
神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)到的是什么?(Python)
神經(jīng)網(wǎng)絡(luò)(深度學(xué)習(xí))學(xué)習(xí)到的是什么?一個含糊的回答是,學(xué)習(xí)到的是數(shù)據(jù)的本質(zhì)規(guī)律。但具體這本質(zhì)規(guī)律究竟是什么呢?要回答這個問題,我們可以從神經(jīng)網(wǎng)絡(luò)的原理開始了解。
一、 神經(jīng)網(wǎng)絡(luò)的原理
神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)就是一種特征的表示學(xué)習(xí),把原始數(shù)據(jù)通過一些簡單非線性的轉(zhuǎn)換成為更高層次的、更加抽象的特征表達(dá)。深度網(wǎng)絡(luò)層功能類似于“生成特征”,而寬度層類似于“記憶特征”,增加網(wǎng)絡(luò)深度可以獲得更抽象、高層次的特征,增加網(wǎng)絡(luò)寬度可以交互出更豐富的特征。通過足夠多的轉(zhuǎn)換組合的特征,非常復(fù)雜的函數(shù)也可以被模型學(xué)習(xí)好。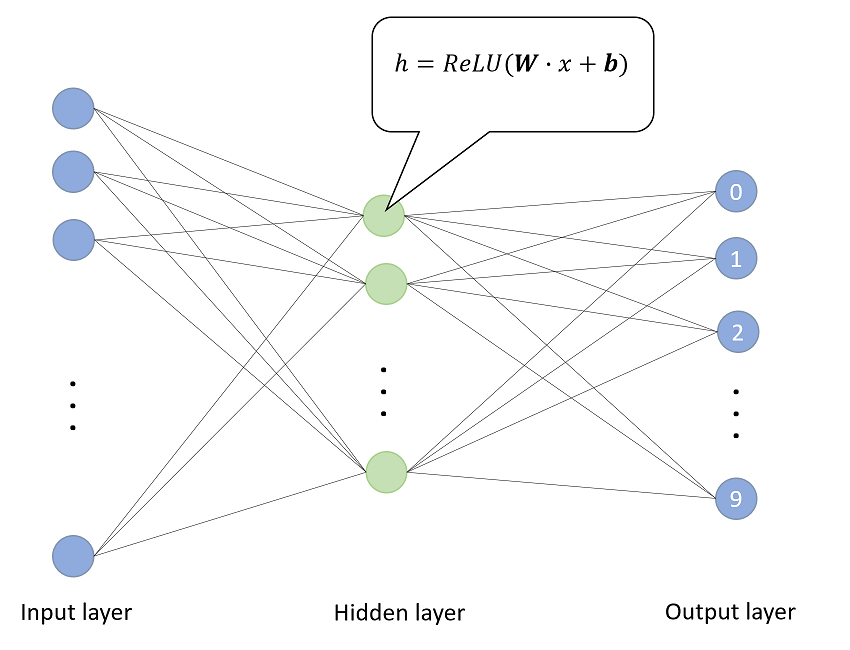
可見神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)的核心是,學(xué)習(xí)合適權(quán)重參數(shù)以對數(shù)據(jù)進(jìn)行非線性轉(zhuǎn)換,以提取關(guān)鍵特征或者決策。即模型參數(shù)控制著特征加工方法及決策。了解了神經(jīng)網(wǎng)絡(luò)的原理,我們可以結(jié)合如下項目示例,看下具體的學(xué)習(xí)的權(quán)重參數(shù),以及如何參與抽象特征生成與決策。
二、神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)內(nèi)容
2.1 簡單的線性模型的學(xué)習(xí)
我們先從簡單的模型入手,分析其學(xué)習(xí)的內(nèi)容。像線性回歸、邏輯回歸可以視為單層的神經(jīng)網(wǎng)絡(luò),它們都是廣義的線性模型,可以學(xué)習(xí)輸入特征到目標(biāo)值的線性映射規(guī)律。
如下代碼示例,以線性回歸模型學(xué)習(xí)波士頓各城鎮(zhèn)特征與房價的關(guān)系,并作出房價預(yù)測。數(shù)據(jù)是波士頓房價數(shù)據(jù)集,它是統(tǒng)計20世紀(jì)70年代中期波士頓郊區(qū)房價情況,有當(dāng)時城鎮(zhèn)的犯罪率、房產(chǎn)稅等共計13個指標(biāo)以及對應(yīng)的房價中位數(shù)。
import?pandas?as?pd?
