
22張圖全解深度學(xué)習(xí)知識,建議收藏
點(diǎn)擊上方“視學(xué)算法”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

https://zhuanlan.zhihu.com/p/152362317
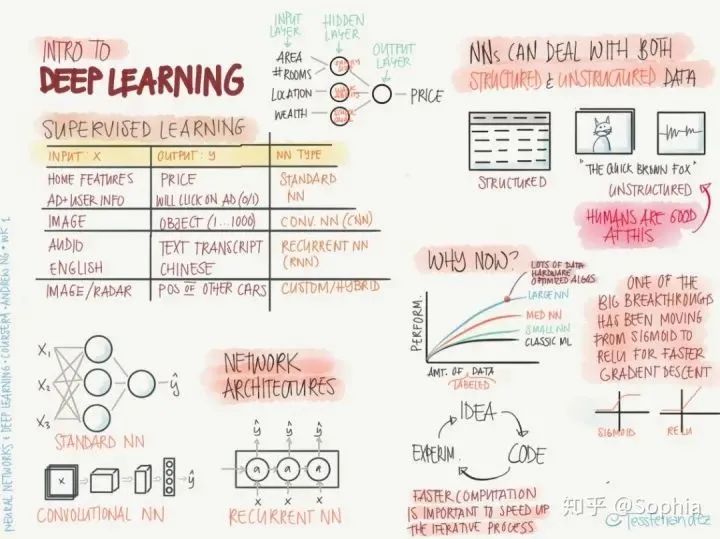
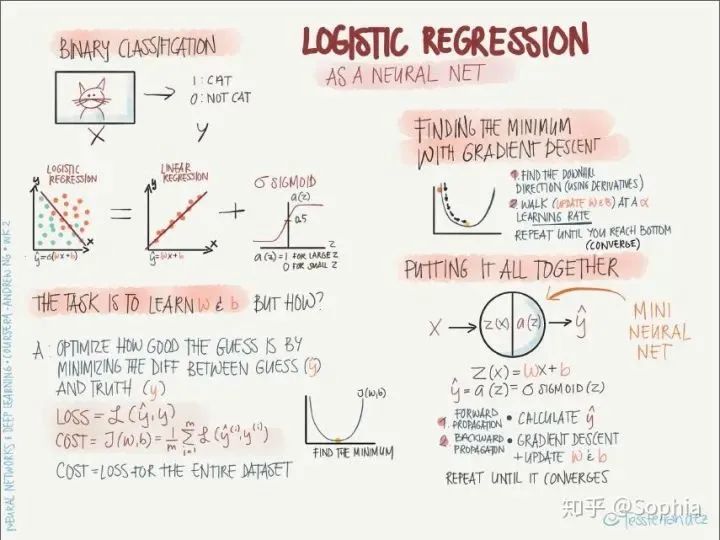
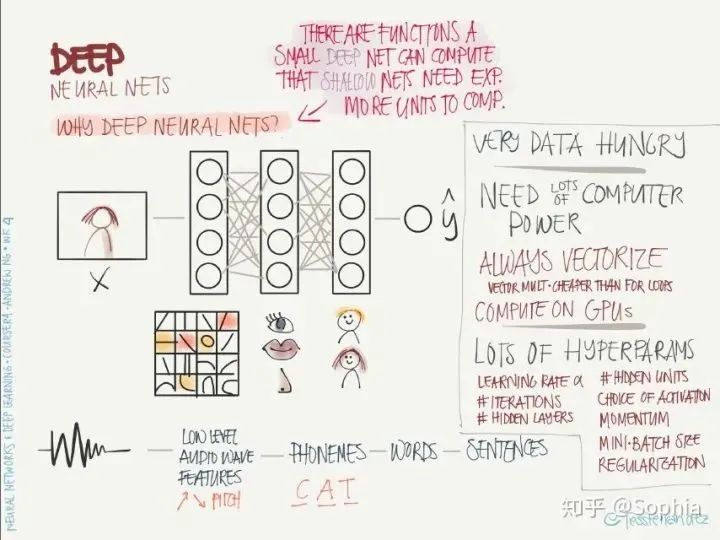
深度學(xué)習(xí)基礎(chǔ)
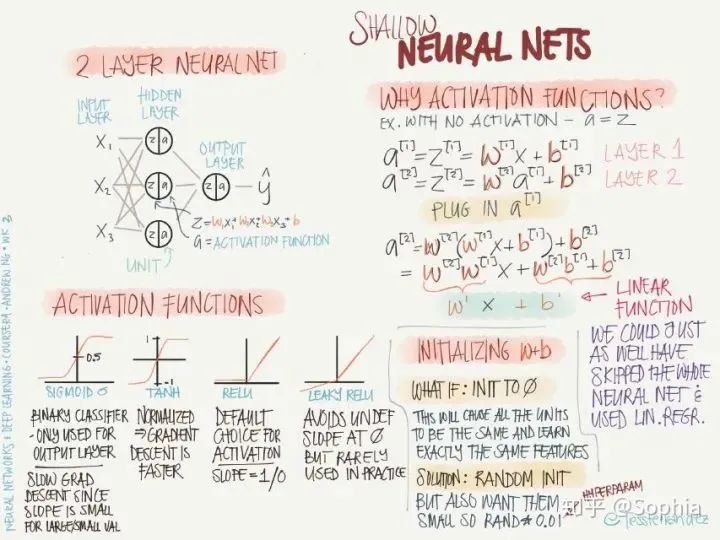
sigmoid:sigmoid 函數(shù)常用于二分分類問題,或者多分類問題的最后一層,主要是由于其歸一化特性。sigmoid 函數(shù)在兩側(cè)會出現(xiàn)梯度趨于零的情況,會導(dǎo)致訓(xùn)練緩慢。 