合統(tǒng)一的算子邏輯,保證了離線訓(xùn)練樣本/在線預(yù)估特征處理的一致性。在系統(tǒng)中,只需要在離線訓(xùn)練時配置一次,訓(xùn)練完成后即可一鍵推送到線上服務(wù),安全高效。
下面是一個TF模型的MFDL配置示例:
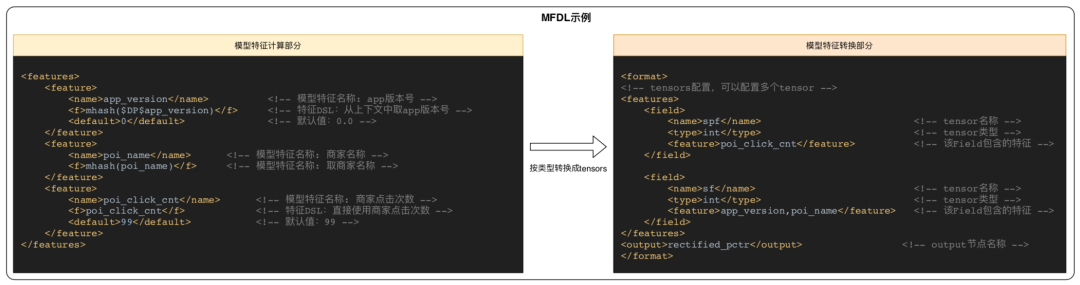
3.2.2 特征獲取流程
MFDL中使用到的特征數(shù)據(jù),需在特征計算之前從KV存儲進行統(tǒng)一獲取。為了提升特征獲取效率,平臺會對多個特征數(shù)據(jù)源異步并行獲取,并針對不同的數(shù)據(jù)源,使用不同的手段進行優(yōu)化,比如RPC聚合等。特征獲取的基本流程如下圖所示:
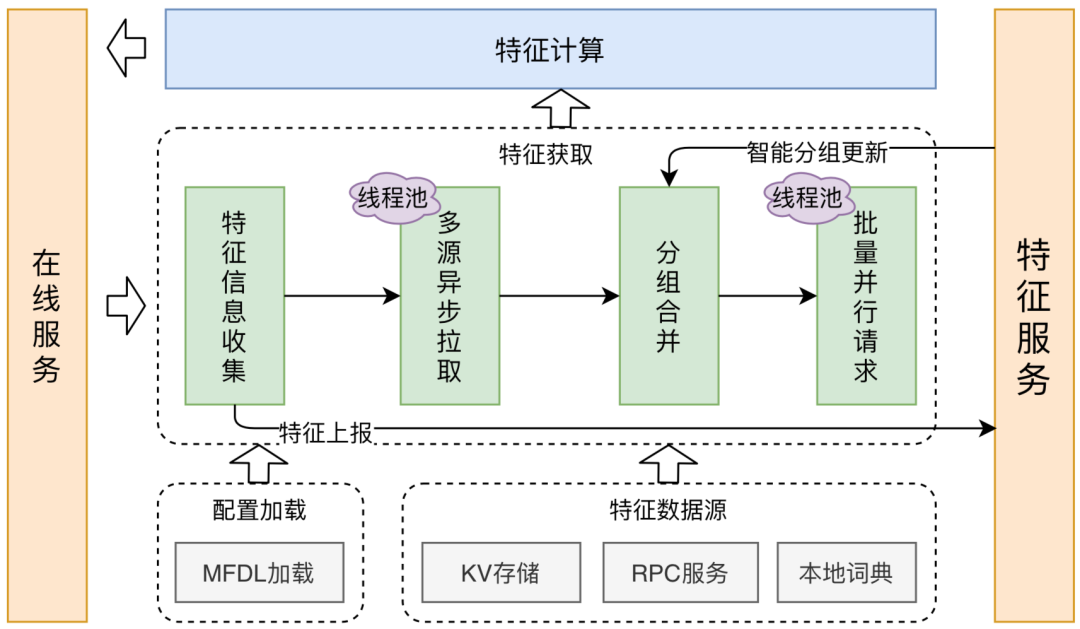
在特征生產(chǎn)章節(jié)已經(jīng)提到,特征數(shù)據(jù)是按分組進行聚合存儲。特征獲取在每次訪問KV存儲時,都會讀取整個分組下所有的特征數(shù)據(jù),一個分組下特征數(shù)量的多少將會直接影響到在線特征獲取的性能。因此,我們在特征分組分配方面進行了相關(guān)優(yōu)化,既保證了特征獲取的高效性,又保證了線上服務(wù)的穩(wěn)定性。
3.2.2.1 智能分組
特征以分組的形式進行聚合,用于特征的寫入和讀取。起初,特征是以固定分組的形式進行組織管理,即不同業(yè)務(wù)線的特征會被人工聚合到同一分組中,這種方式實現(xiàn)簡單,但卻暴露出以下兩點問題:
特征讀取性能差:線上需要讀取解析多個業(yè)務(wù)線聚合后的特征大Value,而每個業(yè)務(wù)線只會用到其中部分特征,導(dǎo)致計算資源浪費、讀取性能變差。 影響KV集群穩(wěn)定性:特征大Value被高頻讀取,一方面會將集群的網(wǎng)卡帶寬打滿,另一方面大Value不會被讀取至內(nèi)存,只能磁盤查找,影響集群查詢性能(特定KV存儲場景)。
