
(附鏈接)2021年小目標(biāo)檢測最新研究綜述
點擊左上方藍(lán)字關(guān)注我們

轉(zhuǎn)載自 | 極市平臺

文章鏈接:http://sjcj.nuaa.edu.cn/sjcjycl/article/html/202103001
摘要
小目標(biāo)檢測長期以來是計算機視覺中的一個難點和研究熱點。在深度學(xué)習(xí)的驅(qū)動下,小目標(biāo) 檢測已取得了重大突破,并成功應(yīng)用于國防安全、智能交通和工業(yè)自動化等領(lǐng)域。為了進(jìn)一步促進(jìn)小 目標(biāo)檢測的發(fā)展,本文對小目標(biāo)檢測算法進(jìn)行了全面的總結(jié),并對已有算法進(jìn)行了歸類、分析和比較。首先,對小目標(biāo)進(jìn)行了定義,并概述小目標(biāo)檢測所面臨的挑戰(zhàn)。然后,重點闡述從數(shù)據(jù)增強、多尺度學(xué)習(xí)、上下文學(xué)習(xí)、生成對抗學(xué)習(xí)以及無錨機制等方面來提升小目標(biāo)檢測性能的方法,并分析了這些方法的優(yōu)缺點和關(guān)聯(lián)性。之后,全面介紹小目標(biāo)數(shù)據(jù)集,并在一些常用的公共數(shù)據(jù)集上對已有算法進(jìn)行了 性能評估。最后本文對小目標(biāo)檢測技術(shù)的未來發(fā)展方向進(jìn)行了展望。
引言
目標(biāo)檢測是計算機視覺領(lǐng)域中的一個重要研究方向,也是其他復(fù)雜視覺任務(wù)的基礎(chǔ)。 作為圖像理解和計算機視覺的基石,目標(biāo)檢測是解決分割、場景理解、目標(biāo)跟蹤、圖像描述和事件檢測等更高層次 視覺任務(wù)的基礎(chǔ)。小目標(biāo)檢測長期以來是目標(biāo)檢測中的一個難點,其旨在精準(zhǔn)檢測出圖像中可視化特征極少的小目標(biāo)(32 像素×32 像素以下的目標(biāo))。在現(xiàn)實場景中,由于小目標(biāo)是的大量存在,因此小目 標(biāo)檢測具有廣泛的應(yīng)用前景,在自動駕駛、智慧醫(yī)療、缺陷檢測和航拍圖像分析等諸多領(lǐng)域發(fā)揮著重要 作用。
近年來,深度學(xué)習(xí)技術(shù)的快速發(fā)展為小目標(biāo)檢測注入了新鮮血液,使其成為研究熱點。然而,相 對于常規(guī)尺寸的目標(biāo),小目標(biāo)通常缺乏充足的外觀信息,因此難以將它們與背景或相似的目標(biāo)區(qū)分開來。在深度學(xué)習(xí)的驅(qū)動下,盡管目標(biāo)檢測算法已取得了重大突破,但是對于小目標(biāo)的檢測仍然是不盡人意的。在目標(biāo)檢測公共數(shù)據(jù)集 MS COCO[1]上,小目標(biāo)和大目標(biāo)在檢測性能上存在顯著差距,小目標(biāo)的檢測性能通常只有大目標(biāo)的一半。由此可見,小目標(biāo)檢測仍然是充滿挑戰(zhàn)的。此外,真實場景是錯 綜復(fù)雜的,通常會存在光照劇烈變化、目標(biāo)遮擋、目標(biāo)稠密相連和目標(biāo)尺度變化等問題,而這些因素對 小目標(biāo)特征的影響是更加劇烈的,進(jìn)一步加大了小目標(biāo)檢測的難度。
事實上,小目標(biāo)檢測具有重要的 研究意義和應(yīng)用價值。對于機場跑道,路面上會存在微小物體,如螺帽、螺釘、墊圈、釘子和保險絲等, 精準(zhǔn)地檢測出跑道的這些小異物將避免重大的航空事故和經(jīng)濟損失。對于自動駕駛,從汽車的高分辨 率場景照片中準(zhǔn)確地檢測出可能引起交通事故的小物體是非常有必要的。對于工業(yè)自動化,同樣需要小目標(biāo)檢測來定位材料表面可見的小缺陷。對于衛(wèi)星遙感圖像,圖像中的目標(biāo),例如車、船,可能只有 幾十甚至幾個像素。精確地檢測出衛(wèi)星遙感圖像中的微小目標(biāo)將有助于政府機構(gòu)遏制毒品和人口販 運,尋找非法漁船并執(zhí)行禁止非法轉(zhuǎn)運貨物的規(guī)定。綜上所述,小目標(biāo)檢測具有廣泛的應(yīng)用價值和重要的研究意義。
與以往將小目標(biāo)與常規(guī)目標(biāo)等同對待或只關(guān)注特定應(yīng)用場景下的目標(biāo)檢測綜述不同,本文對小目標(biāo)檢測這一不可或缺且極具挑戰(zhàn)性的研究領(lǐng)域進(jìn)行了系統(tǒng)且深入的分析與總結(jié)。 本文不僅對小目標(biāo) 的定義進(jìn)行了解釋,也對小目標(biāo)檢測領(lǐng)域存在的挑戰(zhàn)進(jìn)行了詳細(xì)地分析和總結(jié),同時重點闡述了小目 標(biāo)檢測優(yōu)化思路,包括數(shù)據(jù)增強、多尺度學(xué)習(xí)、上下文學(xué)習(xí)、生成對抗學(xué)習(xí)以及無錨機制以及其他優(yōu)化 策略等。此外,本文還在常用的小目標(biāo)數(shù)據(jù)集上分析對比了現(xiàn)有算法的檢測性能。最后,對本文內(nèi)容 進(jìn)行了簡要的總結(jié),并討論了小目標(biāo)檢測未來可能的研究方向和發(fā)展趨勢。
1 小目標(biāo)定義及難點分析
1.1 小目標(biāo)定義
不同場景對于小目標(biāo)的定義各不相同,目前尚未形成統(tǒng)一的標(biāo)準(zhǔn)。現(xiàn)有的小目標(biāo)定義方式主要分為以下兩類,即基于相對尺度的定義與基于絕對尺度的定義。
(1)基于相對尺度定義。 即從目標(biāo)與圖像的相對比例這一角度考慮來對小目標(biāo)進(jìn)行定義。Chen等[11]提出一個針對小目標(biāo)的數(shù)據(jù)集,并對小目標(biāo)做了如下定義:同一類別中所有目標(biāo)實例的相對面積,即邊界框面積與圖像面積之比的中位數(shù)在0.08%~0.58%之間。文中對小目標(biāo)的定義也給出了更具體的說法,如在640像素×480像素分辨率圖像中,16像素×16像素到42像素×42像素的目標(biāo)應(yīng)考慮為小目標(biāo)。除了Chen等對小目標(biāo)的定義方式以外,較為常見的還有以下幾種:(1)目標(biāo)邊界框的寬高與圖像的寬高比例小于一定值,較為通用的比例值為0.1;(2)目標(biāo)邊界框面積與圖像面積的比值開方小于一定值,較為通用的值為0.03;(3)根據(jù)目標(biāo)實際覆蓋像素與圖像總像素之間比例來對小目標(biāo)進(jìn)行定義。
但是,這些基于相對尺度的定義存在諸多問題,如這種定義方式難以有效評估模型對不同尺度目標(biāo)的檢測性能。此外,這種定義方式易受到數(shù)據(jù)預(yù)處理與模型結(jié)構(gòu)的影響。
