
【機(jī)器學(xué)習(xí)基礎(chǔ)】機(jī)器學(xué)習(xí)模型評估教程!
如何在投入生產(chǎn)前評估機(jī)器學(xué)習(xí)模型性能?

想象一下,你訓(xùn)練了一個機(jī)器學(xué)習(xí)模型。也許,可以從中選幾個候選方案。
你在測試集上運(yùn)行它,得到了一些質(zhì)量評估。模型沒有過度擬合,特征也有意義。總的來說,在現(xiàn)有的有限數(shù)據(jù)下,它們的表現(xiàn)盡善盡美。
現(xiàn)在,是時候來決定它們是否好到可以投入生產(chǎn)使用了。如何在標(biāo)準(zhǔn)性的質(zhì)量評估外,評估和比較你的模型呢?
在本教程中,我們將通過一個案例,詳細(xì)介紹如何評估你的模型。
案例:預(yù)測員工流失情況
我們將使用一個來自Kaggle競賽的虛構(gòu)數(shù)據(jù)集,目標(biāo)是識別哪些員工可能很快離開公司。(數(shù)據(jù)集與代碼下載,在后臺回復(fù)日期"210411 "獲取)
這個想法聽起來很簡單:有了預(yù)警,你可能會阻止這個人離開。一個有價值的專家會留在公司——無需尋找一個新的員工,再等他們學(xué)會工作技巧。
讓我們試著提前預(yù)測那些有風(fēng)險的員工吧!
首先,檢查訓(xùn)練數(shù)據(jù)集。它是為方便我們使用而收集的。一個經(jīng)驗豐富的數(shù)據(jù)科學(xué)家會產(chǎn)生懷疑!我們將其視為理所當(dāng)然,并跳過構(gòu)建數(shù)據(jù)集的棘手部分。
我們有1470名員工的數(shù)據(jù)。
共35個特征,描述的內(nèi)容包括:
員工背景(教育、婚姻狀況等)。
工作細(xì)節(jié)(部門、工作級別、是否出差等)。
工作歷史(在公司工作年限、最后一次晉升日期等)。
薪酬(工資、股票意見等)。
以及其他一些特征。
還有一個二元標(biāo)簽,可以看到誰離開了公司。這正是我們所需要的!我們將問題定義為概率分類任務(wù)。模型應(yīng)該估計每個員工屬于目標(biāo) "流失 "類的可能性。

在研究模型時,我們通常會將數(shù)據(jù)集分成訓(xùn)練和測試數(shù)據(jù)集。我們使用第一個數(shù)據(jù)集來訓(xùn)練模型,用其余的數(shù)據(jù)集來檢查它在未知數(shù)據(jù)上的表現(xiàn)。
我們不詳細(xì)介紹模型訓(xùn)練過程。這就是數(shù)據(jù)科學(xué)的魔力,我們相信你是知道的!
假設(shè)我們進(jìn)行了很多次實驗,嘗試了不同的模型,調(diào)整了相應(yīng)的超數(shù),在交叉驗證中進(jìn)行了區(qū)間評估。
我們最終得到了兩個合理的模型,看起來同樣不錯。
接下來,檢查它們在測試集上的性能。這是我們得到的結(jié)果。
隨機(jī)森林模型的ROC AUC值為0. 795分
梯度提升模型的ROC AUC評分為0.803分。
ROC AUC是在概率分類的情況下優(yōu)化的標(biāo)準(zhǔn)指標(biāo)。如果你尋找過Kaggle這個用例的眾多解決方案,這應(yīng)該是大多數(shù)人的做法。

我們的兩個模型看起來都不錯。比隨機(jī)拆分好得多,所以我們肯定可以從數(shù)據(jù)中得到一些線索。
ROC AUC分?jǐn)?shù)很接近。鑒于這只是一個單點估計(single-point estimate),我們可以認(rèn)為性能相似。
那么問題來了,兩者之間我們應(yīng)該選哪個呢?