tanh:相對于 sigmoid,tanh 函數(shù)的優(yōu)點(diǎn)是梯度值更大,可以使訓(xùn)練速度變快。 ReLU:可以理解為閾值激活(spiking model 的特例,類似生物神經(jīng)的工作方式),該函數(shù)很常用,基本是默認(rèn)選擇的激活函數(shù),優(yōu)點(diǎn)是不會導(dǎo)致訓(xùn)練緩慢的問題,并且由于激活值為零的節(jié)點(diǎn)不會參與反向傳播,該函數(shù)還有稀疏化網(wǎng)絡(luò)的效果。 Leaky ReLU:避免了零激活值的結(jié)果,使得反向傳播過程始終執(zhí)行,但在實(shí)踐中很少用。
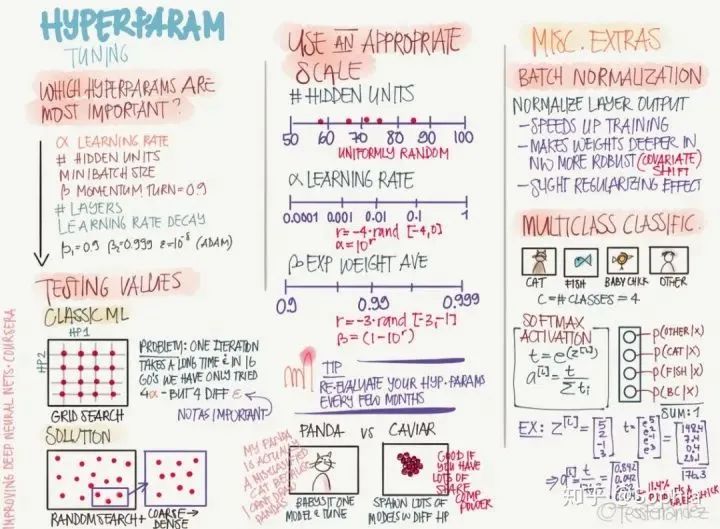
依靠經(jīng)驗(yàn):聆聽自己的直覺,設(shè)置感覺上應(yīng)該對的參數(shù)然后看看它是否工作,不斷嘗試直到累趴。 網(wǎng)格搜索:讓計(jì)算機(jī)嘗試一些在一定范圍內(nèi)均勻分布的數(shù)值。 