import?numpy?as?np
from?keras.datasets?import?boston_housing?#導(dǎo)入波士頓房價數(shù)據(jù)集
(train_x,?train_y),?(test_x,?test_y)?=?boston_housing.load_data()
from?keras.layers?import?*
from?keras.models?import?Sequential,?Model
from?tensorflow?import?random
from?sklearn.metrics?import??mean_squared_error
np.random.seed(0)?#?隨機種子
random.set_seed(0)
#?單層線性層的網(wǎng)絡(luò)結(jié)構(gòu)(也就是線性回歸):無隱藏層,由于是數(shù)值回歸預(yù)測,輸出層沒有用激活函數(shù);
model?=?Sequential()
model.add(Dense(1,use_bias=False))??
model.compile(optimizer='adam',?loss='mse')??#?回歸預(yù)測損失mse
model.fit(train_x,?train_y,?epochs=1000,verbose=False)??#?訓(xùn)練模型
model.summary()
pred_y?=?model.predict(test_x)[:,0]
print("正確標(biāo)簽:",test_y)
print("模型預(yù)測:",pred_y?)
print("實際與預(yù)測值的差異:",mean_squared_error(test_y,pred_y?))
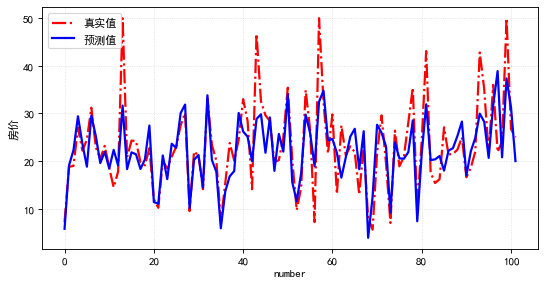
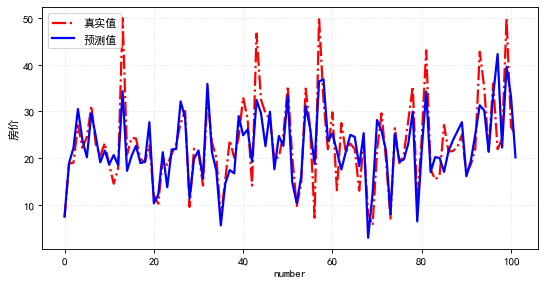
通過線性回歸模型學(xué)習(xí)訓(xùn)練集,輸出測試集預(yù)測結(jié)果如下: 分析預(yù)測的效果,用上面數(shù)值體現(xiàn)不太直觀,如下畫出實際值與預(yù)測值的曲線,可見,整體模型預(yù)測值與實際值的差異還是比較小的(模型擬合較好)。
分析預(yù)測的效果,用上面數(shù)值體現(xiàn)不太直觀,如下畫出實際值與預(yù)測值的曲線,可見,整體模型預(yù)測值與實際值的差異還是比較小的(模型擬合較好)。
#繪圖表示
import?matplotlib.pyplot?as?plt
plt.rcParams['font.sans-serif']?=?['SimHei']
plt.rcParams['axes.unicode_minus']?=?False
#?設(shè)置圖形大小
plt.figure(figsize=(8,?4),?dpi=80)
plt.plot(range(len(test_y)),?test_y,?ls='-.',lw=2,c='r',label='真實值')
plt.plot(range(len(pred_y)),?pred_y,?ls='-',lw=2,c='b',label='預(yù)測值')
#?繪制網(wǎng)格
plt.grid(alpha=0.4,?linestyle=':')
plt.legend()
plt.xlabel('number')?#設(shè)置x軸的標(biāo)簽文本
plt.ylabel('房價')?#設(shè)置y軸的標(biāo)簽文本
#?展示
plt.show()
回到正題,我們的單層神經(jīng)網(wǎng)絡(luò)模型(線性回歸),在數(shù)據(jù)(波士頓房價)、優(yōu)化目標(biāo)(最小化預(yù)測誤差mse)、優(yōu)化算法(梯度下降)的共同配合下,從數(shù)據(jù)中學(xué)到了什么呢?
