
從5秒優(yōu)化到1秒,系統(tǒng)飛起來了...
往期熱門文章:
1、Java/Spring/Dubbo三種SPI機制,誰更好?
2、我用Java幾分鐘處理完30億個數(shù)據(jù)...
3、炸了!Java多線程批量操作,居然有人不做事務(wù)控制
前言
優(yōu)化背景和目標
通過壓縮讓耗時急劇減少
并行獲取數(shù)據(jù),響應(yīng)飛快
緩存分類,進一步加速
MySQL 索引的優(yōu)化
JVM 優(yōu)化
其他優(yōu)化
前言
性能優(yōu)化,有時候看起來是一個比較虛的技術(shù)需求。除非代碼慢的已經(jīng)讓人無法忍受,否則,很少有公司會有覺悟投入資源去做這些工作。
即使你有了性能指標數(shù)據(jù),也很難說服領(lǐng)導(dǎo)做一個由耗時 300ms 降低到 150ms 的改進,因為它沒有業(yè)務(wù)價值。
這很讓人傷心,但這是悲催的現(xiàn)實。
性能優(yōu)化,通常由有技術(shù)追求的人發(fā)起,根據(jù)觀測指標進行的正向優(yōu)化。他們通常具有工匠精神,對每一毫秒的耗時都吹毛求疵,力求完美。當然,前提是你得有時間。
優(yōu)化背景和目標
我們本次的性能優(yōu)化,就是由于達到了無法忍受的程度,才進行的優(yōu)化工作,屬于事后補救,問題驅(qū)動的方式。這通常沒什么問題,畢竟業(yè)務(wù)第一嘛,迭代在填坑中進行。
先說背景。本次要優(yōu)化的服務(wù),請求響應(yīng)時間十分的不穩(wěn)定。隨著數(shù)據(jù)量的增加,大部分請求,要耗時 5-6 秒左右!超出了常人能忍受的范圍。
當然需要優(yōu)化。
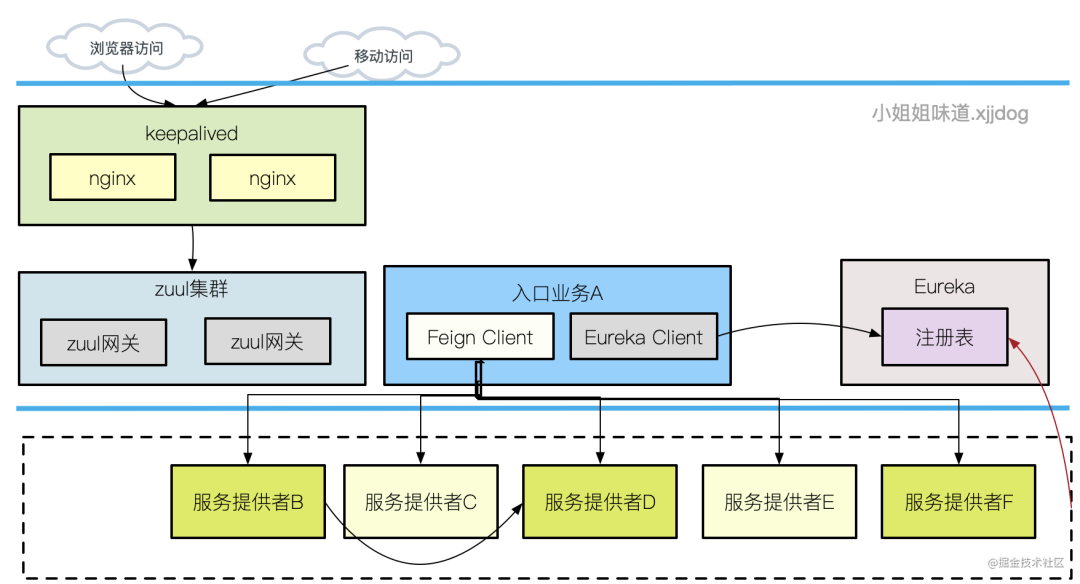
其中,我們優(yōu)化的目標,就處于一個比較靠上游的服務(wù)。它需要通過 Feign 接口,調(diào)用下游非常多的服務(wù)提供者,獲取數(shù)據(jù)后進行聚合拼接,最終通過 zuul 網(wǎng)關(guān)和 nginx,來發(fā)送到瀏覽器客戶端。

要進行優(yōu)化之前,我們需要首先看一下優(yōu)化需要參考的兩個技術(shù)指標:
吞吐量:單位時間內(nèi)發(fā)生的次數(shù)。比如 QPS、TPS、HPS 等。
平均響應(yīng)時間:每個請求的平均耗時。
平均響應(yīng)時間自然是越小越好,它越小,吞吐量越高。吞吐量的增加還可以合理利用多核,通過并行度增加單位時間內(nèi)的發(fā)生次數(shù)。