同樣的質(zhì)量,不同的特點
讓我們更詳細(xì)地分析這些模型。
我們將使用Evidently開源庫來比較模型并生成性能報告。
如果你想一步一步地跟著做,可以在文末打開這個完整的upyter Notebook。
首先,我們在同一個測試數(shù)據(jù)集上訓(xùn)練兩個模型并評估性能。
接下來,我們將兩個模型的性能日志準(zhǔn)備成兩個pandas數(shù)據(jù)框(DataFrames)。每個包括輸入特征、預(yù)測類和真實標(biāo)簽。
我們指定了列映射來來定義目標(biāo)的位置,預(yù)測的類別,以及分類和數(shù)字特征。
然后,我們調(diào)用evidently tabs來生成分類性能報告。在單個的dashboard中顯示兩個模型的性能,以便我們可以比較它們。
comparison_report = Dashboard(rf_merged_test, cat_merged_test, column_mapping = column_mapping, tabs=[ProbClassificationPerformanceTab])
comparison_report.show()
我們將較簡單的隨機(jī)森林模型作為基準(zhǔn),對于這個工具來說,它成為 "參考(Reference)"。第二個梯度提升被表示為 "當(dāng)前(Current)"的評估模型。
我們可以快速看到兩個模型在測試集上的性能指標(biāo)匯總。
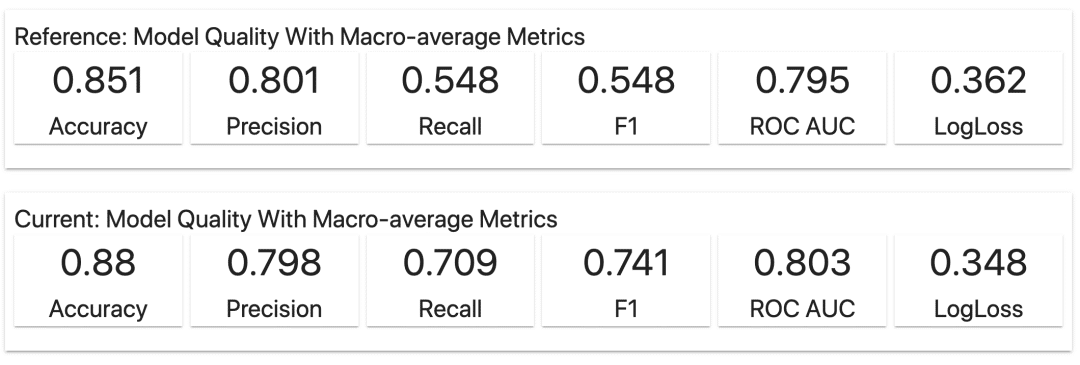
現(xiàn)實情況不是Kaggle,所以我們并不總是關(guān)注第二位數(shù)。如果我們只看準(zhǔn)確率和ROC AUC,這兩個模型的性能看起來非常接近。
我們甚至可能有理由去偏愛更簡單的隨機(jī)森林模型,源于它更強(qiáng)的可解釋性,或者更好的計算性能。
但F1-score的差異暗示可能還有更多故事。模型的內(nèi)部運(yùn)作方式各不相同。
重溫類別不平衡問題
精明的機(jī)器學(xué)習(xí)者知道其中的竅門。兩個類別的規(guī)模遠(yuǎn)不相等。在這種情況下,準(zhǔn)確度的衡量標(biāo)準(zhǔn)是沒有太大意義的。即使這些數(shù)字可能在 "論文"上看起來很好。
目標(biāo)類通常是一個次要的類。我們希望預(yù)測一些罕見但重要的事件,比如:欺詐、流失、辭職。在我們的數(shù)據(jù)集中,只有16%的員工離開了公司。
如果我們做一個樸素的模型,只是把所有員工都?xì)w類為 "可能留下",我們的準(zhǔn)確率是84%!
ROC AUC并不能給我們一個完整的答案。相反,我們必須找到更適合預(yù)期模型性能的指標(biāo)。
何謂"好的"模型?
你知道其中的答案:這要視情況而定。
如果一個模型能簡單地指出那些即將辭職的人,并且永遠(yuǎn)是對的,那就太好了。那么我們就可以做任何事情了!一個理想的模型適合任何用例——但這往往不會在現(xiàn)實中出現(xiàn)。
相反,我們處理不完美的模型,使它們對我們的業(yè)務(wù)流程有用。根據(jù)應(yīng)用,我們可能會選擇不同的標(biāo)準(zhǔn)來評估模型。
沒有一個單一的衡量標(biāo)準(zhǔn)是理想的。但模型并不是存在于真空中——希望你可以從提出問題開始!
讓我們考慮不同的應(yīng)用場景,并在此背景下評估模型。
示例1:給每個員工貼標(biāo)簽
在實踐中,我們可能會將該模型集成到一些現(xiàn)有的業(yè)務(wù)流程中。
假設(shè)我們的模型用于在內(nèi)部人力資源系統(tǒng)的界面上顯示一個標(biāo)簽,我們希望突出顯示每個具有高損耗風(fēng)險的員工。當(dāng)經(jīng)理登錄系統(tǒng)時,他們將會看到部門中每個人的 "高風(fēng)險"或 "低風(fēng)險"標(biāo)簽。
我們希望為所有員工顯示標(biāo)簽。我們需要的模型盡可能的 "正確"。但我們知道,準(zhǔn)確度指標(biāo)隱藏了所有重要的細(xì)節(jié)。我們將如何評估我們的模型呢?