我們可以很簡單地用決策函數(shù)的數(shù)學(xué)式來概括我們學(xué)習(xí)到的線性回歸模型,預(yù)測y=w1x1 + w2x2 + wn*xn。通過提取當(dāng)前線性回歸模型最終學(xué)習(xí)到的參數(shù):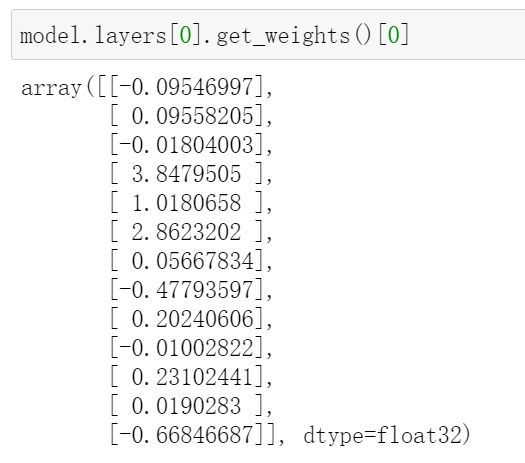 將參數(shù)與對應(yīng)輸入特征組合一下,我們忙前忙后訓(xùn)練模型學(xué)到內(nèi)容也就是——權(quán)重參數(shù),它可以對輸入特征進(jìn)行加權(quán)求和輸出預(yù)測值決策。如下決策公式,我們可以看出預(yù)測的房價和犯罪率、弱勢群體比例等因素是負(fù)相關(guān)的:
將參數(shù)與對應(yīng)輸入特征組合一下,我們忙前忙后訓(xùn)練模型學(xué)到內(nèi)容也就是——權(quán)重參數(shù),它可以對輸入特征進(jìn)行加權(quán)求和輸出預(yù)測值決策。如下決策公式,我們可以看出預(yù)測的房價和犯罪率、弱勢群體比例等因素是負(fù)相關(guān)的:
房價預(yù)測值 = [-0.09546997]*CRIM|住房所在城鎮(zhèn)的人均犯罪率+[0.09558205]*ZN|住房用地超過 25000 平方尺的比例+[-0.01804003]*INDUS|住房所在城鎮(zhèn)非零售商用土地的比例+[3.8479505]*CHAS|有關(guān)查理斯河的虛擬變量(如果住房位于河邊則為1,否則為0 )+[1.0180658]*NOX|一氧化氮濃度+[2.8623202]*RM|每處住房的平均房間數(shù)+[0.05667834]*AGE|建于 1940 年之前的業(yè)主自住房比例+[-0.47793597]*DIS|住房距離波士頓五大中心區(qū)域的加權(quán)距離+[0.20240606]*RAD|距離住房最近的公路入口編號+[-0.01002822]*TAX 每 10000 美元的全額財產(chǎn)稅金額+[0.23102441]*PTRATIO|住房所在城鎮(zhèn)的師生比例+[0.0190283]*B|1000(Bk|0.63)^2,其中 Bk 指代城鎮(zhèn)中黑人的比例+[-0.66846687]*LSTAT|弱勢群體人口所占比例
小結(jié):單層神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)到各輸入特征所合適的權(quán)重值,根據(jù)權(quán)重值對輸入特征進(jìn)行加權(quán)求和,輸出求和結(jié)果作為預(yù)測值(注:邏輯回歸會在求和的結(jié)果再做sigmoid非線性轉(zhuǎn)為預(yù)測概率)。
2.2 深度神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)