我們本次優(yōu)化的目標,就是減少某些接口的平均響應(yīng)時間,降低到 1 秒以內(nèi);增加吞吐量,也就是提高 QPS,讓單實例系統(tǒng)能夠承接更多的并發(fā)請求。
通過壓縮讓耗時急劇減少
我想要先介紹讓系統(tǒng)飛起來最重要的一個優(yōu)化手段:壓縮。
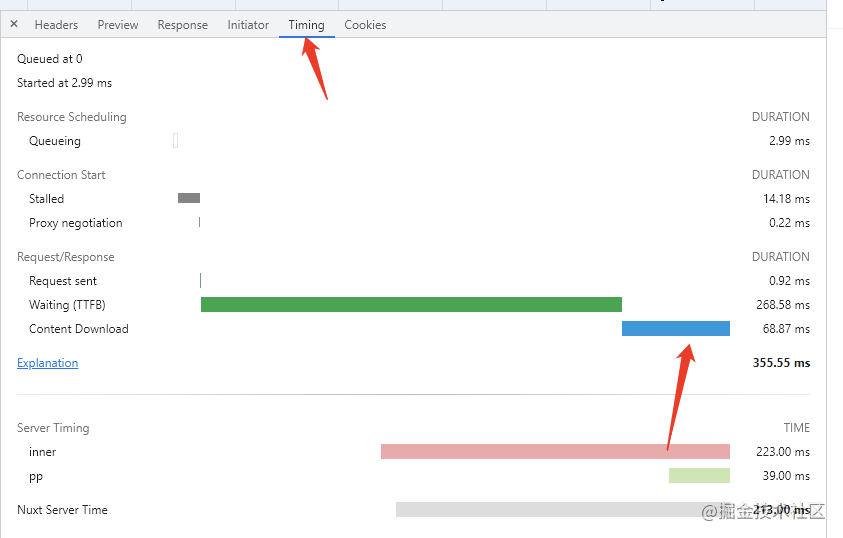
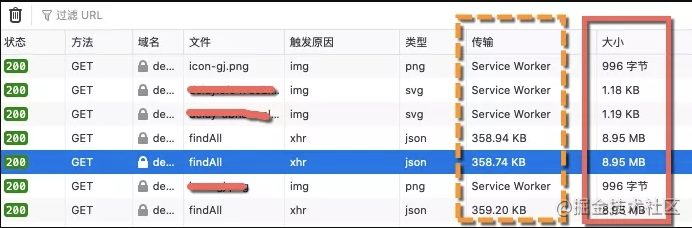
通過在 chrome 的 inspect 中查看請求的數(shù)據(jù),我們發(fā)現(xiàn)一個關(guān)鍵的請求接口,每次要傳輸大約 10MB 的數(shù)據(jù)。這得塞了多少東西。
這么大的數(shù)據(jù),光下載就需要耗費大量時間。如下圖所示,是我請求 juejin 主頁的某一個請求,其中的 content download,就代表了數(shù)據(jù)在網(wǎng)絡(luò)上的傳輸時間。如果用戶的帶寬非常慢,那么這個請求的耗時,將會是非常長的。
它的主要配置如下:
gzip?on;
gzip_vary?on;
gzip_min_length?10240;
gzip_proxied?expired?no-cache?no-store?private?auth;
gzip_types?text/plain?text/css?text/xml?text/javascript?application/x-javascript?application/xml;
gzip_disable?"MSIE?[1-6]\.";
但是等等,nginx 只是最外面的一環(huán),還沒完,我們還可以讓請求更快一些。
請看下面的請求路徑,由于采用了微服務(wù),請求的流轉(zhuǎn)就變得復(fù)雜起來:nginx 并不是直接調(diào)用了相關(guān)得服務(wù),它調(diào)用的是 zuul 網(wǎng)關(guān),zuul 網(wǎng)關(guān)才真正調(diào)用的目標服務(wù),目標服務(wù)又另外調(diào)用了其他服務(wù)。
nginx->zuul->服務(wù)A->服務(wù)E
要想 Feign 之間的調(diào)用全部都走壓縮通道,還需要額外的配置。我們是 springboot 服務(wù),可以通過 okhttp 的透明壓縮進行處理。
<dependency>
