
3D深度學習簡介
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

在過去的幾年里,像微軟Kinect或Asus Xtion傳感器這樣,既能提供彩色圖像又能提供密集深度圖像的新型相機系統(tǒng)變得唾手可得。人們對此類系統(tǒng)的期望很高,它們將推動機器人技術和視覺與增強現(xiàn)實領域中基于3D感知的新應用。
三維深度學習方法已經(jīng)從使用三維數(shù)據(jù)的派生表示轉變?yōu)橹苯邮褂迷紨?shù)據(jù)。在方法方面,將二維卷積神經(jīng)網(wǎng)絡應用于三維數(shù)據(jù)已轉化為專門為三維場景設計的方法,這大大提高了對象分類和語義分割等任務的性能。
本文將重點介紹最近的三維對象分類和語義分割。我們將首先回顧一些獲取和表示三維數(shù)據(jù)的常用方法的背景,接下來,介紹三種不同的基本三維數(shù)據(jù)表示方法。最后,我們將介紹未來有希望的新研究方向,并從我們的角度總結該領域的未來方向。
獲取三維數(shù)據(jù)后,需要將其表示為一種形式,作為正在構建的處理流的輸入。
以下是常見的四種表述:
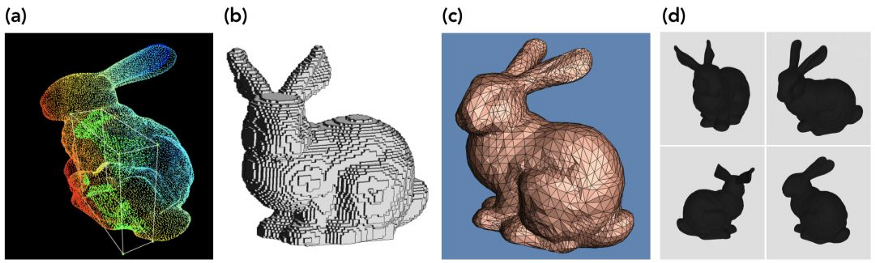
(a) 點云;(b) 體素網(wǎng)格;(c) 三角網(wǎng)格;(d) 多視圖表示
1、點云是三維空間中點的集合;每個點由某個(x、y、z)位置確定,我們還可以為其指定其他屬性(如RGB顏色)。
2、體素網(wǎng)格是從點云發(fā)展而來的,體素類似于三維空間中的像素。
3、多邊形網(wǎng)格由一組具有公共頂點的凸多邊形曲面組成,這些曲面可以近似于幾何曲面。
4、多視圖表示是從不同模擬視角獲得的渲染二維多邊形網(wǎng)格圖像的集合。
多視圖表示是將深度學習模型應用于三維場景的最簡單方法。該問題已轉化為二維問題,但它仍允許在一定程度上對三維幾何結構進行推理。這一思想的早期應用基于[1]一種簡單但非常有效的網(wǎng)絡體系結構,它可以從三維對象的多個二維視圖中學習特征描述符。在預先訓練好的VGG網(wǎng)絡中逐個輸入圖像,以提取顯著特征,組合這些結果向量,并將這些信息傳遞給剩余的卷積層以進行進一步的特征學習。
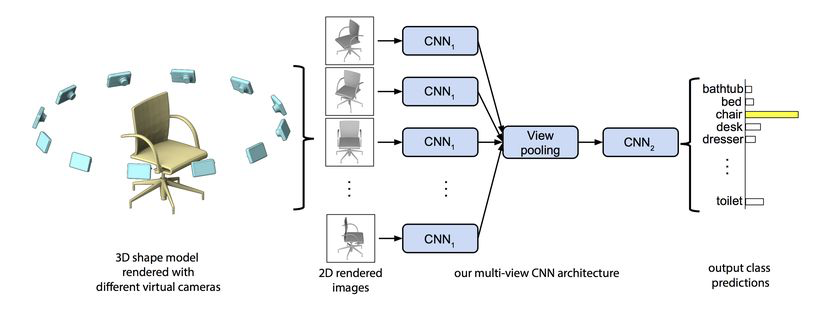
固定數(shù)量的二維視圖仍然只是底層三維結構的不完美近似。由于從二維圖像獲得的特征信息有限,語義分割等任務,尤其是在跨越更復雜的對象和場景時,變得更具挑戰(zhàn)性,這些缺點促使人們研究直接使用三維數(shù)據(jù)進行學習的方法。
通過體素網(wǎng)格學習可以解決多視圖表示的主要缺點。體素網(wǎng)格縮小了2D和3D之間的差距。它們是圖像最接近的三維表示,這使得二維DL概念很容易應用于三維場景。
Maturana和Scherer于2015年提出的VoxNet[2]是第一個在具有給定體素網(wǎng)格的對象分類任務上實現(xiàn)優(yōu)異性能的VoxNet,VoxNet使用概率占用網(wǎng)格,其中每個體素包含體素在空間中被占用的概率。這樣做的一個優(yōu)點是,它允許網(wǎng)絡區(qū)分已知為自由的體素和占用率未知的體素。
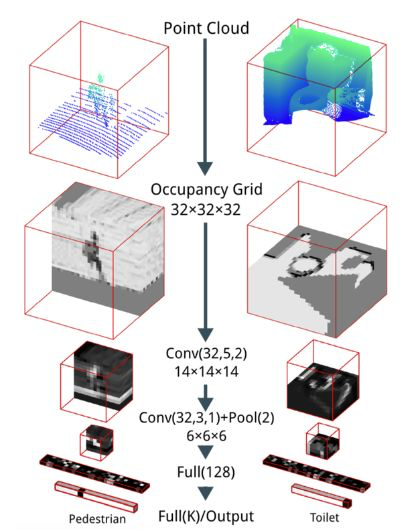
該體系結構由兩個卷積層和一個池層組成,兩個完全連接的層用于計算輸出類別得分向量。VoxNet代表著邁向真正3D學習的一大步,但體素網(wǎng)格仍有一些缺點。首先,與點云相比,它們失去了分辨率。因為如果表示復雜結構的不同點非常接近,它們將綁定在同一個體素中。同時,與稀疏環(huán)境中的點云相比,體素網(wǎng)格可能會導致不必要的高內存使用率,這是因為它們主動消耗內存來表示空閑和未知空間,而點云只包含已知點。
考慮到使用基于體素的方法的問題,最近的工作集中在直接對原始點云數(shù)據(jù)進行操作的架構上。Qi等人于2016年提出的PointNet是處理這種不規(guī)則3D數(shù)據(jù)的最早方法。當我們在點云中給定N個點時,網(wǎng)絡需要學習一個獨特的特征,該特征相對于這些N個輸入點的完整排列是恒定的,因為這些輸入為神經(jīng)網(wǎng)絡提供了點的順序,而不影響基礎幾何結構。此外,網(wǎng)絡應對點云旋轉、平移和其他變換具有魯棒性,縮放操作不應影響預測結果。
為了解決學習點云幾何變換不變表示的問題,PointNet使用了一個稱為T-Net的小型網(wǎng)絡,該網(wǎng)絡將仿射變換應用于輸入點云。這個概念類似于空間變換網(wǎng)絡,但要簡單得多,因為不需要定義新類型的層。T-Net是一個可學習的參數(shù)組合,這些參數(shù)使PointNet能夠將輸入點云轉換為固定和標準化的空間,從而確保整個網(wǎng)絡對即使是最細微的變化也具有魯棒性。
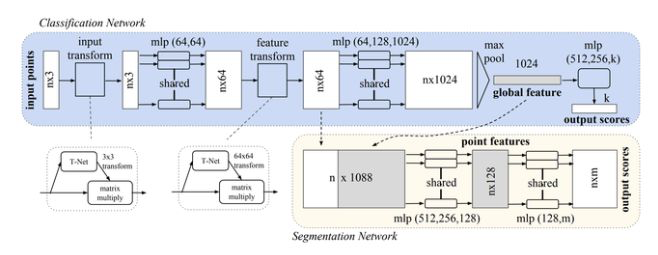
整個PointNet體系結構繼承了最基本的方法、T-Net和多層,它們?yōu)辄c云創(chuàng)建特征表示。然而,除了對象分類之外,PointNet還支持對象和場景的語義分割。
在過去的 5 年中,3D 深度學習方法已經(jīng)從使用 3D 數(shù)據(jù)的派生表示轉變?yōu)槭褂迷紨?shù)據(jù)。在這個過程中,我們采用的方法已經(jīng)從簡單的卷積神經(jīng)網(wǎng)絡應用于3D數(shù)據(jù)轉變?yōu)閷iT為3D場景設計的方法,極大地提高了對象分類和語義分割等任務的性能。
在過去的5年中,三維深度學習方法已經(jīng)從使用三維數(shù)據(jù)的派生表示法轉變?yōu)槭褂迷紨?shù)據(jù)。在這個過程中,我們采用的方法已經(jīng)從簡單的應用于三維數(shù)據(jù)的卷積神經(jīng)網(wǎng)絡轉變?yōu)閷iT為三維場景設計的方法,這大大提高了對象分類和語義分割等任務的性能。
[1] Multi-view Convolutional Neural Networks for 3D Shape Recognition
[2] VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition (2015)
[3] PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
好消息,小白學視覺團隊的知識星球開通啦,為了感謝大家的支持與厚愛,團隊決定將價值149元的知識星球現(xiàn)時免費加入。各位小伙伴們要抓住機會哦!

交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關微信群。請勿在群內發(fā)送廣告,否則會請出群,謝謝理解~