深度神經(jīng)網(wǎng)絡(luò)(深度學(xué)習(xí))與單層神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)差異在于,引入了層數(shù)>=1的非線性隱藏層。從學(xué)習(xí)的角度上看,模型很像是集成學(xué)習(xí)方法——以上層的神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)的特征,輸出到下一層。而這種學(xué)習(xí)方法,就可以學(xué)習(xí)到非線性轉(zhuǎn)換組合的復(fù)雜特征,達(dá)到更好的擬合效果。
對于學(xué)習(xí)到的內(nèi)容,他不僅僅是利用權(quán)重值控制輸出決策結(jié)果--f(WX),還有比較復(fù)雜多層次的特征交互, 這也意味著深度學(xué)習(xí)不能那么直觀數(shù)學(xué)形式做表示--它是一個復(fù)雜的復(fù)合函數(shù)f(f..f(WX))。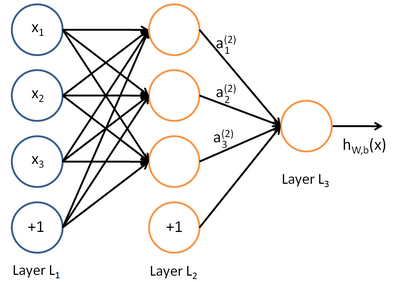
如下以2層的神經(jīng)網(wǎng)絡(luò)為例,繼續(xù)波士頓房價的預(yù)測: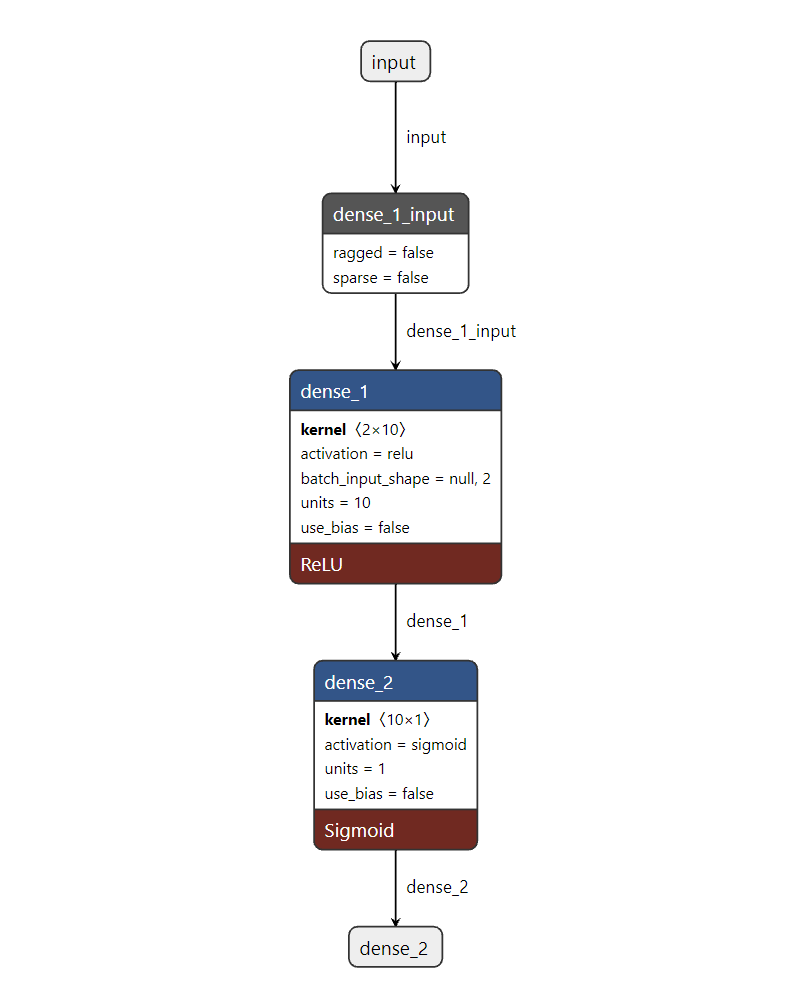 注:本可視化工具來源于https://netron.app/
注:本可視化工具來源于https://netron.app/
from?keras.layers?import?*
from?keras.models?import?Sequential,?Model
from?tensorflow?import?random
from?sklearn.metrics?import??mean_squared_error
np.random.seed(0)?#?隨機種子
random.set_seed(0)
#?網(wǎng)絡(luò)結(jié)構(gòu):輸入層的特征維數(shù)為13,1層relu隱藏層,線性的輸出層;
model?=?Sequential()
model.add(Dense(10,?input_dim=13,?activation='relu',use_bias=False))???#?隱藏層
model.add(Dense(1,use_bias=False))??
model.compile(optimizer='adam',?loss='mse')??#?回歸預(yù)測損失mse
model.fit(train_x,?train_y,?epochs=1000,verbose=False)??#?訓(xùn)練模型
model.summary()
pred_y?=?model.predict(test_x)[:,0]
print("正確標(biāo)簽:",test_y)
print("模型預(yù)測:",pred_y?)
print("實際與預(yù)測值的差異:",mean_squared_error(test_y,pred_y?))
