
又改YOLO | 項(xiàng)目如何改進(jìn)YOLOv5?這篇告訴你如何修改讓檢測更快、更穩(wěn)!!

極市導(dǎo)讀
?本文提出了一種改進(jìn)的特征金字塔模型AF-FPN,該模型利用自適應(yīng)注意模塊(adaptive attention module, AAM)和特征增強(qiáng)模塊(feature enhancement module, FEM)來減少特征圖生成過程中的信息丟失,進(jìn)而提高特征金字塔的表示能力。此外,提出了一種新的自動學(xué)習(xí)數(shù)據(jù)增強(qiáng)方法,以豐富數(shù)據(jù)集,提高模型的魯棒性,使其更適合于實(shí)際場景。大量實(shí)驗(yàn)結(jié)果表明本文方法的有效性和優(yōu)越性得到了驗(yàn)證。?>>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿

交通標(biāo)志檢測對于無人駕駛系統(tǒng)來說是一項(xiàng)具有挑戰(zhàn)性的任務(wù),尤其是多尺度目標(biāo)檢測和檢測的實(shí)時性問題。在交通標(biāo)志檢測過程中,目標(biāo)的規(guī)模變化很大,會對檢測精度產(chǎn)生一定的影響。特征金字塔是解決這一問題的常用方法,但它可能會破壞交通標(biāo)志在不同尺度上的特征一致性。而且,在實(shí)際應(yīng)用中,普通方法難以在保證實(shí)時檢測的同時提高多尺度交通標(biāo)志的檢測精度。
本文提出了一種改進(jìn)的特征金字塔模型AF-FPN,該模型利用自適應(yīng)注意模塊(adaptive attention module, AAM)和特征增強(qiáng)模塊(feature enhancement module, FEM)來減少特征圖生成過程中的信息丟失,進(jìn)而提高特征金字塔的表示能力。將YOLOv5中原有的特征金字塔網(wǎng)絡(luò)替換為AF-FPN,在保證實(shí)時檢測的前提下,提高了YOLOv5網(wǎng)絡(luò)對多尺度目標(biāo)的檢測性能。
此外,提出了一種新的自動學(xué)習(xí)數(shù)據(jù)增強(qiáng)方法,以豐富數(shù)據(jù)集,提高模型的魯棒性,使其更適合于實(shí)際場景。在100K (TT100K)數(shù)據(jù)集上的大量實(shí)驗(yàn)結(jié)果表明,與幾種先進(jìn)方法相比,本文方法的有效性和優(yōu)越性得到了驗(yàn)證。
1 介紹