(2)基于絕對尺度定義。 則從目標(biāo)絕對像素大小這一角度考慮來對小目標(biāo)進(jìn)行定義。目前最為通用的定義來自于目標(biāo)檢測領(lǐng)域的通用數(shù)據(jù)集——MS COCO數(shù)據(jù)集[1],將小目標(biāo)定義為分辨率小于32像素×32像素的目標(biāo)。對于為什么是32像素×32像素,本文從兩個方向進(jìn)行了思考。一種思路來自于Torralba等[12]的研究,人類在圖像上對于場景能有效識別需要的彩色圖像像素大小為32像素×32像素,即小于32像素×32像素的目標(biāo)人類都難以識別。另一種思路來源于深度學(xué)習(xí)中卷積神經(jīng)網(wǎng)絡(luò)本身的結(jié)構(gòu),以與MS COCO數(shù)據(jù)集第一部分同年發(fā)布的經(jīng)典網(wǎng)絡(luò)結(jié)構(gòu)VGG?Net[13]為例,從輸入圖像到全連接層的特征向量經(jīng)過了5個最大池化層,這導(dǎo)致最終特征向量上的“一點”對應(yīng)到輸入圖像上的像素大小為32像素×32像素。于是,從特征提取的難度不同這一角度考慮,可以將32像素×32像素作為區(qū)分小目標(biāo)與常規(guī)目標(biāo)的一個界定標(biāo)準(zhǔn)。除了MS COCO之外,還有其他基于絕對尺度的定義,如在航空圖像數(shù)據(jù)集DOTA[14]與人臉檢測數(shù)據(jù)集WIDER FACE[15]中都將像素值范圍在[10, 50]之間的目標(biāo)定義為小目標(biāo)。在行人識別數(shù)據(jù)集CityPersons[16]中,針對行人這一具有特殊比例的目標(biāo),將小目標(biāo)定義為了高度小于75像素的目標(biāo)。基于航空圖像的小行人數(shù)據(jù)集TinyPerson[17]則將小目標(biāo)定義為像素值范圍在[20, 32]之間的目標(biāo),而且近一步將像素值范圍在[2, 20]之間的目標(biāo)定義為微小目標(biāo)。
1.2 小目標(biāo)檢測面臨的挑戰(zhàn)
前文中已簡要闡述小目標(biāo)的主流定義,通過這些定義可以發(fā)現(xiàn)小目標(biāo)像素占比少,存在覆蓋面積小、包含信息少等基本特點。這些特點在以往綜述或論文中也多有提及,但是少有對小目標(biāo)檢測難點進(jìn)行分析與總結(jié)。接下來本文將試圖對造成小目標(biāo)檢測難度高的原因以及其面臨的挑戰(zhàn)進(jìn)行分析與總結(jié)。
(1) 可利用特征少
無論是從基于絕對尺度還是基于相對尺度的定義,小目標(biāo)相對于大/中尺度尺寸目標(biāo)都存在分辨率低的問題。低分辨率的小目標(biāo)可視化信息少,難以提取到具有鑒別力的特征,并且極易受到環(huán)境因素的干擾,進(jìn)而導(dǎo)致了檢測模型難以精準(zhǔn)定位和識別小目標(biāo)。
(2) 定位精度要求高
小目標(biāo)由于在圖像中覆蓋面積小,因此其邊界框的定位相對于大/中尺度尺寸目標(biāo)具有更大的挑戰(zhàn)性。在預(yù)測過程中,預(yù)測邊界框框偏移一個像素點,對小目標(biāo)的誤差影響遠(yuǎn)高于大/中尺度目標(biāo)。此外,現(xiàn)在基于錨框的檢測器依舊占據(jù)絕大多數(shù),在訓(xùn)練過程中,匹配小目標(biāo)的錨框數(shù)量遠(yuǎn)低于大/中尺度目標(biāo),如圖1所示,這進(jìn)一步地導(dǎo)致了檢測模型更側(cè)重于大/中尺度目標(biāo)的檢測,難以檢測小目標(biāo)。圖中IoU(Intersection over union)為交并比。

(3) 現(xiàn)有數(shù)據(jù)集中小目標(biāo)占比少
在目標(biāo)檢測領(lǐng)域中,現(xiàn)有數(shù)據(jù)集大多針對大/中尺度尺寸目標(biāo),較少關(guān)注小目標(biāo)這一特別的類型。MS COCO中雖然小目標(biāo)占比較高,達(dá)31.62%,但是每幅圖像包含的實例過多,小目標(biāo)分布并不均勻。同時,小目標(biāo)不易標(biāo)注,一方面來源于小目標(biāo)在圖像中不易被人類關(guān)注,很難標(biāo)全;另一方面是小目標(biāo)對于標(biāo)注誤差更為敏感。另外,現(xiàn)有的小目標(biāo)數(shù)據(jù)集往往針對特定場景,例如文獻(xiàn)[14]針對空中視野下的圖像、文獻(xiàn)[15]針對人臉、文獻(xiàn)[16?17]針對行人、文獻(xiàn)[18]針對交通燈、文獻(xiàn)[19]針對樂譜音符,使用這些數(shù)據(jù)集訓(xùn)練的網(wǎng)絡(luò)不適用于通用的小目標(biāo)檢測。總的來說,大規(guī)模的通用小目標(biāo)數(shù)據(jù)集尚處于缺乏狀態(tài),現(xiàn)有的算法沒有足夠的先驗信息進(jìn)行學(xué)習(xí),導(dǎo)致了小目標(biāo)檢測性能不足。
(4) 樣本不均衡問題
為了定位目標(biāo)在圖像中的位置,現(xiàn)有的方法大多是預(yù)先在圖像的每個位置生成一系列的錨框。在訓(xùn)練的過程中,通過設(shè)定固定的閾值來判斷錨框?qū)儆谡龢颖具€是負(fù)樣本。這種方式導(dǎo)致了模型訓(xùn)練過程中不同尺寸目標(biāo)的正樣本不均衡問題。當(dāng)人工設(shè)定的錨框與小目標(biāo)的真實邊界框差異較大時,小目標(biāo)的訓(xùn)練正樣本將遠(yuǎn)遠(yuǎn)小于大/中尺度目標(biāo)的正樣本,這將導(dǎo)致訓(xùn)練的模型更加關(guān)注大/中尺度目標(biāo)的檢測,而忽略小目標(biāo)的檢測。如何解決錨框機制導(dǎo)致的小目標(biāo)和大/中尺度目標(biāo)樣本不均衡問題也是當(dāng)前面臨的一大挑戰(zhàn)。
(5) 小目標(biāo)聚集問題
相對于大/中尺度目標(biāo),小目標(biāo)具有更大概率產(chǎn)生聚集現(xiàn)象。當(dāng)小目標(biāo)聚集出現(xiàn)時,聚集區(qū)域相鄰的小目標(biāo)通過多次降采樣后,反應(yīng)到深層特征圖上將聚合成一個點,導(dǎo)致檢測模型無法區(qū)分。當(dāng)同類小目標(biāo)密集出現(xiàn)時,預(yù)測的邊界框還可能會因后處理的非極大值抑制操作將大量正確預(yù)測的邊界框過濾,從而導(dǎo)致漏檢情況。另外,聚集區(qū)域的小目標(biāo)之間邊界框距離過近,還將導(dǎo)致邊界框難以回歸,模型難以收斂。
(6) 網(wǎng)絡(luò)結(jié)構(gòu)原因
