
十篇文章速覽多模態(tài)語言生成的研究進(jìn)展

本文約3300字,建議閱讀10分鐘
本文整理了最近兩年在語言生成 (NLG) 任務(wù)上的多模態(tài)預(yù)訓(xùn)練模型上的進(jìn)展。
[ 引言 ]在最近幾年,憑借著強(qiáng)大的泛化能力,預(yù)訓(xùn)練模型在NLP,CV等領(lǐng)域都取得了顯著的效果。最近也有不少工作在嘗試多模態(tài)領(lǐng)域使用預(yù)訓(xùn)練模型。筆者整理了最近兩年在語言生成 (NLG) 任務(wù)上的多模態(tài)預(yù)訓(xùn)練模型上的進(jìn)展,這些論文在包括多模態(tài)機(jī)器翻譯 (MMT) 、圖片/視頻標(biāo)題生成 (Image/Video Caption)、文本摘要 (Abstractive Summarization)、問答生成 (QA/VQA) 等多種 NLG 任務(wù)取得了提升。歡迎大家批評(píng)指正,相互交流。
一、論文列表
1. UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
https://aclanthology.org/2021.acl-long.202/
該工作的主要亮點(diǎn)是通過單塔的Transformer模型來同時(shí)編碼文本和圖像數(shù)據(jù)。模型總共有三大類預(yù)訓(xùn)練任務(wù),除了比較常規(guī)的視覺單模態(tài)學(xué)習(xí)任務(wù)(mask區(qū)域恢復(fù)和region分類)以及文本單模態(tài)學(xué)習(xí)任務(wù)(MLM任務(wù)和seq2seq生成),該論文還提出了跨模態(tài)的對(duì)比學(xué)習(xí),通過對(duì)文本進(jìn)行詞級(jí)別、片段級(jí)別和句子級(jí)別重寫以及圖文檢索,產(chǎn)生各種粒度的圖文正負(fù)樣本進(jìn)行跨模態(tài)的對(duì)比學(xué)習(xí)。從而能夠更好地在同一個(gè)語義空間去學(xué)習(xí)這些單模態(tài)、多模態(tài)信息。模型結(jié)構(gòu)如下:
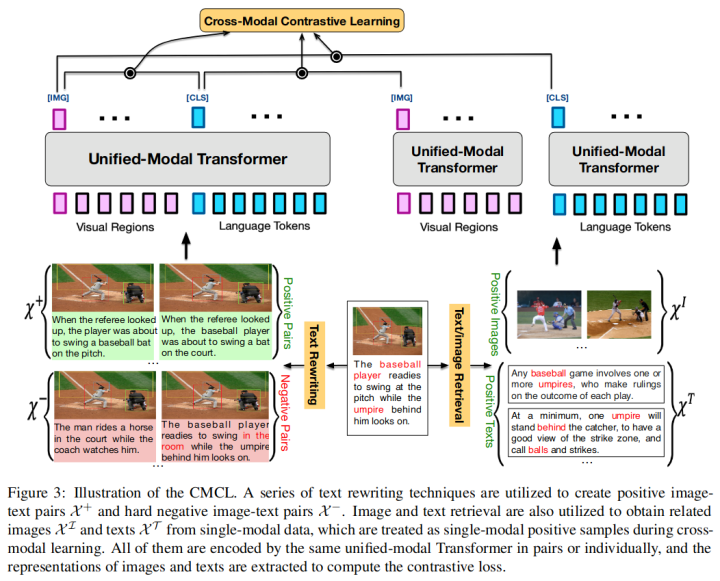
在下游的微調(diào)任務(wù)中,UNIMO在多項(xiàng)任務(wù)上都取得了提升,其中也包括VQA任務(wù)。
2. Enabling Multimodal Generation on CLIP via Vision-Language Knowledge Distillation
https://aclanthology.org/2022.findings-acl.187/