超越準(zhǔn)確度
讓我們回到evidently的報告中,更深入地分析兩種模型的性能。
我們能夠很快注意到,兩個模型的混淆矩陣看起來是不同的。
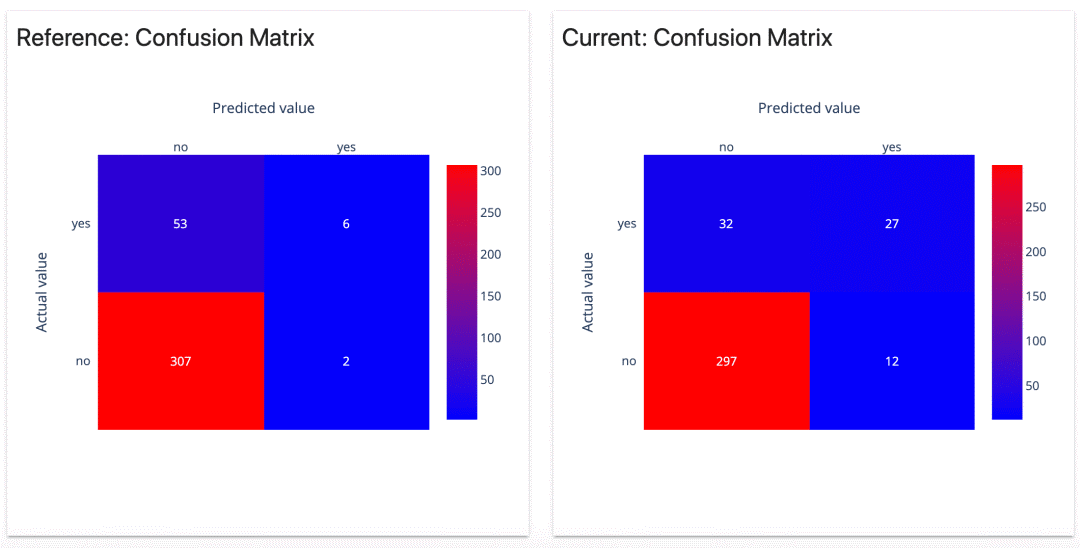
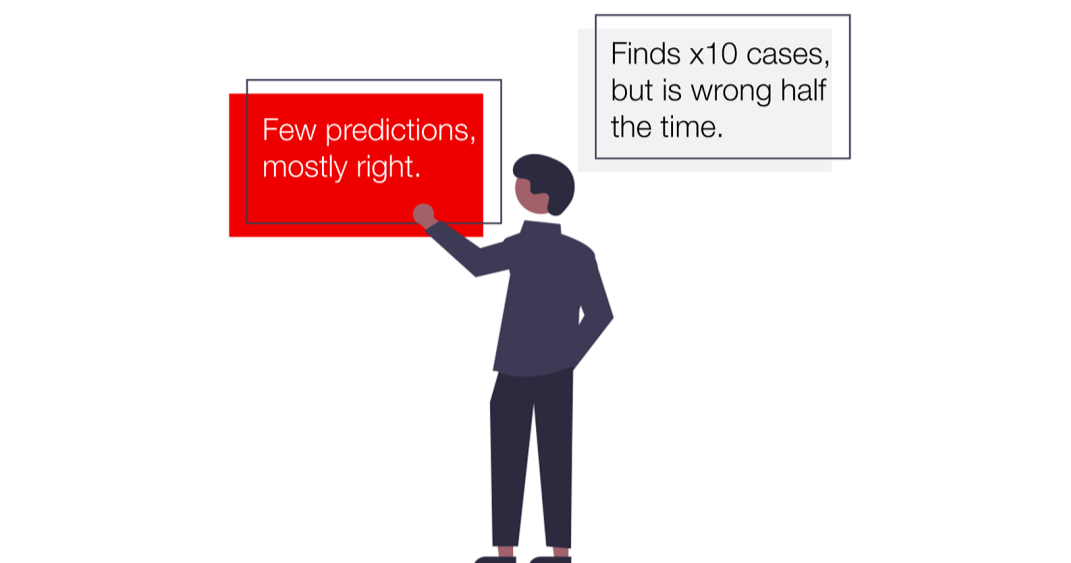
我們的第一個模型只有兩個假陽性(false positives)。聽起來很不錯?的確,它沒有給我們太多關(guān)于潛在辭職的錯誤提醒。
但是,另一方面,它只正確識別了6次辭職。其他的53個都被漏掉了。
第二個模型錯誤地將12名員工標(biāo)記為高風(fēng)險。但是,它正確預(yù)測了27個辭職。它只漏掉了32人。
按類別劃分的質(zhì)量指標(biāo)圖總結(jié)了這一點。讓我們看看 "yes"類別。

但第二個模型在召回率中勝出!它發(fā)現(xiàn)45%的人離開了公司,而第一個模型只有10%。
你會選擇哪個模型呢?