在目標(biāo)檢測領(lǐng)域,現(xiàn)有算法的設(shè)計往往更為關(guān)注大/中尺度目標(biāo)的檢測性能。針對小目標(biāo)特性的優(yōu)化設(shè)計并不多,加之小目標(biāo)自身特性所帶來的難度,導(dǎo)致現(xiàn)有算法在小目標(biāo)檢測上普遍表現(xiàn)不佳。雖然無錨框的檢測器設(shè)計是一個新的發(fā)展趨勢,但是現(xiàn)有網(wǎng)絡(luò)依舊是基于錨框的檢測器占據(jù)主流,而錨框這一設(shè)計恰恰對小目標(biāo)極不友好。此外,在現(xiàn)有網(wǎng)絡(luò)的訓(xùn)練過程中,小目標(biāo)由于訓(xùn)練樣本占比少,對于損失函數(shù)的貢獻(xiàn)少,從而進(jìn)一步減弱了網(wǎng)絡(luò)對于小目標(biāo)的學(xué)習(xí)能力。
2 小目標(biāo)檢測研究思路
2.1 數(shù)據(jù)增強
數(shù)據(jù)增強是一種提升小目標(biāo)檢測性能的最簡單和有效的方法,通過不同的數(shù)據(jù)增強策略可以擴充訓(xùn)練數(shù)據(jù)集的規(guī)模,豐富數(shù)據(jù)集的多樣性,從而增強檢測模型的魯棒性和泛化能力。在相對早期的研究中,Yaeger等[20]通過使用扭曲變形、旋轉(zhuǎn)和縮放等數(shù)據(jù)增強方法顯著提升了手寫體識別的精度。之后,數(shù)據(jù)增強中又衍生出了彈性變形[21]、隨機裁剪[22]和平移[23]等策略。目前,這些數(shù)據(jù)增強策略已被廣泛應(yīng)用于目標(biāo)檢測中。
近些年來,基于深度學(xué)習(xí)的卷積神經(jīng)網(wǎng)絡(luò)在處理計算機視覺任務(wù)中獲得了巨大的成功。深度學(xué)習(xí)的成功很大程度上歸功于數(shù)據(jù)集的規(guī)模和質(zhì)量,大規(guī)模和高質(zhì)量的數(shù)據(jù)能夠大幅度提升模型的泛化能力。數(shù)據(jù)增強策略在目標(biāo)檢測領(lǐng)域有著廣泛應(yīng)用,例如Fast R?CNN[24]、Cascade R?CNN[25]中使用的水平翻轉(zhuǎn),YOLO[26]、YOLO9000[27]中使用的調(diào)整圖像曝光和飽和度,還有常被使用的CutOut[28]、MixUp[29]、CutMix[30]等方法。最近,更是有諸如馬賽克增強(YOLOv4[31])、保持增強[32]等創(chuàng)新策略提出,但是這些數(shù)據(jù)增強策略主要是針對常規(guī)目標(biāo)檢測。
聚焦到小目標(biāo)檢測領(lǐng)域,小目標(biāo)面臨著分辨率低、可提取特征少、樣本數(shù)量匱乏及分布不均勻等諸多挑戰(zhàn),數(shù)據(jù)增強的重要性愈發(fā)顯著。近些年來,出現(xiàn)了一些適用于小目標(biāo)的數(shù)據(jù)增強方法(表 1)。Yu等[17]在對數(shù)據(jù)的處理中,提出了尺度匹配策略,根據(jù)不同目標(biāo)尺寸進(jìn)行裁剪,縮小不同大小目標(biāo)之間的差距,從而避免常規(guī)縮放操作中小目標(biāo)信息易丟失的情形。Kisantal等[33]針對小目標(biāo)覆蓋的面積小、出現(xiàn)位置缺乏多樣性、檢測框與真值框之間的交并比遠(yuǎn)小于期望的閾值等問題,提出了一種復(fù)制增強的方法,通過在圖像中多次復(fù)制粘貼小目標(biāo)的方式來增加小目標(biāo)的訓(xùn)練樣本數(shù),從而提升了小目標(biāo)的檢測性能。在Kisantal等的基礎(chǔ)上,Chen等[34]在RRNet中提出了一種自適應(yīng)重采樣策略進(jìn)行數(shù)據(jù)增強,這種策略基于預(yù)訓(xùn)練的語義分割網(wǎng)絡(luò)對目標(biāo)圖像進(jìn)行考慮上下文信息的復(fù)制,以解決簡單復(fù)制過程中可能出現(xiàn)的背景不匹配和尺度不匹配問題,從而達(dá)到較好的數(shù)據(jù)增強效果。Chen等[35]則從小目標(biāo)數(shù)量占比小、自身包含信息少等問題出發(fā),在訓(xùn)練過程中對圖像進(jìn)行縮放與拼接,將數(shù)據(jù)集中的大尺寸目標(biāo)轉(zhuǎn)換為中等尺寸目標(biāo),中等尺寸目標(biāo)轉(zhuǎn)換為小尺寸目標(biāo),并在提高中/小尺寸目標(biāo)的數(shù)量與質(zhì)量的同時也兼顧考慮了計算成本。在針對小目標(biāo)的特性設(shè)計對應(yīng)的數(shù)據(jù)增強策略之外,Zoph等[36]超越了目標(biāo)特性限制,提出了一種通過自適應(yīng)學(xué)習(xí)方法例如強化學(xué)習(xí)選擇最佳的數(shù)據(jù)增強策略,在小目標(biāo)檢測上獲得了一定的性能提升。

數(shù)據(jù)增強這一策略雖然在一定程度上解決了小目標(biāo)信息量少、缺乏外貌特征和紋理等問題,有效提高了網(wǎng)絡(luò)的泛化能力,在最終檢測性能上獲得了較好的效果,但同時帶來了計算成本的增加。而且在實際應(yīng)用中,往往需要針對目標(biāo)特性做出優(yōu)化,設(shè)計不當(dāng)?shù)臄?shù)據(jù)增強策略可能會引入新的噪聲,損害特征提取的性能,這也給算法的設(shè)計帶來了挑戰(zhàn)。
2.2 多尺度學(xué)習(xí)
小目標(biāo)與常規(guī)目標(biāo)相比可利用的像素較少,難以提取到較好的特征,而且隨著網(wǎng)絡(luò)層數(shù)的增加,小目標(biāo)的特征信息與位置信息也逐漸丟失,難以被網(wǎng)絡(luò)檢測。這些特性導(dǎo)致小目標(biāo)同時需要深層語義信息與淺層表征信息,而多尺度學(xué)習(xí)將這兩種相結(jié)合,是一種提升小目標(biāo)檢測性能的有效策略。
早期的多尺度檢測有兩個思路。一種是使用不同大小的卷積核通過不同的感受野大小來獲取不同尺度的信息,但這種方法計算成本很高,而且感受野的尺度范圍有限,Simonyan和Zisserman[13]提出使用多個小卷積核代替大卷積核具備巨大優(yōu)勢后,使用不同大小卷積核的方法逐漸被棄用。之后,Yu等[37]提出的空洞卷積和Dai等[38]提出的可變卷積又為這種通過不同感受野大小獲取不同尺度信息的方法開拓了新的思路。另一種來自于圖像處理領(lǐng)域的思路——圖像金字塔[39],通過輸入不同尺度的圖像,對不同尺度大小的目標(biāo)進(jìn)行檢測,這種方法在早期的目標(biāo)檢測中有所應(yīng)用[40?41](見圖2(a))。但是,基于圖像金字塔訓(xùn)練卷積神經(jīng)網(wǎng)絡(luò)模型對計算機算力和內(nèi)存都有極高的要求。近些年來,圖像金字塔在實際研究應(yīng)用中較少被使用,僅有文獻(xiàn)[42?43]等方法針對數(shù)據(jù)集目標(biāo)尺度差異過大等問題而使用。
