
【機器學習基礎】淺析機器學習集成學習與模型融合
對比過kaggle比賽上面的top10的模型,除了深度學習以外的模型基本上都是集成學習的產(chǎn)物。集成學習可謂是上分大殺器,今天就跟大家分享在Kaggle或者阿里天池上面大殺四方的數(shù)據(jù)科學比賽利器---集成學習。
一、什么是集成學習
正所謂“三個臭皮匠賽過諸葛亮”的道理,在機器學習數(shù)據(jù)挖掘的工程項目中,使用單一決策的弱分類器顯然不是一個明智的選擇,因為各種分類器在設計的時候都有自己的優(yōu)勢和缺點,也就是說每個分類器都有自己工作偏向,那集成學習就是平衡各個分類器的優(yōu)缺點,使得我們的分類任務完成的更加優(yōu)秀。 在大多數(shù)情況下,這些基本模型本身的性能并不是非常好,這要么是因為它們具有較高的偏差(例如,低自由度模型),要么是因為他們的方差太大導致魯棒性不強(例如,高自由度模型)。集成方法的思想是通過將這些弱學習器的偏差和/或方差結合起來,從而創(chuàng)建一個「強學習器」(或「集成模型」),從而獲得更好的性能。
集成學習的方法:
1. 基于投票思想的多數(shù)票機制的集成分類器(MajorityVoteClassifier) 2. 于bagging思想的套袋集成技術(BaggingClassifier) 3. 基于boosting思想的自適應增強方法(Adaboost) 4. 分層模型集成框架stacking(疊加算法)
二、基于投票思想的集成分類器
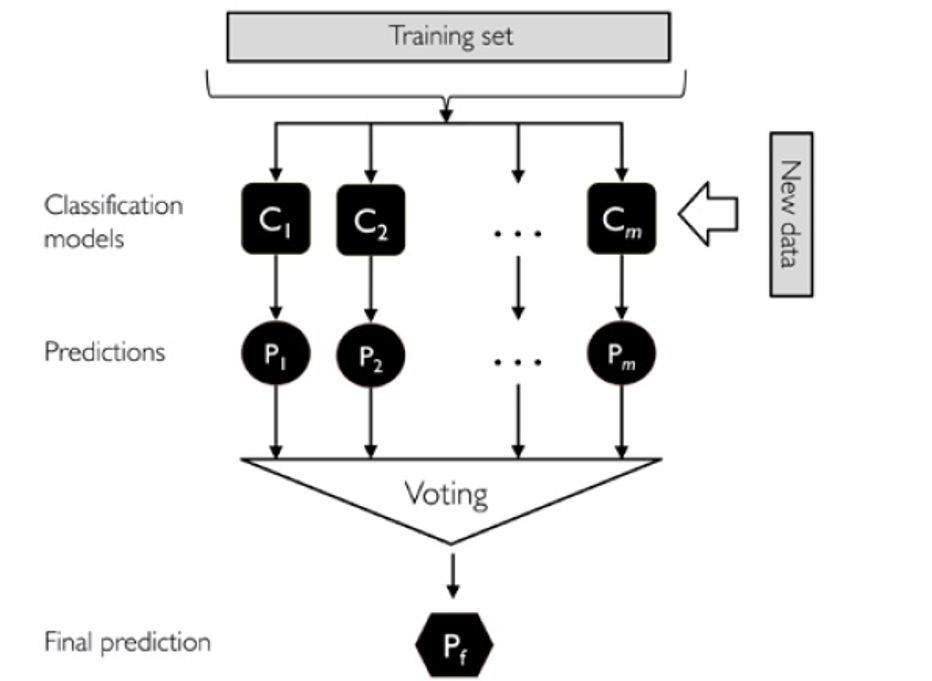
以上是多數(shù)投票的流程圖:
分別訓練n個弱分類器。 對每個弱分類器輸出預測結果,并投票(如下圖) 每個樣本取投票數(shù)最多的那個預測為該樣本最終分類預測。

加載相關庫:
## 加載相關庫
from sklearn.datasets import load_iris # 加載數(shù)據(jù)
from sklearn.model_selection import train_test_split # 切分訓練集與測試集
from sklearn.preprocessing import StandardScaler # 標準化數(shù)據(jù)
from sklearn.preprocessing import LabelEncoder # 標簽化分類變量
初步處理數(shù)據(jù)
## 初步處理數(shù)據(jù)
iris = load_iris()
X,y = iris.data[50:,[1,2]],iris.target[50:]
le = LabelEncoder()
y = le.fit_transform(y)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.5,random_state=1,stratify=y)
我們使用訓練集訓練三種不同的分類器:邏輯回歸 + 決策樹 + k-近鄰分類器
## 我們使用訓練集訓練三種不同的分類器:邏輯回歸 + 決策樹 + k-近鄰分類器
from sklearn.model_selection import cross_val_score # 10折交叉驗證評價模型
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import Pipeline # 管道簡化工作流
clf1 = LogisticRegression(penalty='l2',C=0.001,random_state=1)
clf2 = DecisionTreeClassifier(max_depth=1,criterion='entropy',random_state=0)
clf3 = KNeighborsClassifier(n_neighbors=1,p=2,metric="minkowski")
pipe1 = Pipeline([['sc',StandardScaler()],['clf',clf1]])
pipe3 = Pipeline([['sc',StandardScaler()],['clf',clf3]])
clf_labels = ['Logistic regression','Decision tree','KNN']
