導讀:在已經(jīng)準備好工具箱的情況下,我們來學習怎樣使用pandas對數(shù)據(jù)進行加載、操作、預處理與打磨。
讓我們先從CSV文件和pandas開始。

pandas庫提供了最方便、功能完備的函數(shù),能從文件(或URL)加載表格數(shù)據(jù)。默認情況下,pandas會將數(shù)據(jù)存儲到一個專門的數(shù)據(jù)結(jié)構(gòu)中,這個數(shù)據(jù)結(jié)構(gòu)能夠?qū)崿F(xiàn)按行索引、通過自定義的分隔符分隔變量、推斷每一列的正確數(shù)據(jù)類型、轉(zhuǎn)換數(shù)據(jù)(如果需要的話),以及解析日期、缺失值和出錯數(shù)據(jù)。我們將從導入pandas包和讀取Iris數(shù)據(jù)集開始:import?pandas?as?pd
Iris_filename=’datasets-uci-iris.csv’
Iris=pd.read_csv(iris_filename,sep=’_’,decimal=’_’,heade=None,
?????????????????names=[‘sepal_length’,‘sepal_width’
????????????????????????‘petal_length’,‘petal_width’
????????????????????????‘target’])
通過上面的命令,可以指定文件名、分隔符(sep)、小數(shù)點占位符(decimal)、是否有標題(header)以及變量名稱(使用names和列表)。分隔符和小數(shù)點占位符的默認設(shè)置為sep=','?和decimal='.',在上面的函數(shù)中這些設(shè)置顯得有些多余。但是,對于歐洲格式的CSV文件需要明確指出這兩個參數(shù),這是因為許多歐洲國家的分隔符和小數(shù)點占位符都與默認值不同。如果數(shù)據(jù)集不能在線使用,可以按照如下步驟從互聯(lián)網(wǎng)上下載:import?urllib
??url=”http://aima.cs.berkeley.edu/data/iris.csv”
??set1=urllib.request.Request(ur1)
??iris_p=urllib.request.urlopen(set1)
??iris_other=pd.read_csv(iris_p,sep=',',decimal='.',?
????????header=None,?names=[‘sepal_length’,‘sepal_width’?????????????????????????????????????????????????????????????????????????????????????????????????????????????????
????????????????????????????‘petal_length’,‘petal_width’
?????????????????????????????????????????????‘target’?])
??iris_other.head()
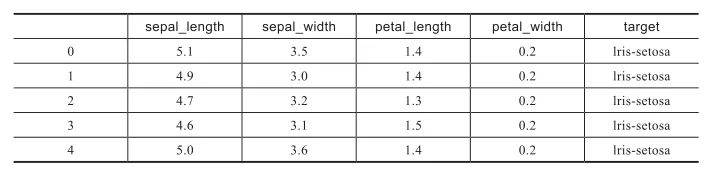
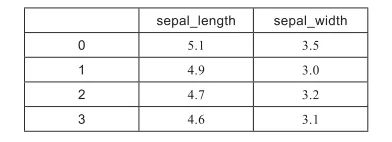
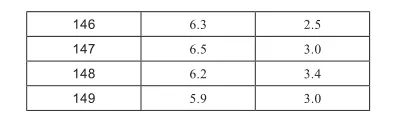
由此產(chǎn)生的對象是一個名為iris的pandas數(shù)據(jù)框(DataFrame)。它不是一個簡單的Python列表或字典。為了對其內(nèi)容有一個粗略的概念,使用如下命令可以輸出它的前幾行(或最后幾行):調(diào)用此函數(shù),如果不帶任何參數(shù),將輸出五行。如果想要輸出不同的行數(shù),調(diào)用函數(shù)時只需要設(shè)置想要的行數(shù)作為參數(shù),格式如下:上述命令只輸出了數(shù)據(jù)的前兩行。現(xiàn)在,為了獲得每列的名稱,可以使用如下代碼獲得列名:
Index([‘sepal_length’,‘sepal_width’?????????????
???????‘petal_length’,‘petal_width’????????????????????????????
???????‘target’?],dtype=‘object’?)
這次生成的對象非常有趣,顯然它看起來像一個列表,但實際上是一個pandas索引。可以從對象的名稱猜測,它表示的是列的名稱。例如,要提取“target”列,簡單地按如下方式就可以做到:0?Iris-setosa
1?Iris-setosa
2?Iris-setosa
3?Iris-setosa
...
149?Iris-virginica
Name:target,dtype:object
對象y的類型是pandas series,可以把它看成是具有軸標簽的一維數(shù)組,稍后我們會對它進行深入研究。現(xiàn)在,我們只需要了解,pandas索引(Index)類就像表中列的字典索引一樣。需要注意的是,還可以通過索引得到列的列表,如下所示:x?=iris[[?‘sepal_length’,‘sepal_width’?]]
x
以下是X數(shù)據(jù)集的前4行數(shù)據(jù):以下是X數(shù)據(jù)集的后4行數(shù)據(jù):在這個例子中,得到的結(jié)果是一個pandas數(shù)據(jù)框。為什么使用相同的函數(shù)卻有如此大的差異呢?那么,在前一個例子中,我們想要抽取一列,因此,結(jié)果是一維向量(即pandas series)。在第二個例子中,我們要抽取多列,于是得到了類似矩陣的結(jié)果(我們知道矩陣可以映射為pandas的數(shù)據(jù)框)。新手讀者可以簡單地通過查看輸出結(jié)果的標題來發(fā)現(xiàn)它們的差異;如果該列有標簽,則正在處理的是pandas 數(shù)據(jù)框。否則,如果結(jié)果是一個沒有標題的向量,那么這是pandas series。至此,我們已經(jīng)了解了數(shù)據(jù)科學過程中一些很常見的步驟。加載完數(shù)據(jù)集之后,通常會分離特征和目標標簽。目標標簽通常是序號或文本字符串,指示與每一組特征相關(guān)的類別。然后,接下來的步驟需要弄清楚要處理的問題的規(guī)模,因此,你需要知道數(shù)據(jù)集的大小。通常,對每個觀測計為一行,對每一個特征計為一列。為了獲得數(shù)據(jù)集的維數(shù),只需在pandas數(shù)據(jù)框和series上使用屬性shape,如下面的例子所示:print?(X.shape)
#輸出:(150,2)
print?(y.shape)
#輸出:(150,)
得到的對象是一個包含矩陣或數(shù)組大小的元組(tuple),還要注意的是pandas series也遵循相同的格式(比如,只有一個元素的元組)。本文摘編自《數(shù)據(jù)科學導論:Python語言》(原書第3版)
延伸閱讀《數(shù)據(jù)科學導論:Python語言》推薦語:數(shù)據(jù)科學快速入門指南,全面覆蓋進行數(shù)據(jù)科學分析和開發(fā)的所有關(guān)鍵要點。PPT?|?讀書?|?書單?|?硬核?|?干貨?|?講明白?|?神操作大數(shù)據(jù)?|?云計算?|?數(shù)據(jù)庫?|?Python?|?可視化AI?|?人工智能?|?機器學習?|?深度學習?|?NLP5G?|?中臺?|?用戶畫像?|?1024?|?數(shù)學?|?算法?|?數(shù)字孿生據(jù)統(tǒng)計,99%的大咖都完成了這個神操作