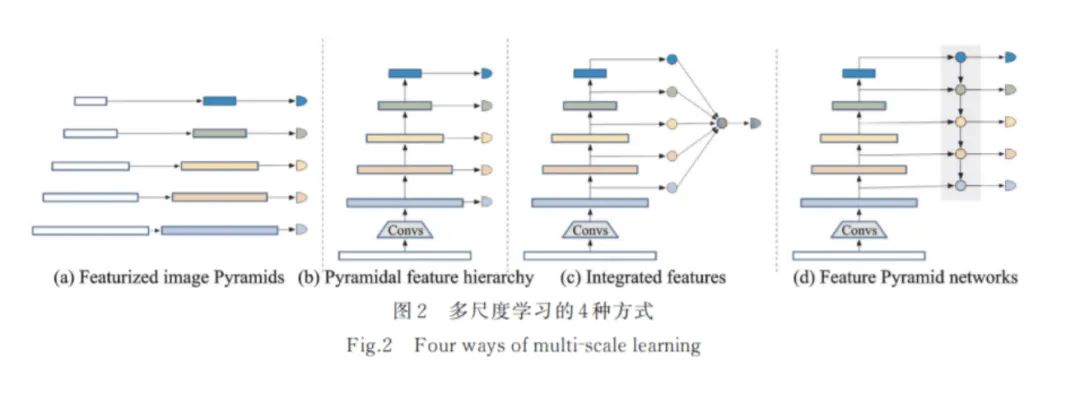
目標(biāo)檢測中的經(jīng)典網(wǎng)絡(luò)如Fast R?CNN[24]、Faster R?CNN[44]、SPPNet[45]和R?FCN[46]等大多只是利用了深度神經(jīng)網(wǎng)絡(luò)的最后層來進(jìn)行預(yù)測。然而,由于空間和細(xì)節(jié)特征信息的丟失,難以在深層特征圖中檢測小目標(biāo)。在深度神經(jīng)網(wǎng)絡(luò)中,淺層的感受野更小,語義信息弱,上下文信息缺乏,但是可以獲得更多空間和細(xì)節(jié)特征信息。從這一思路出發(fā),Liu等[47]提出一種多尺度目標(biāo)檢測算法SSD(Single shot multibox detector),利用較淺層的特征圖來檢測較小的目標(biāo),而利用較深層的特征圖來檢測較大的目標(biāo),如圖2(b)所示。Cai等[48]針對小目標(biāo)信息少,難以匹配常規(guī)網(wǎng)絡(luò)的問題,提出統(tǒng)一多尺度深度卷積神經(jīng)網(wǎng)絡(luò),通過使用反卷積層來提高特征圖的分辨率,在減少內(nèi)存和計算成本的同時顯著提升了小目標(biāo)的檢測性能。
針對小目標(biāo)易受環(huán)境干擾問題,Bell等[49]為提出了ION(Inside?outside network)目標(biāo)檢測方法,通過從不同尺度特征圖中裁剪出同一感興趣區(qū)域的特征,然后綜合這些多尺特征來預(yù)測,以達(dá)到提升檢測性能的目的。與ION的思想相似,Kong等[50]提出了一種有效的多尺度融合網(wǎng)絡(luò),即HyperNet,通過綜合淺層的高分辨率特征和深層的語義特征以及中間層特征的信息顯著提高了召回率,進(jìn)而提高了小目標(biāo)檢測的性能(見圖2(c))。這些方法能有效利用不同尺度的信息,是提升小目標(biāo)特征表達(dá)的一種有效手段。但是,不同尺度之間存在大量重復(fù)計算,對于內(nèi)存和計算成本的開銷較大。
為節(jié)省計算資源并獲得更好的特征融合效果,Lin等[51]結(jié)合單一特征映射、金字塔特征層次和綜合特征的優(yōu)點,提出了特征金字塔FPN(Feature Pyramid network)。FPN是目前最流行的多尺度網(wǎng)絡(luò),它引入了一種自底向上、自頂向下的網(wǎng)絡(luò)結(jié)構(gòu),通過將相鄰層的特征融合以達(dá)到特征增強的目的(見圖2(d))。在FPN的基礎(chǔ)上,Liang等[52]提出了一種深度特征金字塔網(wǎng)絡(luò),使用具有橫向連接的特征金字塔結(jié)構(gòu)加強小目標(biāo)的語義特征,并輔以特別設(shè)計的錨框和損失函數(shù)訓(xùn)練網(wǎng)絡(luò)。為了提高小目標(biāo)的檢測速度,Cao等[53]提出一種多層次特征融合算法,即特征融合SSD,在SSD的基礎(chǔ)上引入上下文信息,較好地平衡了小目標(biāo)檢測的速度與精度。但是基于SSD的特征金字塔方法需要從網(wǎng)絡(luò)的不同層中抽取不同尺度的特征圖進(jìn)行預(yù)測,難以充分融合不同尺度的特征。針對這一問題,Li和Zhou[54]提出一種特征融合單次多箱探測器,使用一個輕量級的特征融合模塊,聯(lián)系并融合各層特征到一個較大的尺度,然后在得到的特征圖上構(gòu)造特征金字塔用于檢測,在犧牲較少速度的情形下提高了對小目標(biāo)的檢測性能。針對機場視頻監(jiān)控中的小目標(biāo)識別準(zhǔn)確率較低的問題,韓松臣等[55]提出了一種結(jié)合多尺度特征融合與在線難例挖掘的機場路面小目標(biāo)檢測方法,該方法采用ResNet?101作為特征提取網(wǎng)絡(luò),并在該網(wǎng)絡(luò)基礎(chǔ)上建立了一個帶有上采樣的“自頂向下”的特征融合模塊,以生成語義信息更加豐富的高分辨率特征圖。
最近,多尺度特征融合這一方法又有了新的拓展,如Nayan等[56]針對小目標(biāo)經(jīng)過多層網(wǎng)絡(luò)特征信息易丟失這一問題,提出了一種新的實時檢測算法,該算法使用上采樣和跳躍連接在訓(xùn)練過程中提取不同網(wǎng)絡(luò)深度的多尺度特征,顯著提高了小目標(biāo)檢測的檢測精度與速度。Liu等[57]為了降低高分辨率圖像的計算成本,提出了一種高分辨率檢測網(wǎng)絡(luò),通過使用淺層網(wǎng)絡(luò)處理高分辨率圖像和深層網(wǎng)絡(luò)處理低分辨率圖像,在保留小目標(biāo)盡可能多的位置信息同時提取了更多的語義信息,在降低計算成本的情形下提升了小目標(biāo)的檢測性能。Deng等[58]發(fā)現(xiàn)雖然多尺度融合可以有效提升小目標(biāo)檢測性能,但是不同尺度的特征耦合仍然會影響性能,于是提出了一種擴展特征金字塔網(wǎng)絡(luò),使用額外的高分辨率金字塔級專門用于小目標(biāo)檢測。
總體來說,多尺度特征融合同時考慮了淺層的表征信息和深層的語義信息,有利于小目標(biāo)的特征提取,能夠有效地提升小目標(biāo)檢測性能。然而,現(xiàn)有多尺度學(xué)習(xí)方法在提高檢測性能的同時也增加了額外的計算量,并且在特征融合過程中難以避免干擾噪聲的影響,這些問題導(dǎo)致了基于多尺度學(xué)習(xí)的小目標(biāo)檢測性能難以得到進(jìn)一步提升。
2.3 上下文學(xué)習(xí)
在真實世界中,“目標(biāo)與場景”和“目標(biāo)與目標(biāo)”之間通常存在一種共存關(guān)系,通過利用這種關(guān)系將有助于提升小目標(biāo)的檢測性能。在深度學(xué)習(xí)之前,已有研究[59]證明通過對上下文進(jìn)行適當(dāng)?shù)慕?梢蕴嵘繕?biāo)檢測性能,尤其是對于小目標(biāo)這種外觀特征不明顯的目標(biāo)。隨著深度神經(jīng)網(wǎng)絡(luò)的廣泛應(yīng)用,一些研究也試圖將目標(biāo)周圍的上下文集成到深度神經(jīng)網(wǎng)絡(luò)中,并取得了一定的成效。以下將從基于隱式上下文特征學(xué)習(xí)和基于顯式上下文推理的目標(biāo)檢測兩個方面對國內(nèi)外研究現(xiàn)狀及發(fā)展動態(tài)進(jìn)行簡要綜述。