該工作之前的多模態(tài)預(yù)訓(xùn)練模型(如CLIP)在各種多模態(tài)對(duì)齊任務(wù)上取得了不錯(cuò)的效果,但由于其文本編碼器較弱,在文本生成任務(wù)上的表現(xiàn)不佳。為了解決這個(gè)問題,該工作提出將 CLIP 的多模態(tài)知識(shí)蒸餾到 BART 上,以獲得一個(gè)同時(shí)具有多模態(tài)知識(shí)和文本生成能力的模型。本文使用了三個(gè)目標(biāo)函數(shù)來實(shí)現(xiàn)多模態(tài)知識(shí)蒸餾:
ext-Text Distance Minimization (TTDM): 該損失函數(shù)是為了對(duì)齊BART的編碼器和CLIP的文本編碼器,拉近兩者的表示空間Image-Text Contrastive Learning (ITCL): 該損失函數(shù)是為了對(duì)齊BART的編碼器和CLIP的圖片編碼器。即在BART編碼的文本和CLIP編碼的圖片表示之間進(jìn)行跨模態(tài)的對(duì)比學(xué)習(xí);Image-Conditioned Text Infilling (ITCL): 上面兩個(gè)目標(biāo)只是將CLIP的多模態(tài)信息傳遞給了BART的編碼器。這個(gè)損失函數(shù)可以理解為同時(shí)給出文本和圖片編碼器表示的conditional text generation,使得BART的編碼器也能理解視覺表示。

本文也測試了經(jīng)過蒸餾的BART在Image Captioning, VQA以及Abstractive Summarization等任務(wù)上的表現(xiàn),取得了不錯(cuò)的效果。
3. A Non-hierarchical Attention Network with Modality Dropout for Textual Response Generation in Multimodal Dialogue Systems??
https://arxiv.org/abs/2110.09702
以往的的圖文多模態(tài)對(duì)話系統(tǒng)使用傳統(tǒng)的分層循環(huán)編碼器-解碼器(HRED)框架,這些舊模型仍具有兩個(gè)問題:
(1)文本特征和視覺特征之間的交互不夠精細(xì)。
(2) 上下文表示不夠完整。