最有可能的是,在目標(biāo) "辭職"類別中,召回率較高的那一個會贏。它可以幫助我們發(fā)現(xiàn)更多可能離職的人。
我們可以容忍一些假陽性,因為解釋預(yù)測的是經(jīng)理。人力資源系統(tǒng)中已有的數(shù)據(jù)也提供了額外的背景。
更有可能的是,在其中增加可解釋性是必不可少的。它可以幫助用戶解釋模型預(yù)測,并決定何時以及如何做出反應(yīng)。
總而言之,我們將基于召回率指標(biāo)來評估我們的模型。作為一個非ML標(biāo)準(zhǔn),我們將添加經(jīng)理對該功能的可用性測試。具體來說,要把可解釋性作為界面的一部分來考慮。
示例2:發(fā)送主動警報
讓我們想象一下,我們期望在模型上有一個特定的行動。
它可能會與同一個人力資源系統(tǒng)進(jìn)行整合。但現(xiàn)在,我們將根據(jù)預(yù)測發(fā)送主動通知。
也許,給經(jīng)理發(fā)送一封電子郵件,提示安排與有風(fēng)險的員工會面?或者是對可能的留用環(huán)節(jié)提出具體建議,比如額外的培訓(xùn)等等。

在這種情況下,我們可能對這些假陽性有額外的考慮。
如果我們過于頻繁地給經(jīng)理們發(fā)送郵件,他們很可能會被忽略。不必要的干預(yù)也可能被視為一種負(fù)面結(jié)果。
我們該怎么辦?
如果沒有任何新的有價值的功能可以添加,我們就只能使用現(xiàn)有的模型。我們無法榨取更多的精度。但是,可以限制采取行動的預(yù)測數(shù)量,目標(biāo)是只關(guān)注那些預(yù)測風(fēng)險較高的員工。
精度-召回率權(quán)衡
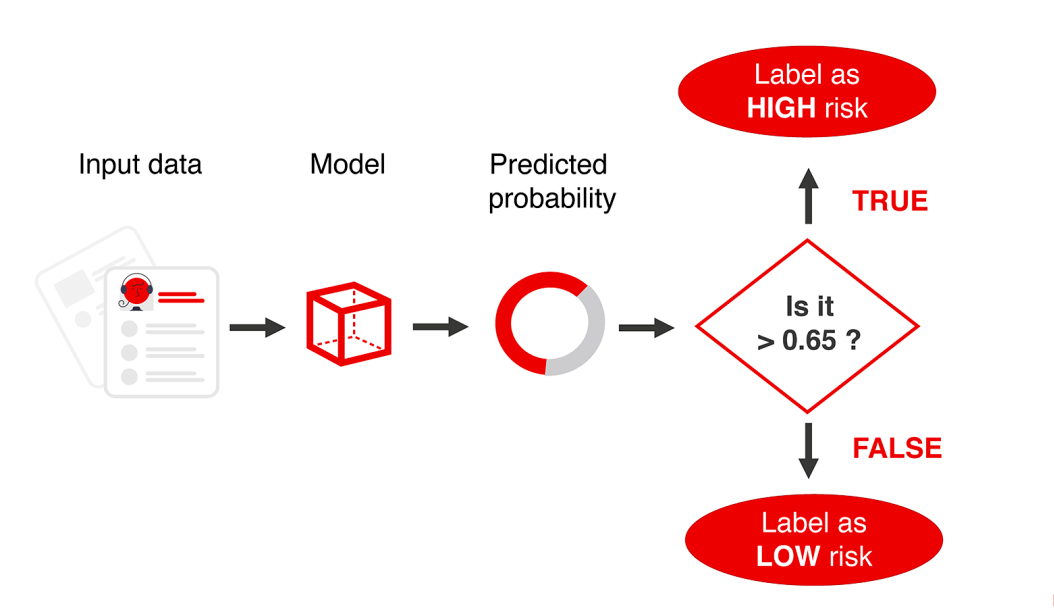
概率模型的輸出是一個介于0和1之間的數(shù)字,為了使用預(yù)測,我們需要在這些預(yù)測的概率上分配標(biāo)簽。二元分類的 "默"方法是以0.5為切入點。如果概率較高,標(biāo)簽就是 "yes"。
我們可以選擇一個不同的閾值,也許,0.6甚至0.8?通過設(shè)置更高的閾值,我們將限制假陽性的數(shù)量。
但這是以召回率為代價的:我們犯的錯誤越少,正確預(yù)測的數(shù)量也越少。
這個來自evidently報告的類別分離圖(Class Separation)讓這個想法非常直觀。它在實際標(biāo)簽旁邊顯示了各個預(yù)測概率。
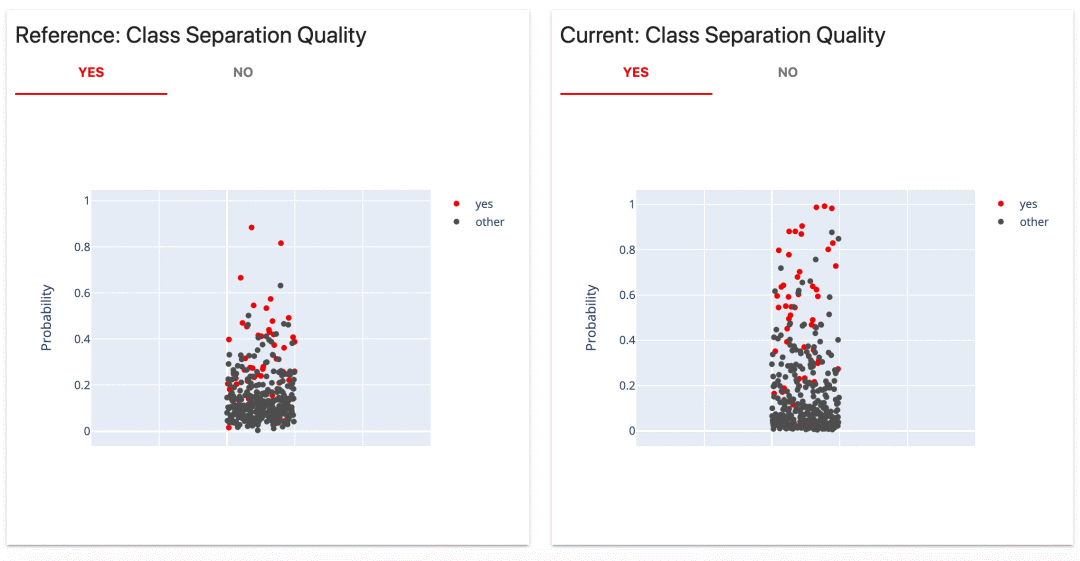
我們可以看到,第一個模型做出了幾個非常自信的預(yù)測。稍微 "上調(diào)"或 "下調(diào)"閾值,在絕對數(shù)字上不會有太大的差別。