(1)基于隱式上下文特征學(xué)習(xí)的目標(biāo)檢測。 隱式上下文特征是指目標(biāo)區(qū)域周圍的背景特征或者全局的場景特征。事實上,卷積神經(jīng)網(wǎng)絡(luò)中的卷積操作在一定程度上已經(jīng)考慮了目標(biāo)區(qū)域周圍的隱式上下文特征。為了利用目標(biāo)周圍的上下文特征,Li等[60]提出一種基于多尺度上下文特征增強的目標(biāo)檢測方法,該方法首先在圖像中生成一系列的目標(biāo)候選區(qū)域,然后在目標(biāo)周圍生成不同尺度的上下文窗口,最后利用這些窗口中的特征來增強目標(biāo)的特征表示(見圖3(a))。隨后,Zeng等[61]提出一種門控雙向卷積神經(jīng)網(wǎng)絡(luò),該網(wǎng)絡(luò)同樣在目標(biāo)候選區(qū)域的基礎(chǔ)上生成包含不同尺度上下文的支撐區(qū)域,不同之處在于該網(wǎng)絡(luò)讓不同尺度和分辨率的信息在生成的支撐區(qū)域之間相互傳遞,從而綜合學(xué)習(xí)到最優(yōu)的特征。為了更好地檢測復(fù)雜環(huán)境下的微小人臉,Tang等[62]提出一種基于上下文的單階段人臉檢測方法,該方法設(shè)計了一種新的上下文錨框,在提取人臉特征的同時考慮了其周圍的上下文信息,例如頭部信息和身體信息。鄭晨斌等[63]提出一種強化上下文模型網(wǎng)絡(luò),該網(wǎng)絡(luò)利用雙空洞卷積結(jié)構(gòu)來節(jié)省參數(shù)量的同時,通過擴大有效感受野來強化淺層上下文信息,并在較少破壞原始目標(biāo)檢測網(wǎng)絡(luò)的基礎(chǔ)上靈活作用于網(wǎng)絡(luò)中淺預(yù)測層。然而,這些方法大多依賴于上下文窗口的設(shè)計或受限于感受野的大小,可能會導(dǎo)致重要上下文信息的丟失。
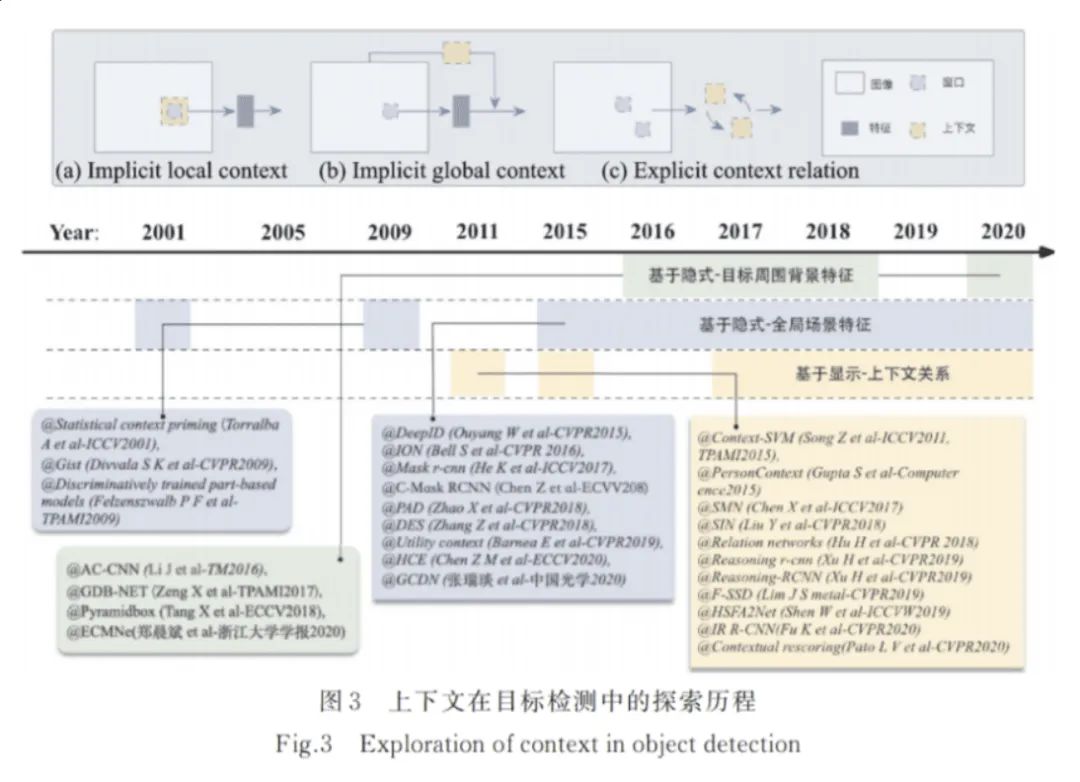
為了更加充分地利用上下文信息,一些方法嘗試將全局的上下文信息融入到目標(biāo)檢測模型中(見 圖3(b))。對于早期的目標(biāo)檢測算法,一種常用的集成全局上下文方法是通過構(gòu)成場景元素的統(tǒng)計匯總,例如Gist[64]。Torralba等[65]提出通過計算全局場景的低級特征和目標(biāo)的特征描述符的統(tǒng)計相關(guān)性來對視覺上下文建模。隨后,F(xiàn)elzenszwalb等[66]提出一種基于混合多尺度可變形部件模型的目標(biāo)檢測方法。該方法通過引入上下文來對檢測結(jié)果進(jìn)行二次評分,從而進(jìn)一步提升檢測結(jié)果的可靠性。對于目前的基于深度學(xué)習(xí)的目標(biāo)檢測算法,主要通過較大的感受野、卷積特征的全局池化或把全局上下文看作一種序列信息3種方式來感知全局上下文。Bell等[49]提出基于循環(huán)神經(jīng)網(wǎng)絡(luò)的上下文傳遞方法,該方法利用循環(huán)神經(jīng)網(wǎng)絡(luò)從4個方向?qū)φ麄€圖像中的上下文信息進(jìn)行編碼,并將得到的4個特征圖進(jìn)行串聯(lián),從而實現(xiàn)對全局上下文的感知。然而,該方法使模型變得復(fù)雜,并且模型的訓(xùn)練嚴(yán)重依賴于初始化參數(shù)的設(shè)置。Ouyang等[67]通過學(xué)習(xí)圖像的分類得分,并將該得分作為補充的上下文特征來提升目標(biāo)檢測性能。為了提升候選區(qū)域的特征表示,Chen等[68]提出一種上下文微調(diào)網(wǎng)絡(luò),該網(wǎng)絡(luò)首先通過計算相似度找到與目標(biāo)區(qū)域相關(guān)的上下文區(qū)域,然后利用這些上下文區(qū)域的特征來增強目標(biāo)區(qū)域特征。隨后,Barnea等[69]將上下文的利用視為一個優(yōu)化問題,討論了上下文或其他類型的附加信息可以將檢測分?jǐn)?shù)提高到什么程度,并表明簡單的共現(xiàn)性關(guān)系是最有效的上下文信息。此外,Chen等[70]提出一種層次上下文嵌入框架,該框架可以作為一個即插即用的組件,通過挖掘上下文線索來增強候選區(qū)域的特征表達(dá),從而提升最終的檢測性能。最近,張瑞琰等[71]提出了面向光學(xué)遙感目標(biāo)的全局上下文檢測模型,該模型通過全局上下文特征與目標(biāo)中心點局部特征相結(jié)合的方式生成高分辨率熱點圖,并利用全局特征實現(xiàn)目標(biāo)的預(yù)分類。此外,一些方法通過語義分割來利用全局上下文信息。He等[72]提出一種統(tǒng)一的實例分割框架,利用像素級的監(jiān)督來優(yōu)化檢測器,并通過多任務(wù)的方式聯(lián)合優(yōu)化目標(biāo)檢測和實例分割模型。盡管通過語義分割可以顯著提高檢測性能,但是像素級的標(biāo)注是非常昂貴的。鑒于此,Zhao等[73]提出一種生成偽分割標(biāo)簽的方法,通過利用偽分割標(biāo)簽來于優(yōu)化檢測器,并取得了不錯的效果。進(jìn)一步地,Zhang等[74]提出一種無監(jiān)督的分割方法,在無像素級的標(biāo)注下通過聯(lián)合優(yōu)化目標(biāo)檢測和分割來增強用于目標(biāo)檢測的特征圖。目前,基于全局上下文的方法在目標(biāo)檢測上已經(jīng)取得了較大的進(jìn)展,但如何從全局場景中找到有利于提升小目標(biāo)檢測性能的上下文信息仍然是當(dāng)前的研究難點。
(2)基于顯式上下文推理的目標(biāo)檢測。 顯示上下文推理是指利用場景中明確的上下文信息來輔助推斷目標(biāo)的位置或類別,例如利用場景中天空區(qū)域與目標(biāo)的上下文關(guān)系來推斷目標(biāo)的類別。上下文關(guān)系通常指場景中目標(biāo)與場景或者目標(biāo)與目標(biāo)之間的約束和依賴關(guān)系(見圖3(c))。為了利用上下文關(guān)系,Chen等[75]提出一種自適應(yīng)上下文建模和迭代提升的方法,通過將一個任務(wù)的輸出作為另一個任務(wù)的上下文來提升目標(biāo)分類和檢測性能。此后,Gupta等[76]提出一種基于空間上下文的目標(biāo)檢測方法。該方法能夠準(zhǔn)確地捕捉到上下文和感興趣目標(biāo)之間的空間關(guān)系,并且有效地利用了上下文區(qū)域的外觀特征。進(jìn)一步地,Liu等[77]提出一種結(jié)構(gòu)推理網(wǎng)絡(luò),通過充分考慮場景上下文和目標(biāo)之間的關(guān)系來提升目標(biāo)的檢測性能。為了利用先驗知識,Xu等[78]在Faster R?CNN[44]的基礎(chǔ)上提出了一種Reasoning?RCNN,通過構(gòu)建知識圖譜來編碼上下文關(guān)系,并利用先驗的上下文關(guān)系來影響目標(biāo)檢測。Chen等[79]提出了一種空間記憶網(wǎng)絡(luò),空間記憶實質(zhì)上是將目標(biāo)實例重新組合成一個偽圖像表示,并將偽圖像表示輸入到卷積神經(jīng)網(wǎng)絡(luò)中進(jìn)行目標(biāo)關(guān)系推理,從而形成一種順序推理體系結(jié)構(gòu)。在注意力機制的基礎(chǔ)上,Hu等[80]提出一種輕量級目標(biāo)關(guān)系網(wǎng)絡(luò),通過引入不同物體之間的外觀和幾何結(jié)構(gòu)關(guān)系來做約束,實現(xiàn)物體之間的關(guān)系建模。該網(wǎng)絡(luò)無需額外的監(jiān)督,并且易于嵌入到現(xiàn)有的網(wǎng)絡(luò)中,可以有效地過濾冗余框,從而提升目標(biāo)的檢測性能。