交通標(biāo)志識別系統(tǒng)是ITS和無人駕駛系統(tǒng)的重要組成部分。如何提高交通標(biāo)志檢測與識別技術(shù)的準(zhǔn)確性和實(shí)時性,是該技術(shù)走向?qū)嶋H應(yīng)用時需要解決的關(guān)鍵問題。近年來,大多數(shù)先進(jìn)的目標(biāo)檢測算法,如Faster R-CNN、R-FCN、SSD和YOLO,都使用了卷積神經(jīng)網(wǎng)絡(luò),并在目標(biāo)檢測任務(wù)中取得了豐碩的成果。然而,將這些方法簡單地應(yīng)用到交通標(biāo)志識別中很難取得滿意的效果。車載移動終端的目標(biāo)識別和檢測對不同尺度的目標(biāo)要求較高的精度,對識別速度要求較高,這意味著要滿足準(zhǔn)確性和實(shí)時性兩個要求。傳統(tǒng)的CNN通常需要大量的參數(shù)和浮點(diǎn)運(yùn)算(FLOPs)來達(dá)到令人滿意的精度,例如ResNet-50有大約25.6萬個參數(shù),需要41億個浮點(diǎn)運(yùn)算來處理224×224大小的圖像。然而,內(nèi)存和計(jì)算資源有限的移動設(shè)備(如智能手機(jī)和自動駕駛汽車)無法用于更大網(wǎng)絡(luò)的部署和推理。YOLOv5作為一種One-stage檢測器,具有計(jì)算量小、識別速度快等優(yōu)點(diǎn)。本文提出了一種改進(jìn)的YOLOv5網(wǎng)絡(luò),既保證模型尺寸滿足部署在車輛側(cè)的要求,又提高了多尺度目標(biāo)的能力,滿足實(shí)時性要求。工作的主要貢獻(xiàn)如下:
提出了一種新的特征金字塔網(wǎng)絡(luò)。通過自適應(yīng)特征融合和感受野增強(qiáng),在特征傳遞過程中很大程度上保留通道信息,并自適應(yīng)學(xué)習(xí)每個特征圖中的不同感受野,增強(qiáng)特征金字塔的表示,有效地提高了多尺度目標(biāo)識別的精度; 提出了一種新的自動學(xué)習(xí)數(shù)據(jù)增強(qiáng)策略。受AutoAugment的啟發(fā),添加了最新的數(shù)據(jù)增強(qiáng)操作。改進(jìn)的數(shù)據(jù)增強(qiáng)方法有效地提高了模型訓(xùn)練效果和訓(xùn)練模型的魯棒性,具有更大的現(xiàn)實(shí)意義; 與現(xiàn)有的YOLOv5網(wǎng)絡(luò)不同,對當(dāng)前版本進(jìn)行了改進(jìn),以減少尺度不變性的影響。同時,它可以部署在車輛的移動終端上,對交通標(biāo)志進(jìn)行實(shí)時檢測和識別。
2 相關(guān)工作
2.1 基于CNN的交通標(biāo)識檢測
目前,卷積神經(jīng)網(wǎng)絡(luò)在視覺目標(biāo)檢測方面取得了很大的成功。根據(jù)是否需要提出區(qū)域建議,基于深度學(xué)習(xí)的目標(biāo)檢測可分為兩類:單階段檢測和兩階段檢測。Shao等人提出了一種區(qū)域建議算法來簡化Gabor小波,提高Faster R-CNN用于交通標(biāo)志檢測。Zhang等人提出了一種改進(jìn)的基于YOLOv2的交通標(biāo)志檢測器,修改了經(jīng)典YOLOv2網(wǎng)絡(luò)的卷積層數(shù),使其適合中國交通標(biāo)志數(shù)據(jù)集。