然而,我們可能會欣賞一個模型,并挑選出幾個具有高置信度的案例的能力。例如,如果我們認(rèn)為假陽性的成本非常高。在0.8處做一個分界點,就能得到100%的精度。我們只做兩個預(yù)測,但都是正確的。
如果這是我們喜歡的行為,我們可以從開始就設(shè)計這樣一個 "決定性 "的模型,它將強(qiáng)烈地懲罰假陽性,并在概率范圍的中間做出較少的預(yù)測。(事實上,這正是我們在這個演示中所做的!)。
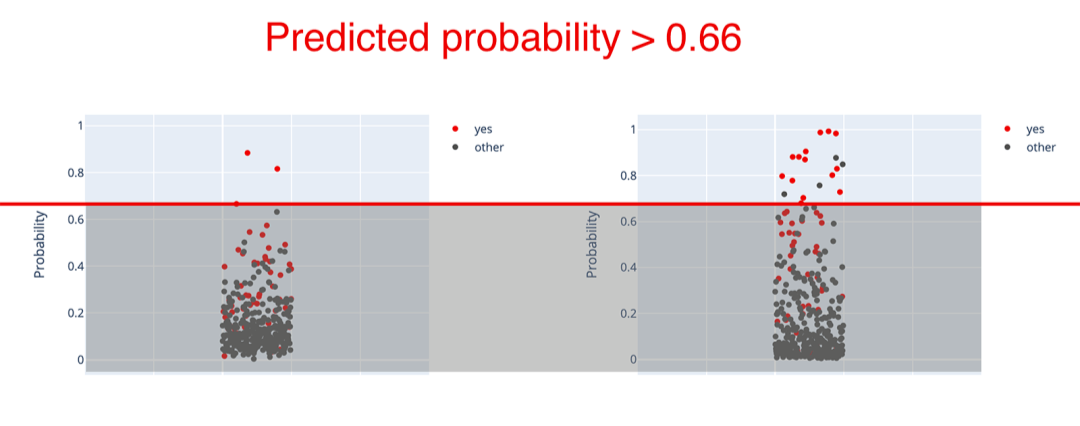
第二個模型的預(yù)測概率比較分散。改變閾值會產(chǎn)生不同的情況。我們只需看一下圖示,就能做出大致的估計。例如,如果我們將閾值設(shè)置為0.8,就會讓我們只剩下幾個假陽性。
更具體地說,讓我們看看精度-召回表。它旨在類似情況下選擇閾值。它顯示了top-X預(yù)測的不同情況。

例如,我們可以只對第二個模型的前5%的預(yù)測采取行動。在測試集上,它對應(yīng)的概率閾值為66%。所有預(yù)測概率較高的員工都被認(rèn)為有可能離職。
在這種情況下,只剩下18個預(yù)測。但其中14個將是正確的!召回率下降到只有23.7%,但現(xiàn)在的精度是77.8%。我們可能更喜歡它,而不是原來的69%精度,以盡量減少誤報。
為了簡化概念,我們可以想象一下類別分離圖上的一條線。
在實踐中,我們可以通過以下兩種方式之一進(jìn)行限制:
只對topX預(yù)測采取行動
將所有概率大于 X 的預(yù)測分配給正類。
第一種方案可用于批量模型。如果我們一次生成所有員工的預(yù)測,我們可以對它們進(jìn)行分類,比如說,前5%。
如果我們根據(jù)要求進(jìn)行個別預(yù)測,那么選取一個自定義的概率閾值是有意義的。
這兩種方法中的任何一種都可以工作,這取決于具體用例。
我們也可以決定用不同的方式來可視化標(biāo)簽。例如,將每個員工標(biāo)記為高、中、低流失風(fēng)險。這將需要基于預(yù)測概率的多個閾值。
在這種情況下,我們會額外關(guān)注模型校準(zhǔn)的質(zhì)量,這一點從類別分離圖上可以看出。
綜上所述,我們會考慮精度-召回率的權(quán)衡來評估我們的模型,并選擇應(yīng)用場景。
我們不顯示每個人的預(yù)測,而是選擇一個閾值。它幫助我們只關(guān)注流失風(fēng)險最高的員工。
示例3:有選擇地應(yīng)用模型
我們還可以采取第三種方法。
當(dāng)看到兩個模型的不同圖譜時,一個明顯的問題出現(xiàn)了。圖上的小點背后的具體員工是誰?兩種模型在預(yù)測來自不同角色、部門、經(jīng)驗水平的辭職者時有什么不同?