這篇工作為多模態(tài)對(duì)話提出了一個(gè)具有多模態(tài)的、非層次化的自注意網(wǎng)絡(luò)模型,該模型具有類似Transformer的編碼器-解碼器結(jié)構(gòu)。編碼器部分主要有兩個(gè)部分,一部分是融合每句話以及對(duì)應(yīng)的圖片的表示,另一部分則是融合所有歷史對(duì)話表示,這兩個(gè)部分都使用自注意力機(jī)制來融合表示;解碼器結(jié)構(gòu)則和Transformer的解碼器結(jié)構(gòu)比較類似,使用編碼器的表示來生成回復(fù)。模型結(jié)構(gòu)如下所示:
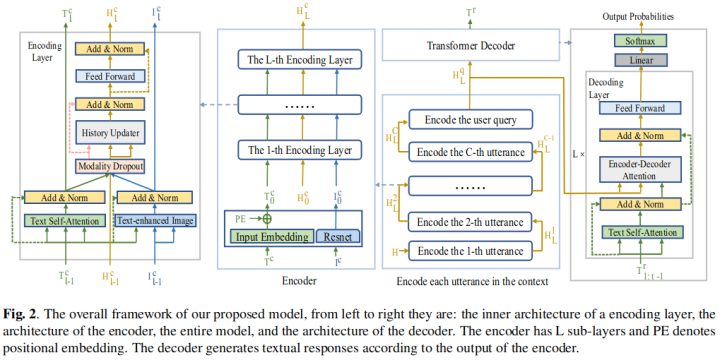
4. Modeling Text-visual Mutual Dependency for Multi-modal Dialog Generation
https://arxiv.org/abs/2110.09702
這項(xiàng)工作提出了一個(gè)多模態(tài)對(duì)話生成的一個(gè)框架,使得每個(gè)對(duì)話回合都與發(fā)生對(duì)話的視覺上下文相關(guān)聯(lián)。具體的說,該工作首先提出了普通的視覺模型來提取視覺特征并將其合并到序列到序列對(duì)話框生成中,其中每個(gè)模型在不同的級(jí)別提取視覺特征:從僅使用文本特征到使用粗粒度圖像級(jí)特征,再到細(xì)粒度對(duì)象級(jí)特征。
然后,發(fā)現(xiàn)模型學(xué)習(xí)到的文本特征和視覺特征的關(guān)聯(lián)程度仍然不高,該工作提出要對(duì)文本和視覺特征之間的相互依賴性進(jìn)行建模,即對(duì)話模型不僅需要了解在前面的對(duì)話話語和視覺上下文中生成下一個(gè)話語的概率,還需要建模在對(duì)話話語中預(yù)測視覺特征的后向概率,以引導(dǎo)模型生成特定于視覺上下文的對(duì)話語句。
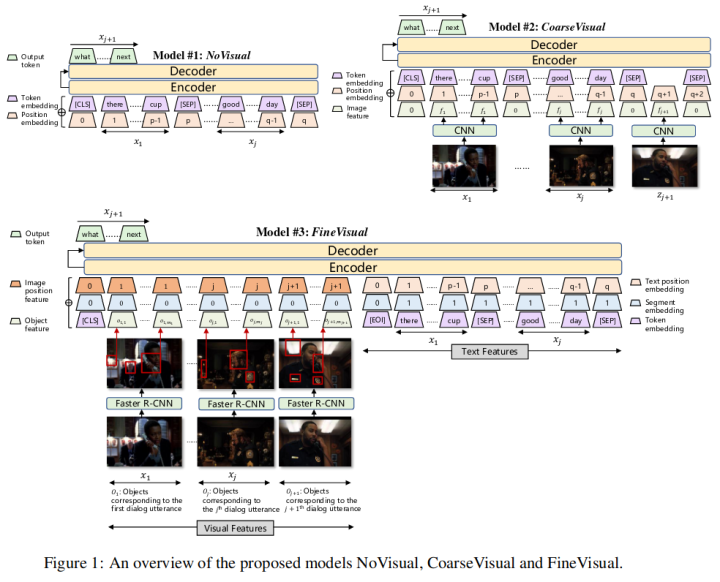
5. GIT: A Generative Image-to-text Transformer for Vision and Language
https://arxiv.org/abs/2205.14100
本文的主要亮點(diǎn)是設(shè)計(jì)并訓(xùn)練了一個(gè)生成式圖像到文本轉(zhuǎn)換器GIT,以統(tǒng)一圖像/視頻字幕和問答等視覺語言任務(wù)。雖然生成模型在預(yù)訓(xùn)練和微調(diào)之間提供了一致的網(wǎng)絡(luò)架構(gòu),但現(xiàn)有的工作通常包含復(fù)雜的結(jié)構(gòu)(單/多模態(tài)編碼器/解碼器),并且依賴于外部模塊,如對(duì)象檢測器/標(biāo)記器和光學(xué)字符識(shí)別(OCR)。