近年來,基于上下文學(xué)習(xí)的方法得到了進(jìn)一步發(fā)展。Lim等[81]提出一種利用上下文連接多尺度特征的方法,該方法中使用網(wǎng)絡(luò)不同深度層級中的附加特征作為上下文,輔以注意力機制聚焦于圖像中的目標(biāo),充分利用了目標(biāo)的上下文信息,進(jìn)而提升了實際場景中的小目標(biāo)檢測精度。針對室內(nèi)小尺度人群檢測面臨的目標(biāo)特征與背景特征重疊且邊界難以區(qū)分的問題,Shen等[82]提出了一種室內(nèi)人群檢測網(wǎng)絡(luò)框架,使用一種特征聚合模塊(Feature aggregation module, FAM)通過融合和分解的操作來聚合上下文特征信息,為小尺度人群檢測提供更多細(xì)節(jié)信息,進(jìn)而顯著提升了對于室內(nèi)小尺度人群的檢測性能。Fu等[83]提出了一種新穎的上下文推理方法,該方法對目標(biāo)之間的固有語義和空間布局關(guān)系進(jìn)行建模和推斷,在提取小目標(biāo)語義特征的同時盡可能保留其空間信息,有效解決了小目標(biāo)的誤檢與漏檢問題。為了提升目標(biāo)的分類結(jié)果,Pato等[84]提出一種基于上下文的檢測結(jié)果重打分方法,該方法通過循環(huán)神經(jīng)網(wǎng)絡(luò)和自注意力機制來傳遞候選區(qū)域之間的信息并生成上下文表示,然后利用得到的上下文來對檢測結(jié)果進(jìn)行二次評估。
基于上下文學(xué)習(xí)的方法充分利用了圖像中與目標(biāo)相關(guān)的信息,能夠有效提升小目標(biāo)檢測的性能。但是,已有方法沒有考慮到場景中的上下文信息可能匱乏的問題,同時沒有針對性地利用場景中易于檢測的結(jié)果來輔助小目標(biāo)的檢測。鑒于此,未來的研究方向可以從以下兩個角度出發(fā)考慮:(1)構(gòu)建基于類別語義池的上下文記憶模型,通過利用歷史記憶的上下文來緩解當(dāng)前圖像中上下文信息匱乏的問題;(2)基于圖推理的小目標(biāo)檢測,通過圖模型和目標(biāo)檢測模型的結(jié)合來針對性地提升小目標(biāo)的檢測性能。
2.4 生成對抗學(xué)習(xí)
生成對抗學(xué)習(xí)的方法旨在通過將低分辨率小目標(biāo)的特征映射成與高分辨率目標(biāo)等價的特征,從而達(dá)到與尺寸較大目標(biāo)同等的檢測性能。前文所提到的數(shù)據(jù)增強、特征融合和上下文學(xué)習(xí)等方法雖然可以有效地提升小目標(biāo)檢測性能,但是這些方法帶來的性能增益往往受限于計算成本。針對小目標(biāo)分辨率低問題,Haris等[85]提出一種端到端的聯(lián)合訓(xùn)練超分辨率和檢測模型的方法,該方法一定程度上提升了低分辨率目標(biāo)的檢測性能。但是,這種方法對于訓(xùn)練數(shù)據(jù)集要求較高,并且對小目標(biāo)檢測性能的提升不足。
目前,一種有效的方法是通過結(jié)合生成對抗網(wǎng)絡(luò)(Generative adversarial network, GAN)[86]來提高小目標(biāo)的分辨率,縮小小目標(biāo)與大/中尺度目標(biāo)之間的特征差異,增強小目標(biāo)的特征表達(dá),進(jìn)而提高小目標(biāo)檢測的性能。在Radford等[87]提出了DCGAN(Deep convolutional GAN)后,計算視覺的諸多任務(wù)開始利用生成對抗模型來解決具體任務(wù)中面臨的問題。針對訓(xùn)練樣本不足的問題,Sixt等[88]提出了RenderGAN,該網(wǎng)絡(luò)通過對抗學(xué)習(xí)來生成更多的圖像,從而達(dá)到數(shù)據(jù)增強的目的。為了增強檢測模型的魯棒性,Wang等[89]通過自動生成包含遮擋和變形特征的樣本,以此提高對困難目標(biāo)的檢測性能。隨后,Li等[90]提出了一種專門針對小目標(biāo)檢測的感知GAN方法,該方法通過生成器和鑒別器相互對抗的方式來學(xué)習(xí)小目標(biāo)的高分辨率特征表示。在感知GAN中,生成器將小目標(biāo)表征轉(zhuǎn)換為與真實大目標(biāo)足夠相似的超分辨表征。同時,判別器與生成器對抗以識別生成的表征,并對生成器施加條件要求。該方法通過生成器和鑒別器相互對抗的方式來學(xué)習(xí)小目標(biāo)的高分辨率特征表示。這項工作將小目標(biāo)的表征提升為“超分辨”表征,實現(xiàn)了與大目標(biāo)相似的特性,獲得了更好的小目標(biāo)檢測性能。
近年來,基于GAN對小目標(biāo)進(jìn)行超分辨率重建的研究有所發(fā)展,Bai等[91]提出了一種針對小目標(biāo)的多任務(wù)生成對抗網(wǎng)絡(luò)(Multi?task generative adversarial network, MTGAN)。在MTGAN中,生成器是一個超分辨率網(wǎng)絡(luò),可以將小模糊圖像上采樣到精細(xì)圖像中,并恢復(fù)詳細(xì)信息以便更準(zhǔn)確地檢測。判別器是多任務(wù)網(wǎng)絡(luò),區(qū)分真實圖像與超分辨率圖像并輸出類別得分和邊界框回歸偏移量。此外,為了使生成器恢復(fù)更多細(xì)節(jié)以便于檢測,判別器中的分類和回歸損失在訓(xùn)練期間反向傳播到生成器中。MTGAN由于能夠從模糊的小目標(biāo)中恢復(fù)清晰的超分辨目標(biāo),因此大幅度提升了小目標(biāo)的檢測性能。進(jìn)一步地,針對現(xiàn)有的用于小目標(biāo)檢測的超分辨率模型存在缺乏直接的監(jiān)督問題,Noh等[92]提出一種新的特征級別的超分辨率方法,該方法通過空洞卷積的方式使生成的高分辨率目標(biāo)特征與特征提取器生成的低分辨率特征保持相同的感受野大小,從而避免了因感受野不匹配而生成錯誤超分特征的問題。此外,Deng等[58]設(shè)計了一種擴展特征金字塔網(wǎng)絡(luò),該網(wǎng)絡(luò)通過設(shè)計的特征紋理模塊生成超高分辨率的金字塔層,從而豐富了小目標(biāo)的特征信息。