因此,特征平臺設(shè)計了智能分組,打破之前固定分組的形式,通過合理機制進行特征分組的動態(tài)調(diào)整,保證特征聚合的合理性和有效性。如下圖所示,平臺打通了線上線下鏈路,線上用于上報業(yè)務(wù)線所用的特征狀態(tài),線下則通過收集分析線上特征,從全局視角對特征所屬分組進行智能化的整合、遷移、反饋和管理。同時,基于存儲和性能的折中考慮,平臺建立了兩種分組類型:業(yè)務(wù)分組和公共分組:
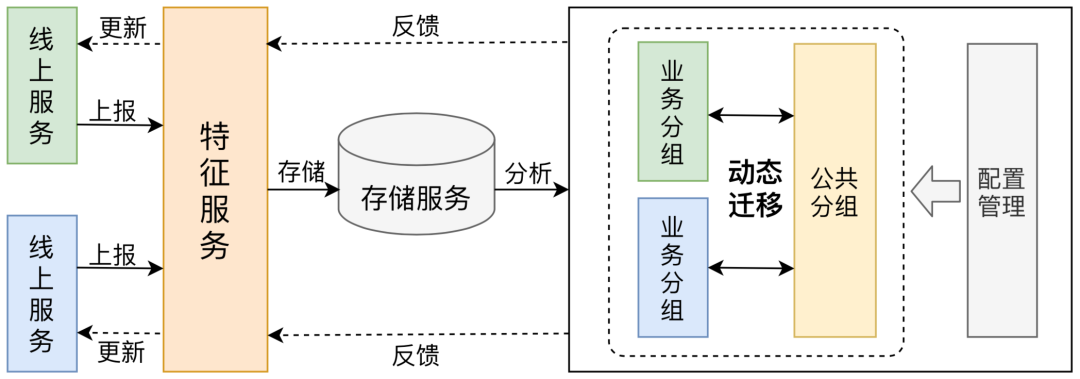
業(yè)務(wù)分組:用于聚合每個業(yè)務(wù)線各自用到的專屬特征,保證特征獲取的有效性。如果特征被多業(yè)務(wù)共用,若仍存儲在各自業(yè)務(wù)分組,會導(dǎo)致存儲資源浪費,需遷移至公共分組(存儲角度)。 公共分組:用于聚合多業(yè)務(wù)線同時用到的特征,節(jié)省存儲資源開銷,但分組增多會帶來KV存儲讀寫量增大,因此公共分組數(shù)量需控制在合理范圍內(nèi)(性能角度)。
通過特征在兩種分組間的動態(tài)遷移以及對線上的實時反饋,保證各業(yè)務(wù)對特征所拉即所用,提升特征讀取性能,保證KV集群穩(wěn)定性。
3.2.2.2 分組合并
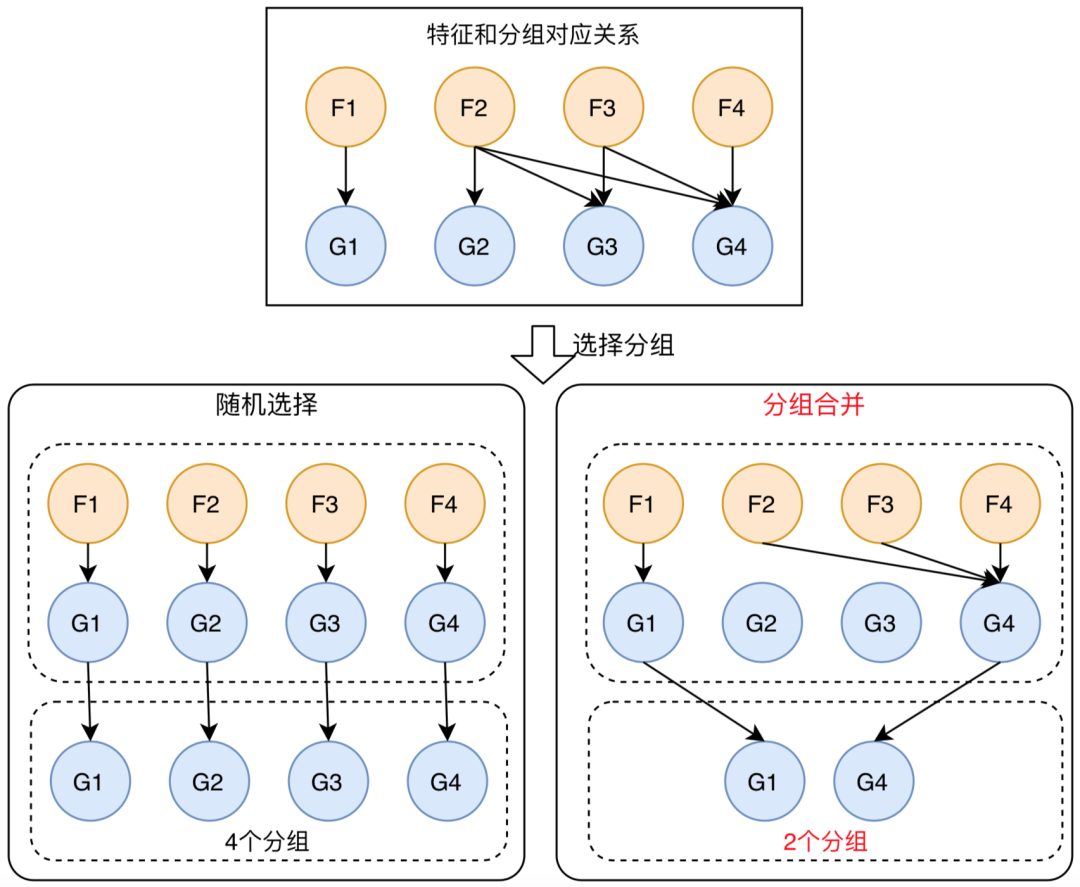
智能分組可以有效的提升特征獲取效率,但同時也引入了一個問題:在智能分組過程中,特征在分組遷移階段,會出現(xiàn)一個特征同時存在于多個分組的情況,造成特征在多個分組重復(fù)獲取的問題,增加對KV存儲的訪問壓力。為了優(yōu)化特征獲取效率,在特征獲取之前需要對特征分組進行合并,將特征盡量放在同一個分組中進行獲取,從而減少訪問KV存儲的次數(shù),提升特征獲取性能。
如下圖所示,經(jīng)過分組合并,將特征獲取的分組個數(shù)由4個(最壞情況)減少到2個,從而對KV存儲訪問量降低一半。
3.3 訓(xùn)練樣本構(gòu)建:統(tǒng)一配置化的一致性訓(xùn)練樣本生成能力
3.3.1 現(xiàn)狀分析
訓(xùn)練樣本是特征工程連接算法模型的一個關(guān)鍵環(huán)節(jié),訓(xùn)練樣本構(gòu)建的本質(zhì)是一個數(shù)據(jù)加工過程,而這份數(shù)據(jù)如何做到“能用”(數(shù)據(jù)質(zhì)量要準確可信)、“易用”(生產(chǎn)過程要靈活高效)、“好用”(通過平臺能力為業(yè)務(wù)賦能)對于算法模型迭代的效率和效果至關(guān)重要。
在特征平臺統(tǒng)一建設(shè)之前,外賣策略團隊在訓(xùn)練樣本構(gòu)建流程上主要遇到幾個問題:
重復(fù)性開發(fā):缺少體系化的平臺系統(tǒng),依賴一些簡單工具或定制化開發(fā)Hive/Spark任務(wù),與業(yè)務(wù)耦合性較高,在流程復(fù)用、運維成本、性能調(diào)優(yōu)等方面都表現(xiàn)較差。 靈活性不足:樣本構(gòu)建流程復(fù)雜,包括但不限數(shù)據(jù)預(yù)處理、特征抽取、特征樣本拼接、特征驗證,以及數(shù)據(jù)格式轉(zhuǎn)換(如TFRecord)等,已有工具在配置化、擴展性上很難滿足需求,使用成本較高。 一致性較差:線上、線下在配置文件、算子上使用不統(tǒng)一,導(dǎo)致在線預(yù)測樣本與離線訓(xùn)練樣本的特征值不一致,模型訓(xùn)練正向效果難保障。
3.3.2 配置化流程
平臺化建設(shè)最重要的流程之一是“如何進行流程抽象”,業(yè)界有一些機器學(xué)習(xí)平臺的做法是平臺提供較細粒度的組件,讓用戶自行選擇組件、配置依賴關(guān)系,最終生成一張樣本構(gòu)建的DAG圖。
對于用戶而言,這樣看似是提高了流程編排的自由度,但深入了解算法同學(xué)實際工作場景后發(fā)現(xiàn),算法模型迭代過程中,大部分的樣本生產(chǎn)流程都比較固定,反而讓用戶每次都去找組件、配組件屬性、指定關(guān)系依賴這樣的操作,會給算法同學(xué)帶來額外的負擔,所以我們嘗試了一種新的思路來優(yōu)化這個問題:模板化 + 配置化,即平臺提供一個基準的模板流程,該流程中的每一個節(jié)點都抽象為一個或一類組件,用戶基于該模板,通過簡單配置即可生成自己樣本構(gòu)建流程,如下圖所示:
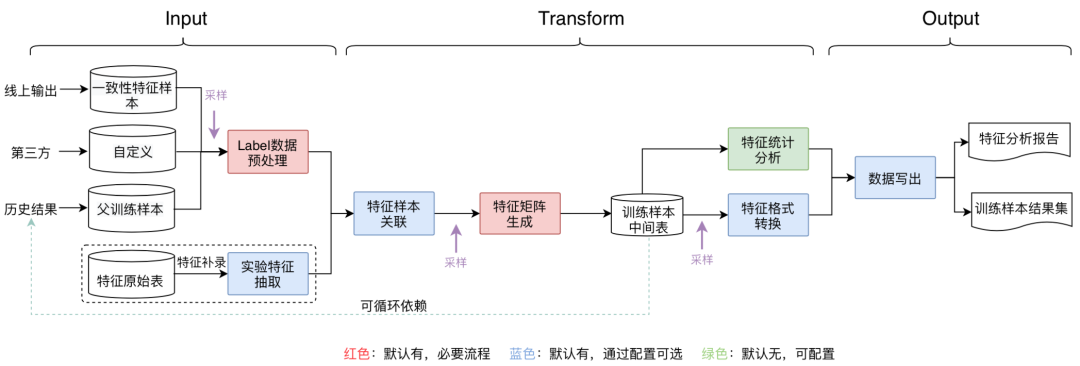
整個流程模板包括三個部分:輸入(Input)、轉(zhuǎn)化(Transform)、輸出(Output), 其中包含的組件有:Label數(shù)據(jù)預(yù)處理、實驗特征抽取、特征樣本關(guān)聯(lián)、特征矩陣生成、特征格式轉(zhuǎn)換、特征統(tǒng)計分析、數(shù)據(jù)寫出,組件主要功能:
Label數(shù)據(jù)預(yù)處理:支持通過自定義Hive/Spark SQL方式抽取Label數(shù)據(jù),平臺也內(nèi)置了一些UDF(如URL Decode、MD5/Murmur Hash 等),通過自定義SQL+UDF方式靈活滿足各種數(shù)據(jù)預(yù)處理的需求。在數(shù)據(jù)源方面,支持如下類型: 一致性特征樣本:指線上模型預(yù)測時,會將一次預(yù)測請求中使用到的特征及Label相關(guān)字段收集、加工、拼接,為離線訓(xùn)練提供基礎(chǔ)的樣本數(shù)據(jù),推薦使用,可更好保障一致性。 自定義:不使用算法平臺提供的一致性特征樣本數(shù)據(jù)源,通過自定義方式抽取Label數(shù)據(jù)。 父訓(xùn)練樣本:可依賴之前或其他同學(xué)生產(chǎn)的訓(xùn)練樣本結(jié)果,只需要簡單修改特征或采樣等配置,即可實現(xiàn)對原數(shù)據(jù)微調(diào),快速生成新的訓(xùn)練數(shù)據(jù),提高執(zhí)行效率。 實驗特征抽取:線下訓(xùn)練如果需要調(diào)研一些新特征(即在一致性特征樣本中不存在)效果,可以通過特征補錄方式加入新的特征集。 特征樣本關(guān)聯(lián):將Label數(shù)據(jù)與補錄的實驗特征根據(jù)唯一標識(如:poi_id)進行關(guān)聯(lián)。 特征矩陣生成:根據(jù)用戶定義的特征MFDL配置文件,將每一個樣本需要的特征集計算合并,生成特征矩陣,得到訓(xùn)練樣本中間表。 特征格式轉(zhuǎn)換:基于訓(xùn)練樣本中間表,根據(jù)不同模型類型,將數(shù)據(jù)轉(zhuǎn)換為不同格式的文件(如:CSV/TFRecord)。 特征統(tǒng)計分析:輔助功能,基于訓(xùn)練樣本中間表,對特征統(tǒng)計分析,包括均值、方差、最大/最小值、分位數(shù)、空值率等多種統(tǒng)計維度,輸出統(tǒng)計分析報告。 數(shù)據(jù)寫出:將不同中間結(jié)果,寫出到Hive表/HDFS等存儲介質(zhì)。
上面提到,整個流程是模板化,模板中的多數(shù)環(huán)節(jié)都可以通過配置選擇開啟或關(guān)閉,所以整個流程也支持從中間的某個環(huán)節(jié)開始執(zhí)行,靈活滿足各類數(shù)據(jù)生成需求。
3.3.3 一致性保障
(1)為什么會不一致?
上文還提到了一個關(guān)鍵的問題:一致性較差。先來看下為什么會不一致?
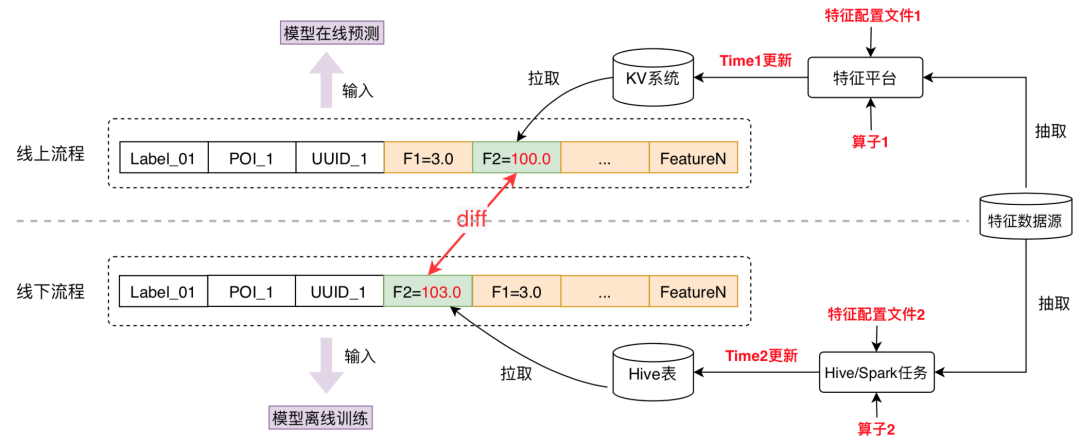
上圖展示了在離線訓(xùn)練和在線預(yù)測兩條鏈路中構(gòu)建樣本的方式,最終導(dǎo)致離線、在線特征值Diff的原因主要有三點:
特征配置文件不一致:在線側(cè)、離線側(cè)對特征計算、編排等配置描述未統(tǒng)一,靠人工較難保障一致性。 特征更新時機不一致:特征一般是覆蓋更新,特征抽取、計算、同步等流程較長,由于數(shù)據(jù)源更新、重刷、特征計算任務(wù)失敗等諸多不確定因素,在線、離線在不同的更新時機下,數(shù)據(jù)口徑不一致。 特征算子定義不一致:從數(shù)據(jù)源抽取出來的原始特征一般都需要經(jīng)過二次運算,線上、線下算子不統(tǒng)一。
(2)如何保證一致性?
明確了問題所在,我們通過如下方案來解決一致性問題:
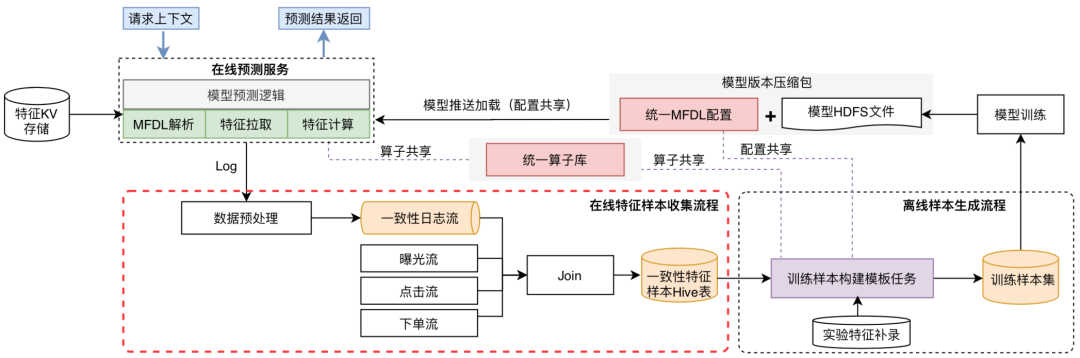
打通線上線下配置
線下生成訓(xùn)練樣本時,用戶先定義特征MFDL配置文件,在模型訓(xùn)練后,通過平臺一鍵打包功能,將MFDL配置文件以及訓(xùn)練輸出的模型文件,打包、上傳到模型管理平臺,通過一定的版本管理及加載策略,將模型動態(tài)加載到線上服務(wù),從而實現(xiàn)線上、線下配置一體化。
提供一致性特征樣本
通過實時收集在線Serving輸出的特征快照,經(jīng)過一定的規(guī)則處理,將結(jié)果數(shù)據(jù)輸出到Hive表,作為離線訓(xùn)練樣本的基礎(chǔ)數(shù)據(jù)源,提供一致性特征樣本,保障在線、離線數(shù)據(jù)口徑一致。
統(tǒng)一特征算子庫
上文提到可以通過特征補錄方式添加新的實驗特征,補錄特征如果涉及到算子二次加工,平臺既提供基礎(chǔ)的算子庫,也支持自定義算子,通過算子庫共用保持線上、線下計算口徑一致。
3.3.4 為業(yè)務(wù)賦能
從特征生產(chǎn),到特征獲取計算,再到生成訓(xùn)練樣本,特征平臺的能力不斷得到延展,逐步和離線訓(xùn)練流程、在線預(yù)測服務(wù)形成一個緊密協(xié)作的整體。在特征平臺的能力邊界上,我們也在不斷的思考和探索,希望能除了為業(yè)務(wù)提供穩(wěn)定、可靠、易用的特征數(shù)據(jù)之外,還能從特征的視角出發(fā),更好的建設(shè)特征生命周期閉環(huán),通過平臺化的能力反哺業(yè)務(wù),為業(yè)務(wù)賦能。在上文特征生產(chǎn)章節(jié),提到了特征平臺一個重要能力:特征復(fù)用,這也是特征平臺為業(yè)務(wù)賦能最主要的一點。
特征復(fù)用需要解決兩個問題:
特征快速發(fā)現(xiàn):當前特征平臺有上萬特征,需要通過平臺化的能力,讓高質(zhì)量的特征快速被用戶發(fā)現(xiàn),另外,特征的“高質(zhì)量”如何度量,也需要有統(tǒng)一的評價標準來支撐。 特征快速使用:對于用戶發(fā)現(xiàn)并篩選出的目標特征,平臺需要能夠以較低的配置成本、計算資源快速支持使用(參考上文3.1.2 小節(jié)“特征復(fù)用”)。
本小節(jié)重點介紹如何幫助用戶快速發(fā)現(xiàn)特征,主要包括兩個方面:主動檢索和被動推薦,如下圖所示:
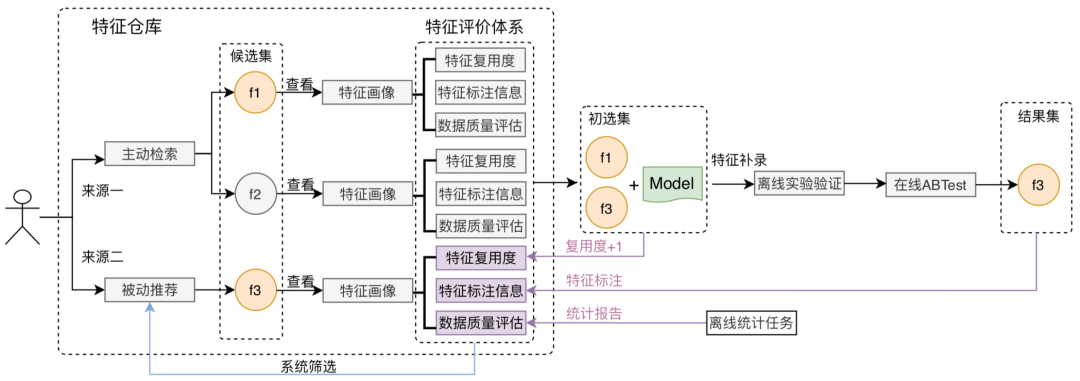
首先,用戶可以通過主動檢索,從特征倉庫篩選出目標特征候選集,然后結(jié)合特征畫像來進一步篩選,得到特征初選集,最后通過離線實驗流程、在線ABTest,結(jié)合模型效果,評估篩選出最終的結(jié)果集。其中特征畫像主要包括以下評價指標: 特征復(fù)用度:通過查看該特征在各業(yè)務(wù)、各模型的引用次數(shù),幫助用戶直觀判斷該特征的價值。 特征標注信息:通過查看該特征在其他業(yè)務(wù)離線、在線效果的標注信息,幫助用戶判斷該特征的正負向效果。 數(shù)據(jù)質(zhì)量評估:平臺通過離線統(tǒng)計任務(wù),按天粒度對特征進行統(tǒng)計分析,包括特征的就緒時間、空值率、均值、方差、最大/小值、分位點統(tǒng)計等,生成特征評估報告,幫助用戶判斷該特征是否可靠。 其次,平臺根據(jù)特征的評價體系,將表現(xiàn)較好的Top特征篩選出來,通過排行榜展現(xiàn)、消息推送方式觸達用戶,幫助用戶挖掘高分特征。
為業(yè)務(wù)賦能是一個長期探索和實踐的過程,未來我們還會繼續(xù)嘗試在深度學(xué)習(xí)場景中,建立每個特征對模型貢獻度的評價體系,并通過自動化的方式打通模型在線上、線下的評估效果,通過智能化的方式挖掘特征價值。
4 總結(jié)與展望
本文分別從特征框架演進、特征生產(chǎn)、特征獲取計算以及訓(xùn)練樣本生成四個方面介紹了特征平臺在建設(shè)與實踐中的思考和優(yōu)化思路。經(jīng)過兩年的摸索建設(shè)和實踐,外賣特征平臺已經(jīng)建立起完善的架構(gòu)體系、一站式的服務(wù)流程,為外賣業(yè)務(wù)的算法迭代提供了有力支撐。
未來,外賣特征平臺將繼續(xù)推進從離線->近線->在線的全鏈路優(yōu)化工作,在計算性能、資源開銷、能力擴展、合作共建等方面持續(xù)投入人力探索和建設(shè),并在更多更具挑戰(zhàn)的業(yè)務(wù)場景中發(fā)揮平臺的價值。同時,平臺將繼續(xù)和模型服務(wù)和模型訓(xùn)練緊密結(jié)合,共建端到端算法閉環(huán),助力外賣業(yè)務(wù)蓬勃發(fā)展。
5 作者簡介
英亮、陳龍、劉磊、亞劼、樂彬等,美團外賣算法平臺工程師。
推薦閱讀:
華為15年招聘經(jīng)驗總結(jié):可用之才,必備5個特質(zhì)