?<groupId>io.github.openfeigngroupId>
?<artifactId>feign-okhttpartifactId>
dependency>
server:
??port:8888
??compression:
????enabled:true
????min-response-size:1024
????mime-types:["text/html","text/xml","application/xml","application/json","application/octet-stream"]
開啟客戶端配置:
feign:
??httpclient:
????enabled:false
??okhttp:
????enabled:true
經(jīng)過這些壓縮之后,我們的接口平均響應(yīng)時間,直接從 5-6 秒降低到了 2-3 秒,優(yōu)化效果非常顯著。
當然,我們也在結(jié)果集上做了文章,在返回給前端的數(shù)據(jù)中,不被使用的對象和字段,都進行了精簡。
但一般情況下,這些改動都是傷筋動骨的,需要調(diào)整大量代碼,所以我們在這上面用的精力有限,效果自然也有限。
并行獲取數(shù)據(jù),響應(yīng)飛快
接下來,就要深入到代碼邏輯內(nèi)部進行分析了。上面我們提到,面向用戶的接口,其實是一個數(shù)據(jù)聚合接口。
它的每次請求,通過 Feign,調(diào)用了幾十個其他服務(wù)的接口,進行數(shù)據(jù)獲取,然后拼接結(jié)果集合。
為什么慢?因為這些請求全部是串行的!Feign 調(diào)用屬于遠程調(diào)用,也就是網(wǎng)絡(luò) I/O 密集型調(diào)用,多數(shù)時間都在等待,如果數(shù)據(jù)滿足的話,是非常適合并行調(diào)用的。
首先,我們需要分析這幾十個子接口的依賴關(guān)系,看一下它們是否具有嚴格的順序性要求。如果大多數(shù)沒有,那就再好不過了。
分析結(jié)果喜憂參半,這堆接口,按照調(diào)用邏輯,大體上可以分為 A,B 類。
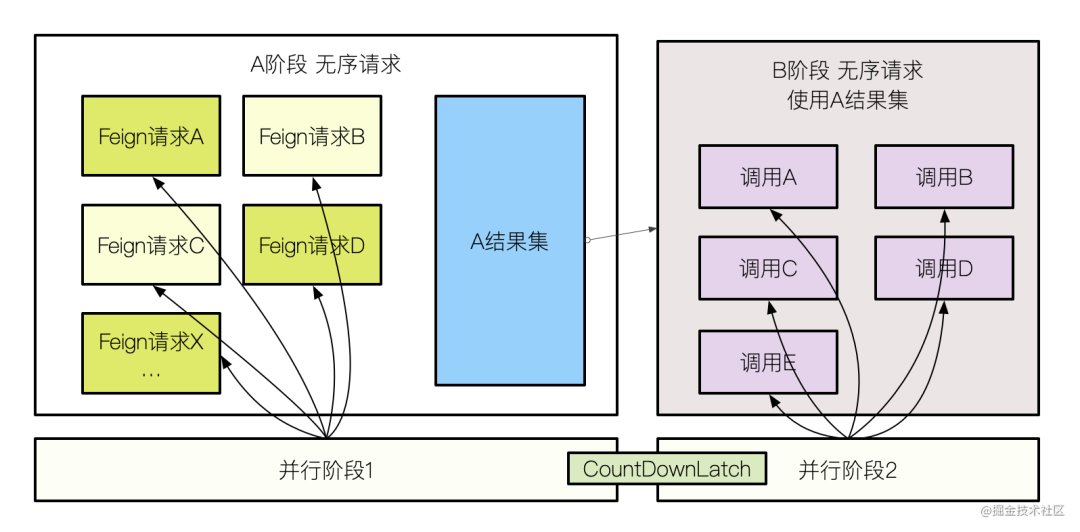
也就是說,我們可以把這個接口,拆分成順序執(zhí)行的兩部分,在某個部分都可以并行的獲取數(shù)據(jù)。
CountDownLatch?latch?=?new?CountDownLatch(jobSize);
//submit?job
executor.execute(()?->?{?