本文提出的模型僅包含兩個(gè)部分:一個(gè)圖像編碼器和一個(gè)文本解碼器。圖像編碼器部分是一個(gè)類似Swin的視覺Transformer,它基于對(duì)比學(xué)習(xí)任務(wù)在大量圖像-文本進(jìn)行預(yù)訓(xùn)練。而文本解碼器部分則采用了類似UniLM的方法,將視覺部分的編碼作為前綴,然后用Auto Regressive的方法來生成文本。盡管這個(gè)模型并不復(fù)雜,但在擴(kuò)大了預(yù)訓(xùn)練數(shù)據(jù)和模型大小后,該模型在Image Caption, VQA, Video Caption and Question Answering, Scene Text Recognition等多項(xiàng)任務(wù)上都取得了良好的性能。
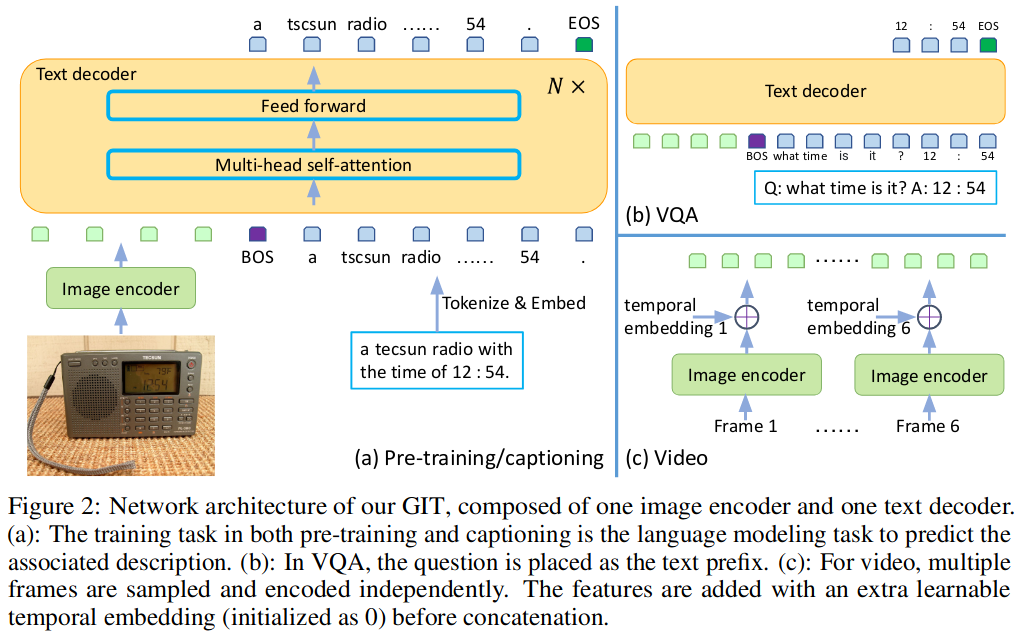
6. CoCa: Contrastive Captioners are Image-Text Foundation Models
https://arxiv.org/abs/2205.0191
這項(xiàng)工作主要亮點(diǎn)是設(shè)計(jì)了一個(gè)能同時(shí)包含圖文對(duì)比學(xué)習(xí)和標(biāo)題生成的多模態(tài)預(yù)訓(xùn)練模型。模型共分為三個(gè)部分:Image Encoder, Unimodal Text Decoder和Multimodal Text Decoder。模型首先將圖文分別輸入到Image Encoder和Unimodal Text Decoder,將兩者得到的表示進(jìn)行對(duì)比學(xué)習(xí),得到對(duì)比學(xué)習(xí)的損失;然后在將兩個(gè)表示輸入到Multimodal Text Decoder進(jìn)行Cross Attention,使用Auto Regressive的方法來生成輸入文本,得到文本生成的損失。該模型通過這樣的預(yù)訓(xùn)練方式來同時(shí)學(xué)習(xí)圖文對(duì)比和文本生成能力。模型圖如下所示:
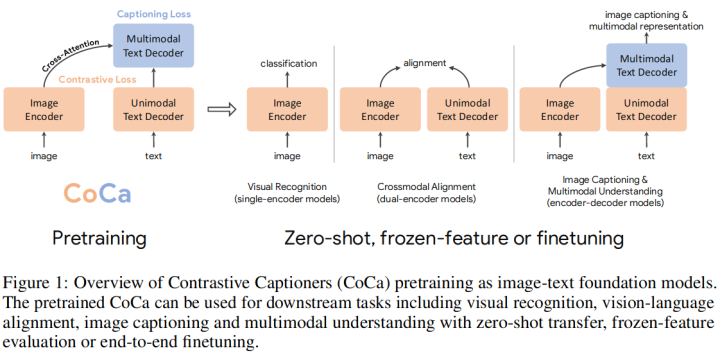
該模型在Image Caption, VQA等NLG任務(wù)上也取得了不錯(cuò)的效果。
7. DU-VLG: Unifying Vision-and-Language Generation via Dual Sequence-to-Sequence Pre-training
https://aclanthology.org/2022.findings-acl.201