print('10-folds cross validation :\n')
for clf,label in zip([pipe1,clf2,pipe3],clf_labels):
scores = cross_val_score(estimator=clf,X=X_train,y=y_train,cv=10,scoring='roc_auc')
print("ROC AUC: %0.2f(+/- %0.2f)[%s]"%(scores.mean(),scores.std(),label))
我們使用MajorityVoteClassifier集成:
## 我們使用MajorityVoteClassifier集成:
from sklearn.ensemble import VotingClassifier
mv_clf = VotingClassifier(estimators=[('pipe1',pipe1),('clf2',clf2),('pipe3',pipe3)],voting='soft')
clf_labels += ['MajorityVoteClassifier']
all_clf = [pipe1,clf2,pipe3,mv_clf]
print('10-folds cross validation :\n')
for clf,label in zip(all_clf,clf_labels):
scores = cross_val_score(estimator=clf,X=X_train,y=y_train,cv=10,scoring='roc_auc')
print("ROC AUC: %0.2f(+/- %0.2f)[%s]"%(scores.mean(),scores.std(),label))
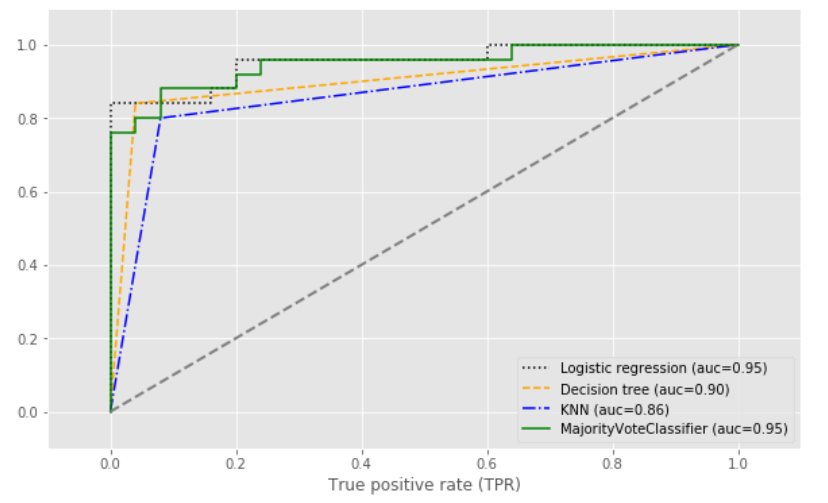
## 對比下面結果,可以得知多數(shù)投票方式的分類算法,抗差能力更強。

使用ROC曲線評估集成分類器:
## 使用ROC曲線評估集成分類器
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
colors = ['black','orange','blue','green']
linestyles = [':','--','-.','-']
plt.figure(figsize=(10,6))
for clf,label,clr,ls in zip(all_clf,clf_labels,colors,linestyles):
y_pred = clf.fit(X_train,y_train).predict_proba(X_test)[:,1]
fpr,tpr,trhresholds = roc_curve(y_true=y_test,y_score=y_pred)
roc_auc = auc(x=fpr,y=tpr)
plt.plot(fpr,tpr,color=clr,linestyle=ls,label='%s (auc=%0.2f)'%(label,roc_auc))
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],linestyle='--',color='gray',linewidth=2)
plt.xlim([-0.1,1.1])
plt.ylim([-0.1,1.1])
plt.xlabel('False positive rate (FPR)')
plt.xlabel('True positive rate (TPR)')
plt.show()
三、基于bagging思想的套袋集成技術
套袋方法是由柳.布萊曼在1994年的技術報告中首先提出并證明了套袋方法可以提高不穩(wěn)定模型的準確度的同時降低過擬合的程度(可降低方差)。
套袋方法的流程如下:
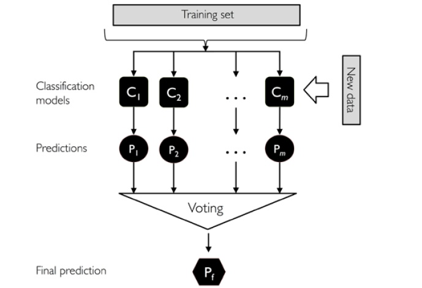
注意:套袋方法與投票方法的不同:
投票機制在訓練每個分類器的時候都是用相同的全部樣本,而Bagging方法則是使用全部樣本的一個隨機抽樣,每個分類器都是使用不同的樣本進行訓練。其他都是跟投票方法一模一樣!