????//job?code
?latch.countDown();?
});?
executor.execute(()?->?{?
?latch.countDown();?
});?
...
//end?submit
latch.await(timeout,?TimeUnit.MILLISECONDS);?
結(jié)果非常讓人滿意,我們的接口耗時,又減少了接近一半!此時,接口耗時已經(jīng)降低到 2 秒以下。
final?ThreadPoolExecutor?executor?=?new?ThreadPoolExecutor(100,?200,?1,?
????????????TimeUnit.HOURS,?new?ArrayBlockingQueue<>(100));?
壓縮和并行化,是我們本次優(yōu)化中,最有效的手段。它們直接砍掉了請求大半部分的耗時,非常的有效。但我們還是不滿足,因為每次請求,依然有 1 秒鐘以上呢。
緩存分類,進一步加速
for(List){
????client.getData();
}
如果將這些常用的結(jié)果緩存起來,那么就可以大大減少網(wǎng)絡(luò) IO 請求的次數(shù),增加程序的運行效率。
緩存在大多數(shù)應(yīng)用程序的優(yōu)化中,作用非常大。但由于壓縮和并行效果的對比,緩存在我們這個場景中,效果不是非常的明顯,但依然減少了大約三四十毫秒的請求時間。
我們是這么做的。
首先,我們將一部分代碼邏輯簡單,適合 Cache Aside Pattern 模式的數(shù)據(jù),放在了分布式緩存 Redis 中。
具體來說,就是讀取的時候,先讀緩存,緩存讀不到的時候,再讀數(shù)據(jù)庫;更新的時候,先更新數(shù)據(jù)庫,再刪除緩存(延時雙刪)。
使用這種方式,能夠解決大部分業(yè)務(wù)邏輯簡單的緩存場景,并能解決數(shù)據(jù)的一致性問題。
但是,僅僅這么做是不夠的,因為有些業(yè)務(wù)邏輯非常的復(fù)雜,更新的代碼發(fā)非常的分散,不適合使用 Cache Aside Pattern 進行改造。
我們了解到,有部分數(shù)據(jù),具有以下特點:
這些數(shù)據(jù),通過耗時的獲取之后,在極端的時間內(nèi),會被再次用到
業(yè)務(wù)數(shù)據(jù)對它們的一致性要求,可以控制在秒級別以內(nèi)
對于這些數(shù)據(jù)的使用,跨代碼、跨線程,使用方式多樣
針對于這種情況,我們設(shè)計了存在時間極短的堆內(nèi)內(nèi)存緩存,數(shù)據(jù)在 1 秒之后,就會失效,然后重新從數(shù)據(jù)庫中讀取。加入某個節(jié)點調(diào)用服務(wù)端接口是 1 秒鐘 1k 次,我們直接給降低到了 1 次。
LoadingCache<String,?String>?lc?=?CacheBuilder
??????.newBuilder()
??????.expireAfterWrite(1,TimeUnit.SECONDS)
??????.build(new?CacheLoader<String,?String>()?{
??????@Override
??????public?String?load(String?key)?throws?Exception?{
????????????return?slowMethod(key);
}});
MySQL 索引的優(yōu)化
我們的業(yè)務(wù)系統(tǒng),使用的是 MySQL 數(shù)據(jù)庫,由于沒有專業(yè) DBA 介入,而且數(shù)據(jù)表是使用JPA生成的。在優(yōu)化的時候,發(fā)現(xiàn)了大量不合理的索引,當然是要優(yōu)化掉。
由于 SQL 具有很強的敏感性,我這里只談一些在優(yōu)化過程中碰到的索引優(yōu)化規(guī)則問題,相信你一樣能夠在自己的業(yè)務(wù)系統(tǒng)中進行類比。
索引非常有用,但是要注意,如果你對字段做了函數(shù)運算,那索引就用不上了。