隨機(jī)搜索:讓計(jì)算機(jī)嘗試一些隨機(jī)值,看看它們是否好用。 貝葉斯優(yōu)化:使用類似 MATLAB bayesopt 的工具自動選取最佳參數(shù)——結(jié)果發(fā)現(xiàn)貝葉斯優(yōu)化的超參數(shù)比你自己的機(jī)器學(xué)習(xí)算法還要多,累覺不愛,回到依靠經(jīng)驗(yàn)和網(wǎng)格搜索方法上去。
卷積網(wǎng)絡(luò)
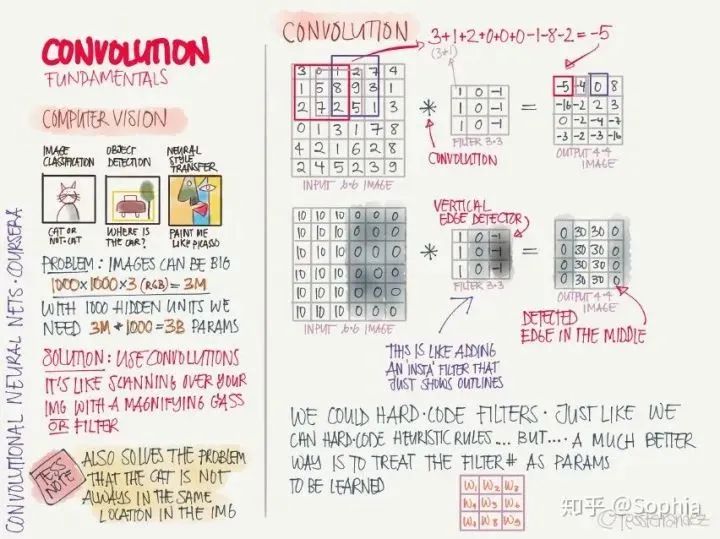
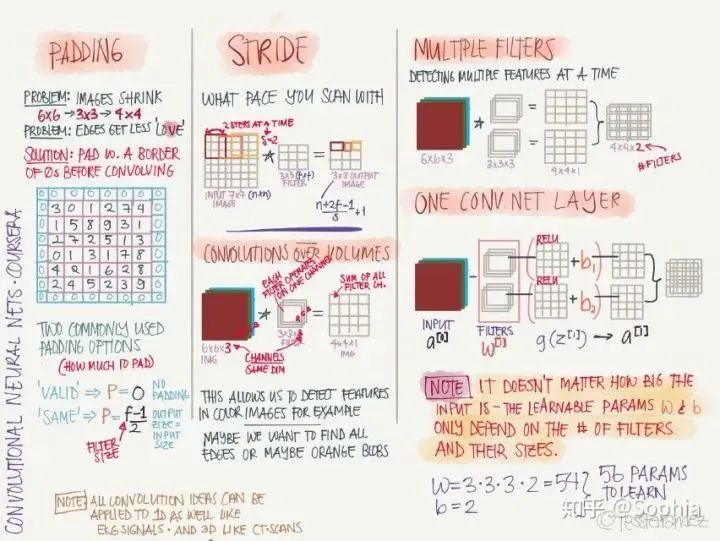
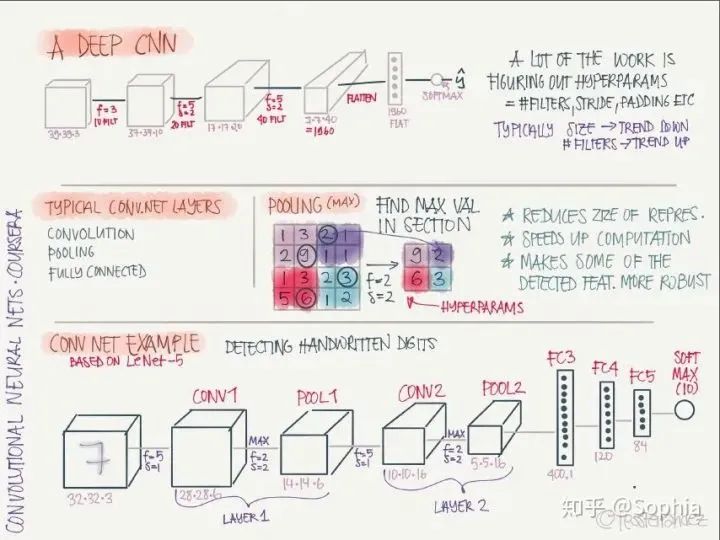
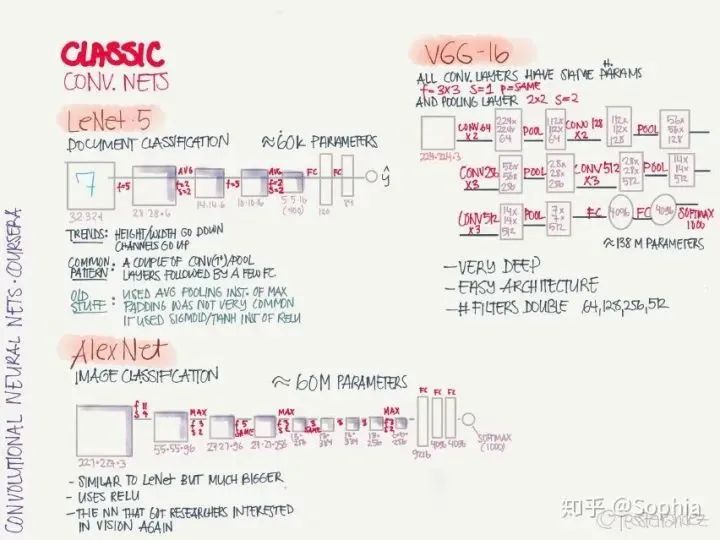
LeNet·5:手寫識別分類網(wǎng)絡(luò),這是第一個(gè)卷積神經(jīng)網(wǎng)絡(luò),由 Yann LeCun 提出。 AlexNet:圖像分類網(wǎng)絡(luò),首次在 CNN 引入 ReLU 激活函數(shù)。 VGG-16:圖像分類網(wǎng)絡(luò),深度較大。
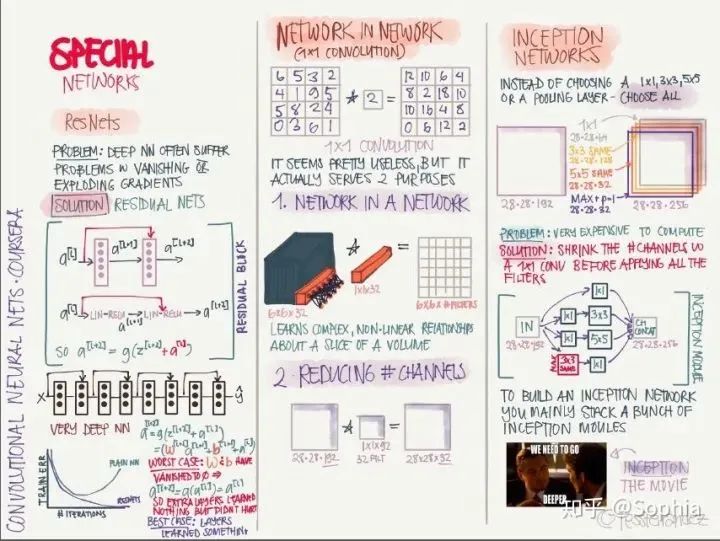
ResNet: 引入殘差連接,緩解梯度消失和梯度爆炸問題,可以訓(xùn)練非常深的網(wǎng)絡(luò)。 Network in Network: 使用 1x1 卷積核,可以將卷積運(yùn)算變成類似于全連接網(wǎng)絡(luò)的形式,還可以減少特征圖的通道數(shù),從而減少參數(shù)數(shù)量。 Inception Network: 使用了多種尺寸卷積核的并行操作,再堆疊成多個(gè)通道,可以捕捉多種規(guī)模的特征,但缺點(diǎn)是計(jì)算量太大,可以通過 1x1 卷積減少通道數(shù)。
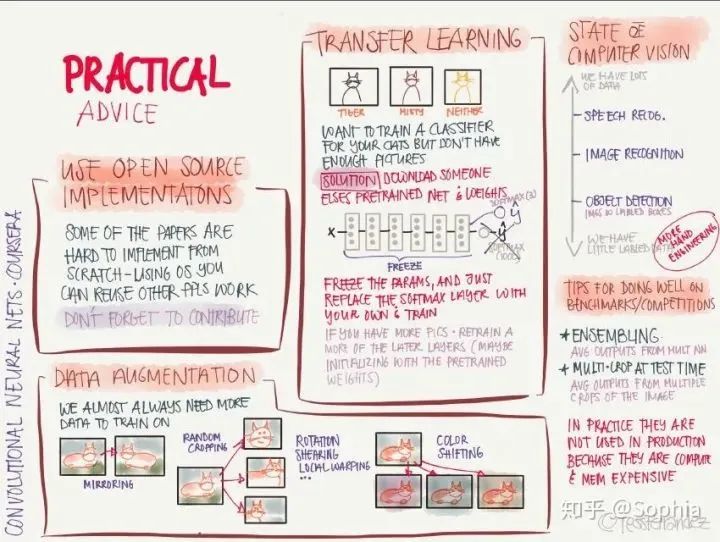
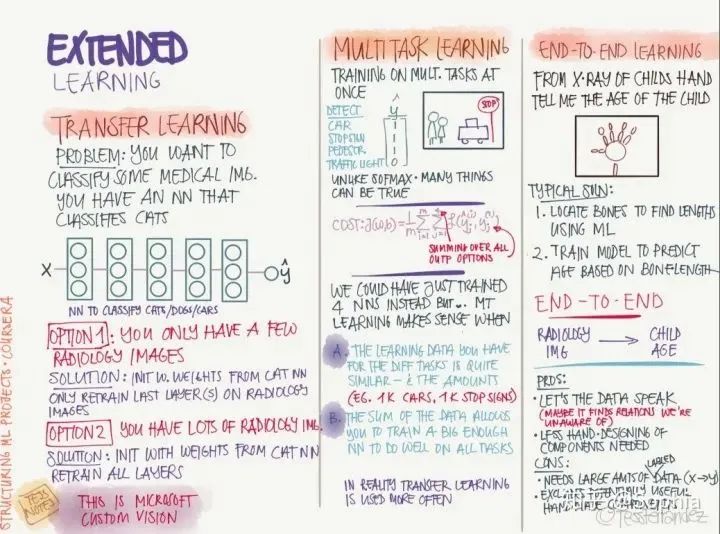
使用開源實(shí)現(xiàn): 從零開始實(shí)現(xiàn)時(shí)非常困難的,利用別人的實(shí)現(xiàn)可以快速探索更復(fù)雜有趣的任務(wù)。 數(shù)據(jù)增強(qiáng): 通過對原圖像進(jìn)行鏡像、隨機(jī)裁剪、旋轉(zhuǎn)、顏色變化等操作,增加訓(xùn)練數(shù)據(jù)量和多樣性。 遷移學(xué)習(xí): 針對當(dāng)前任務(wù)的訓(xùn)練數(shù)據(jù)太少時(shí),可以將充分訓(xùn)練過的模型用少量數(shù)據(jù)微調(diào)獲得足夠好的性能。 基準(zhǔn)測試和競賽中表現(xiàn)良好的訣竅: 使用模型集成,使用多模型輸出的平均結(jié)果;在測試階段,將圖像裁剪成多個(gè)副本分別測試,并將測試結(jié)果取平均。
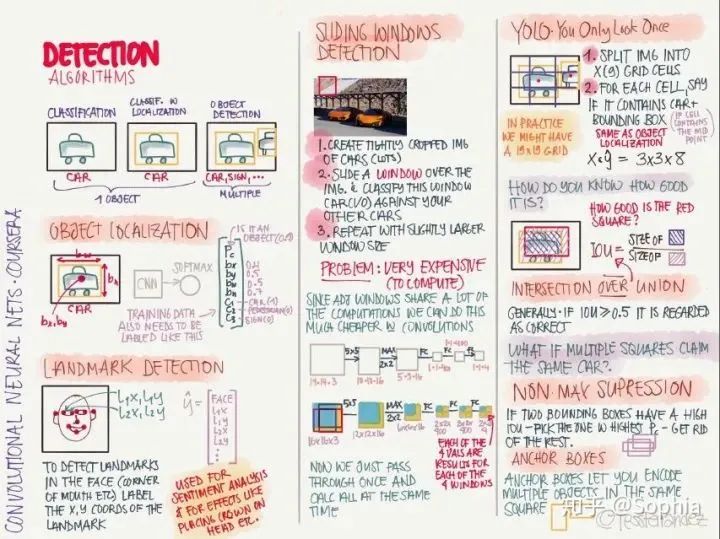
循環(huán)網(wǎng)絡(luò)




點(diǎn)個(gè)在看 paper不斷!
評論
圖片
表情