Li等人開發(fā)了一種新的感知生成對抗網(wǎng)絡(luò),該網(wǎng)絡(luò)通過生成小交通標(biāo)志的超分辨率表示來提高檢測性能。SADANet結(jié)合域自適應(yīng)網(wǎng)絡(luò)和多尺度預(yù)測網(wǎng)絡(luò)來解決尺度變化問題。上述網(wǎng)絡(luò)大多采用單尺度的深度特征,難以提高復(fù)雜場景下的檢測和識別性能。大型和小型交通標(biāo)志具有完全不同的視覺特征,因此規(guī)模變化問題是交通標(biāo)志檢測與識別中的一個難題。對于目標(biāo)檢測,學(xué)習(xí)尺度不變表示對于識別和定位目標(biāo)至關(guān)重要。目前的工作主要從兩個方面來解決這一挑戰(zhàn),即網(wǎng)絡(luò)架構(gòu)和數(shù)據(jù)擴(kuò)充。目前,多尺度特征被廣泛應(yīng)用于高層目標(biāo)識別中,以提高多尺度目標(biāo)的識別性能。特征金字塔網(wǎng)絡(luò)(Feature Pyramid Network, FPN)是一種常用的多層特征融合方法,利用其多尺度表達(dá)能力衍生出許多檢測精度較高的網(wǎng)絡(luò),如Mask R-CNN和RetinaNet。值得注意的是,由于功能通道的減少,特征圖會出現(xiàn)信息丟失,并且在其他level的特征圖中只包含一些不太相關(guān)的上下文信息。此外,使用FPN會導(dǎo)致網(wǎng)絡(luò)過分注重Low-level特征的優(yōu)化,有時會導(dǎo)致對大規(guī)模目標(biāo)的檢測精度降低。針對這一問題,提出了一種簡單而有效的方法,即感受野金字塔(RFP),以增強(qiáng)特征金字塔的表示能力,并驅(qū)動網(wǎng)絡(luò)學(xué)習(xí)最優(yōu)的特征融合模式。
2.2 數(shù)據(jù)增強(qiáng)
數(shù)據(jù)增強(qiáng)已被廣泛應(yīng)用于網(wǎng)絡(luò)優(yōu)化,并被證明有利于視覺任務(wù),可以提高CNN的性能,防止過擬合,且易于實(shí)現(xiàn)。數(shù)據(jù)增強(qiáng)方法大致可以分為顏色操作(如亮度、對比度和顏色投射)和幾何操作(如縮放、翻轉(zhuǎn)、平移和縮放)。這些增強(qiáng)操作通過數(shù)據(jù)扭曲或過采樣人為地擴(kuò)大了訓(xùn)練數(shù)據(jù)集的大小。Lv等人提出了五種針對人臉圖像的數(shù)據(jù)增強(qiáng)方法,包括landmark抖動和四種合成方法(發(fā)型、眼鏡、姿勢、照明)。Nair等人對訓(xùn)練數(shù)據(jù)應(yīng)用了兩種形式的數(shù)據(jù)增強(qiáng)。一種是隨機(jī)裁剪和水平反射,另一種是通過在顏色空間上應(yīng)用PCA來改變RGB通道的強(qiáng)度。這些常用的方法只是做簡單的轉(zhuǎn)換,不能滿足復(fù)雜情況的需求。