這種分析可能會幫助我們決定什么時候應(yīng)用模型,什么時候不應(yīng)用模型。如果有明顯的細(xì)分市場,模型失效,我們可以將其排除。或者反過來說,我們可以只在模型表現(xiàn)好的地方應(yīng)用模型。
在界面中,我們可以顯示 "信息不足 "這樣的內(nèi)容。這可能比一直錯誤要好!

低性能部分
為了更深入地了解表現(xiàn)不佳的片段,我們來分析一下分類質(zhì)量表(Classification Quality Table)。對于每個特征,它將預(yù)測的概率與特征值一起映射。
這樣,我們就可以看到模型在哪些方面犯了錯誤,以及它們是否依賴于單個特征的值。
我們舉個例子。
這里有一個工作等級(Job Level)特征,它是角色資歷的特定屬性。

如果我們對1級的員工最感興趣,那么第一個模型可能是一個不錯的選擇!它能以高概率做出一些有把握的預(yù)測。例如,在0.6的閾值下,它在這個群體中只有一個假陽性。
如果我們想預(yù)測3級的辭職情況,第二個模型看起來要好得多。
如果我們希望我們的模型對所有級別都有效,我們可能會再次選擇第二個模型。平均而言,它在1、2、3級中的表現(xiàn)可以接受。
但同樣有趣的是,這兩個模型在第4級和第5級上的表現(xiàn)**。**對這些群體中的員工做出的所有預(yù)測,概率都明顯低于0.5。兩種模型總是分配一個 "負(fù)"的標(biāo)簽。
如果我們看一下真實標(biāo)簽的分布,我們可以看到,在這些工作級別中,辭職的絕對數(shù)量相當(dāng)?shù)汀:苡锌赡茉谟?xùn)練中也是如此,模型并沒有發(fā)現(xiàn)任何有用的模式。