常見的索引失效,還有下面兩種情況:
查詢的索引字段類型,與用戶傳遞的數(shù)據(jù)類型不同,要做一層隱式轉(zhuǎn)換。比如 varchar 類型的字段上,傳入了 int 參數(shù)
查詢的兩張表之間,使用的字符集不同,也就無法使用關(guān)聯(lián)字段作為索引
MySQL 的索引優(yōu)化,最基本的是遵循最左前綴原則,當有 a、b、c 三個字段的時候,如果查詢條件用到了 a,或者 a、b,或者 a、b、c,那么我們就可以創(chuàng)建(a,b,c)一個索引即可,它包含了 a 和 ab。當然,字符串也是可以加前綴索引的,但在平常應(yīng)用中較少。
有時候,MySQL 的優(yōu)化器,會選擇了錯誤的索引,我們需要使用 force index 指定所使用的索引。
在 JPA 中,就要使用 nativeQuery,來書寫綁定到 MySQL 數(shù)據(jù)庫的 SQL 語句,我們盡量的去避免這種情況。
另外一個優(yōu)化是減少回表。由于 InnoDB 采用了 B+ 樹,但是如果不使用非主鍵索引,會通過二級索引(secondary index)先查到聚簇索引(clustered index),然后再定位到數(shù)據(jù)。
多了一步,產(chǎn)生回表。使用覆蓋索引,可以一定程度上避免回表,是常用的優(yōu)化手段。
具體做法,就是把要查詢的字段,與索引放在一起做聯(lián)合索引,是一種空間換時間的做法。
JVM 優(yōu)化
我通常將 JVM 的優(yōu)化放在最后一環(huán)。而且,除非系統(tǒng)發(fā)生了嚴重的卡頓,或者 OOM 問題,都不會主動對其進行過度優(yōu)化。
很不幸的是,我們的應(yīng)用,由于開啟了大內(nèi)存(8GB+),在 JDK1.8 默認的并行收集器下,經(jīng)常發(fā)生卡頓。雖然不是很頻繁,但動輒幾秒鐘,已經(jīng)嚴重影響到部分請求的平滑性。
程序剛開始,是光禿禿跑在 JVM 下的,GC 信息,還有 OOM,什么都沒留下。為了記錄 GC 信息,我們做了如下的改造。
-XX:+HeapDumpOnOutOfMemoryError?-XX:HeapDumpPath=/opt/xxx.hprof??-DlogPath=/opt/logs/?-verbose:gc?-XX:+PrintGCDetails?-XX:+PrintGCDateStamps?-XX:+PrintGCApplicationStoppedTime?-XX:+PrintTenuringDistribution?-Xloggc:/opt/logs/gc_%p.log?-XX:ErrorFile=/opt/logs/hs_error_pid%p.log
這樣,我們就可以拿著生成的 GC 文件,上傳到 gceasy 等平臺進行分析。可以查看 JVM 的吞吐量和每個階段的延時等。
第二步,開啟 SpringBoot 的 GC 信息,接入 Promethus 監(jiān)控。
<dependency>
??<groupId>org.springframework.bootgroupId>
??<artifactId>spring-boot-starter-actuatorartifactId>
dependency>
management.endpoints.web.exposure.include=health,info,prometheus
在觀測了 JVM 的表現(xiàn)之后,我們切換成了 G1 垃圾回收器。G1 有最大停頓目標,可以讓我們的 GC 時間更加的平滑。
它主要有以下幾個調(diào)優(yōu)參數(shù):
-XX:MaxGCPauseMillis:設(shè)置目標停頓時間,G1 會盡力達成。
-XX:G1HeapRegionSize:設(shè)置小堆區(qū)大小。這個值為 2 的次冪,不要太大,也不要太小。如果是在不知道如何設(shè)置,保持默認。
-XX:InitiatingHeapOccupancyPercent:當整個堆內(nèi)存使用達到一定比例(默認是 45%),并發(fā)標記階段就會被啟動。