對訓練集隨機采樣 分別基于不同的樣本集合訓練n個弱分類器。 對每個弱分類器輸出預測結果,并投票(如下圖) 每個樣本取投票數(shù)最多的那個預測為該樣本最終分類預測。

我們使用葡萄酒數(shù)據(jù)集進行建模(數(shù)據(jù)處理):
## 我們使用葡萄酒數(shù)據(jù)集進行建模(數(shù)據(jù)處理)
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)
df_wine.columns = ['Class label', 'Alcohol','Malic acid', 'Ash','Alcalinity of ash','Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols','Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']
df_wine = df_wine[df_wine['Class label'] != 1] # drop 1 class
y = df_wine['Class label'].values
X = df_wine[['Alcohol','OD280/OD315 of diluted wines']].values
from sklearn.model_selection import train_test_split # 切分訓練集與測試集
from sklearn.preprocessing import LabelEncoder # 標簽化分類變量
le = LabelEncoder()
y = le.fit_transform(y)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y)
我們使用單一決策樹分類:
## 我們使用單一決策樹分類:
tree = DecisionTreeClassifier(criterion='entropy',random_state=1,max_depth=None) #選擇決策樹為基本分類器
from sklearn.metrics import accuracy_score
tree = tree.fit(X_train,y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pred)
tree_test = accuracy_score(y_test,y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))

我們使用BaggingClassifier分類:
## 我們使用BaggingClassifier分類:
from sklearn.ensemble import BaggingClassifier
tree = DecisionTreeClassifier(criterion='entropy',random_state=1,max_depth=None) #選擇決策樹為基本分類器
bag = BaggingClassifier(base_estimator=tree,n_estimators=500,max_samples=1.0,max_features=1.0,bootstrap=True,
bootstrap_features=False,n_jobs=1,random_state=1)
from sklearn.metrics import accuracy_score
bag = bag.fit(X_train,y_train)
y_train_pred = bag.predict(X_train)
y_test_pred = bag.predict(X_test)
bag_train = accuracy_score(y_train,y_train_pred)
bag_test = accuracy_score(y_test,y_test_pred)
print('Bagging train/test accuracies %.3f/%.3f' % (bag_train,bag_test))

我們可以對比兩個準確率,測試準確率較之決策樹得到了顯著的提高
我們來對比下這兩個分類方法上的差異:
## 我們來對比下這兩個分類方法上的差異
x_min = X_train[:, 0].min() - 1
x_max = X_train[:, 0].max() + 1
y_min = X_train[:, 1].min() - 1
y_max = X_train[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=1, ncols=2,sharex='col',sharey='row',figsize=(12, 6))
for idx, clf, tt in zip([0, 1],[tree, bag],['Decision tree', 'Bagging']):
clf.fit(X_train, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train==0, 0],X_train[y_train==0, 1],c='blue', marker='^')
axarr[idx].scatter(X_train[y_train==1, 0],X_train[y_train==1, 1],c='green', marker='o')
axarr[idx].set_title(tt)
axarr[0].set_ylabel('Alcohol', fontsize=12)
plt.tight_layout()
plt.text(0, -0.2,s='OD280/OD315 of diluted wines',ha='center',va='center',fontsize=12,transform=axarr[1].transAxes)
plt.show()
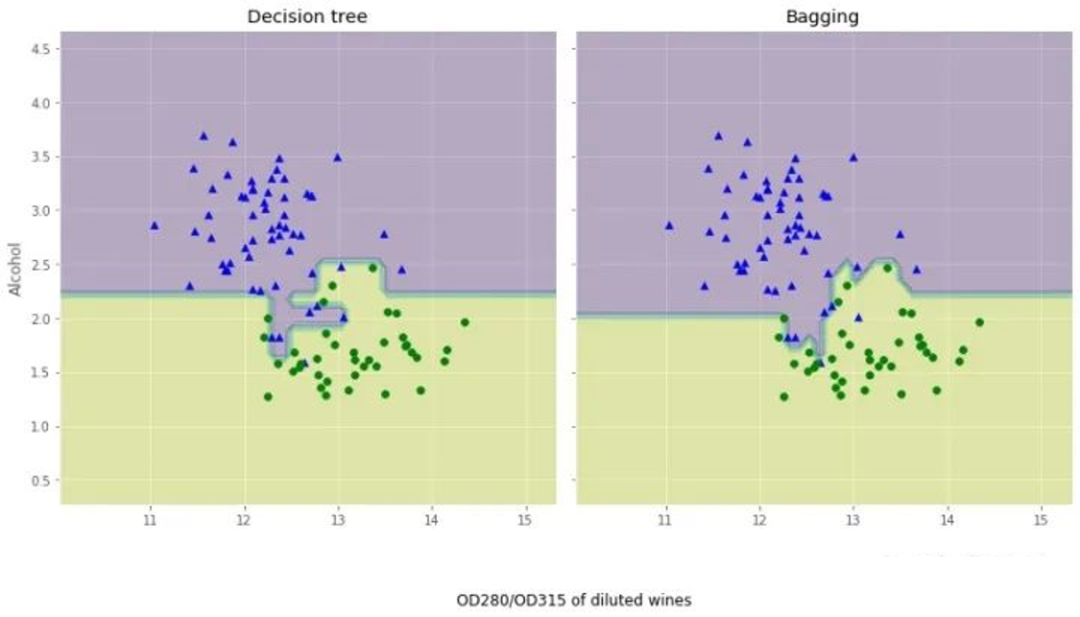
從結果圖看起來,三個節(jié)點深度的決策樹分段線性決策邊界在Bagging集成中看起來更加平滑。
四、基于boosting思想的自適應增強方法
Adaboost最初的想法是由Robert E. Schapire在1990年提出的,這個想法叫做自適應增強方法。
與Bagging相比,Boosting思想可以降低偏差。
原始的增強過程具體的實現(xiàn)如下:

AdaBoost的具體步驟如下:

如更新權重如下圖:
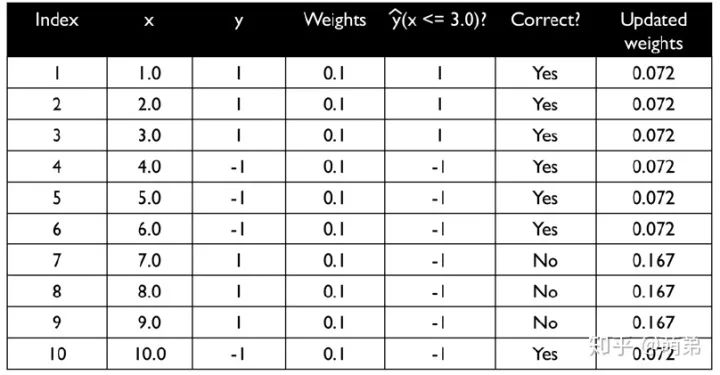
我們用單一決策樹建模:
## 我們用單一決策樹建模:
from sklearn.ensemble import AdaBoostClassifier
tree = DecisionTreeClassifier(criterion='entropy',random_state=1,max_depth=1)
from sklearn.metrics import accuracy_score
tree = tree.fit(X_train,y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pred)
tree_test = accuracy_score(y_test,y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))

我們使用Adaboost集成建模:
## 我們使用Adaboost集成建模:
ada = AdaBoostClassifier(base_estimator=tree,n_estimators=500,learning_rate=0.1,random_state=1)
ada = ada.fit(X_train,y_train)
y_train_pred = ada.predict(X_train)
y_test_pred = ada.predict(X_test)
ada_train = accuracy_score(y_train,y_train_pred)
ada_test = accuracy_score(y_test,y_test_pred)
print('Adaboost train/test accuracies %.3f/%.3f' % (ada_train,ada_test))

我們觀察下Adaboost與決策樹的異同:
## 我們觀察下Adaboost與決策樹的異同
x_min = X_train[:, 0].min() - 1
x_max = X_train[:, 0].max() + 1
y_min = X_train[:, 1].min() - 1
y_max = X_train[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=1, ncols=2,sharex='col',sharey='row',figsize=(12, 6))
for idx, clf, tt in zip([0, 1],[tree, ada],['Decision tree', 'Adaboost']):
clf.fit(X_train, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train==0, 0],X_train[y_train==0, 1],c='blue', marker='^')
axarr[idx].scatter(X_train[y_train==1, 0],X_train[y_train==1, 1],c='red', marker='o')
axarr[idx].set_title(tt)
axarr[0].set_ylabel('Alcohol', fontsize=12)
plt.tight_layout()
plt.text(0, -0.2,s='OD280/OD315 of diluted wines',ha='center',va='center',fontsize=12,transform=axarr[1].transAxes)
plt.show()
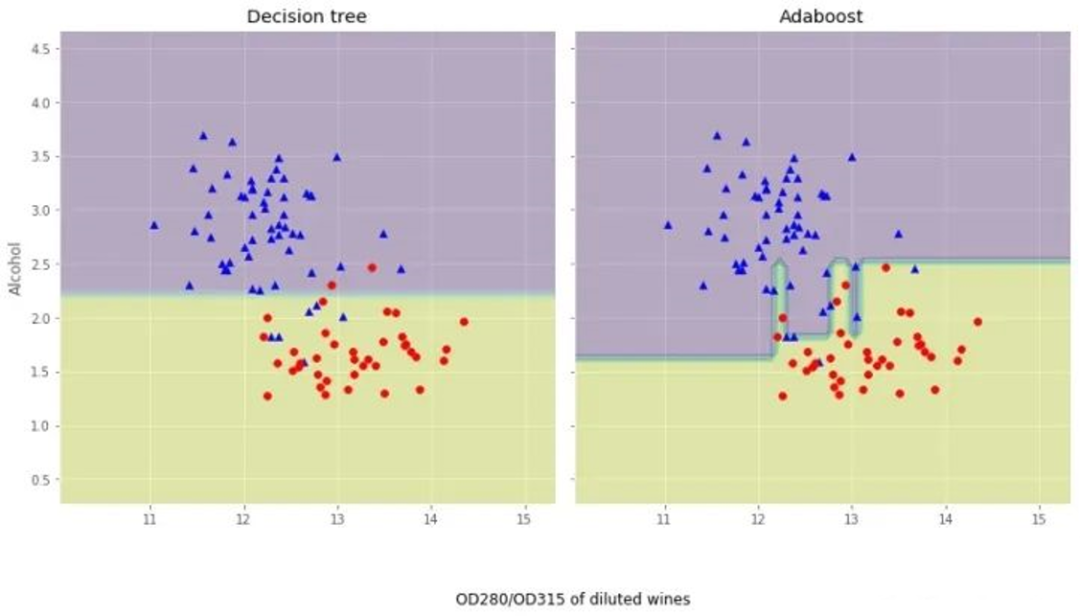
從結果圖看起來,Adaboost決策邊界比單層決策樹復雜得多!
五、分層模型集成框架stacking(疊加算法)
Stacking集成算法可以理解為一個兩層的集成,第一層含有一個分類器,把預測的結果(元特征)提供給第二層, 而第二層的分類器通常是邏輯回歸,他把一層分類器的結果當做特征做擬合輸出預測結果。過程如下圖:

標準的Stacking,也叫Blending如下圖:
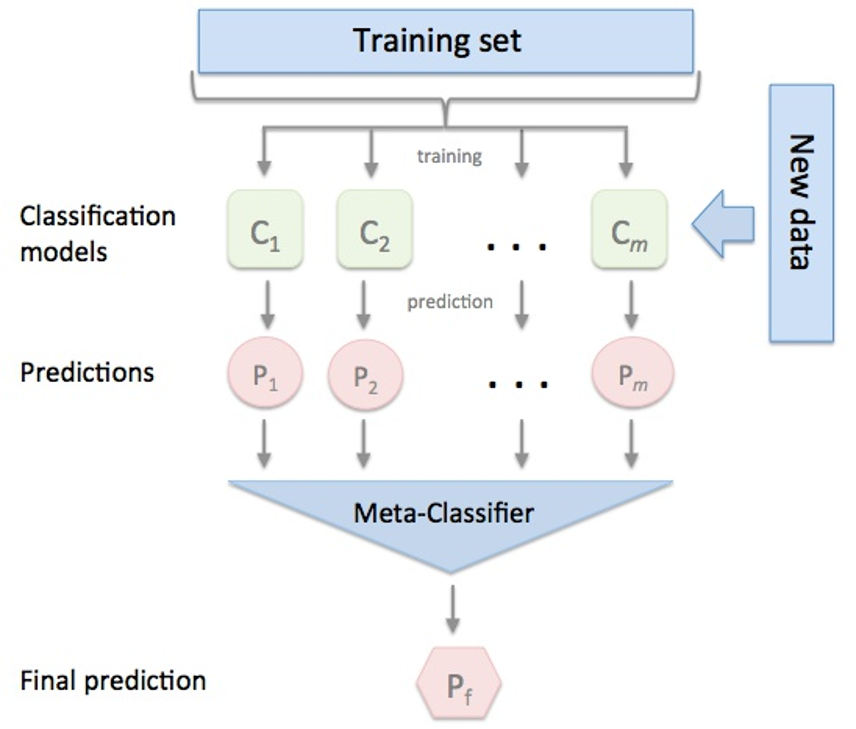
但是,標準的Stacking會導致信息泄露,所以推薦以下Satcking算法:
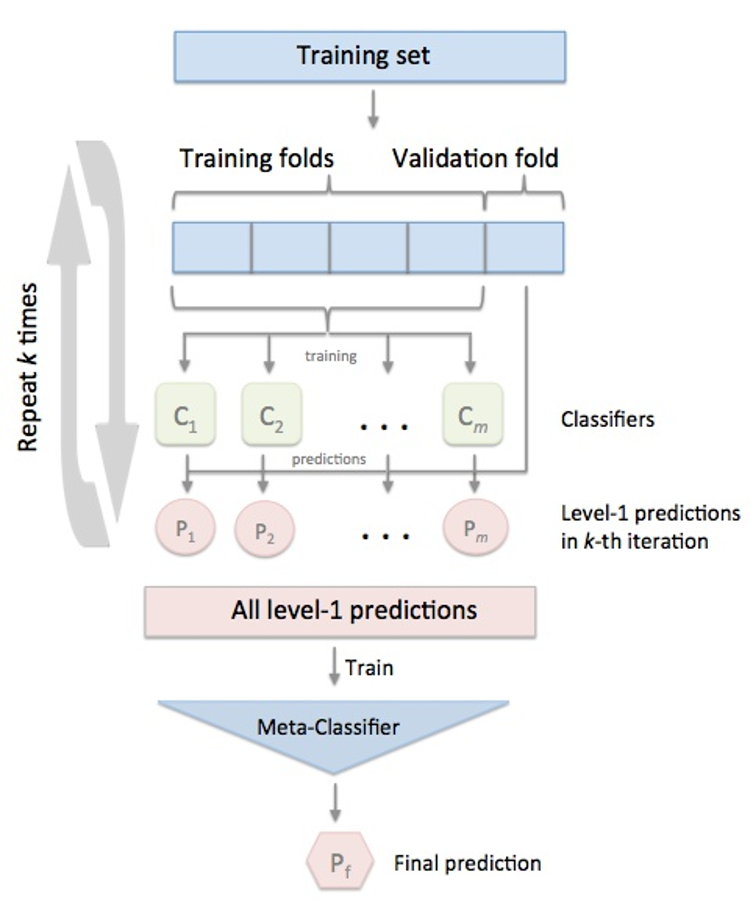
由于目前sklearn沒有Stacking相關的類,因此我們使用mlxtend庫!!!!
詳細代碼內容查看:
http://rasbt.github.io/mlxtend/user_guide/classifier/StackingClassifier/
http://rasbt.github.io/mlxtend/user_guide/classifier/StackingCVClassifier/
1. 簡單堆疊3折CV分類:
## 1. 簡單堆疊3折CV分類
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingCVClassifier
RANDOM_SEED = 42
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=RANDOM_SEED)
clf3 = GaussianNB()
lr = LogisticRegression()
# Starting from v0.16.0, StackingCVRegressor supports
# `random_state` to get deterministic result.
sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3], # 第一層分類器
meta_classifier=lr, # 第二層分類器
random_state=RANDOM_SEED)
print('3-fold cross validation:\n')
for clf, label in zip([clf1, clf2, clf3, sclf], ['KNN', 'Random Forest', 'Naive Bayes','StackingClassifier']):
scores = cross_val_score(clf, X, y, cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
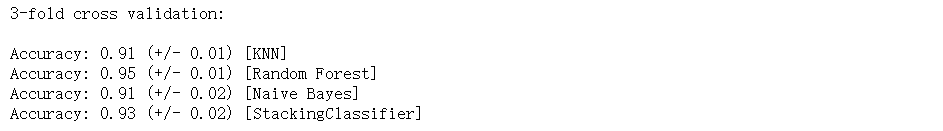
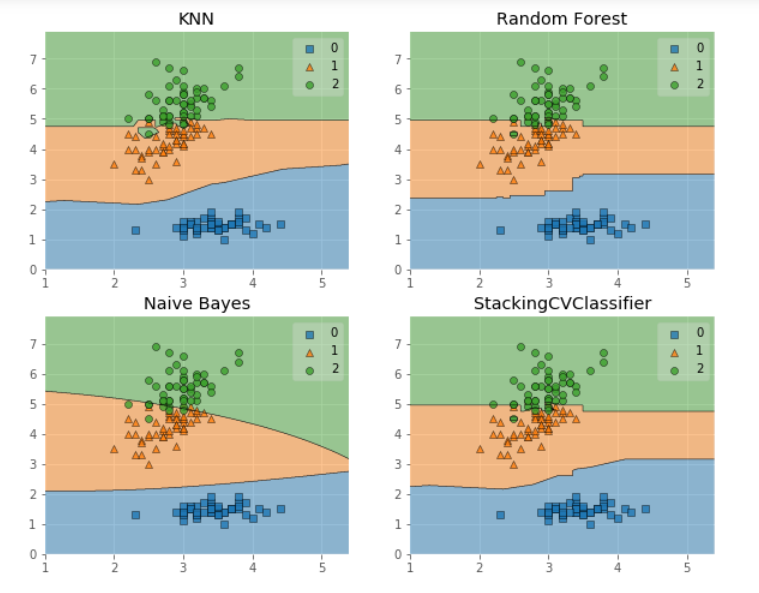
我們畫出決策邊界:
## 我們畫出決策邊界
from mlxtend.plotting import plot_decision_regions
import matplotlib.gridspec as gridspec
import itertools
gs = gridspec.GridSpec(2, 2)
fig = plt.figure(figsize=(10,8))
for clf, lab, grd in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingCVClassifier'],
itertools.product([0, 1], repeat=2)):
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf)
plt.title(lab)
plt.show()
2.使用概率作為元特征:
## 2.使用概率作為元特征
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3],
use_probas=True,
meta_classifier=lr,
random_state=42)
print('3-fold cross validation:\n')
for clf, label in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingClassifier']):
scores = cross_val_score(clf, X, y,
cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))

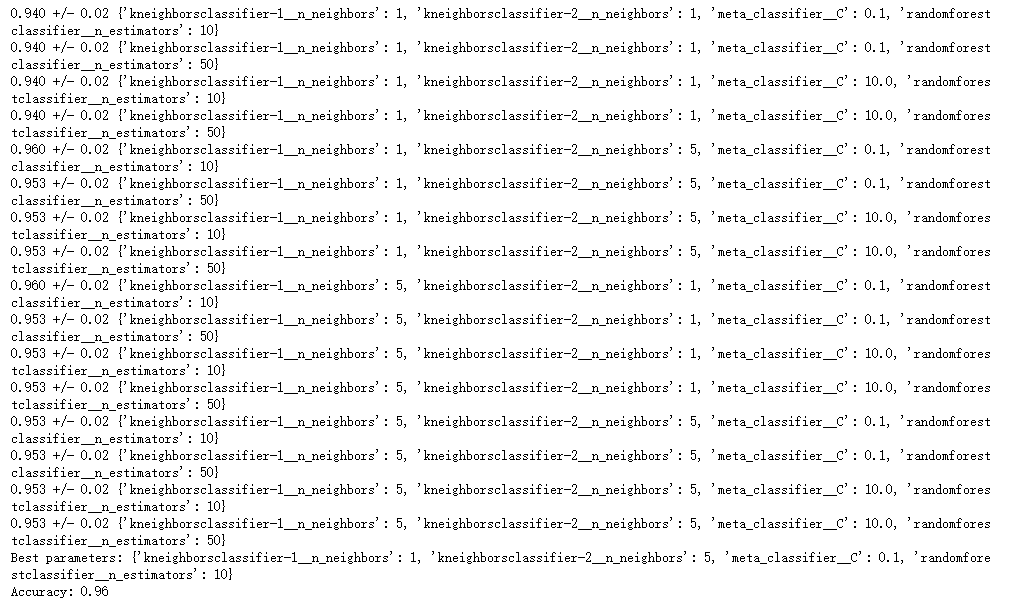
3. 堆疊5折CV分類與網(wǎng)格搜索(結合網(wǎng)格搜索調參優(yōu)化):
## 3. 堆疊5折CV分類與網(wǎng)格搜索(結合網(wǎng)格搜索調參優(yōu)化)
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from mlxtend.classifier import StackingCVClassifier
# Initializing models
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=RANDOM_SEED)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr,
random_state=42)
params = {'kneighborsclassifier__n_neighbors': [1, 5],
'randomforestclassifier__n_estimators': [10, 50],
'meta_classifier__C': [0.1, 10.0]}
grid = GridSearchCV(estimator=sclf,
param_grid=params,
cv=5,
refit=True)
grid.fit(X, y)
cv_keys = ('mean_test_score', 'std_test_score', 'params')
for r, _ in enumerate(grid.cv_results_['mean_test_score']):
print("%0.3f +/- %0.2f %r"
% (grid.cv_results_[cv_keys[0]][r],
grid.cv_results_[cv_keys[1]][r] / 2.0,
grid.cv_results_[cv_keys[2]][r]))
print('Best parameters: %s' % grid.best_params_)
print('Accuracy: %.2f' % grid.best_score_)

如果我們打算多次使用回歸算法,我們要做的就是在參數(shù)網(wǎng)格中添加一個附加的數(shù)字后綴,如下所示:
## 如果我們打算多次使用回歸算法,我們要做的就是在參數(shù)網(wǎng)格中添加一個附加的數(shù)字后綴,如下所示:
from sklearn.model_selection import GridSearchCV
# Initializing models
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=RANDOM_SEED)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingCVClassifier(classifiers=[clf1, clf1, clf2, clf3],
meta_classifier=lr,
random_state=RANDOM_SEED)
params = {'kneighborsclassifier-1__n_neighbors': [1, 5],
'kneighborsclassifier-2__n_neighbors': [1, 5],
'randomforestclassifier__n_estimators': [10, 50],
'meta_classifier__C': [0.1, 10.0]}
grid = GridSearchCV(estimator=sclf,
param_grid=params,
cv=5,
refit=True)
grid.fit(X, y)
cv_keys = ('mean_test_score', 'std_test_score', 'params')
for r, _ in enumerate(grid.cv_results_['mean_test_score']):
print("%0.3f +/- %0.2f %r"
% (grid.cv_results_[cv_keys[0]][r],
grid.cv_results_[cv_keys[1]][r] / 2.0,
grid.cv_results_[cv_keys[2]][r]))
print('Best parameters: %s' % grid.best_params_)
print('Accuracy: %.2f' % grid.best_score_)
4.在不同特征子集上運行的分類器的堆疊:
## 4.在不同特征子集上運行的分類器的堆疊
###不同的1級分類器可以適合訓練數(shù)據(jù)集中的不同特征子集。以下示例說明了如何使用scikit-learn管道和ColumnSelector:
from sklearn.datasets import load_iris
from mlxtend.classifier import StackingCVClassifier
from mlxtend.feature_selection import ColumnSelector
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
iris = load_iris()
X = iris.data
y = iris.target
