
(附代碼)一個可視化選擇最優(yōu)backbone的小方法
點(diǎn)擊左上方藍(lán)字關(guān)注我們

轉(zhuǎn)載自 | 邁微AI研習(xí)社
理想情況下,我在這里描述用代碼的技巧應(yīng)該適用于任何使用卷積特征提取器(CONV-FE)的深度學(xué)習(xí)(Deep Learning, DL)模型。(“Feature Extractor”有時也被稱為“backbone” 或 “Encoder”)
今天我們將看到一個巧妙的技巧來可視化化任何CV任務(wù)的CONV-FE。我們將使用帶有TensorFlow后臺的Keras來演示這個技巧。這個技巧可以用來“調(diào)試”沒有正確訓(xùn)練的模型,或者“檢查”/“解釋”訓(xùn)練好的模型。
對于新讀者來說,值得一提的是架構(gòu)和CONV-FE之間的區(qū)別。SSD, YOLO和F-RCNN是當(dāng)今一些流行的目標(biāo)檢測架構(gòu)。正如你所知道的,架構(gòu)是具有某種形式的靈活性的模板,用戶可以根據(jù)自己的用例選擇調(diào)整架構(gòu)。
對于新讀者來說,值得一提的是架構(gòu)和骨干之間的區(qū)別。大多數(shù)架構(gòu)都將CONV-FE視為插件。一些流行的CONV-FE是 VGG-16、ResNet50和MobileNetV2。通常可以看到,使用特定體系結(jié)構(gòu)構(gòu)建的模型的性能(包括速度和準(zhǔn)確性)將受到很大的影響。出于這個原因,實(shí)踐者提到了他們在模型名稱本身中使用的 VGG-16。一個F-RCNN(ResNet50)是一個模型與F-RCNN論文中描述的架構(gòu),使用ResNet50 CONV-FE構(gòu)建。換句話說,F(xiàn)-RCNN(MobileNetV2)和F-RCNN(vg -16)遵循相同的網(wǎng)絡(luò)架構(gòu),但使用不同的CONV-FEs。因此,我們可以期望每個系統(tǒng)都有不同的性能。CONV-FEs也有他們的架構(gòu),這就是為什么我們有VGG-16和VGG-19的原因。
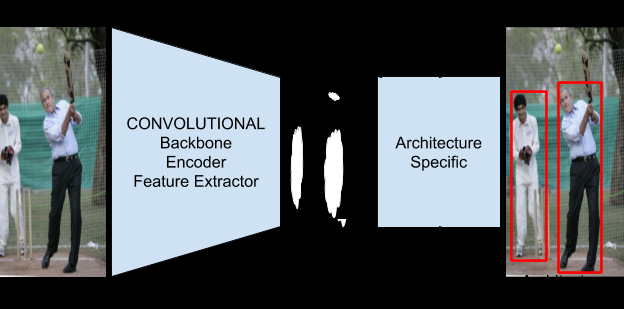
圖1顯示了一個基于DL的目標(biāo)檢測系統(tǒng)的高級架構(gòu)。眾所周知的體系結(jié)構(gòu)如YOLO、F-RCNN和SSD都可以用這個模板。[W, H, 3]表示圖像的輸入寬度和高度,也表示輸入圖像有3通道。[w, h, N]表示轉(zhuǎn)換函數(shù)的輸出維數(shù)。需要注意的是,由于N是特征提取器最后一層CONV層中濾波器的數(shù)量,所以通常是一個很大的數(shù)量(對于VGG-16, N = 512)。w和h幾乎總是比w, h小,因?yàn)樵诮裉斓拇蠖鄶?shù)架構(gòu)中,CONV塊通常后面跟著池化層。
如上所述,對于我們的CV系統(tǒng)而言,選擇一個對 CONV-FE是至關(guān)重要的。然而,問題在于N的值很大。不可能想象一個所有維度都任意大的三維張量!這就是我們今天要解決的問題。我們馬上開始吧。
我們先選擇一個CONV-FE,用VGG-16試試。
一旦模型被加載,我們需要做一些腳本來加載我們想要嘗試我們的技巧的圖像。我在這里不描述這些步驟,因?yàn)樗鼈冊谀愕奶囟ㄓ美袝泻艽蟮牟煌,F(xiàn)在,我們只假設(shè)所有所需的圖像都存儲在工作目錄中名為“images”的目錄中。現(xiàn)在讓我們使用這個技巧!
你將看到類似于下面的輸出(這些也將保存在直接在工作目錄中創(chuàng)建的“results”目錄中)
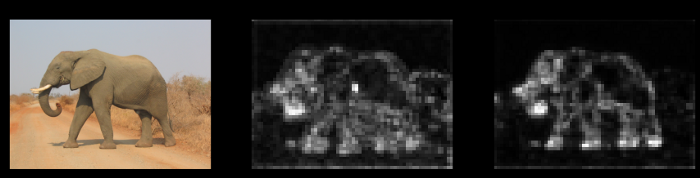 Figure 2.1: Results1_Elephant
Figure 2.1: Results1_Elephant
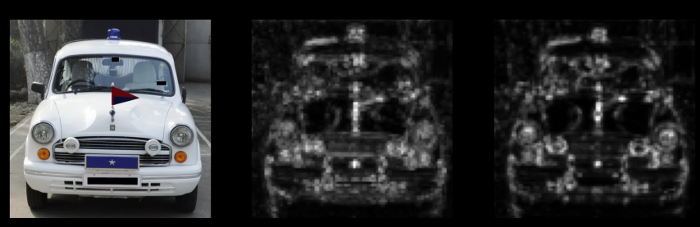
Figure 2.2: Results2_Car

Figure 2.3: Results3_Man

Figure 2.4 Results4_PCB
第二列顯示了任意通道可以在由CONV-FE產(chǎn)生的輸出特征映射中實(shí)現(xiàn)的像素級最大值。第三列顯示了所有通道的平均值。我們說,如果我們的結(jié)果中的第二列和第三列顯示出清晰的特征分離,那么CONV-FE適用于我們的數(shù)據(jù)集。
如我們所見,1和2的結(jié)果非常好,但3和4的結(jié)果表明,如果你有全屏PCB圖像或穿著傳統(tǒng)服裝的印度男人的圖像,當(dāng)前的模型并不真的適合。但是,如果你的數(shù)據(jù)集包含野生動物或汽車/車輛的圖片,那么這個模型似乎是一個不錯的選擇。
現(xiàn)在,讓我們做一個小小的調(diào)整。根據(jù)圖1,輸出特性映射可以有任意數(shù)量(N)的輸出通道。這是我們無法可視化和比較CONV-FEs的主要原因。我們使用常見的聚合技術(shù),即求和和平均,來獲得特征圖質(zhì)量的總體近似。我沒有沿著通道使用像素級的中間值進(jìn)行聚合。
感興趣的讀者可以參考源碼,試一試,了解更多細(xì)節(jié)。
源碼 https://github.com/IshanBhattOfficial/Vizualize-CONV-FeatureExtractors
英文原文:https://medium.com/analytics-vidhya/how-to-select-the-perfect-cnn-back-bone-for-object-detection-a-simple-test-b3f9e9519174
END
整理不易,點(diǎn)贊三連↓