-XX:ConcGCThreads:并發(fā)垃圾收集器使用的線程數(shù)量。默認值隨 JVM 運行的平臺不同而不同。不建議修改。
切換成 G1 之后,這種不間斷的停頓,竟然神奇的消失了!期間,還發(fā)生過很多次內(nèi)存溢出的問題,不過有 MAT 這種神器的加持,最終都很 easy 的被解決了。
其他優(yōu)化
在工程結(jié)構(gòu)和架構(gòu)方面,如果有硬傷的話,那么代碼優(yōu)化方面,起到的作用其實是有限的,就比如我們這種情況。
但主要代碼還是要整一下容得。有些處于高耗時邏輯中的關(guān)鍵的代碼,我們對其進行了格外的關(guān)照。按照開發(fā)規(guī)范,對代碼進行了一次統(tǒng)一的清理。其中,有幾個印象比較深深刻的點。
map1.clear();
map2.clear();
map3.clear();
map4.clear();
public?void?clear()?{
????Node[]?tab;
????modCount++;
????if?((tab?=?table)?!=?null?&&?size?>?0)?{
????????size?=?0;
????????for?(int?i?=?0;?i?????????????tab[i]?=?null;
????}
}
public?int?size()?{
????????restartFromHead:?for?(;;)?{
????????????int?count?=?0;
????????????for?(Node?p?=?first();?p?!=?null;)?{
????????????????if?(p.item?!=?null)
????????????????????if?(++count?==?Integer.MAX_VALUE)
????????????????????????break;??//?@see?Collection.size()
????????????????if?(p?==?(p?=?p.next))
????????????????????continue?restartFromHead;
????????????}
????????????return?count;
????????}
}
另外,有些服務(wù)的 web 頁面,本身響應(yīng)就非常的慢,這是由于業(yè)務(wù)邏輯復(fù)雜,前端 JavaScript 本身就執(zhí)行緩慢。
總結(jié)
性能優(yōu)化,其實也是有套路的,但一般團隊都是等發(fā)生了問題才去優(yōu)化,鮮有未雨綢繆的。但有了監(jiān)控和 APM 就不一樣,我們能夠隨時拿到數(shù)據(jù),反向推動優(yōu)化過程。
有些性能問題,能夠在業(yè)務(wù)需求層面,或者架構(gòu)層面去解決。凡是已經(jīng)帶到代碼層,需要程序員介入的優(yōu)化,都已經(jīng)到了需求方和架構(gòu)方不能再亂動,或者不想再動的境地。
性能優(yōu)化首先要收集信息,找出瓶頸點,權(quán)衡 CPU、內(nèi)存、網(wǎng)絡(luò)、、IO 等資源,然后盡量的減少平均響應(yīng)時間,提高吞吐量。
緩存、緩沖、池化、減少鎖沖突、異步、并行、壓縮,都是常見的優(yōu)化方式。在我們的這個場景中,起到最大作用的,就是數(shù)據(jù)壓縮和并行請求。
往期熱門文章:
1、我用Java幾分鐘處理完30億個數(shù)據(jù)... 2、炸了!Java多線程批量操作,居然有人不做事務(wù)控制 3、巨坑,常見的 update 語句很容易造成Bug 4、完爆90%的數(shù)據(jù)庫性能毛病! 5、Spring Boot性能太差,教你幾招輕松搞定 6、Fastjson 2 來了,性能繼續(xù)提升,還能再戰(zhàn)十年 7、笑死!程序員延壽指南開源了 8、用 Dubbo 傳輸文件?被老板一頓揍! 9、45 個 Git 經(jīng)典操作場景,專治不會合代碼! 10、@Transactional 注解失效的3種原因及解決辦法