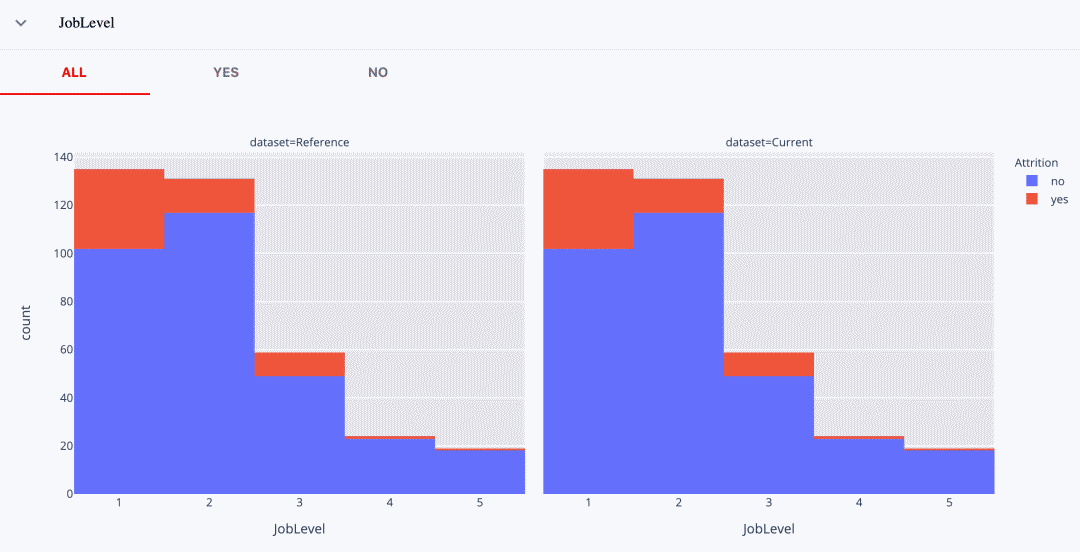
由于我們比較的是同一測試數(shù)據(jù)集上的性能,所以分布是相同的。
如果我們要在生產(chǎn)中部署一個模型,我們可以構(gòu)建一個簡單的業(yè)務(wù)規(guī)則,將這些片段(segments)從應(yīng)用中排除。
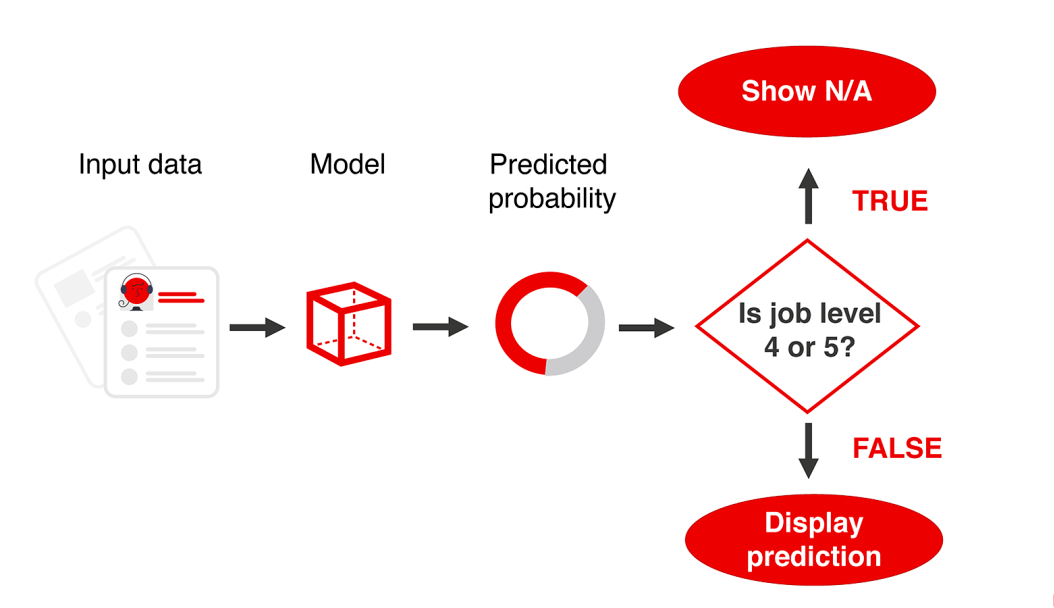
我們也可以利用這個分析的結(jié)果,把我們的模型放在一個 "性能改進(jìn)計劃"上。也許,我們可以添加更多的數(shù)據(jù)來幫助模型。
例如,我們可能有一些 "舊的"數(shù)據(jù),而這些數(shù)據(jù)是我們最初從訓(xùn)練中排除的。我們可以有選擇地增強(qiáng)訓(xùn)練數(shù)據(jù)集,用于表現(xiàn)不佳的部分。在這種情況下,我們會添加更多關(guān)于4級和5級員工辭職的舊數(shù)據(jù)。
綜上所述,我們可以識別出模型失敗的特定細(xì)分片段,我們?nèi)匀伙@示出對盡可能多的員工的預(yù)測。但知道模型遠(yuǎn)非完美,我們只對表現(xiàn)最好的那部分員工進(jìn)行應(yīng)用。
模型知道什么?
這張表同樣可以幫助我們更詳細(xì)地了解模型的行為。我們可以探索誤差、離群值,并了解模型的學(xué)習(xí)情況。
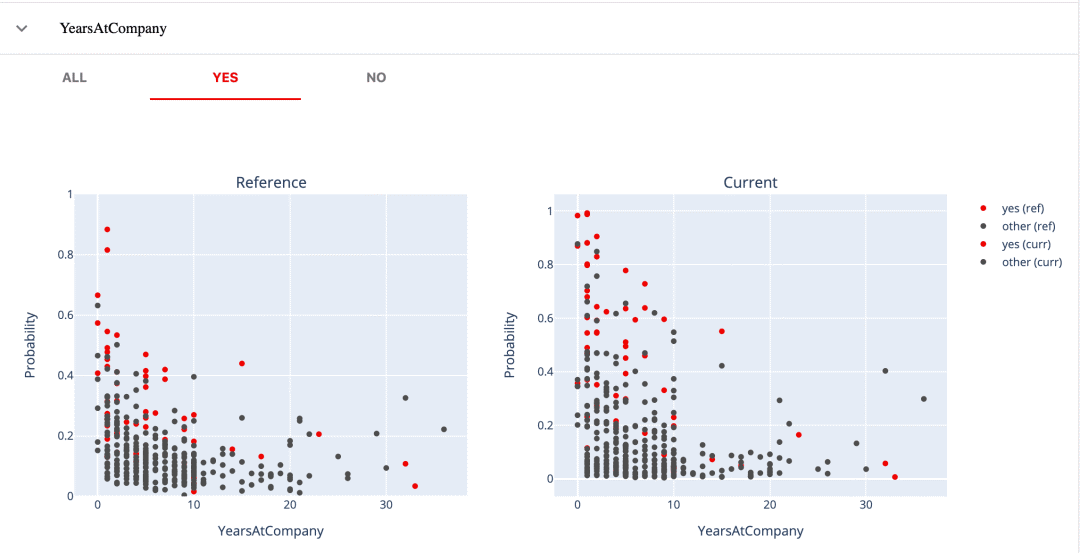
例如,我們已經(jīng)看到,第一個模型只預(yù)測了少數(shù)有把握的辭職。第二個模型從我們的數(shù)據(jù)中 "捕捉"到了更多有用的信號。它是從哪里來的呢?