基于生成對抗模型的目標(biāo)檢測算法通過增強小目標(biāo)的特征信息,可以顯著提升檢測性能。同時,利用生成對抗模型來超分小目標(biāo)這一步驟無需任何特別的結(jié)構(gòu)設(shè)計,能夠輕易地將已有的生成對抗模型和檢測模型相結(jié)合。但是,目前依舊面臨兩個無法避免的問題:(1)生成對抗網(wǎng)絡(luò)難以訓(xùn)練,不易在生成器和鑒別器之間取得好的平衡;(2)生成器在訓(xùn)練過程中產(chǎn)生樣本的多樣性有限,訓(xùn)練到一定程度后對于性能的提升有限。
2.5 無錨機制
錨框機制在目標(biāo)檢測中扮演著重要的角色。許多先進(jìn)的目標(biāo)檢測方法都是基于錨框機制而設(shè)計的,但是錨框這一設(shè)計對于小目標(biāo)的檢測極不友好。現(xiàn)有的錨框設(shè)計難以獲得平衡小目標(biāo)召回率與計算成本之間的矛盾,而且這種方式導(dǎo)致了小目標(biāo)的正樣本與大目標(biāo)的正樣本極度不均衡,使得模型更加關(guān)注于大目標(biāo)的檢測性能,從而忽視了小目標(biāo)的檢測。極端情況下,設(shè)計的錨框如果遠(yuǎn)遠(yuǎn)大于小目標(biāo),那么小目標(biāo)將會出現(xiàn)無正樣本的情況。小目標(biāo)正樣本的缺失,將使得算法只能學(xué)習(xí)到適用于較大目標(biāo)的檢測模型。此外,錨框的使用引入了大量的超參,比如錨框的數(shù)量、寬高比和大小等,使得網(wǎng)絡(luò)難以訓(xùn)練,不易提升小目標(biāo)的檢測性能。近些年無錨機制的方法成為了研究熱點,并在小目標(biāo)檢測上取得了較好效果。
一種擺脫錨框機制的思路是將目標(biāo)檢測任務(wù)轉(zhuǎn)換為關(guān)鍵點的估計,即基于關(guān)鍵點的目標(biāo)檢測方法。基于關(guān)鍵點的目標(biāo)檢測方法主要包含兩個大類:基于角點的檢測和基于中心的檢測。基于角點的檢測器通過對從卷積特征圖中學(xué)習(xí)到的角點分組來預(yù)測目標(biāo)邊界框。DeNet[93]將目標(biāo)檢測定義為估計目標(biāo)4個角點的概率分布,包括左上角、右上角、左下角和右下角(見圖4(a))。首先利用標(biāo)注數(shù)據(jù)來訓(xùn)練卷積神經(jīng)網(wǎng)絡(luò),然后利用該網(wǎng)絡(luò)來預(yù)測角點分布。之后,利用角點分布和樸素貝葉斯分類器來確定每個角點對應(yīng)的候選區(qū)域是否包含目標(biāo)。在DeNet之后,Wang等[94]提出了一種新的使用角點和中心點之間的連接來表示目標(biāo)的方法,命名為PLN(Point linking network)。PLN首先回歸與DeNet相似的4個角點和目標(biāo)的中心點,同時通過全卷積網(wǎng)絡(luò)預(yù)測關(guān)鍵點兩兩之間是否相連,然后將角點及其相連的中心點組合起來生成目標(biāo)邊界框。PLN對于稠密目標(biāo)和具有極端寬高比率目標(biāo)表現(xiàn)良好。但是,當(dāng)角點周圍沒有目標(biāo)像素時,PLN由于感受野的限制將很難檢測到角點。繼PLN之后,Law等[95]提出了一種新的基于角點的檢測算法,命名為CornerNet。CornerNet將目標(biāo)檢測問題轉(zhuǎn)換為角點檢測問題,首先預(yù)測所有目標(biāo)的左上和右下的角點,然后將這些角點進(jìn)行兩兩匹配,最后利用配對的角點生成目標(biāo)的邊界框。CornetNet的改進(jìn)版本——CornerNet?Lite[96],從減少處理的像素數(shù)量和減少在每個像素上進(jìn)行的計算數(shù)量兩個角度出發(fā)進(jìn)行改進(jìn),有效解決了目標(biāo)檢測中的兩個關(guān)鍵用例:在不犧牲精度的情況下提高效率以及實時效率的準(zhǔn)確性。與基于錨框的檢測器相比,CornerNet系列具有更簡潔的檢測框架,在提高檢測效率的同時獲得了更高的檢測精度。但是,該系列仍然會因為錯誤的角點匹配預(yù)測出大量不正確的目標(biāo)邊界框。

為了進(jìn)一步提高目標(biāo)檢測性能,Duan等[97]提出了一種基于中心預(yù)測的目標(biāo)檢測框架,稱為CenterNet(見圖4(b))。CenterNet首先預(yù)左上角和右下角的角點以及中心關(guān)鍵點,然后通過角點匹配確定邊界框,最后利用預(yù)測的中心點消除角點不匹配引起的不正確的邊界框。與CenterNet類似,Zhou等[98]通過對極值點和中心點進(jìn)行匹配,提出了一種自下而上的目標(biāo)檢測網(wǎng)絡(luò),稱為ExtremeNet。ExtremeNet首先使用一個標(biāo)準(zhǔn)的關(guān)鍵點估計網(wǎng)絡(luò)來預(yù)測最上面、最下面、最左邊、最右邊的4個極值點和中心點,然后在5個點幾何對齊的情況下對它們進(jìn)行分組以生成邊界框。但是ExtremeNet和CornerNet等基于關(guān)鍵點的檢測網(wǎng)絡(luò)都需要經(jīng)過一個關(guān)鍵點分組階段,這降低了算法整體的速度。針對這一問題,Zhou等[99]將目標(biāo)建模為其一個單點,即邊界框中心點,無需對構(gòu)建點進(jìn)行分組或其他后處理操作。然后在探測器使用關(guān)鍵點估計來查找中心點,并回歸到所有其他對象屬性,如大小、位置等。這一方法很好地平衡了檢測的精度與速度。
近年來,基于關(guān)鍵點的目標(biāo)檢測方法又有了新的擴展。Yang等[100]提出了一種名為代表點(RepPoints)的檢測方法,提供了更細(xì)粒度的表示方式,使得目標(biāo)可以被更精細(xì)地界定。同時,這種方法能夠自動學(xué)習(xí)目標(biāo)的空間信息和局部語義特征,一定程度上提升了小目標(biāo)檢測的精度(見圖4(c))。更進(jìn)一步地,Kong等[101]受到人眼的中央凹(視網(wǎng)膜中央?yún)^(qū)域,集中了絕大多數(shù)的視錐細(xì)胞,負(fù)責(zé)視力的高清成像)啟發(fā),提出了一種直接預(yù)測目標(biāo)存在的可能性和邊界框坐標(biāo)的方法,該方法首先預(yù)測目標(biāo)存在的可能性,并生成類別敏感語義圖,然后為每一個可能包含目標(biāo)的位置生成未知類別的邊界框。由于擺脫了錨框的限制,F(xiàn)oveaBox對于小目標(biāo)等具有任意橫縱比的目標(biāo)具備良好的魯棒性和泛化能力,并在檢測精度上也得到了較大提升。與FoveaBox相似,Tian等[102]使用語義分割的思想來解決目標(biāo)檢測問題,提出了一種基于全卷積的單級目標(biāo)檢測器FCOS(Fully convolutional one?stage),避免了基于錨框機制的方法中超參過多、難以訓(xùn)練的問題(見圖4(d))。此外,實驗表明將兩階段檢測器的第一階段任務(wù)換成FCOS來實現(xiàn),也能有效提升檢測性能。