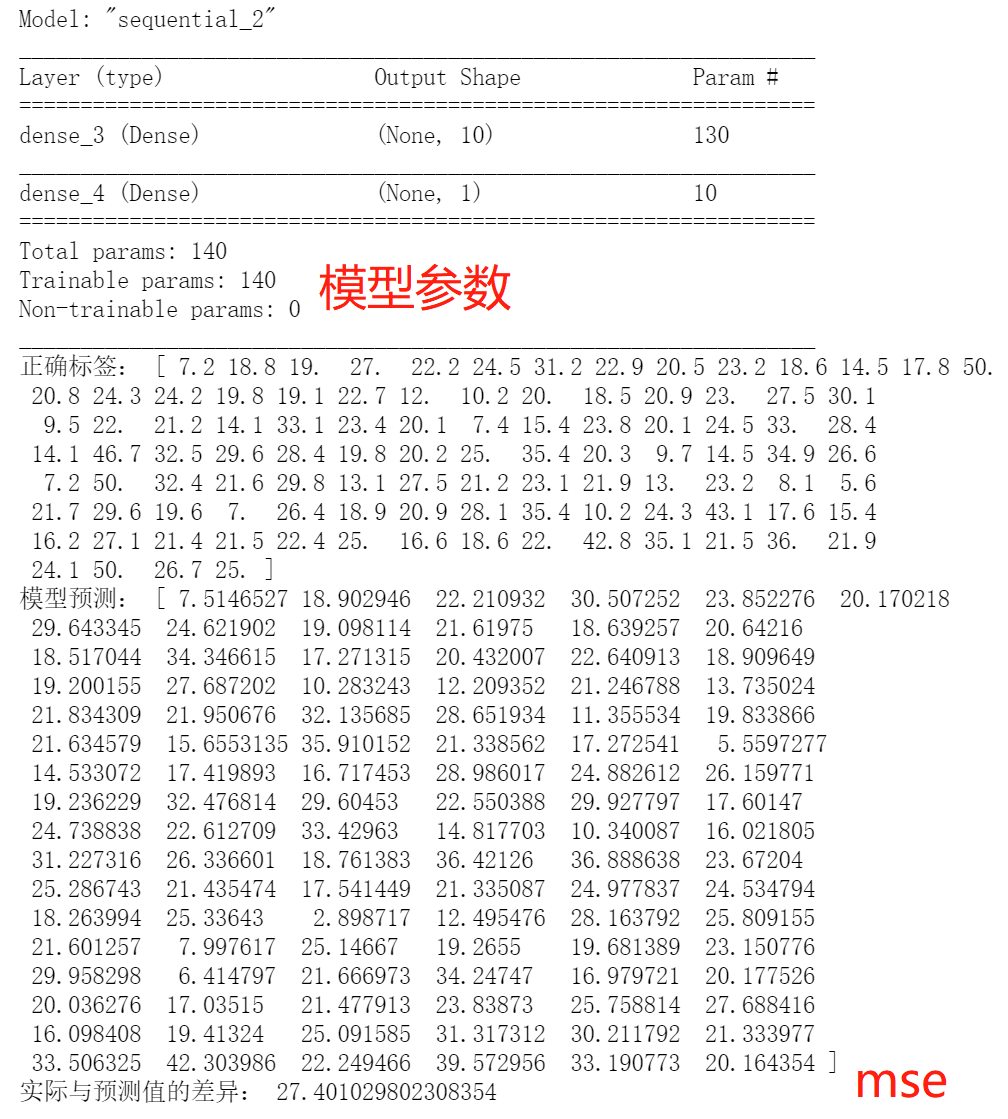
可見,其模型的參數(shù)(190個)遠(yuǎn)多于單層線性網(wǎng)絡(luò)(13個);學(xué)習(xí)的誤差(27.4)小于單層線性網(wǎng)絡(luò)模型(31.9),有著更高的復(fù)雜度和更好的學(xué)習(xí)效果。
#繪圖表示
import?matplotlib.pyplot?as?plt
plt.rcParams['font.sans-serif']?=?['SimHei']
plt.rcParams['axes.unicode_minus']?=?False
#?設(shè)置圖形大小
plt.figure(figsize=(8,?4),?dpi=80)
plt.plot(range(len(test_y)),?test_y,?ls='-.',lw=2,c='r',label='真實值')
plt.plot(range(len(pred_y)),?pred_y,?ls='-',lw=2,c='b',label='預(yù)測值')
#?繪制網(wǎng)格
plt.grid(alpha=0.4,?linestyle=':')
plt.legend()
plt.xlabel('number')?#設(shè)置x軸的標(biāo)簽文本
plt.ylabel('房價')?#設(shè)置y軸的標(biāo)簽文本
#?展示
plt.show()
回到分析深度神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)的內(nèi)容,這里我們輸入一條樣本,看看每一層神經(jīng)網(wǎng)絡(luò)的輸出。