如果通過我們的特征,可以得到一個提示。
比如說,第一個模型只成功預(yù)測了那些相對新進(jìn)公司的人的辭職,第二個模型可以檢測出有10年以下工作經(jīng)驗的潛在離職者。我們可以從這個圖中看到。
我們可以從股票期權(quán)等級(stock options level)中看到類似的情況。
第一個模型只成功預(yù)測了0級的員工。即使我們有不少重新加入的員工,至少也是1級的!第二種模型捕獲到了更多等級較高的離職者。

但如果我們看加薪(即最近的加薪),我們會發(fā)現(xiàn)沒有明顯的細(xì)分,無論哪個模型的效果都更好或更差。
除了第一種模型的一般特征外,并沒有具體的 "傾斜",做出較少的置信預(yù)測。

類似的分析可以幫助在模型之間進(jìn)行選擇,或者找到改進(jìn)模型的方法。
就像上面工作級別的例子一樣,我們可能有辦法來增強(qiáng)我們的數(shù)據(jù)集。我們可能會添加其他時期的數(shù)據(jù),或者包含更多的特征。在類別不平衡的情況下,我們可以嘗試給特定例子更多的權(quán)重。作為最后的手段,我們也可以添加業(yè)務(wù)規(guī)則。
我們找到了贏家!
回到我們的例子:第二種模式是大多數(shù)情況下的贏家。

但誰會只看ROC AUC就被信服了呢?我們必須超越單一的指標(biāo)來深入評估模型。
它適用于許多其他用例。性能比準(zhǔn)確度更重要。而且并非總是可以為每種錯誤類型分配簡單的"成本"來對其進(jìn)行優(yōu)化。像對待產(chǎn)品一樣對待模型,分析必須更加細(xì)致入微。
關(guān)鍵是不要忽視用例場景,并將我們的標(biāo)準(zhǔn)與之掛鉤。可視化可能有助于那些不以ROC AUC思考的業(yè)務(wù)相關(guān)者進(jìn)行溝通。
提示:本教程不用于辭職預(yù)測,而是模型分析
如果你想解決類似的用例,我們至少要指出這個數(shù)據(jù)集的幾個限制。
我們?nèi)狈σ粋€關(guān)鍵的數(shù)據(jù)點:辭職的類型。人們可以自愿離職、被解雇、退休、搬到全國各地等等。這些都是不同的事件,將它們歸為一類可能會造成模糊的標(biāo)簽。如果把重點放在 "可預(yù)測"的辭職類型上,或者解決多類問題來代替,會比較合理。
關(guān)于所從事的工作,沒有足夠的上下文。一些其他數(shù)據(jù)可能會更好地表明流失情況:績效評估、特定項目、晉升規(guī)劃等。這種用例需要與領(lǐng)域?qū)<乙黄鹁臉?gòu)建訓(xùn)練數(shù)據(jù)集。
沒有關(guān)于時間和辭職日期的數(shù)據(jù)。我們無法說明事件的順序,并與公司歷史上的特定時期有關(guān)。
最后提醒一點:像這樣的用例可能是高度敏感的。
你可能會使用類似的模型來預(yù)測一線人員的流動率。目標(biāo)是預(yù)測招聘部門的工作量和相關(guān)的招聘需求。不正確的預(yù)測可能會導(dǎo)致一些財務(wù)風(fēng)險,但這些很容易考慮進(jìn)去。
但如果該模型用于支持對單個員工的決策,其影響可能會更加關(guān)鍵。例如,考慮分配培訓(xùn)機(jī)會時的偏差。我們應(yīng)該評估使用案例的道德規(guī)范(the ethics of the use case),并審核我們的數(shù)據(jù)和模型是否存在偏見和公平(bias and fairness)。
參考鏈接:
本文所用數(shù)據(jù)集地址:https://www.kaggle.com/pavansubhasht/ibm-hr-analytics-attrition-dataset Evidently開源庫:https://github.com/evidentlyai/evidently Jupyter notebook地址:https://github.com/evidentlyai/evidently/blob/main/evidently/examples/ibm_hr_attrition_model_validation.ipynb 原文地址:https://evidentlyai.com/blog/tutorial-2-model-evaluation-hr-attrition
往期精彩回顧
本站qq群851320808,加入微信群請掃碼: