
為什么你的顯卡利用率總是0%?

極市導(dǎo)讀
本文通過提高數(shù)據(jù)讀取、預(yù)處理速度,以便讓GPU保持99%算力。 >>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿
為啥GPU利用率總是這么低
榨干GPU的顯存,使模型成功跑起來已有多種教程。但是,又一個問題來了,GPU的利用率總是一會99%,一會10%,就不能一直99%榨干算力?導(dǎo)致算力不能夠完全利用的原因是數(shù)據(jù)處理的速度沒有跟上網(wǎng)絡(luò)的訓(xùn)練速度。因此,我們的抓手在于提高數(shù)據(jù)的讀取、預(yù)處理速度。
定位問題
首先,我們得先判斷到底是不是數(shù)據(jù)讀取、預(yù)處理階段是整個pipeline的瓶頸,不然豈不是優(yōu)化了個寂寞。
pycharm run/profile 分析瓶頸
通過pycharm的run/profile xxx,我們可以看到程序執(zhí)行的調(diào)用圖,并且可以顯示每個步驟的耗時以及其占比。通過這個工具,我們可以分析在整套訓(xùn)練代碼中時間的瓶頸,因此也能夠更加準(zhǔn)確的定位程序運行慢的癥結(jié)所在。下圖為profile收集一個epoch結(jié)果之后所產(chǎn)生的調(diào)用圖。
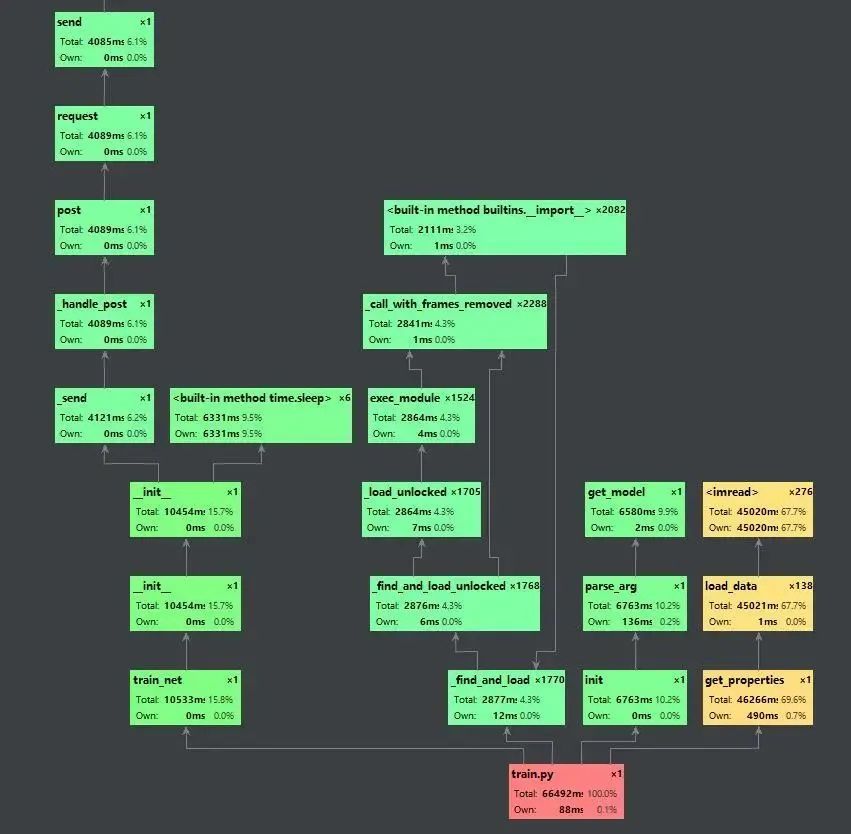
我們可以看到,讀取數(shù)據(jù)的這部分為黃色,說明數(shù)據(jù)讀取部分是整個訓(xùn)練pipeline的瓶頸,因此我們便可以針對性的優(yōu)化。
提高數(shù)據(jù)讀取速度
數(shù)據(jù)讀取速度慢主要是兩個方面的問題:1.數(shù)據(jù)在機械硬盤中不是連續(xù)存儲的,因此多個小文件的讀取會浪費很多時間在尋道上;2.機械硬盤的物理特性決定其讀取速度的上限。
打包數(shù)據(jù)
https://github.com/Lyken17/Efficient-PyTorch#data-loader
假如我們訓(xùn)練的圖片都是比較小,但是數(shù)量比較多的情況下,我們可以采取將數(shù)據(jù)打包成一個大的文件,比如hdf5/pth等格式。這種方式主要是降低了機械硬盤的尋道時間還有OS開啟/關(guān)閉文件描述符的時間。實現(xiàn)的方法可以參考上述repo。
把數(shù)據(jù)放到內(nèi)存上
相比于機械硬盤來說,內(nèi)存的速度可是快了幾個量級,基本上可以說讀取無延遲。因此,如果內(nèi)存夠大的話,的確可以先把數(shù)據(jù)全部都掛載在內(nèi)存上,然后訓(xùn)練的時候直接從內(nèi)存讀取。
sudo mount tmpfs /path/to/your/data -t tmpfs -o size=30G
mount用于掛載Linux系統(tǒng)外的文件,tmpfs即temporary file system。許多軟件為了提高一些常用的數(shù)據(jù)的讀取速度,會把這些數(shù)據(jù)長期駐留在內(nèi)存中以保持一個較快讀寫速度。后面的路徑則是指明需要掛載對數(shù)據(jù)的路徑,-o則是tmpfs動態(tài)大小的上限。需要注意的是,由于虛擬內(nèi)存的存在(在linux為swap空間),數(shù)據(jù)并不一定都會放在物理內(nèi)存中。因此我們掛載的數(shù)據(jù)也可能會因為太久沒有使用而被置換到機械硬盤中。并且,由于再邏輯上這些數(shù)據(jù)是存儲在內(nèi)存中,因此斷電之后這些數(shù)據(jù)都會會清空。
加錢
都2021年了,現(xiàn)在SATA接口的SSD價格早已跌破0.5元1G了,建議可以換個大容量的SSD,提高工作效率。手頭比較寬松的小伙伴/實驗室也可以考慮一下NVMe協(xié)議的固態(tài),速度直接起飛。
提高數(shù)據(jù)讀取/預(yù)處理速度
選擇opencv而不是PIL讀取數(shù)據(jù)
https://www.kaggle.com/yukia18/opencv-vs-pil-speed-comparisons-for-pytorch-user
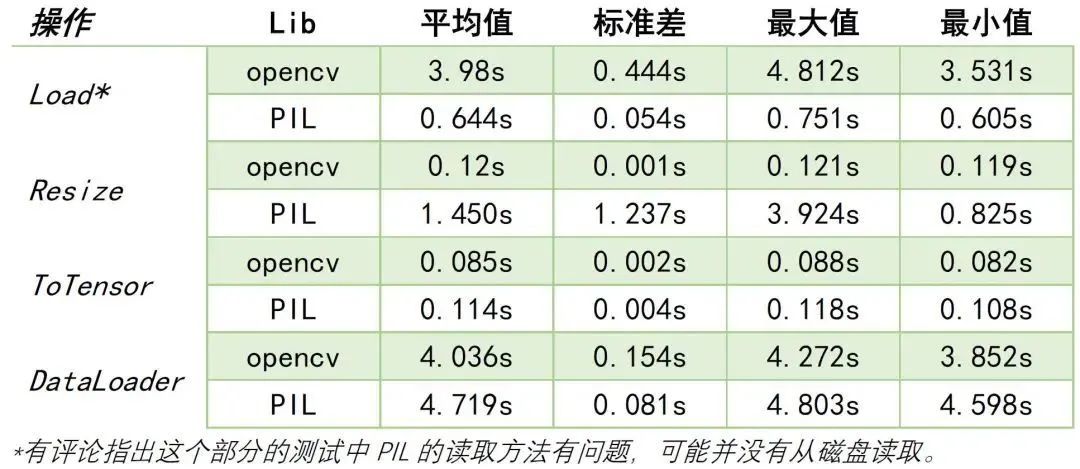
上面鏈接的作者在20579張圖片中對opencv和PIL的圖片讀取、Resize、ToTensor等方法進行了對比。結(jié)論是:大部分情況下,opencv的速度都要優(yōu)于PIL。下面展示不同項目的結(jié)果對比。
prefetch
預(yù)讀就是在GPU還在訓(xùn)練一個batch的同時,CPU也沒有閑著,趕緊把數(shù)據(jù)讀到內(nèi)存中并進行數(shù)據(jù)預(yù)處理。在Pytorch1.7以前,一般使用Nvidia的apex庫來進行prefetch。但是有個問題就是可能會存在內(nèi)存泄漏的問題,具體原因可以參考https://github.com/NVIDIA/apex/issues/439。而在Pytorch1.7版本之后,torch.utils.data里面的DataLoader中就能夠通過prefetch_factor屬性來決定每個每個 worker提前加載的sample數(shù)量。
DALI出奇跡
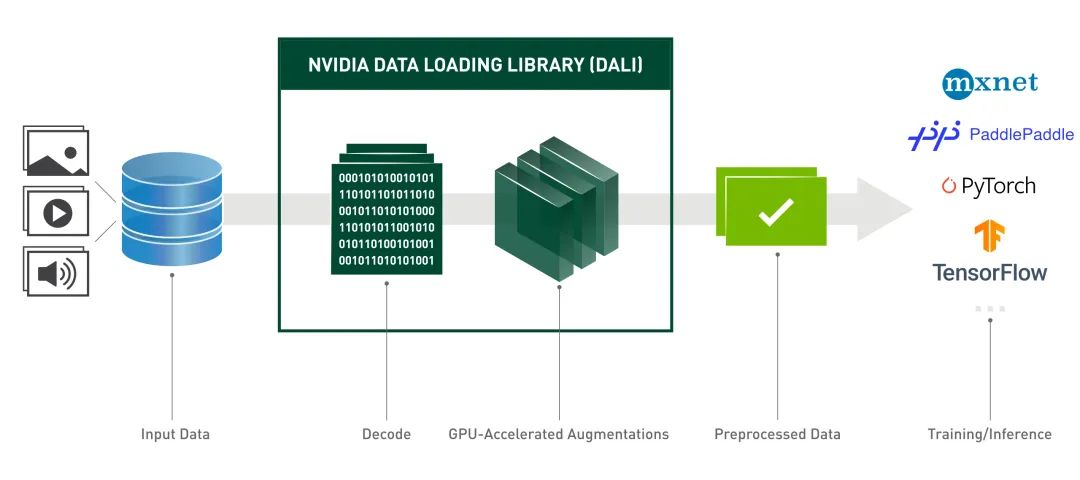
為了解決數(shù)據(jù)讀取和預(yù)處理速度的問題,Nvidia推出了Data Loading Library[1],包含了諸如數(shù)據(jù)加載、解碼、裁剪、resize還有許多數(shù)據(jù)增強功能。并且還能夠?qū)?shù)據(jù)預(yù)處理階段放到顯卡上運行,進一步提高了數(shù)據(jù)增強的效率,目前已經(jīng)可以輕松地被部署到TensorFlow,PyTorch,MXNet和PaddlePaddle框架。實測在使用Pytorch+DALI能夠比原來的速度提高將近四倍![2]
References
[1]https://docs.nvidia.com/deeplearning/dali/user-guide/docs/
[2]https://zhuanlan.zhihu.com/p/105056158
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“ICCV2021”獲取最新論文合集~

# CV技術(shù)社群邀請函 #

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測-深圳)
即可申請加入極市目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