from?numpy?import?exp
x0=train_x[0]
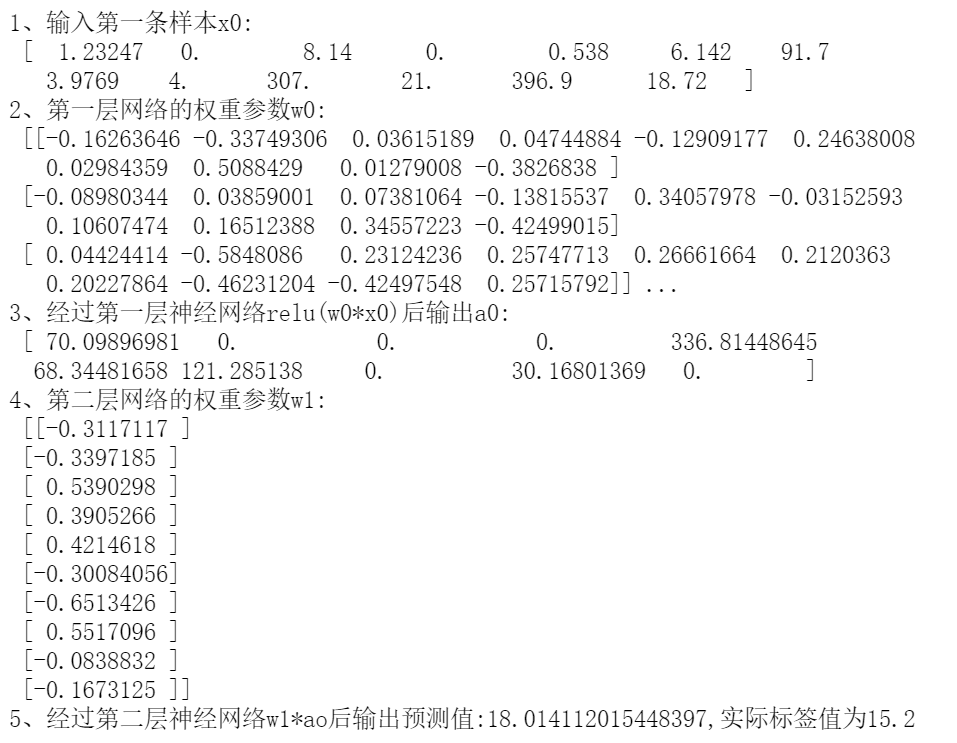
print("1、輸入第一條樣本x0:\n",?x0)
?#?權(quán)重參數(shù)可以控制數(shù)據(jù)的特征表達(dá)再輸出到下一層
w0=?model.layers[0].get_weights()[0]?
print("2、第一層網(wǎng)絡(luò)的權(quán)重參數(shù)w0:\n",?w0)?
a0?=?np.maximum(0,np.dot(w0.T,?x0))?
#?a0可以視為第一層網(wǎng)絡(luò)層交互出的新特征,但其特征含義是比較模糊的
print("3、經(jīng)過第一層神經(jīng)網(wǎng)絡(luò)relu(w0*x0)后輸出:\n",a0)?
w1=model.layers[1].get_weights()[0]?
print("4、第二層網(wǎng)絡(luò)的權(quán)重參數(shù)w1:\n",?w1)??
?#?預(yù)測結(jié)果為w1與ao加權(quán)求和
a1?=?np.dot(w1.T,a0)??????????????????????????????????
print("5、經(jīng)過第二層神經(jīng)網(wǎng)絡(luò)w1*ao后輸出預(yù)測值:%s,實際標(biāo)簽值為%s"%(a1[0],train_y[0]))??