而后,Zhu等[103]將無錨機制用于改進(jìn)特征金字塔中的特征分配問題,根據(jù)目標(biāo)語義信息而不是錨框來為目標(biāo)選擇相應(yīng)特征,同時提高了小目標(biāo)檢測的精度與速度。Zhang等[104]則從基于錨框機制與無錨機制的本質(zhì)區(qū)別出發(fā),即訓(xùn)練過程中對于正負(fù)樣本的定義不同,提出了一種自適應(yīng)訓(xùn)練樣本選擇策略,根據(jù)對象的統(tǒng)計特征自動選擇正反樣本。針對復(fù)雜的場景下小型船舶難以檢測的問題,F(xiàn)u等[105]提出了一種新的檢測方法——特征平衡與細(xì)化網(wǎng)絡(luò),采用直接學(xué)習(xí)編碼邊界框的一般無錨策略,消除錨框?qū)τ跈z測性能的負(fù)面影響,并使用基于語義信息的注意力機制平衡不同層次的多個特征,達(dá)到了最先進(jìn)的性能。為了更有效地處理無錨框架下的多尺度檢測,Yang等[106]提出了一種基于特殊注意力機制的特征金字塔網(wǎng)絡(luò),該網(wǎng)絡(luò)能夠根據(jù)不同大小目標(biāo)的特征生成特征金字塔,進(jìn)而更好地處理多尺度目標(biāo)檢測問題,顯著提升了小目標(biāo)的檢測性能。
2.6 其他優(yōu)化策略
在小目標(biāo)檢測這一領(lǐng)域,除了前文所總結(jié)的幾個大類外,還有諸多優(yōu)秀的方法。針對小目標(biāo)訓(xùn)練樣本少的問題,Kisantal等[33]提出了一種過采樣策略,通過增加小目標(biāo)對于損失函數(shù)的貢獻(xiàn),以此提升小目標(biāo)檢測的性能。除了增加小目標(biāo)樣本權(quán)重這一思路之外,另一種思路則是通過增加專用于小目標(biāo)的錨框數(shù)量來提高檢測性能。Zhang等[107]提出了一種密集錨框策略,通過在一個感受野中心設(shè)計多個錨框來提升小目標(biāo)的召回率。與密集錨框策略相近,Zhang等[108]設(shè)計了一種基于有效感受野和等比例區(qū)間界定錨框尺度的方法,并提出一種尺度補償錨框匹配策略來提高小人臉目標(biāo)的召回率。增加錨框數(shù)量對于提升小目標(biāo)檢測精度十分有效,同時也額外增加了巨大的計算成本。Eggert等[109]從錨框尺度的優(yōu)化這一角度入手,通過推導(dǎo)小目標(biāo)尺寸之間的聯(lián)系,為小目標(biāo)選擇合適的錨框尺度,在商標(biāo)檢測上獲得了較好的檢測效果。之后,Wang等[110]提出了一種基于語義特征的引導(dǎo)錨定策略,通過同時預(yù)測目標(biāo)中心可能存在的位置及目標(biāo)的的尺度和縱橫比,提高了小目標(biāo)檢測的性能。此外,這種策略可以集成到任何基于錨框的方法中。但是,這些改進(jìn)沒有實質(zhì)性地平衡檢測精度與計算成本之間的矛盾。
近些年來,隨著計算資源的增加,越來越多的網(wǎng)絡(luò)使用級聯(lián)思想來平衡目標(biāo)漏檢率與誤檢率。級聯(lián)這一思想來源已久[111],并在目標(biāo)檢測領(lǐng)域得到了廣泛的應(yīng)用。它采用了從粗到細(xì)的檢測理念:用簡單的計算過濾掉大多數(shù)簡單的背景窗口,然后用復(fù)雜的窗口來處理那些更困難的窗口。隨著深度學(xué)習(xí)時代的到來,Cai等[25]提出了經(jīng)典網(wǎng)絡(luò)Cascade R?CNN,通過級聯(lián)幾個基于不同IoU閾值的檢測網(wǎng)絡(luò)達(dá)到不斷優(yōu)化預(yù)測結(jié)果的目的。之后,Li等[112]在Cascade R?CNN的基礎(chǔ)上進(jìn)行了擴展,進(jìn)一步提升了小目標(biāo)檢測性能。受到級聯(lián)這一思想的啟發(fā),Liu等[113]提出了一種漸近定位策略,通過不斷增加IoU閾值來提升行人檢測的檢測精度。另外,文獻(xiàn)[114?116]展現(xiàn)了級聯(lián)網(wǎng)絡(luò)在困難目標(biāo)檢測上的應(yīng)用,也一定程度上提升了小目標(biāo)的檢測性能。
另外一種思路則是分階段檢測,通過不同層級之間的配合平衡漏檢與誤檢之間的矛盾。Chen等[117]提出一種雙重探測器,其中第一尺度探測器最大限度地檢測小目標(biāo),第二尺度探測器則檢測第一尺度探測器無法識別的物體。進(jìn)一步地,Drenkow等[118]設(shè)計了一種更加高效的目標(biāo)檢測方法,該方法首先在低分辨率下檢查整個場景,然后使用前一階段生成的顯著性地圖指導(dǎo)后續(xù)高分辨率下的目標(biāo)檢測。這種方式很好地權(quán)衡了檢測精度和檢測速度。此外,文獻(xiàn)[119?121]針對空中視野圖像中的困難目標(biāo)識別進(jìn)行了前后景的分割,區(qū)分出重要區(qū)域與非重要區(qū)域,在提高檢測性能的同時也減少了計算成本。
優(yōu)化損失函數(shù)也是一種提升小目標(biāo)檢測性能的有效方法。Redmon等[26]發(fā)現(xiàn),在網(wǎng)絡(luò)的訓(xùn)練過程中,小目標(biāo)更容易受到隨機誤差的影響。隨后,他們針對這一問題進(jìn)行了改進(jìn)[27],提出一種依據(jù)目標(biāo)尺寸設(shè)定不同權(quán)重的損失函數(shù),實現(xiàn)了小目標(biāo)檢測性能的提升。Lin等[122]則針對類別不均衡問題,在RetinaNet中提出了焦距損失,有效解決了訓(xùn)練過程中存在的前景?背景類不平衡問題。進(jìn)一步地,Zhang等[123]將級聯(lián)思想與焦距損失相結(jié)合,提出了Cascade RetinaNet,進(jìn)一步提高了小目標(biāo)檢測的精度。針對小目標(biāo)容易出現(xiàn)的前景與背景不均衡問題,Deng等[58]則提出了一種考慮前景?背景之間平衡的損失函數(shù),通過全局重建損失和正樣本塊損失提高前景與背景的特征質(zhì)量,進(jìn)而提升了小目標(biāo)檢測的性能。
為了權(quán)衡考慮小目標(biāo)的檢測精度和速度,Sun等[124]提出了一種多接受域和小目標(biāo)聚焦弱監(jiān)督分割網(wǎng)絡(luò),通過使用多個接收域塊來關(guān)注目標(biāo)及其相鄰背景,并依據(jù)不同空間位置設(shè)置權(quán)重,以達(dá)到增強特征可辨識性的目的。此外,Yoo等[125]將多目標(biāo)檢測任務(wù)重新表述為邊界框的密度估計問題,提出了一種混合密度目標(biāo)檢測器,通過問題的轉(zhuǎn)換避免了真值框與預(yù)測框匹配以及啟發(fā)式錨框設(shè)計等繁瑣過程,也一定程度上解決了前景與背景不平衡的問題。
END
整理不易,點贊三連↓