pipe1 = make_pipeline(ColumnSelector(cols=(0, 2)), # 選擇第0,2列
LogisticRegression())
pipe2 = make_pipeline(ColumnSelector(cols=(1, 2, 3)), # 選擇第1,2,3列
LogisticRegression())
sclf = StackingCVClassifier(classifiers=[pipe1, pipe2],
meta_classifier=LogisticRegression(),
random_state=42)
sclf.fit(X, y)

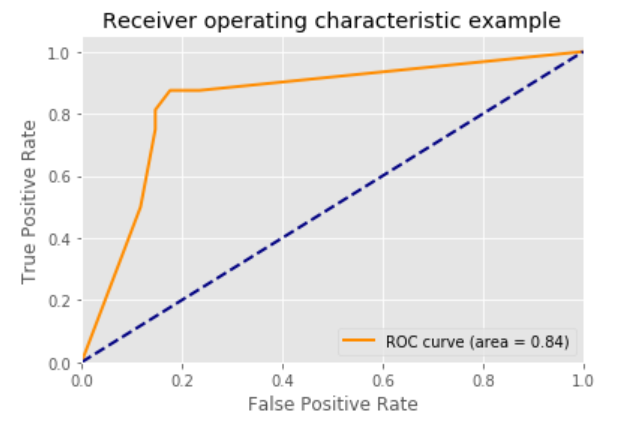
5.ROC曲線 decision_function:
## 5.ROC曲線 decision_function
### 像其他scikit-learn分類器一樣,它StackingCVClassifier具有decision_function可用于繪制ROC曲線的方法。
### 請注意,decision_function期望并要求元分類器實現(xiàn)decision_function。
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingCVClassifier
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
iris = datasets.load_iris()
X, y = iris.data[:, [0, 1]], iris.target
# Binarize the output
y = label_binarize(y, classes=[0, 1, 2])
n_classes = y.shape[1]
RANDOM_SEED = 42
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=RANDOM_SEED)
clf1 = LogisticRegression()
clf2 = RandomForestClassifier(random_state=RANDOM_SEED)
clf3 = SVC(random_state=RANDOM_SEED)
lr = LogisticRegression()
sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr)
# Learn to predict each class against the other
classifier = OneVsRestClassifier(sclf)
y_score = classifier.fit(X_train, y_train).decision_function(X_test)
# Compute ROC curve and ROC area for each class
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# Compute micro-average ROC curve and ROC area
fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_score.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
plt.figure()
lw = 2
plt.plot(fpr[2], tpr[2], color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc[2])
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
往期精彩回顧
獲取一折本站知識星球優(yōu)惠券,復制鏈接直接打開:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群請掃碼進群(如果是博士或者準備讀博士請說明):