運行代碼,輸出如下結(jié)果
從深度神經(jīng)網(wǎng)絡(luò)的示例可以看出,神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)的內(nèi)容一樣是權(quán)重參數(shù)。由于非線性隱藏層的作用下,深度神經(jīng)網(wǎng)絡(luò)可以通過權(quán)重參數(shù)對數(shù)據(jù)非線性轉(zhuǎn)換,交互出復(fù)雜的、高層次的特征,并利用這些特征輸出決策,最終取得較好的學(xué)習(xí)效果。但是,正也因為隱藏層交互組合特征過程的復(fù)雜性,學(xué)習(xí)的權(quán)重參數(shù)在業(yè)務(wù)含義上如何決策,并不好直觀解釋。
對于深度神經(jīng)網(wǎng)絡(luò)的解釋,常常說深度學(xué)習(xí)模型是“黑盒”,學(xué)習(xí)內(nèi)容很難表示成易于解釋含義的形式。在此,一方面可以借助shap等解釋性的工具加于說明。另一方面,還有像深度學(xué)習(xí)處理圖像識別任務(wù),就是個天然直觀地展現(xiàn)深度學(xué)習(xí)的過程。如下展示輸入車子通過層層提取的高層次、抽象的特征,圖像識別的過程。注:圖像識別可視化工具來源于https://poloclub.github.io/cnn-explainer/

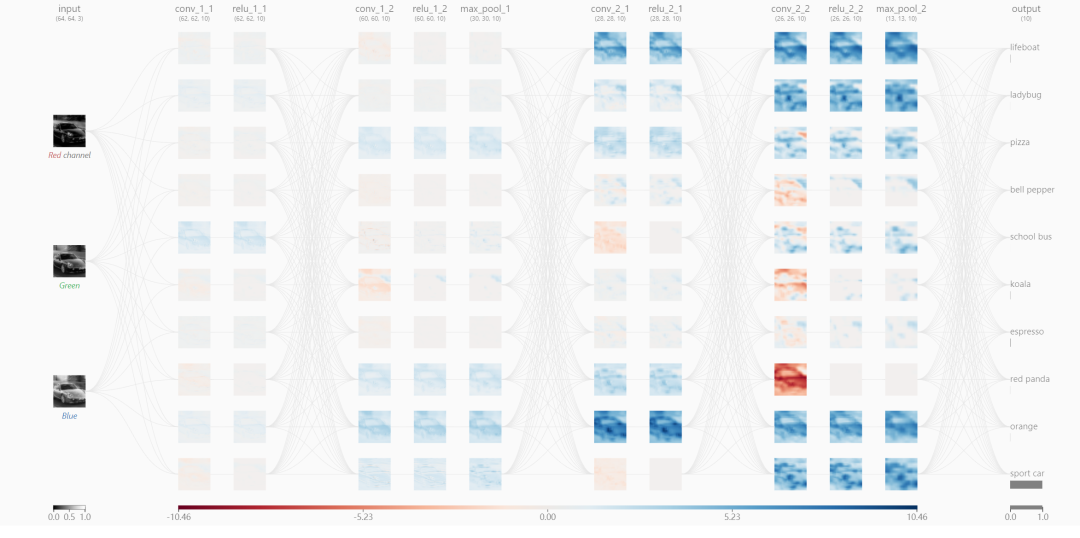 在神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)提取層次化特征以識別圖像的過程:
在神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)提取層次化特征以識別圖像的過程:
第一層,像是各種邊緣探測特征的集合,在這個階段,激活值仍然是保留了幾乎原始圖像的所有信息。 更高一層,激活值就變得進(jìn)一步抽象,開始表示更高層次的內(nèi)容,諸如“車輪”。有著更少的視覺表示(稀疏),也提取到了更關(guān)鍵特征的信息。
這和人類學(xué)習(xí)(圖像識別)的過程是類似的——從具體到抽象,簡單概括出物體的本質(zhì)特征。就像我們看到一輛很酷的小車,
然后憑記憶將它畫出來,很可能沒法畫出很多細(xì)節(jié),只有抽象出來的關(guān)鍵特征表現(xiàn),類似這樣??:
我們的大腦學(xué)習(xí)輸入的視覺圖像的抽象特征,而不相關(guān)忽略的視覺細(xì)節(jié),提高效率的同時,學(xué)習(xí)的內(nèi)容也有很強的泛化性,我們只要識別一輛車的樣子,就也會辨別出不同樣式的車。這也是深度神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)更高層次、抽象的特征的過程。
準(zhǔn)備寫本書 屬實逼真,決策樹可視化! 21個深度學(xué)習(xí)開源數(shù)據(jù)集匯總! 耗時一個月,做了一個純粹的機器學(xué)習(xí)網(wǎng)站 用 Python 從 0 實現(xiàn)一個神經(jīng)網(wǎng)絡(luò) 40篇AI論文!附PDF下載,代碼、視頻講解
三連在看,月入百萬??