Dwibedi等人通過cut-paste策略提高了檢測性能。此外,InstaBoost使用帶注釋的實(shí)例mask和位置概率圖來增強(qiáng)訓(xùn)練圖像。YOLOv4和Stitcher引入了包含重新縮放子圖像的Mosaic輸入,這也在YOLOv5中使用。然而,這些數(shù)據(jù)增強(qiáng)實(shí)現(xiàn)是手工設(shè)計(jì)的,最佳的增強(qiáng)策略是特定于數(shù)據(jù)集的。為了避免數(shù)據(jù)增強(qiáng)的數(shù)據(jù)特定性質(zhì),最近的工作集中在直接從數(shù)據(jù)本身學(xué)習(xí)數(shù)據(jù)增強(qiáng)策略。Tran等人使用貝葉斯方法根據(jù)從訓(xùn)練集中學(xué)習(xí)到的分布生成增廣數(shù)據(jù)。Cubuk等人提出了一種名為AutoAugment的數(shù)據(jù)增強(qiáng)新方法,用于自動搜索改進(jìn)的數(shù)據(jù)增強(qiáng)策略。
3 本文方法
3.1 Improved YOLOv5s架構(gòu)
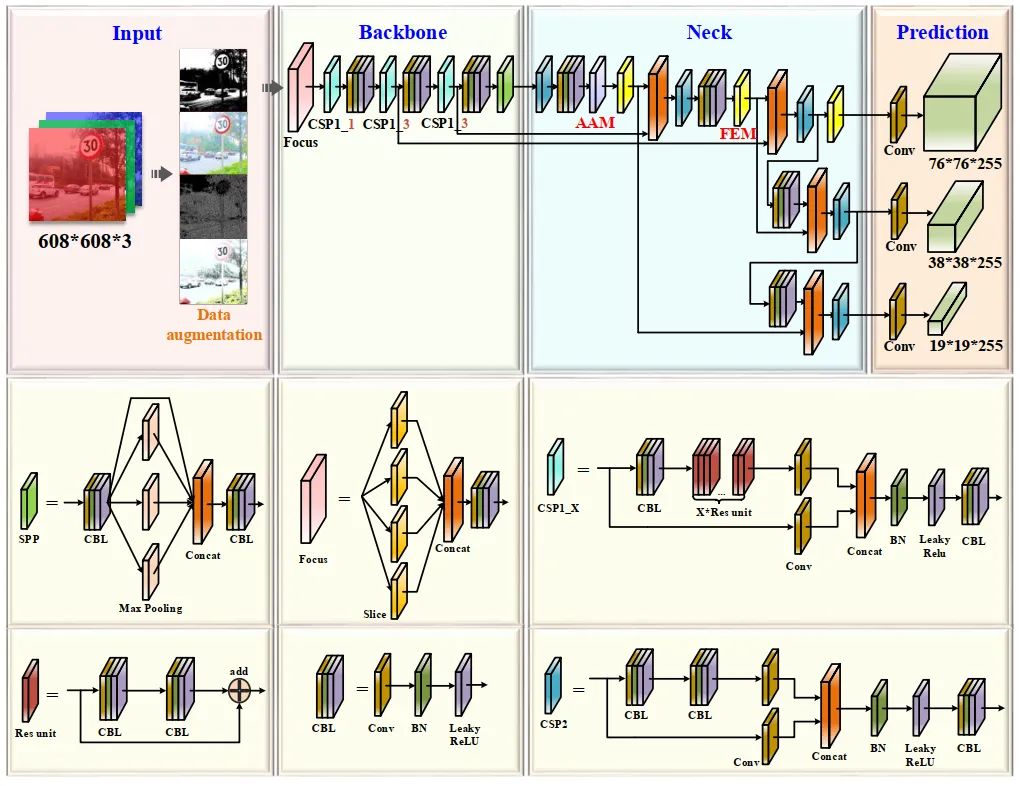
作為目前YOLO系列的最新版本,YOLOv5優(yōu)越的靈活性使得它可以方便地快速部署在車輛硬件側(cè)。YOLOv5包含YOLOv5s、YOLOv5m、YOLOv5l, YOLOv5x。YOLOv5s是YOLO系列中最小的版本,由于其內(nèi)存大小為14.10M,更適合部署在車載移動硬件平臺上,但其識別精度不能滿足準(zhǔn)確高效識別的要求,尤其是對小目標(biāo)的識別。YOLOv5的基本框架可以分為4個部分:Input、Backbone、Neck和Prediction。
Input部分通過拼接數(shù)據(jù)增強(qiáng)來豐富數(shù)據(jù)集,對硬件設(shè)備要求低,計(jì)算成本低。但是,這會導(dǎo)致數(shù)據(jù)集中原有的小目標(biāo)變小,導(dǎo)致模型的泛化性能下降。 Backbone部分主要由CSP模塊組成,通過CSPDarknet53進(jìn)行特征提取。 在Neck中使用FPN和路徑聚合網(wǎng)絡(luò)(PANet)來聚合該階段的圖像特征。 最后,網(wǎng)絡(luò)進(jìn)行目標(biāo)預(yù)測并通過預(yù)測輸出。
本文引入AF-FPN和自動學(xué)習(xí)數(shù)據(jù)增強(qiáng),解決模型大小與識別精度不兼容的問題,進(jìn)一步提高模型的識別性能。用AF-FPN代替原來的FPN結(jié)構(gòu),提高了多尺度目標(biāo)識別能力,在識別速度和精度之間進(jìn)行了有效的權(quán)衡。此外,去除原網(wǎng)絡(luò)中的Mosaic增強(qiáng),根據(jù)自動學(xué)習(xí)數(shù)據(jù)增強(qiáng)策略使用最佳的數(shù)據(jù)增強(qiáng)方法來豐富數(shù)據(jù)集,提高訓(xùn)練效果。改進(jìn)后的YOLOv5s網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示。
在預(yù)測中,使用Generalized IoU (GIoU) Loss作為BBox的損失函數(shù),使用加權(quán)的非最大抑制(NMS)方法NMS。損失函數(shù)如下:
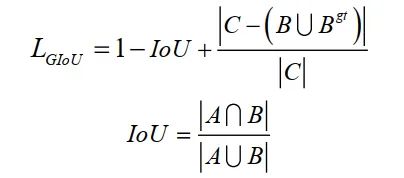
其中是覆蓋和的最小方框。為ground-truth box,為predicted box。但是,當(dāng)預(yù)測框在ground-truth 框內(nèi)且預(yù)測框大小相同時,預(yù)測框與ground-truth框的相對位置無法區(qū)分。本文用Complete IoU(CIoU) Loss代替GIoU Loss。CIoU損失在考慮GIoU損失的基礎(chǔ)上,考慮了BBox的重疊面積、中心點(diǎn)距離以及BBox長寬比的一致性。損失函數(shù)可以定義為:
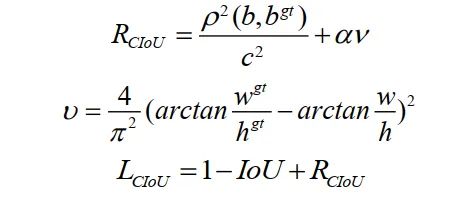
其中是懲罰項(xiàng),通過最小化兩個BBox中心點(diǎn)之間的歸一化距離來定義。和表示和的中心點(diǎn),為歐幾里得距離,c為覆蓋兩個方框的最小封閉方框的對角線長度。是一個正的權(quán)衡參數(shù),衡量縱橫比的一致性。權(quán)衡參數(shù)定義為:
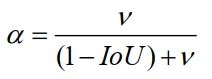
其中重疊面積因子在回歸中具有較高的優(yōu)先級,特別是在非重疊情況下。
3.2 架構(gòu)改進(jìn)
3.2.1 AF-FPN
AF-FPN在傳統(tǒng)特征金字塔網(wǎng)絡(luò)的基礎(chǔ)上,增加了自適應(yīng)注意力模塊(AAM)和特征增強(qiáng)模塊(FEM)。前者減少了特征通道,減少了高層特征圖中上下文信息的丟失。后一部分增強(qiáng)了特征金字塔的表示,提高了推理速度,同時實(shí)現(xiàn)了最先進(jìn)的性能。AF-FPN結(jié)構(gòu)如圖2所示。
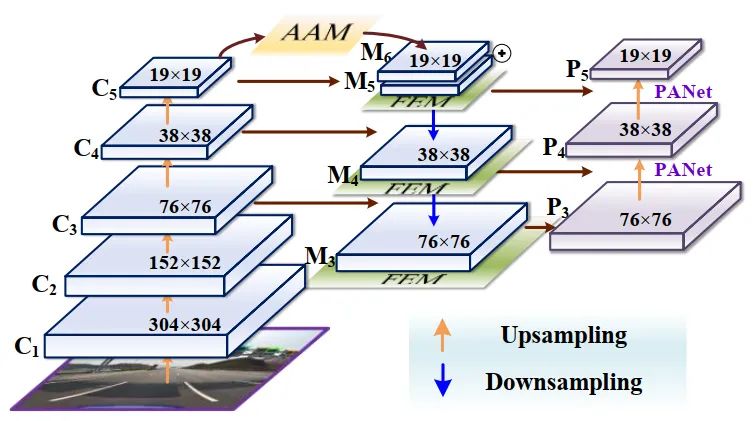
輸入圖像通過多個卷積生成特征映射{C1, C2, C3, C4, C5}。C5通過AAM生成特征映射M6。M6與M5求和并通過自上而下的途徑傳播與較低層次的其他特征融合,通過擴(kuò)展感受域每次融合后的有限元分析。PANet縮短了底層與頂層特征之間的信息路徑。自適應(yīng)注意模塊的操作可以分為2個步驟:
首先,通過自適應(yīng)平均池化層獲得不同尺度的多個上下文特征。池化系數(shù)為[0.1,0.5],根據(jù)數(shù)據(jù)集的目標(biāo)大小自適應(yīng)變化。
其次,通過空間注意力機(jī)制,為每個特征圖生成空間權(quán)值圖。通過權(quán)重圖融合上下文特征,生成包含多尺度上下文信息的新特征圖。
3.2.2 AAM
AAM的具體結(jié)構(gòu)如圖3所示。

作為自適應(yīng)注意力模塊的輸入,C5的大小為S=h×w,
首先通過自適應(yīng)池化層獲得不同尺度的語義特征。
然后,每個上下文特征進(jìn)行1×1卷積,以獲得相同的通道維數(shù)256。利用雙線性插值將它們上采樣到S尺度,進(jìn)行后續(xù)融合。空間注意力機(jī)制通過Concat層將3個上下文特征的通道進(jìn)行合并;
然后特征圖依次經(jīng)過1×1卷積層、ReLU激活層、3×3卷積層和sigmoid激活層,為每個特征圖生成相應(yīng)的空間權(quán)值。生成的權(quán)值映射和合并通道后的特征映射經(jīng)過Hadamard乘積操作,將其分離并添加到輸入特征映射M5中,將上下文特征聚合為M6。
最終得到的特征圖具有豐富的多尺度上下文信息,在一定程度上緩解了由于通道數(shù)量減少而造成的信息丟失。
3.2.3 FEM
FEM主要是根據(jù)檢測到的交通標(biāo)志尺度的不同,利用擴(kuò)張卷積自適應(yīng)地學(xué)習(xí)每個特征圖中的不同感受野,從而提高多尺度目標(biāo)檢測識別的準(zhǔn)確性。
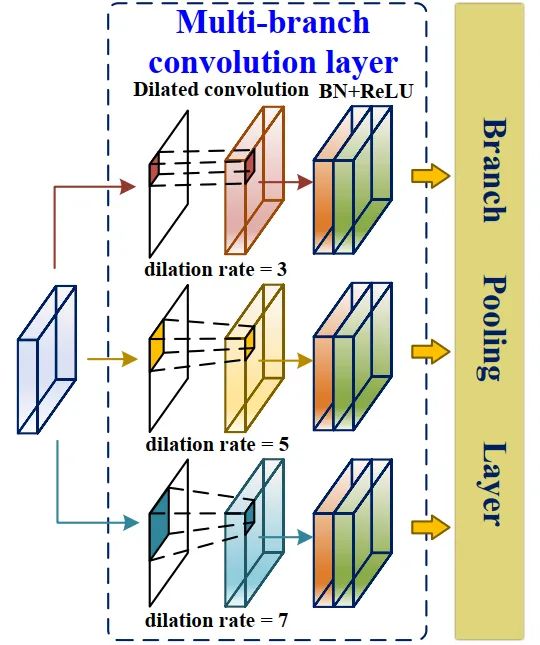
如圖4所示,它可以分為兩部分:
多分支卷積層 分支池化層
多分支卷積層通過擴(kuò)張卷積為輸入特征圖提供不同大小的感受野。利用平均池化層融合來自三個支路感受野的交通信息,提高多尺度精度預(yù)測。多分支卷積層包括擴(kuò)張卷積、BN層和ReLU激活層。三個平行分支中的擴(kuò)張卷積具有相同的內(nèi)核大小,但擴(kuò)張速率不同。具體來說,每個擴(kuò)張卷積的核為3×3,不同分支的擴(kuò)張速率d分別為1、3、5。擴(kuò)展卷積支持指數(shù)擴(kuò)展的感受野,而不損失分辨率。而在擴(kuò)張卷積的卷積運(yùn)算中,卷積核的元素是間隔的,空間的大小取決于膨脹率,這與標(biāo)準(zhǔn)卷積運(yùn)算中卷積核的元素都是相鄰的不同。卷積核由3×3更改為7×7,該層的感受野為7×7。擴(kuò)張卷積的感受野公式為:
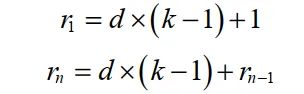
其中k和分別表示kernel-size和膨脹率。d表示卷積的stride。分支池化層用于融合來自不同并行分支的信息,避免引入額外參數(shù)。在訓(xùn)練過程中,利用平均操作來平衡不同平行分支的表示,使單個分支在測試過程中實(shí)現(xiàn)推理。表達(dá)式如下:

其中表示分支池化層的輸出。B表示并行分支的數(shù)量,這里設(shè)B = 3。
3.3 數(shù)據(jù)增強(qiáng)
擴(kuò)展策略由搜索空間和搜索算法兩部分組成。在搜索空間中,有S=5個子策略,每個子策略由兩個圖像操作組成,依次應(yīng)用。隨機(jī)選擇一個子策略并應(yīng)用于當(dāng)前圖像。此外,每個操作還與兩個超參數(shù)相關(guān):應(yīng)用操作的概率和操作的大小。在實(shí)驗(yàn)中使用的操作包括最新的數(shù)據(jù)增強(qiáng)方法,如Mosaic、SnapMix、Earsing、CutMix、Mixup和Translate X/Y。在搜索空間中總共有15個操作。每個操作也有一個默認(rèn)的幅度范圍。將幅度的范圍離散為D=11等間距值,以便可以使用離散搜索算法來找到它們。類似地,還將對P=10個值(均勻間距)進(jìn)行操作的概率離散化。在個可能性的空間中找到每個子策略成為一個搜索問題。因此,包含5個子策略的搜索空間大約有可能性,需要一個高效的搜索算法來導(dǎo)航該空間。圖5顯示了搜索空間中包含5個子策略的策略。

通過搜索空間,將搜索學(xué)習(xí)到的增廣策略問題轉(zhuǎn)化為離散優(yōu)化問題。采用強(qiáng)化學(xué)習(xí)作為搜索算法,它包含兩個部分:控制器RNN和訓(xùn)練算法。控制器RNN為遞歸神經(jīng)網(wǎng)絡(luò),訓(xùn)練算法為近端策略優(yōu)化(PPO),學(xué)習(xí)率為0.00035。控制器RNN在每一步預(yù)測softmax產(chǎn)生的決策,然后將預(yù)測作為搜索空間的嵌入,送入下一步。控制器總共有30個softmax預(yù)測來預(yù)測5個子策略,每個子策略有2個操作,每個操作需要操作類型、大小和概率。將自動學(xué)習(xí)數(shù)據(jù)增強(qiáng)方法應(yīng)用于TT100K數(shù)據(jù)集,然后使用通過訓(xùn)練獲得的最佳數(shù)據(jù)增強(qiáng)策略。
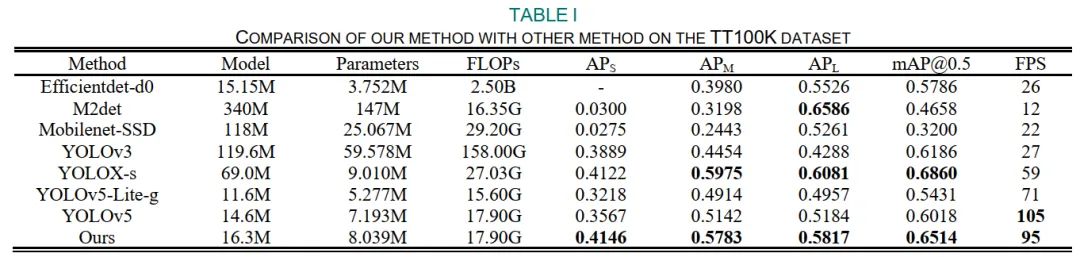
4 實(shí)驗(yàn)

5 參考
Improved YOLOv5 network for real-time multi-scale traffic sign detection
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“transformer”獲取最新Transformer綜述論文下載~

#?CV技術(shù)社群邀請函?#

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測-深圳)
即可申請加入極市目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實(shí)項(xiàng)目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與?10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