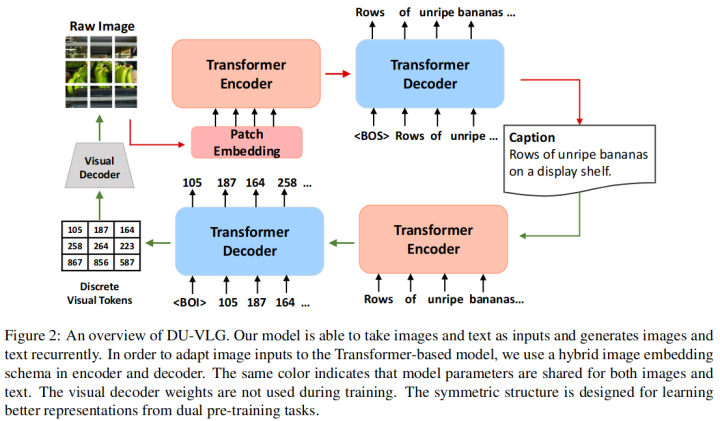
這項(xiàng)工作提出了一個(gè)具有視覺和語言生成雙序列到序列預(yù)訓(xùn)練的模型 DU-VLG (DUal sequence-to-sequence pre-training for Vision-and-Language Generation)。這個(gè)模型是Transformer的Encoder-Decoder結(jié)構(gòu),它可以文本(或圖像)為輸入,自回歸的生成對(duì)應(yīng)的圖像(或文本)。為了訓(xùn)練這個(gè)模型,該工作提出了兩個(gè)預(yù)訓(xùn)練任務(wù):Multi-modal Denoising Autoencoder Task 和 Modality Translation Task。
第一個(gè)預(yù)訓(xùn)練任務(wù)類似MLM,將帶有隨機(jī)屏蔽的圖像或單詞的圖文對(duì)作為輸入,并通過重建損壞的模態(tài)來學(xué)習(xí)圖像文本對(duì)齊。第二個(gè)任務(wù)則是跨模態(tài)的生成。通過這兩個(gè)任務(wù)來增強(qiáng)模型的語義對(duì)齊能力。此外,本文還提出了一種新的commitment loss來驅(qū)動(dòng)模型獲得更好的圖像表示。下游的微調(diào)任務(wù)表明該模型在Image Captioning, Visual Commonsense Reasoning等任務(wù)上均有提升。
8. Gumbel-Attention for Multi-modal Machine Translation
https://arxiv.org/abs/2103.08862
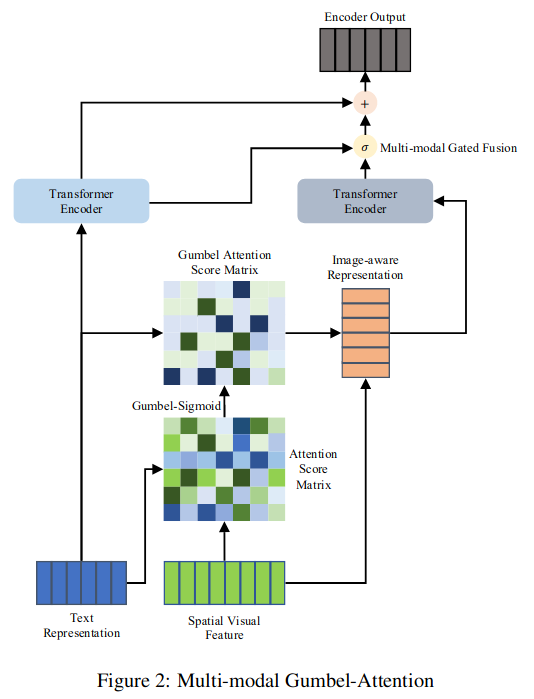
多模態(tài)機(jī)器翻譯(MMT)通過引入視覺信息來提高翻譯質(zhì)量。然而,現(xiàn)有的MMT模型忽略了圖像會(huì)帶來與文本無關(guān)的信息,對(duì)模型造成很大的噪聲,影響翻譯質(zhì)量的問題。該工作提出了一種新的用于多模態(tài)機(jī)器翻譯的Gumbel-Attention方法,它可以選擇圖像特征中與文本相關(guān)的部分。具體來說,與以往基于注意的方法不同,它首先使用可微方法來選擇圖像信息,并自動(dòng)去除圖像特征中無用的部分。
通過Gumbel-Attention得分矩陣和圖像特征,生成圖像感知的文本表示。然后使用多模態(tài)編碼器對(duì)文本表示和圖像感知文本表示進(jìn)行獨(dú)立編碼。最后,通過多模態(tài)門控融合得到編碼器的最終輸出。實(shí)驗(yàn)和案例分析表明,該方法保留了與文本相關(guān)的圖像特征,其余部分有助于MMT模型生成更好的翻譯。
9. M6: A Chinese Multimodal Pretrainer
https://arxiv.org/abs/2103.00823
這篇工作有兩個(gè)主要貢獻(xiàn),一是提供了一個(gè)大規(guī)模的中文多模態(tài)預(yù)訓(xùn)練數(shù)據(jù)集,而是提出了一個(gè)跨模態(tài)預(yù)訓(xùn)練模型M6。該模型使用Transformer Encoder,將圖片和文本編碼到同一個(gè)空間中。為了該模型能夠同時(shí)做理解和生成任務(wù),它也使用了UniLM里的mask方法。該模型共有三種預(yù)訓(xùn)練任務(wù):
Text-to-text Transfer:?這部分任務(wù)包含文本去噪和語言建模,主要是為了增強(qiáng)模型的文本理解和生成能力。Image-to-text transfer: 這部分任務(wù)則是生成圖片標(biāo)題描述,通過輸入的視覺信息來生成對(duì)應(yīng)的文本。Multimodality-to-text transfer: 這部分任務(wù)建立圖像到文本的基礎(chǔ)上,增加了隱藏的語言輸入。模型需要學(xué)習(xí)同時(shí)基于視覺信息和語言信息生成目標(biāo)文本。
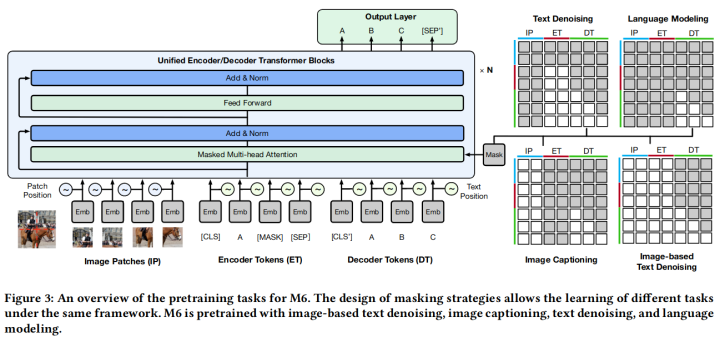
模型結(jié)構(gòu)圖如上所示。實(shí)驗(yàn)表明 M6 在VQA, Image Caption, Poem Generation等多項(xiàng)任務(wù)上都有提升。
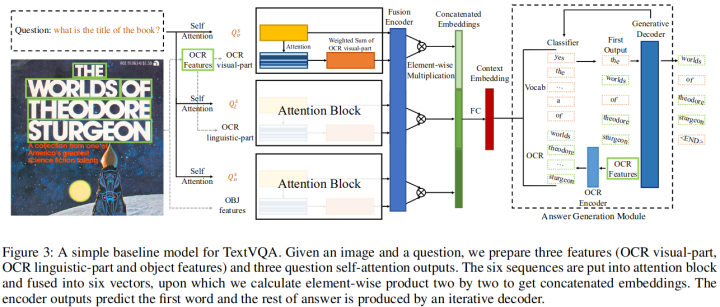
10. Simple is not Easy: A Simple Strong Baseline for TextVQA and TextCaps
https://ojs.aaai.org/index.php/AAAI/article/view/16476
OCR工具可以識(shí)別的日常場景中出現(xiàn)的文本包含重要信息,這對(duì)于TextVQA和TextCaps這兩個(gè)任務(wù)非常重要。以往的工作都使用了許多復(fù)雜的多模態(tài)編碼框架來融合與文字有關(guān)的特征。該工作僅使用了簡單的Attention機(jī)制來融合這些特征,它將文本特征分成兩個(gè)功能不同的部分,即語言部分和視覺部分,這兩個(gè)部分傳入相應(yīng)的Attention模塊。然后再將編碼后的特征傳給一個(gè)Decoder,以生成答案或字幕。
編輯:黃繼彥